




Úvod do návrhu databáze
Identifikace atributů
Prvky dat, které chcete uložit pro každou entitu, se nazývají „atributy“.
O prodávaných výrobcích chcete vědět například, jaká je jejich cena, název výrobce a typové číslo. O zákaznících znáte jejich zákaznické číslo, jejich jméno a adresu. O prodejnách znáte kód lokality, název a adresu. O prodejích víte, kdy se uskutečnily, ve které prodejně, jaké výrobky se prodaly a jaká byla celková částka prodeje. O prodavači znáte číslo jeho zaměstnanců, jméno a adresu. Co přesně bude zahrnuto, není zatím důležité, jde zatím jen o to, co chcete uložit.
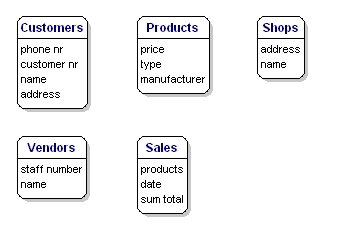
Obrázek 6: Entity s atributy.
Odvozená data
Odvozená data jsou data, která jsou odvozena z jiných dat, která jste již uložili. V tomto případě je „celkový součet“ klasickým případem odvozených dat. Přesně víte, co se prodalo a kolik stojí jednotlivé výrobky, takže můžete vždy vypočítat, kolik je součet prodejů. Ve skutečnosti tedy není nutné celkový součet ukládat.
Takže proč se zde ukládá? No protože se jedná o prodej a cena výrobku se může v čase měnit. Dnes může výrobek stát 10 eur a příští měsíc 8 eur a pro svou správu potřebujete vědět, kolik stál v době prodeje, a nejjednodušší způsob, jak to udělat, je uložit to zde. Existuje spousta elegantnějších způsobů, ale ty jsou pro tento článek příliš hluboké.
Prezentace entit a vztahů: Diagram vztahů entit (ERD)
Diagram vztahů entit (ERD) poskytuje grafický přehled o databázi. Existuje několik stylů a typů ER diagramů. Velmi používaným zápisem je zápis „crowfeet“, kde jsou entity znázorněny jako obdélníky a vztahy mezi entitami jsou znázorněny jako čáry mezi entitami. Značky na konci čar označují typ vztahu. Strana vztahu, která je povinná pro existenci druhé strany, se označí pomlčkou na čáře. Entity, které nejsou povinné, jsou označeny kroužkem. „Mnoho“ je označeno prostřednictvím „lomítka“; řádek vztahu se rozdělí na tři řádky.
V tomto článku využíváme k návrhu a prezentaci naší databáze DeZign for Databases.
Povinný vztah 1:1 je znázorněn takto:
Obrázek 7: Povinný vztah jedna ku jedné.
Povinný vztah 1:N:
Obrázek 8: Povinný vztah jeden k mnoha.
Povinný vztah M:N je:
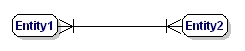
Obrázek 9: Povinný vztah mnoho k mnoha.
Model našeho příkladu bude vypadat takto:
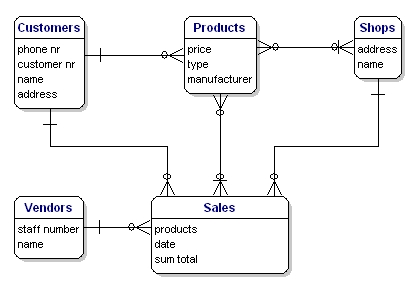
Obrázek 10: Model se vztahy.
Přiřazení klíčů
Primární klíče
Primární klíč (PK) je jeden nebo více datových atributů, které jednoznačně identifikují entitu. Klíč, který se skládá ze dvou nebo více atributů, se nazývá složený klíč. Všechny atributy, které jsou součástí primárního klíče, musí mít v každém záznamu hodnotu (která nesmí zůstat prázdná) a kombinace hodnot v rámci těchto atributů musí být v tabulce jedinečná.
V příkladu je několik zřejmých kandidátů na primární klíč. Všichni zákazníci mají číslo zákazníka, všechny výrobky mají jedinečné číslo výrobku a prodeje mají číslo prodeje. Každý z těchto údajů je jedinečný a každý záznam bude obsahovat hodnotu, takže tyto atributy mohou být primárním klíčem. Často se pro primární klíč používá celočíselný sloupec, aby bylo možné záznam snadno najít pomocí jeho čísla.
Odkazy-entity obvykle odkazují na atributy primárního klíče entit, které propojují. Primární klíč odkazové entity je obvykle kolekcí těchto referenčních atributů. Například v entitě Sales_details bychom mohli jako PK entity Sales_details použít kombinaci PK entit Sales a Products. Tímto způsobem si vynutíme, že stejný výrobek (typ) může být v jednom prodeji použit pouze jednou. Více položek stejného typu výrobku v prodeji musí být označeno množstvím.
V ERD jsou atributy primárního klíče označeny textem „PK“ za názvem atributu. V příkladu pouze entita „shop“ nemá zřejmého kandidáta na PK, proto pro tuto entitu zavedeme nový atribut: shopnr.
Cizí klíče
Cizí klíč (FK) v entitě je odkaz na primární klíč jiné entity. V ERD bude tento atribut označen symbolem „FK“ za svým názvem. Cizí klíč entity může být také součástí primárního klíče, v takovém případě bude atribut označen znakem „PF“ za svým názvem. To je obvykle případ propojených entit, protože obvykle spojujeme dvě instance dohromady pouze jednou (při 1 prodeji se prodává pouze 1 typ výrobku 1krát).
Pokud do ERD vložíme všechny propojené entity, PK a FK, dostaneme model podle následujícího obrázku. Všimněte si, že atribut „products“ již není v „Sales“ nutný, protože „sold products“ je nyní obsažen v tabulce odkazů. Do tabulky odkazů bylo přidáno další pole „množství“, které udává, kolik výrobků bylo prodáno. Pole „množství“ bylo přidáno také do tabulky „sklad“, které udává, kolik výrobků je ještě na skladě.
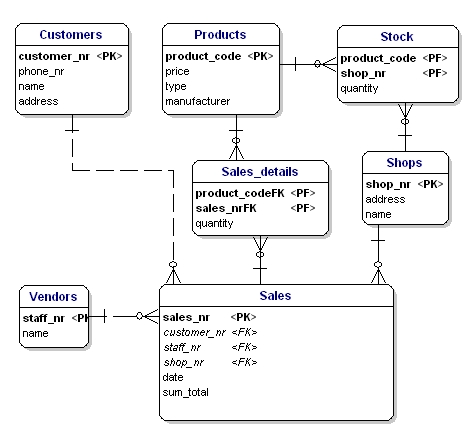
Obrázek 11: Primární klíče a cizí klíče.
Definice datového typu atributu
Nyní je třeba zjistit, jaké datové typy je třeba pro atributy použít. Existuje mnoho různých datových typů. Několik z nich je standardizováno, ale mnoho databází má své vlastní datové typy, které mají všechny své výhody. Některé databáze nabízejímožnost definovat vlastní datové typy pro případ, že standardní typy neumějí to, co potřebujete.
Standardní datové typy, které zná každá databáze a které jsou nejpoužívanější, jsou: CHAR, VARCHAR, TEXT, FLOAT, DOUBLE a INT.
Text:
- CHAR(length) – zahrnuje text (znaky, čísla, interpunkční znaménka…). CHAR má tu vlastnost, že vždy ukládá pevný počet pozic. Pokud definujete CHAR(10), můžete uložit maximálně deset pozic, ale pokud použijete pouze dvě pozice, databáze stále uloží 10 pozic. Zbývajících osm pozic bude vyplněno mezerami.
- VARCHAR(length) – obsahuje text (znaky, čísla, interpunkční znaménka…). VARCHAR je stejný jako CHAR, rozdíl je v tom, že VARCHAR zabírá jen tolik místa, kolik je potřeba.
- TEXT – může obsahovat velké množství textu. V závislosti na typu databáze to může být až gigabajt.
ČÍSLA:
- INT – obsahuje kladné nebo záporné celé číslo. Mnoho databází má varianty INT, například TINYINT, SMALLINT, MEDIUMINT, BIGINT, INT2, INT4, INT8. Tyto varianty se od INT liší pouze velikostí čísla, které se do něj vejde. Běžný INT má velikost 4 bajty (INT4) a vejdou se do něj čísla od -2147483647 do +2147483646, nebo pokud jej definujete jako UNSIGNED od 0 do 4294967296. INT8 neboli BIGINT může mít ještě větší velikost, od 0 do 18446744073709551616, ale zabere až 8 bajtů diskového prostoru, i když je v něm jen malé číslo.
- FLOAT, DOUBLE – Stejná myšlenka jako INT, ale lze do něj ukládat i čísla s pohyblivou řádovou čárkou. . Upozorňujeme, že ne vždy funguje dokonale. Například v MySQL není počítání s těmito čísly s pohyblivou řádovou čárkou dokonalé, (1/3)*3 bude mít u MySQL floatů za výsledek 0,9999999, nikoliv 1.
Další typy:
- BLOB – pro binární data, například soubory.
- INET – pro IP adresy. Použitelné také pro síťové masky.
Pro náš příklad jsou datové typy následující:
Obrázek 12: Datový model zobrazující datové typy.
Normalizace
Normalizace činí váš datový model flexibilním a spolehlivým. Generuje sice určitou režii, protože obvykle získáte více tabulek, ale umožňuje vám dělat s datovým modelem mnoho věcí, aniž byste jej museli upravovat. Více o normalizaci databáze si můžete přečíst v tomto článku.
Normalizace, první forma
První forma normalizace říká, že v entitě nesmí být žádné opakující se skupiny sloupců. Mohli jsme vytvořit entitu „prodej“ s atributy pro každý z nakoupených výrobků. Vypadalo by to takto:

Obrázek 13: Není v 1. normální formě.
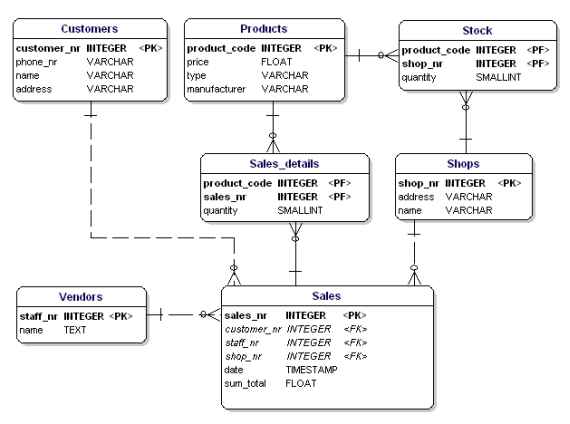
Špatné na tom je, že nyní lze prodat pouze 3 výrobky. Pokud byste chtěli prodávat 4 výrobky, pak byste museli zahájit druhý prodej nebo upravit datový model přidáním atributů ‚product4‘. Obě řešení jsou nežádoucí. V těchto případech byste měli vždy vytvořit novou entitu, kterou propojíte se starou entitou prostřednictvím vztahu one-to-many.
Obrázek 14: V souladu s 1. normální formou.
Normalizace, 2. forma
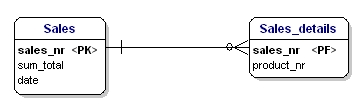
Druhá forma normalizace říká, že všechny atributy entity by měly být plně závislé na celém primárním klíči. To znamená, že každý atribut entity lze identifikovat pouze prostřednictvím celého primárního klíče. Předpokládejme, že v entitě Sales_details máme datum:

Obrázek 15: Není ve druhé normální formě.
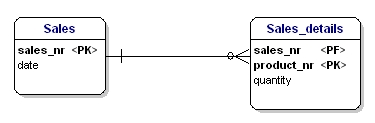
Tato entita není podle druhé normalizační formy, protože abych mohl vyhledat datum prodeje, nemusím vědět, co se prodalo (productnr), jediné, co potřebuji vědět, je prodejní číslo. To se vyřešilo rozdělením tabulek na tabulku Sales a Sales_details:
Obrázek 16: V souladu s 2. normální formou.
Nyní je každý atribut entity závislý na celé PK entity. Datum je závislé na prodejním čísle a množství je závislé na prodejním čísle a prodaném výrobku.
Normalizace, třetí forma
Třetí forma normalizace říká, že všechny atributy musí být přímo závislé na primárním klíči a ne na jiných atributech. Zdá se, že to je to, co uvádí druhá forma normalizace, ale ve druhé formě je ve skutečnosti uveden opak. Ve druhé formě normalizace poukazujete na atributy prostřednictvím PK, ve třetí formě normalizace musí být každý atribut závislý na PK a na ničem jiném.

Obrázek 17: Není ve třetí normální formě.
V tomto případě je cena volného výrobku závislá na objednacím čísle a objednací číslo je závislé na čísle výrobku a prodejním čísle. To není v souladu s třetí normalizační formou. Opět to řeší rozdělení tabulek.
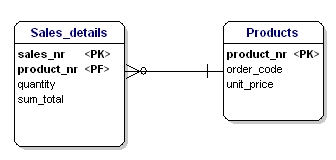
Obrázek 18: V souladu s třetí normální formou.
Normalizace, další formy
Existuje více forem normalizace než tři výše uvedené, ale ty běžného uživatele příliš nezajímají. Tyto další formuláře jsou vysoce specializované pro určité aplikace. Pokud se budete držet pravidel návrhu a normalizace uvedených v tomto článku, vytvoříte návrh, který bude skvěle fungovat pro většinu aplikací.
Normalizovaný datový model
Použijete-li pravidla normalizace, zjistíte, že „výrobce“ v tabulce výrobků by měl být také samostatnou tabulkou:
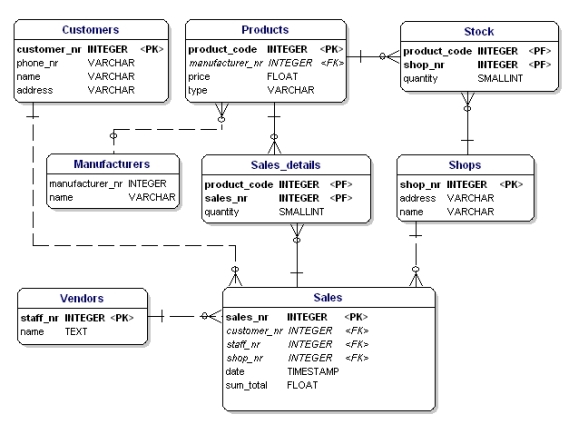
Obrázek 19: Datový model podle 1., 2. a 3. normální formy.