




Článek v časopise SQL Magazine 7 – SQL Server: Zlepšete své dotazy pomocí indexovaných pohledů
Převezměte svůj dotaz Označit jako splněný Anotovat
Účelem tohoto článku je představit koncept indexovaných pohledů SQL Serveru a ukázat, jak tento typ pohledů implementovat a používat k optimalizaci dotazů.
Koncept pohledů
Pohledy jsou také známé jako „virtuální tabulky“, protože představují alternativu k použití tabulek pro přístup k datům. Zobrazení není nic jiného než příkaz SELECT zapouzdřený do objektu. Syntaxe pro vytvoření pohledu je uvedena v Seznamu 1.
CREATE VIEW nome_da_visão ...) ] AS subconsulta;Příklad vytvoření a použití pohledu je uveden v Seznamu 1.
Use NorthWind go create view vi_vendas_mes As Select ano = datepart(yyyy,OrderDate), mes = datepart(mm,OrderDate), qtde_total = sum(Quantity) from Orders o inner join od on o.OrderId = od.OrderId group by datepart(yyyy,o.OrderDate), datepart(mm,o.OrderDate) go select * from vi_vendas_mês go ano mes qtde_total contador ----------- ----------- ----------- -------------------- 1996 7 1462 59 1996 8 1322 69 1996 9 1124 57 1996 10 1738 73 1996 11 1735 66Mezi výhodami používání pohledů můžeme zmínit :
- Zjednodušení kódu: složité SELECTy můžete napsat jednou, zapouzdřit je do pohledu a spouštět je z něj, jako by šlo o libovolnou tabulku;
- Zabezpečení: předpokládejme, že v některých tabulkách máte důvěrné informace, a proto chcete, aby k nim měli přístup jen někteří uživatelé. K některým sloupcům v těchto tabulkách však musí mít přístup všichni uživatelé. Efektivním způsobem řešení tohoto problému je vytvoření zobrazení a skrytí citlivých sloupců. Tímto způsobem lze potlačit přístupová práva k původní tabulce a uvolnit přístup k pohledu;
- Možnost optimalizace dotazů implementací indexovaných pohledů.
Indexované pohledy v praxi
Pohledy zapouzdřují příkazy SELECT, což znamená, že kdykoli jsou spuštěny, provedou se s nimi spojené příkazy SELECT. Pohledy nevytvářejí úložiště pro data, která vracejí (jako tabulka). Bylo by skvělé, kdybychom mohli výsledek příkazu SELECT nalezený v zobrazení „zhmotnit“ v tabulce a vytvořit indexy, které by k němu usnadnily přístup. Právě to dělají indexované pohledy. Provedení příkazu SELECT v indexovaném zobrazení má stejný účinek jako provedení příkazu select v běžné tabulce.
Hlavním účelem indexovaných zobrazení je zvýšení výkonu a výhodou SQL Serveru je, že umožňuje, aby prováděcí plány zohlednily indexované zobrazení jako prostředek přístupu k datům, i když název zobrazení nebyl v dotazu explicitně uveden. To je možné v Enterprise Edition SQL Serveru 2000, kde optimalizátor příkazů může vybírat data přímo v indexovaném zobrazení (namísto výběru surových dat existujících v tabulce), jak uvidíme dále.
Vytvoření indexovaného pohledu krok za krokem
- Konfigurace prostředí, prvním krokem je nastavení stavu některých parametrů v relaci, ve které chcete pohled vytvořit a používat, protože jelikož je indexovaný pohled „zhmotněn“ v tabulce, nemůže do jeho výsledku nic zasahovat. Představte si například následující scénář:
- Před vytvořením indexovaného pohledu je nastaveno určité nastavení, které ovlivňuje výsledek SELECTu (např. concat_null_yelds_null);
- Indexovaný pohled je vytvořen; všimněte si, že výsledek pohledu bude „zhmotněn“ na disku podle nastavení nastaveného v předchozím kroku;
- Poté je nastavení zakázáno a indexovaný pohled je spuštěn uživatelem. Vzhledem k tomu, že zobrazení bylo materializováno, dostaneme výsledek, který neodpovídá aktuální konfiguraci.
Například výpis 2 ukazuje rozdíl ve výsledku příkazu při změně vlastnosti concat_null_yields_null.
set concat_null_yields_null ON print null + 'abc' -------------------------------------- Set concat_null_yields_null OFF print null + 'abc' -------------------------------------- abcPředstavte si, co by se stalo, kdyby byl indexovaný pohled vytvořen se zapnutou vlastností concat_null_yields_null, ale aktuální relace by byla s touto vlastností vypnutou – stejný SELECT by vedl k různým výsledkům!
Tento problém byl vyřešen jednoduchým způsobem – pro vytvoření a použití indexovaných pohledů je nutné nakonfigurovat prostředí podle seznamu výchozích hodnot. Tímto způsobem není možné získat jiné výsledky, protože zobrazení jednoduše nebude fungovat, pokud je některé z nastavení nastaveno na nestandardní hodnotu.
Tabulka 1 zobrazuje tato nastavení a jejich příslušné výchozí hodnoty.
| Nastavení | Id (*) | Vyžadovaný stav pro indexované pohledy | SQL Server 2000 výchozí | Výchozí u připojení OLE DB (=ADO) nebo ODBC | Výchozí u připojení, která používají knihovnu DB | |
|---|---|---|---|---|---|---|
| ANSI_NULLS | 32 | ON | OFF | ON | OFF | |
| ANSI_PADDING | 16 | ZAP | ZAP | ZAP | VYP | |
| ANSI_WARNING | 8 | ZAP | VYPNUTO | ZAPNUTO | VYPNUTO | |
| ARITHABORT | 64 | ZAPNUTO | VYPNUTO | VYPNUTO | VYPNUTO | OFF |
| CONCAT_NULL_YIELDS_NULL | 4096 | ON | OFF | ON | OFF | OFF |
| CITOVANÝ_IDENTIFIKÁTOR | 256 | ZAPNUTÝ | VYPNUTÝ | ZAPNUTÝ | VYPNUTÝ | |
| NUMERIC_ROUNDABORT | 8192 | OFF | OFF | OFF | OFF | OFF |
(*) Id se používá v příkazu sp_configure. Chcete-li zjistit, co jednotlivá nastavení dělají, přečtěte si část „Požadovaná nastavení pro indexovaná zobrazení“. Hodnotu konfigurace lze změnit dvěma způsoby:
- Přímo v relaci: spusťte příkaz set ON | OFF
- Změna stávajícího výchozího nastavení serveru: spusťte sp_Configure ‚user options‘, . Identifikační číslo každé konfigurace je uvedeno v tabulce 1.
Poznámka: AritHabort má id 64 a Quoted_Identifier má id 256. Pro propojení například Quoted_Identifier + AritHabort bychom provedli příkaz sp_cofigure a jako parametr předali výsledek 64+256 (=320): sp_configure ‚user options‘, 320. Úplný výpis identifikátorů přiřazených jednotlivým konfiguracím najdete na adrese http://msdn.microsoft.com/library/default.asp?url=/library/en-us/adminsql/ad_config_9b1q.asp.
Pro potvrzení stavu jednotlivých parametrů v tabulce 1 použijte funkci SessionProperty(‚název parametru‘) nebo příkaz DBCC UserOptions.
Tímto způsobem nastavte všechny parametry podle sloupce „požadovaný stav pro indexované pohledy“ v tabulce 1 – pokud tak neučiníte, SQL Server vám nedovolí vytvořit/vykonat indexovaný pohled.
Vytvoření indexovaného pohledu
Vytvoříme pohled, který bude sčítat denní prodanou částku v tabulce Podrobnosti o objednávce, která se nachází v databázi NorthWind. Viz výpis 3.
use NorthWind go create view vi_vendas_mes with SchemaBinding as select ano = datepart(yyyy,OrderDate), mes = datepart(mm,OrderDate), qtde_total = sum(Quantity), contador = count_big(*) from dbo.Orders o inner join dbo. od on o.OrderId = od.OrderId group by datepart(yyyy,o.OrderDate),datepart(mm,o.OrderDate) goPři vytváření indexovaných pohledů musíme dodržet některé zvláštnosti:
- Pohled musí být deterministický. Zobrazení bude deterministické, pokud v jeho kódu použijeme pouze deterministické funkce. Stejný příkaz SELECT provedený opakovaně na indexovaném pohledu (s ohledem na statickou základnu) nemůže dát různé výsledky. Deterministické funkce zajišťují, že výsledek funkce zůstane nezměněn bez ohledu na to, kolikrát bude provedena. Například funkce DatePart je deterministická, protože pro určité datum vrací vždy stejný výsledek. Funkce getdate() vrátí při každém spuštění jinou hodnotu. Úplný seznam deterministických funkcí SQL Serveru 2000 najdete na adrese http://msdn.microsoft.com/library/default.asp?url=/library/en-us/createdb/cm_8_des_08_95v7.asp
- Zkontrolujte, zda neexistují žádná syntaktická omezení. Níže uvedené klauzule, funkce a typy dotazů nemohou integrovat schéma indexovaného zobrazení:
- MIN, MAX,TOP
- VARIANCE,STDEV,AVG
- COUNT(*)
- SUMA na sloupcích, které umožňují nulové hodnoty
- DISTINCT
- Funkce ROWSET
- Derived tables, self joins, subqueries, vnější spojení
- DISTINCT
- UNION
- Float, text, ntext a image
- COMPUTE a COMPUTE BY
- HAVING, CUBE a ROLLUP
Je nutné vytvořit indexované pohledy pomocí SchemaBinding. Aby byl obsah zobrazení konzistentní, nelze měnit strukturu tabulek, z nichž zobrazení pochází. Abyste se vyhnuli tomuto problému, je při vytváření indexovaných pohledů nutné použít SchemaBinding, protože tato možnost neumožňuje měnit strukturu tabulky bez předchozího odstranění pohledu.
Chcete-li použít klauzuli GROUP BY, je nutné zahrnout funkci COUNT_BIG(*). Funkce count_big(*) provádí totéž co count(*), ale vrací hodnotu typu bigint (8 bajtů).
Vždy informujte vlastníka objektů, na které je odkazováno v indexovaném zobrazení. Použijte select * from dbo.Orders místo select * from Orders, protože je možné mít tabulky se stejným názvem, ale různými vlastníky. Protože volba schemabinding je povinná, SQL Server potřebuje přesnou specifikaci objektu, aby omezil změnu schématu.
Vytvoření clusterového indexu v pohledu (materializace)
Pohled vytvořený v bodě 2 se ještě nechová jako indexovaný pohled, protože výsledek příkazu select nebyl materializován do tabulky. Toto tvrzení si můžete potvrdit spuštěním příkazu sp_spaceused v programu Query Analyzer, který vrátí počet řádků a prostor využitý tabulkami (Výpis 4).
sp_SpaceUsed vi_vendas_mes -------------------------------------------------------------------------------------- Server: Msg 15235, Level 16, State 1, Procedure sp_spaceused, Line 91 Views do not have space allocated.Všimněte si na Výpisu 5, že zpracování pohledu je čistě logické, a to natolik, že hodnota Physical Reads je nulová. Všimněte si hodnot zaznamenaných v položkách Logical Reads a Physical Reads (1672+0+4+0=1676) – tyto hodnoty použijeme při dalších srovnáních.
Set statistics io ON Select * from vi_vendas_mesgo---------------------------------------------------------ano mes qtde_total contador ----------- ----------- ------------- -------------------- 1996 7 1462 591996 8 1322 691996 9 1124 57.....(23 row(s) affected)Table 'Order Details'. Scan count 830, logical reads 1672, physical reads 0, read-ahead reads 0.Table 'Orders'. Scan count 1, logical reads 4, physical reads 0, read-ahead reads 0.Pro kontrolu, zda lze pohled indexovat (materializovat), tj. zda byl vytvořen v rámci standardů a nastavení požadovaných pro indexované pohledy, by se měl výsledek následujícího SELECT rovnat 1.
select ObjectProperty(object_id('vi_vendas_mes'),'IsIndexable')Potvrdíme-li předpoklady, můžeme nyní vytvořit index. Syntaxe má stejný formát, jaký se používá při vytváření indexů v běžných tabulkách:
create unique clustered index pk_ano_mes on vi_vendas_mes (ano,mes)Všimněte si, že clusterový index je nutný, protože generuje stránky dat. Neklastrové indexy v indexovaných pohledech můžete vytvořit až po vytvoření klastrového indexu.
Nyní nalezený SELECT v pohledu byl zhmotněn. což lze dokázat příkazem sp_spaceused v nástroji Query Analyzer (výpis 6).
sp_SpaceUsed vi_vendas_mêsgo-----------------------------------------------------Name Rows Reserved data index_size Unusedvi_vendas_mes 23 24 KB 8 KB 16 KB 0 KBPoužití indexovaných zobrazení
Jedním ze způsobů přístupu k indexovanému zobrazení (stejně jako k běžnému zobrazení) je odkaz na jeho název v příkazu SELECT:
select * from vi_vendas_mesPorovnejte objem přesunutých stránek v seznamu 5 (1672+4=1676) s objemem v seznamu 7 (2+0=2). Rozdíl je poměrně výrazný – vytvoření indexovaného pohledu snížilo celkovou potřebu I/O o 1674 stránek.
Set statistics io ON select * from vi_vendas_mes go --------------------------------------------------------- ano mes qtde_total contador ----------- ----------- ------------- -------------------- 1996 7 1462 59 1996 9 1124 57 ..... (23 row(s) affected) Table 'vi_vendas_mes'. Scan count 1, logical reads 2, physical reads 0, read-ahead reads 0.Podívejme se na další příklad. Obrázek 1 ukazuje plán provádění dotazu. Potvrďte, že zobrazení bylo vybráno, i když nebylo přítomno v řádku SELECT.
Při sestavování plánu provádění dotazu optimalizátor zjistil, že v souboru vi_sales_mes jsou již předem shrnutá data pro tento dotaz, a rozhodl se vybrat data přímo v indexovaném zobrazení.
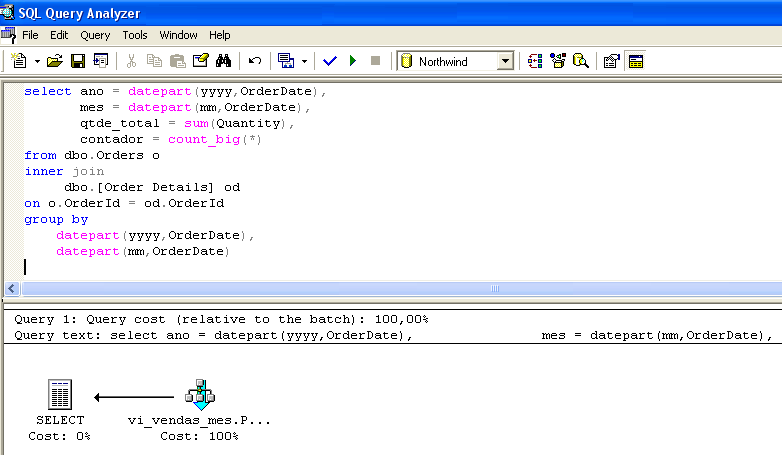
Všimněte si, že dotaz provedený na obrázku 1 je totožný s dotazem nalezeným v zobrazení vi_sales_mes. Přístup optimalizátoru k zobrazení je však nezávislý na podobnosti mezi prováděným dotazem a dotazem na zobrazení. Výběr indexovaného zobrazení zpracovatelem dotazu bere v úvahu pouze poměr nákladů a přínosů. Prováděné dotazy tak nemusí být totožné s pohledem (viz obrázek 3).
Je však nutné dodržet některá pravidla, aby byl indexovaný pohled zohledněn optimalizátorem dotazů:
- Spojení přítomné v pohledu musí být „obsaženo“ v dotazu: pokud dotaz provede spojení mezi tabulkami A a B a pohled provede spojení mezi A a C, pohled nebude v plánu provádění spuštěn. Pokud však dotaz provede spojení mezi A,B a C, může být pohled spuštěn.
- Podmínky nastavené v dotazu musí souhlasit s podmínkami v pohledu: v SELECT na obrázku 2 nebude indexovaný pohled vi_sales_mes brán v úvahu, protože v kódu pohledu nebyla přítomna klauzule where, což způsobilo, že ve spojení byly vypočteny řádky s množstvím <= 5.
Na druhou stranu, pokud má dotaz podmínku where where sum(Quantity) > 5, bude v plánu provádění zohledněn pohled vi_sales_mes, protože podmínka dotazu je podmnožinou SELECT přítomných v pohledu.
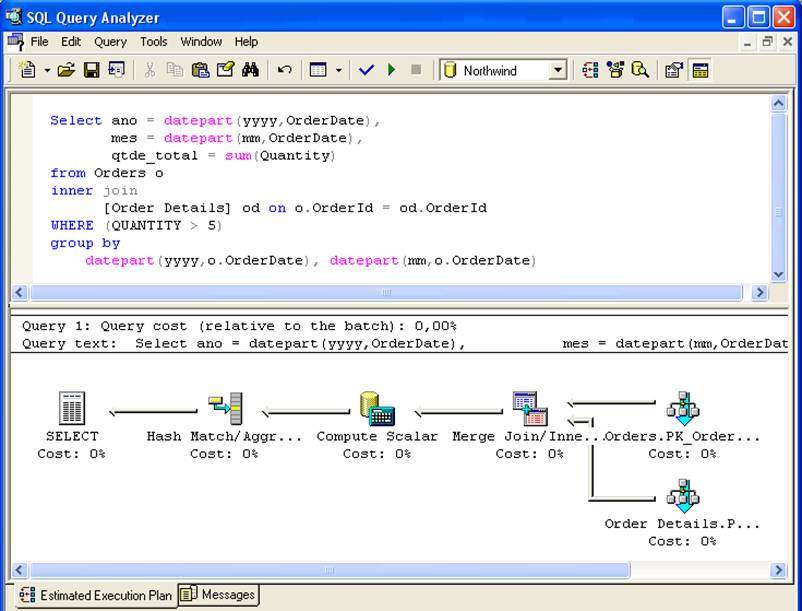
Sloupce s agregačními funkcemi v dotazu musí být „obsaženy“ v definici pohledu: pokud pohled vrací sloupec qtde=sum(Quantity) a dotaz má sloupec vlr_unit=sum(UnitPrice), pohled nebude zohledněn.
Obrázek 3 ukazuje příkaz SELECT, který umožňuje prokázat inteligenci optimalizátoru příkazů – výpočet AVG(Množství) byl nahrazen dělením SUM(Množství) / Count_Big(*), reprezentovaným ikonou Compute Scalar. Uvažuje se také predikát where sum(Quantity) > 1500 (reprezentovaný ikonou Filtr).
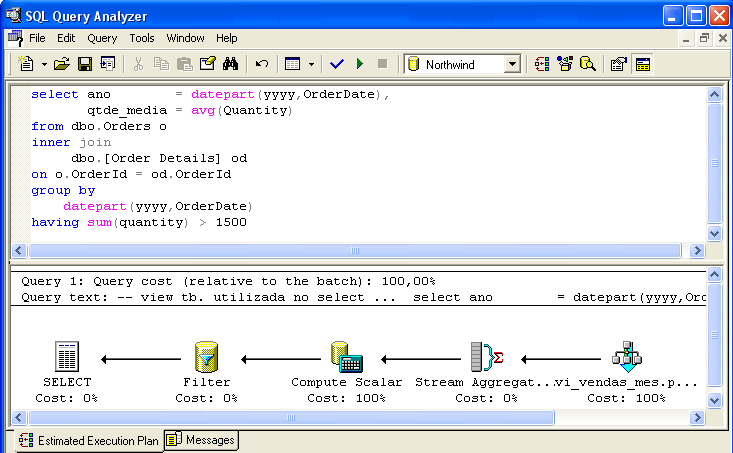
Obecné úvahy o použití indexovaných pohledů:
- Indexované pohledy lze vytvořit v libovolné verzi SQL Serveru 2000. Pouze ve verzi Enterprise Edition je však optimalizátor dotazu vybere automaticky.
- V jiných verzích než Enterprise musíte použít nápovědu NoExpand, abyste k indexovanému pohledu přistupovali jako k běžné tabulce. Pokud není použita funkce NoExpand, bude indexované zobrazení považováno za „normální“ zobrazení.
Poznámka: Nápověda Expand dělá opak NoExpand: zachází s indexovaným pohledem jako s „normálním“ pohledem a nutí SQL Server provést příkaz SELECT během fáze běhu.
- Údržba indexovaného pohledu je automatická (stejně jako u indexů); nevyžaduje žádnou další synchronizaci. Díky své vlastní charakteristice (obvykle ukládá předem shrnutá data) bývá jeho aktualizace o něco pomalejší než u běžných indexů.
- Používání indexovaných pohledů v bázích OLTP vyžaduje opatrnost, protože sice představují velký výkon v dotazech, ale způsobují režii v procesech, které modifikují tabulky související s pohledem. V situacích, kdy je vyžadován vysoký výkon zápisu s častými aktualizacemi, se vytváření indexovaných pohledů nedoporučuje.
- Stejně jako u indexů bude optimalizátor analyzovat kód pohledu ve verzích Enterprise v rámci procesu výběru nejlepšího plánu provádění dotazu. Pokud však existuje mnoho indexovaných pohledů vhodných k provedení pro stejný dotaz, může dojít k podstatnému prodloužení doby výběru, protože budou analyzovány všechny pohledy. Proto se při implementaci pohledů řiďte zdravým rozumem.
Potřebná nastavení pro indexované pohledy
ANSI_NULLS
Definuje způsob porovnávání s nulovými hodnotami (výpis 8).
set ANSI_NULLS ON declare @var char(10) set @var = null if @var = null print 'VERDADEIRO' else print 'FALSO' ------------------------------------- FALSO set ANSI_NULLS OFF declare @var char(10) set @var = null if @var = null print 'VERDADEIRO' else print 'FALSO' -------------------------------------- VERDADEIROANSI_PADDING
Určuje, jak mají být uloženy sloupce char, varchar, binary a varbinary, pokud je jejich obsah menší než velikost definovaná ve struktuře tabulky. Ve výchozím nastavení SQL Serveru 2000 je ansi_padding zapnutý (=ON); v této podmínce platí následující pravidla:
- Při aktualizaci sloupců char budou na konec řetězce přidány bílé znaky, pokud je jejich velikost menší než velikost definovaná ve struktuře sloupce. Stejné pravidlo platí i pro binární sloupce (v tomto případě je mezera vyplněna posloupností nul)
- Varchar nebo varbinary sloupce se výše uvedeným pravidlem neřídí: vždy si zachovávají svou původní velikost.
ARITHABORT
Pokud je povoleno, ukončí provádění dotazu, pokud dojde k dělení nulou nebo k nějakému druhu přetečení.
QUOTED_IDENTIFIER
Pokud je povoleno, umožňuje použití dvojitých uvozovek k určení názvů tabulek, sloupců atd. – Takto mohou tyto názvy obsahovat mezery nebo speciální znaky.
CONCAT_NULL_YELDS_NULL
Řídí výsledek spojování řetězců s nulovými hodnotami. Je-li povoleno, určuje, že toto spojení musí vrátit nulovou hodnotu; jinak vrátí samotný řetězec.
ANSI_WARNINGS
Pokud je povoleno, určuje generování chybových hlášení, když:
- použijete sumarizační funkce a v rozsahu dotazu jsou nalezeny nulové hodnoty;
- jsou nalezena dělení nulou nebo aritmetické přetečení.
NUMERIC_ROUNDABORT
Řídí, jak má SQL Server postupovat při ztrátě numerické přesnosti při aritmetických operacích. Pokud je parametr povolen a proměnná s přesností na dvě desetinná místa obdrží hodnotu na tři desetinná místa, operace se přeruší. Pokud je parametr zakázán, bude hodnota zkrácena na dvě desetinná místa.
Závěr
Pokud jde o optimalizaci dotazů, jsou indexované pohledy dobrou volbou pro využití výkonu. Proto důkladně vyhodnoťte dotazy, které se týkají shrnutí a jsou prováděny s určitou frekvencí, a přejděte k vytváření indexovaných pohledů. Výsledek stojí za to!