




Jak dobré jsou průzkumy veřejného mínění? Analýza datového souboru Five-Thirty-Eight
Analyzujeme datový soubor žebříčku průzkumů veřejného mínění z úctyhodného webu pro politické předpovědi Five-Thirty-Eight.

Je volební rok a volební scéna kolem voleb (všeobecných prezidentských i sněmovních/senátních) se vyhrocuje. V příštích dnech to bude stále napínavější a napínavější – tweety, protitweety, souboje na sociálních sítích a nekonečné pindání v televizi.
Víme, že ne všechny průzkumy jsou stejně kvalitní. Jak se tedy v tom všem vyznat? Jak pomocí dat a analýz rozpoznat důvěryhodné průzkumníky?“

Ve světě politických (a některých dalších záležitostí, jako je sport, společenské jevy, ekonomie atd.) prediktivních analýz je Five-Thirty-Eight impozantní jméno.
Od začátku roku 2008 publikuje tento web články – obvykle vytvářející nebo analyzující statistické informace – na nejrůznější témata z oblasti aktuální politiky a politického zpravodajství. Webová stránka, kterou vede datová hvězda a statistik Nate Silver, dosáhla zvláštního věhlasu a široké proslulosti kolem prezidentských voleb v roce 2012, kdy její model správně předpověděl vítěze všech 50 států a District of Columbia.
A než se začnete posmívat a říkat: „Ale co volby v roce 2016?“, možná by bylo dobré přečíst si tento článek o tom, že zvolení Donalda Trumpa bylo v rámci běžné chyby statistického modelování.
Pro politicky zvídavější čtenáře tu mají celý pytel článků o volbách 2016.
Praktici datových věd by si měli Five-Thirty-Eight oblíbit, protože se nevyhýbá vysvětlování svých predikčních modelů vysoce odbornými termíny (přinejmenším dostatečně složitými pro laiky).

Tady se mluví o přijetí slavného t-rozdělení, zatímco většina ostatních agregátorů průzkumů se může spokojit jen s všudypřítomným normálním rozdělením.
Tým pod vedením Silvera se však nad rámec používání sofistikovaných technik statistického modelování pyšní unikátní metodikou – pollster ratingem, který pomáhá jejich modelům zůstat vysoce přesnými a důvěryhodnými.
V tomto článku analyzujeme jejich údaje o těchto ratingových metodách.
Five-Thirty-Eight se nevyhýbá vysvětlování svých predikčních modelů vysoce odbornými termíny (přinejmenším dostatečně složitými pro laiky).
Pollster rating a ranking
V této zemi působí velké množství pollsterů. Jejich čtení a hodnocení kvality může být vysoce zatěžující a frapantní. Jak uvádí webová stránka: „Čtení průzkumů veřejného mínění může být nebezpečné pro vaše zdraví. Mezi příznaky patří vybírání třešniček, přehnaná důvěra, propadání šmejdským číslům a ukvapené soudy. Naštěstí máme lék.“ (zdroj)
Existují průzkumy veřejného mínění. Pak jsou průzkumy veřejného mínění. Pak jsou tu vážené průzkumy veřejného mínění. A především existují ankety anket s váhami, které jsou statisticky modelované a váhy se dynamicky mění.
Zní vám povědomě jiná slavná metodika sestavování žebříčků, o které jste jako datový vědec slyšeli? Žebříček produktů Amazonu nebo žebříček filmů Netflixu? Pravděpodobně ano.
V podstatě Five-Thirty-Eight používá tento systém hodnocení/rankování k vážení výsledků průzkumů (vysoce hodnocené výsledky průzkumů mají vyšší váhu a tak dále). Zároveň aktivně sledují přesnost a metodiku, která stojí za výsledky jednotlivých průzkumů, a v průběhu roku upravují jejich pořadí.
Existují průzkumy veřejného mínění. Pak jsou průzkumy veřejného mínění. Pak jsou tu vážené průzkumy veřejného mínění. A především existují ankety anket s váhami, které jsou statisticky modelované a váhy se dynamicky mění.
Zajímavé je, že jejich metodika sestavování žebříčků nehodnotí nutně jako lepší tu anketu, která má větší vzorek. Následující snímek obrazovky z jejich webových stránek to jasně demonstruje. Zatímco agentury pro průzkum veřejného mínění jako Rasmussen Reports a HarrisX mají větší velikost vzorku, je to ve skutečnosti Marist College, která získává hodnocení A+ se skromnou velikostí vzorku.
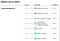
Naštěstí zde na Githubu také otevřeně zveřejňují svá data o pořadí v průzkumech veřejného mínění (spolu s téměř všemi ostatními soubory dat). A pokud vás zajímá jen pěkně vypadající tabulka, tady je.
Jako datový vědec se samozřejmě můžete chtít podívat hlouběji do surových dat a pochopit věci jako,
- jak jejich číselný žebříček koreluje s přesností tazatelů
- jestli mají stranickou zaujatost při výběru konkrétních tazatelů (ve většině případů je lze zařadit do kategorie buď demokraticky orientovaných, nebo republikánsky orientovaných)
- kdo jsou nejlépe hodnoceni tazatelé? Provádějí mnoho průzkumů, nebo jsou selektivní?
Pokusili jsme se analyzovat soubor dat pro získání těchto poznatků. Pojďme se ponořit do kódu a zjištění, ano?“
Analýza
Zápisník Jupyter najdete zde na mém repozitáři Github.
Zdroj
Na začátek si můžete data vytáhnout přímo z jejich Githubu, a to do datového rámce Pandas DataFrame takto,

V tomto souboru dat je 23 sloupců. Takto vypadají,

Nějaká transformace a vyčištění
Všimli jsme si, že jeden sloupec má nějaké místo navíc. Několik dalších možná bude potřebovat nějakou extrakci a konverzi datového typu.



Po použití této extrakce, má nový DataFrame další sloupce, což jej činí vhodnějším pro filtrování a statistické modelování.

Zkoumání a kvantifikace sloupce „Známka 538“
Sloupec „Známka 538“ obsahuje jádro datového souboru – písmennou známku pro tazatele. Stejně jako u běžné zkoušky je A+ lepší než A a A je lepší než B+. Vyneseme-li do grafu počty písmenných známek, pozorujeme celkem 15 stupňů, od A+ po F.

Namísto práce s tolika kategoriálními stupni bychom je mohli sloučit do malého počtu číselných stupňů – 4 pro A+/A/A-, 3 pro B atd.

Boxploty
Přejdeme-li k vizuální analýze, můžeme začít boxploty.
Předpokládejme, že chceme ověřit, která metoda hlasování má lepší výsledky z hlediska chyby předpovědi. Datový soubor má sloupec nazvaný „Prostá průměrná chyba“, který je definován jako „Průměrná chyba firmy, vypočtená jako rozdíl mezi výsledkem průzkumu a skutečným výsledkem pro rozpětí oddělující první dva účastníky závodu.“

Pak nás může zajímat, zda jsou tazatelé s určitým stranickým zaujetím úspěšnější ve správném tipování voleb než ostatní.

Všimli jste si něčeho zajímavého výše? Pokud jste progresivní, liberálně smýšlející člověk, se vší pravděpodobností můžete být straníkem Demokratické strany. Ale v průměru průzkumníci s republikánským zaměřením, volí volby přesněji a s menší variabilitou. Raději si na tyto průzkumy dejte pozor!“
Další zajímavý sloupec v souboru dat se jmenuje „NCPP/AAPOR/Roper“. Ten „označuje, zda byla firma provádějící průzkum veřejného mínění členem Národní rady pro průzkumy veřejného mínění, signatářem iniciativy Americké asociace pro výzkum veřejného mínění za transparentnost nebo přispěvatelem do archivu dat Roperova centra pro výzkum veřejného mínění. Členství fakticky naznačuje dodržování robustnější metodiky průzkumu veřejného mínění“ (zdroj).
Jak posoudit platnost výše uvedeného tvrzení? Soubor dat má sloupec nazvaný „Advanced Plus-Minus“, což je „skóre, které porovnává výsledek průzkumu veřejného mínění s výsledky jiných průzkumných firem provádějících průzkum stejných závodů a které váží více nedávné výsledky. Záporné skóre je příznivé a naznačuje nadprůměrnou kvalitu“ (zdroj).
Tady je boxplot mezi těmito dvěma parametry. Nejenže průzkumy veřejného mínění, spojené s NCCP/AAPOR/Roper, vykazují nižší chybové skóre, ale vykazují také značně nízkou variabilitu. Jejich předpovědi se zdají být stabilní a robustní.

Pokud jste progresivně a liberálně smýšlející, se vší pravděpodobností můžete být stranou Demokratické strany. Ale v průměru průzkumníci, kteří se přiklánějí k republikánům, odhadují volby přesněji a s menší variabilitou.
Rozptylové a regresní grafy
Abychom pochopili korelaci mezi parametry, můžeme se podívat na rozptylové grafy s regresním fitem. Pro generování těchto grafů používáme knihovny Seaborn a Scipy Python a vlastní funkci.
Například můžeme dát do souvislosti „Závody vyvolané správně“ s „Prediktivním plus-mínusem“. Podle Five-Thirty-Eight je „Prediktivní Plus-Minus“ „projekcí toho, jak přesný bude průzkum veřejného mínění v budoucích volbách. Vypočítává se přepočtem skóre Advanced Plus-Minus průzkumníka na průměr na základě našich ukazatelů metodologické kvality“. (zdroj)

Nebo můžeme zkontrolovat, jak námi definované „číselné hodnocení“ koreluje s průměrem chybovosti průzkumu. Negativní trend naznačuje, že vyšší číselná známka je spojena s nižší chybou průzkumu.

Můžeme také zkontrolovat, zda „# průzkumů pro analýzu zaujatosti“ pomáhá při snižování „Stupně stranické zaujatosti“, který je přiřazen jednotlivým průzkumníkům. Můžeme pozorovat klesající závislost, což naznačuje, že dostupnost vysokého počtu průzkumů skutečně pomáhá snížit stupeň stranické zaujatosti. Vztah však vypadá silně nelineárně a pro dosazení křivky by bylo vhodnější logaritmické škálování.

Má se aktivnějším tazatelům více věřit? Vykreslíme histogram počtu anket a vidíme, že se řídí záporným mocninným zákonem. Můžeme odfiltrovat tazatele s velmi nízkým i velmi vysokým počtem anket a vytvořit vlastní graf rozptylu. Pozorujeme však téměř neexistující korelaci mezi # průzkumů a prediktivním skóre Plus-Minus. Velký počet průzkumů tedy nemusí nutně vést k vysoké kvalitě průzkumů a prediktivní síle
.