




Brudte pakker: IP-fragmentering er mangelfuld
I modsætning til det offentlige telefonnet har internettet et Packet Switched-design. Men hvor store kan disse pakker egentlig være?
 CC BY 2.0-billede af ajmexico, inspireret af
CC BY 2.0-billede af ajmexico, inspireret af
Dette er et gammelt spørgsmål, og IPv4-RFC’erne besvarer det ret klart. Ideen var at opdele problemet i to separate problemer:
-
Hvad er den maksimale pakkestørrelse, der kan håndteres af styresystemer i begge ender?
-
Hvad er den maksimalt tilladte datagramstørrelse, der sikkert kan skubbes gennem de fysiske forbindelser mellem værterne?
Når en pakke er for stor til en fysisk forbindelse, kan en mellemliggende router hugge den op i flere mindre datagrammer for at få den til at passe. Denne proces kaldes “forward” IP-fragmentering, og de mindre datagrammer kaldes IP-fragmenter.
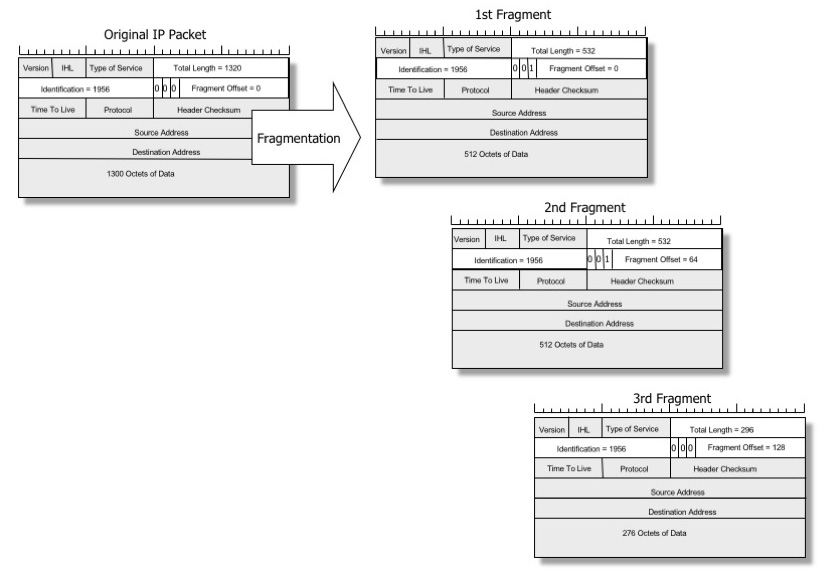 Billede af Geoff Huston, gengivet med tilladelse
Billede af Geoff Huston, gengivet med tilladelse
I IPv4-specifikationen defineres de minimale krav. Fra RFC791:
Every internet destination must be able to receive a datagramof 576 octets either in one piece or in fragments tobe reassembled. Every internet module must be able to forward a datagram of 68octets without further fragmentation. Den første værdi – tilladt reassembleret pakkestørrelse – er typisk ikke problematisk. IPv4 definerer minimumsværdien som 576 bytes, men populære operativsystemer kan klare meget store pakker, typisk op til 65KiB.
Den anden værdi er mere besværlig. Alle fysiske forbindelser har iboende datagramstørrelsesgrænser, afhængigt af det specifikke medie, de bruger. Frame Relay kan f.eks. sende datagrammer på mellem 46 og 4.470 bytes. ATM bruger faste 53 bytes, klassisk Ethernet kan klare mellem 64 og 1.500 bytes.
Specifikationen definerer det minimale krav – hver fysisk forbindelse skal kunne sende datagrammer på mindst 68 bytes. For IPv6 er denne minimumsværdi blevet hævet til 1280 bytes (se RFC2460).
Derimod er den maksimale datagramstørrelse, der kan transmitteres uden fragmentering, ikke defineret af nogen specifikation og varierer alt efter forbindelsestype. Denne værdi kaldes MTU (Maximum Transmission Unit).
MTU’en definerer en maksimal datagramstørrelse på et lokalt fysisk link. Internettet er skabt af ikke-homogene netværk, og på stien mellem to værter kan der være links med kortere MTU-værdier. Den maksimale pakkestørrelse, der kan sendes uden fragmentering mellem to fjernværter, kaldes en Path MTU og kan potentielt være forskellig for hver forbindelse.
Undgå fragmentering
Man kan tro, at det er fint nok at bygge programmer, der sender meget store pakker, og stole på routere til at udføre IP-fragmenteringen. Dette er dog ikke en god idé. Problemerne med denne fremgangsmåde blev første gang diskuteret af Kent og Mogul i 1987. Her er et par af højdepunkterne:
-
For at det skal lykkes at samle en pakke igen, skal alle fragmenter leveres. Ingen fragmenter kan blive korrupte eller gå tabt undervejs. Der er simpelthen ingen måde at underrette den anden part om manglende fragmenter!
-
Det sidste fragment vil næsten aldrig have den optimale størrelse. Ved store overførsler betyder det, at en betydelig del af trafikken vil bestå af suboptimale korte datagrammer – et spild af dyrebare routerressourcer.
-
For genassembleringen skal en vært have delvise, fragmenterede datagrammer i hukommelsen. Dette åbner mulighed for angreb på udtømning af hukommelsen.
-
Suafhængige fragmenter mangler headeren fra det højere lag. TCP- eller UDP-header er kun til stede i det første fragment. Dette gør det umuligt for firewalls at filtrere fragmentdatagrammer på baggrund af kriterier som kilde- eller destinationsporte.
En mere udførlig beskrivelse af IP-fragmenteringsproblemer kan findes i disse artikler af Geoff Huston:
- Evaluering af IPv4- og IPv6-pakkefragmentering
- Fragmentering af IPv6
Don’t fragmenting – ICMP Packet too big
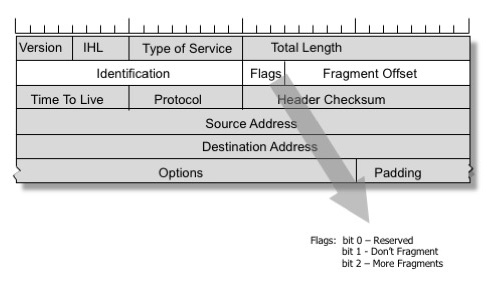
Billede af Geoff Huston, gengivet med tilladelse
En løsning på disse problemer blev indarbejdet i IPv4-protokollen. En afsender kan sætte DF-flaget (Don’t Fragment) i IP-headeren og bede mellemliggende routere om aldrig at foretage fragmentering af en pakke. I stedet vil en router med en forbindelse, der har en mindre MTU, sende en ICMP-meddelelse “bagud” og informere afsenderen om at reducere MTU’en for denne forbindelse.
TCP-protokollen sætter altid DF-flaget. Netværksstacken ser nøje efter indkommende “Packet too big”-ICMP-meddelelser og holder styr på “path MTU”-karakteristikken for hver forbindelse. Denne teknik kaldes “path MTU discovery”, og den er mest almindeligt anvendt til TCP, selv om den også kan anvendes på andre IP-baserede protokoller. At kunne levere ICMP-meddelelserne “Packet too big” er afgørende for, at TCP-stacken kan fungere optimalt.
Sådan fungerer internettet faktisk
I en perfekt verden ville internetforbundne enheder samarbejde og håndtere fragmenterede datagrammer og de tilhørende ICMP-pakker korrekt. I virkeligheden bliver IP-fragmenter og ICMP-pakker dog meget ofte filtreret fra.
Det skyldes, at det moderne internet er langt mere komplekst, end man forudså for 36 år siden. I dag er der stort set ingen, der er tilsluttet direkte til det offentlige internet.
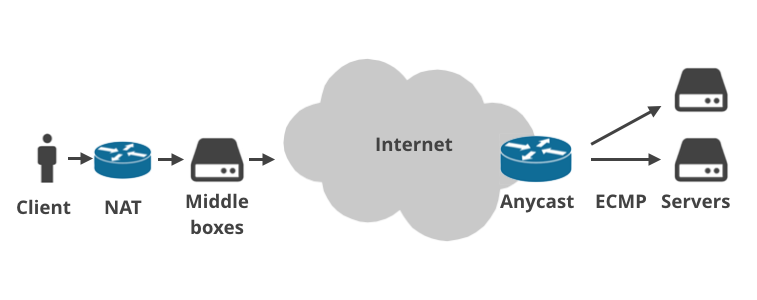
Kundernes enheder tilsluttes via routere i hjemmet, som udfører NAT (Network Address Translation) og normalt håndhæver firewallregler. I stigende grad er der mere og mere ofte mere end én NAT-installation på pakkestien (f.eks. carrier-grade NAT). Derefter rammer pakkerne ISP’s infrastruktur, hvor der findes ISP-“middle boxes”. De udfører alle mulige mærkelige ting med trafikken: håndhæver planlofter, drosler forbindelser, foretager logning, kaprer DNS-anmodninger, gennemfører forbud mod websteder pålagt af myndighederne, fremtvinger gennemsigtig caching eller “optimerer” trafikken på en anden magisk måde. Mellemkasserne bruges især af mobiltelefonselskaber.
Sådan er der ofte flere lag mellem en server og det offentlige internet. Tjenesteudbydere anvender undertiden Anycast BGP-routing. Det vil sige: de håndterer de samme IP-områder fra flere fysiske steder rundt om i verden. Inden for et datacenter er det på den anden side i stigende grad populært at bruge ECMP Equal Cost Multi Path til lastudligning.
Hvert af disse lag mellem en klient og en server kan forårsage et Path MTU-problem. Tillad mig at illustrere dette med fire scenarier.
1. Klient -> Server DF+ / ICMP
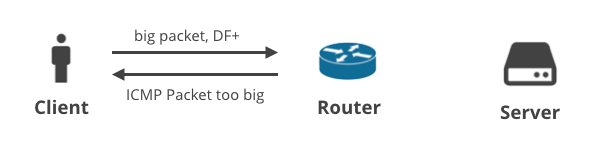
I det første scenarie uploader en klient nogle data til serveren ved hjælp af TCP, så DF-flaget er sat på alle pakkerne. Hvis klienten ikke formår at forudsige en passende MTU, vil en mellemliggende router droppe de store pakker og sende en ICMP-meddelelse “Packet too big” tilbage til klienten. Disse ICMP-pakker kan blive droppet af forkert konfigurerede NAT-enheder hos kunden eller ISP’s mellemkasser.
I henhold til et dokument af Maikel de Boer og Jeffrey Bosma fra 2012 blokerer omkring 5 % af IPv4-værterne og 1 % af IPv6-værterne indgående ICMP-pakker.
Mine erfaringer bekræfter dette. ICMP-meddelelser droppes faktisk ofte af hensyn til opfattede sikkerhedsfordele, men det er relativt let at rette op på. Et større problem er med visse mobile ISP’er med underlige mellemkasser. Disse ignorerer ofte ICMP fuldstændigt og udfører meget aggressivt connection rewriting. Orange Polska ignorerer f.eks. ikke blot indgående “Packet too big”-ICMP-meddelelser, men omskriver også forbindelsestilstanden og klemmer MSS’en til en ikke-negotiabel 1344 bytes.
2. Klient -> Server DF- / fragmentering
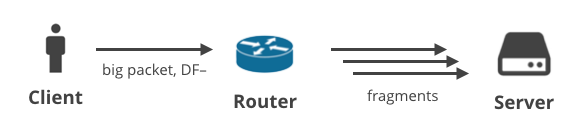
I næste scenarie uploader en klient nogle data med en anden protokol end TCP, som har DF-flaget slået fra. Det kan f.eks. være en bruger, der spiller et spil ved hjælp af UDP, eller som har et taleopkald. De store udgående pakker kan blive fragmenteret på et tidspunkt i stien.
Vi kan emulere dette ved at starte ping med en stor payload-størrelse:
$ ping -s 2048 facebook.comDenne særlige ping vil fejle med payloads, der er større end 1472 bytes. Enhver større størrelse vil blive fragmenteret og vil ikke blive leveret korrekt. Der er flere grunde til, at servere kan håndtere fragmenter forkert, men et af de populære problemer er brugen af ECMP-belastningsudligning. På grund af ECMP-hashingen vil det første datagram, der indeholder en protokolhoveddetalje, sandsynligvis blive belastningsbalanceret til en anden server end resten af fragmenterne, hvilket forhindrer reassembleringen.
For en mere detaljeret diskussion af dette problem, se:
- Vores tidligere skrivning om ECMP.
- Hvordan Google forsøger at løse ECMP-fragmenteringsproblemer med Maglev L4 Load Balancer.
Dertil kommer, at server- og routerfejlkonfiguration er et væsentligt problem. Ifølge RFC7852 dropper mellem 30 % og 55 % af serverne IPv6-datagrammer, der indeholder fragmenteringsheader.
3. Server -> Client DF+ / ICMP
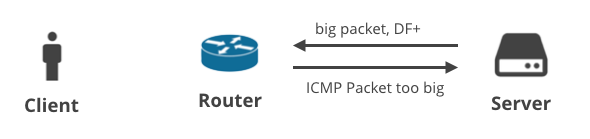
Det næste scenarie handler om en klient, der downloader nogle data over TCP. Når serveren ikke kan forudsige den korrekte MTU, skal den modtage en ICMP-meddelelse “Packet too big” (pakke for stor). Det er nemt, ikke sandt?
Det er det desværre ikke, igen på grund af ECMP-routing. ICMP-meddelelsen vil højst sandsynligt blive leveret til den forkerte server – ICMP-pakkens 5-tuple hash vil ikke stemme overens med 5-tuple hash’en for den problematiske forbindelse. Vi har tidligere skrevet om dette og udviklet en simpel userspace-dæmon til at løse det. Den fungerer ved at udsende den indgående ICMP-meddelelse “Packet too big” til alle ECMP-servere i håb om, at den med den problematiske forbindelse vil se den.
Dertil kommer, at ICMP-meddelelsen på grund af Anycast-routing kan blive leveret til det helt forkerte datacenter! Internet-routing er ofte asymmetrisk, og den bedste vej fra en mellemliggende router kan lede ICMP-pakkerne til det forkerte sted.
Manglende ICMP-meddelelser om “Packet too big” kan resultere i, at forbindelserne går i stå og går i stå. Dette kaldes ofte et PMTU-blackhole. For at hjælpe dette pessimistiske tilfælde implementerer Linux en workaround – MTU Probing RFC4821. MTU Probing forsøger automatisk at identificere pakker, der tabes på grund af den forkerte MTU, og bruger heuristik til at justere den. Denne funktion styres via en sysctl:
$ echo 1 > /proc/sys/net/ipv4/tcp_mtu_probingMen MTU probing er ikke uden sine egne problemer. For det første har den en tendens til at fejlkategorisere overbelastningsrelateret pakketab som MTU-problemer. Forbindelser, der kører længe, har en tendens til at ende med en reduceret MTU. For det andet implementerer Linux ikke MTU Probing for IPv6.
4. Server -> Client DF- / fragmentering
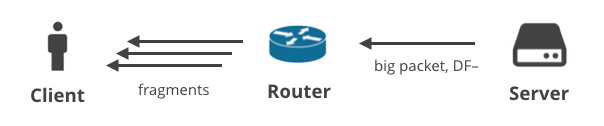
Endelig er der en situation, hvor serveren sender store pakker ved hjælp af en ikke-TCP-protokol med DF-bitten klar. I dette scenario vil de store pakker blive fragmenteret på vejen til klienten. Denne situation kan bedst illustreres med store DNS-svar. Her er to DNS-anmodninger, der vil generere store svar og blive leveret til klienten som flere IP-fragmenter:
$ dig +notcp +dnssec DNSKEY org @199.19.56.1$ dig +notcp +dnssec DNSKEY org @2001:500:f::1Disse anmodninger kan mislykkes på grund af allerede nævnte forkert konfigurerede hjemme-routere, ødelagt NAT, ødelagte ISP-installationer eller for restriktive firewall-indstillinger.
I henhold til Boer og Bosma blokerer ca. 6 % af IPv4-værterne og 10 % af IPv6-værterne indgående fragmentdatagrammer.
Her er nogle links med flere oplysninger om de specifikke fragmenteringsproblemer, der påvirker DNS:
- DNS-OARC Reply Size Test
- IPv6, store UDP-pakker og DNS
Men internettet virker stadig!
Med alle disse ting, der går galt, hvordan kan internettet så stadig fungere?
 CC BY-SA 3.0, kilde: Wikipedia
CC BY-SA 3.0, kilde: Wikipedia
Dette skyldes primært Ethernet’s succes. Langt størstedelen af forbindelserne på det offentlige internet er Ethernet (eller afledt heraf) og understøtter MTU’en på 1500 bytes.
Hvis du blindt antager MTU’en på 1500, vil du blive overrasket over, hvor ofte det fungerer helt fint. Internettet bliver ved med at fungere, hovedsagelig fordi vi alle bruger en MTU på 1500 og sjældent har brug for at foretage IP-fragmentering og sende ICMP-meddelelser.
Dette holder op med at fungere på en usædvanlig opsætning med links, der har en ikke-standardiseret MTU. VPN’er og anden netværkstunnelsoftware skal være omhyggelig med at sikre, at fragmenteringerne og ICMP-meddelelserne fungerer fint.
Dette er især synligt i IPv6-verdenen, hvor mange brugere opretter forbindelse via tunneler. Det er meget vigtigt at have en sund passage af ICMP i begge retninger, især fordi fragmentering i IPv6 stort set ikke fungerer (vi citerede to kilder, der hævder, at mellem 10 % og 50 % af IPv6-værterne blokerer IPv6 Fragment header).
Da Path MTU-problemerne i IPv6 er så almindelige, klemmer mange IPv6-servere Path MTU ned til det protokolmandaterede minimum på 1280 bytes. Denne fremgangsmåde giver en smule ydelse til gengæld for den bedste pålidelighed.
Online ICMP blackhole checker
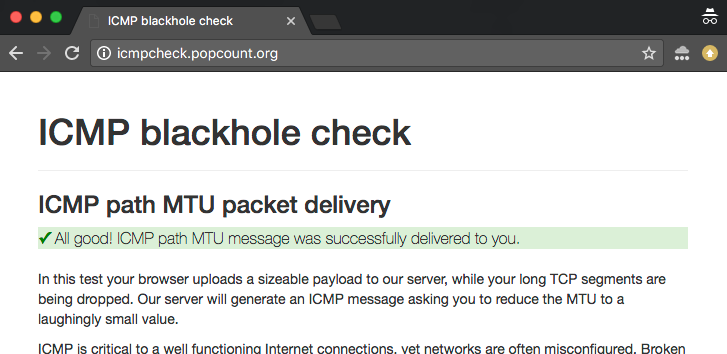
For at hjælpe med at udforske og fejlfinde disse problemer har vi bygget en online-checker. Du kan finde to versioner af testen:
- IPv4-version: http://icmpcheck.popcount.org
- IPv6-version: http://icmpcheck.popcount.org
- IPv6-version: http://icmpcheckv6.popcount.org
- Den første test sender ICMP-meddelelser til din computer med det formål at reducere Path MTU til en latterligt lille værdi.
- Den anden test sender fragmentdatagrammer tilbage til dig.
Disse websteder starter to tests:
Det at modtage et “bestået” i begge disse tests burde give dig en rimelig sikkerhed for, at internettet på din side af kablet opfører sig godt.
Det er også nemt at køre testene fra kommandolinjen, hvis du vil køre det på serveren:
perl -e "print 'packettoolongyaithuji6reeNab4XahChaeRah1diej4' x 180" > payload.bincurl -v -s http://icmpcheck.popcount.org/icmp --data @payload.bincurl -v -s http://icmpcheckv6.popcount.org/icmp --data @payload.binDette burde reducere Path MTU til vores server til 905 bytes. Du kan verificere dette ved at kigge i routing-cachetabellen. På Linux gør du dette med:
ip route get `dig +short icmpcheck.popcount.org`Det er muligt at rydde routing-cachen på Linux:
ip route flush cache to `dig +short icmpcheck.popcount.org`Den anden test verificerer, om fragmenter leveres korrekt til klienten:
curl -v -s http://icmpcheck.popcount.org/frag -o /dev/nullcurl -v -s http://icmpcheckv6.popcount.org/frag -o /dev/nullSummary
I dette blogindlæg beskrev vi problemerne med at registrere Path MTU-værdier på internettet. ICMP- og fragmentdatagrammer er ofte blokeret på begge sider af forbindelserne. Klienter kan støde på fejlkonfigurerede firewalls, NAT-enheder eller bruge internetudbydere, som aggressivt opsnapper forbindelser. Klienter bruger også ofte VPN’er eller IPv6-tunneler, som, hvis de er fejlkonfigureret, kan forårsage path MTU-problemer.
Servere på den anden side er på den anden side i stigende grad ofte afhængige af Anycast eller ECMP. Begge disse ting samt fejlkonfigurering af routere og firewalls er ofte årsag til, at ICMP- og fragmentdatagrammer tabes.
Slutteligt håber vi, at onlinetesten er nyttig og kan give dig mere indsigt i det indre arbejde i dine netværk. Testen har nyttige eksempler på tcpdump-syntaks, der er nyttige for at få mere indsigt. God fornøjelse med netværksfejlsøgning!
Er det spændende at løse fragmenteringsproblemer for 10 % af internettet? Vi ansætter systemingeniører af alle slags, Golang-programmører, C wranglers og praktikanter flere steder! Kom med os i San Francisco, London, Austin, Austin, Champaign og Warszawa.
-
I IPv6 fungerer “forward”-fragmenteringen en smule anderledes end i IPv4. De mellemliggende routere er forbudt at fragmentere pakkerne, men kilden kan stadig gøre det. Dette er ofte forvirrende – en vært kan blive bedt om at fragmentere en pakke, som den tidligere har sendt. Dette giver ikke meget mening for stateless-protokoller som DNS. ︎
-
Og som en sidebemærkning findes der også en “minimum transmissionsenhed”! I den almindeligt anvendte Ethernet-ramning skal hvert transmitteret datagram have mindst 64 bytes på lag 2. Dette svarer til 22 bytes på UDP og 10 bytes på TCP-laget. Flere implementeringer har brugt til at lække uinitialiseret hukommelse på kortere pakker! ︎
-
Strictly speaking in IPv4 the ICMP packet is named “Destination Unreachable, Fragmentation Needed and Don’t Fragmentation was Set”. Men jeg synes, at IPv6 ICMP-fejlbeskrivelsen “Packet too big” er meget klarere. ︎
-
Som et hint indeholder TCP-stakken også en maksimalt tilladt “MSS”-værdi i SYN-pakker (MSS er grundlæggende en MTU-værdi reduceret med størrelsen af IP- og TCP-headere). Dette giver værterne mulighed for at vide, hvad MTU’en på deres forbindelser er. Bemærk: dette siger ikke, hvad MTU’en er på de mange internetforbindelser mellem de to værter! ︎
-
Lad os gå på den sikre side. En bedre MTU er 1492, for at tage højde for DSL- og PPPoE-forbindelser. ︎