




Enterprise Data Warehouse: Koncepter og arkitektur Koncepter, arkitektur og komponenter
Læsetid: 12 minutter
I løbet af dagen træffer vi mange beslutninger på baggrund af tidligere erfaringer. Vores hjerne lagrer trillioner af bits af data om tidligere begivenheder og udnytter disse erindringer, hver gang vi står over for behovet for at træffe en beslutning. Ligesom mennesker genererer og indsamler virksomheder tonsvis af data om fortiden. Og disse data kan bruges til at træffe bedre beslutninger.
Mens vores hjerne både tjener til at behandle og lagre data, har virksomheder brug for flere værktøjer til at arbejde med data. Og et af de vigtigste er et datawarehouse.
I denne artikel vil vi diskutere, hvad et enterprise data warehouse er, dets typer og funktioner, og hvordan det bruges i databehandling. Vi vil definere, hvordan enterprise warehouses adskiller sig fra de sædvanlige warehouses, hvilke typer datawarehouses der findes, og hvordan de fungerer. Fokus er at give information om den forretningsmæssige værdi af hver arkitektonisk og konceptuel tilgang til opbygning af et warehouse.
Hvad er et Enterprise Data Warehouse?
Hvis du ved, hvad terabyte er, vil du sikkert blive imponeret over, at Netflix havde omkring 44 terabyte data i sit warehouse tilbage i 2016. Alene størrelsen antyder, hvorfor vi kalder det et warehouse i stedet for blot en database. Så lad os begynde med det grundlæggende.
Et Enterprise Data Warehouse (EDW) er en form for virksomhedens repository, der gemmer og administrerer alle historiske forretningsdata i en virksomhed. Oplysningerne kommer normalt fra forskellige systemer som ERP-systemer, CRM-systemer, fysiske optegnelser og andre flade filer. For at forberede data til yderligere analyse skal de placeres i et enkelt lager. På den måde kan forskellige forretningsenheder forespørge på det og analysere oplysninger fra flere vinkler.
Med et datawarehouse kan en virksomhed administrere store datasæt uden at skulle administrere flere databaser. En sådan praksis er en fremtidssikret måde at lagre data til business intelligence (BI), som er et sæt metoder/teknologier til at omdanne rådata til brugbar indsigt. Med EDW som en vigtig del af det, svarer systemet til en menneskelig hjerne, der lagrer information, men på steroider.
Enterprise data warehouse vs. sædvanligt data warehouse: hvad er forskellen?
Et data warehouse er en database, der altid er forbundet med rådatakilder via dataintegrationsværktøjer i den ene ende og analytiske grænseflader i den anden ende. Hvis det er tilfældet, hvorfor isolerer vi så virksomhedsformen til diskussion?
Et hvilket som helst warehouse tilbyder lagring, der har mekanismer til at transformere data, flytte dem og præsentere dem for slutbrugeren. Forskellen mellem et almindeligt datawarehouse og et enterprise warehouse ligger i dets langt større arkitektoniske mangfoldighed og funktionalitet. På grund af den komplekse struktur og størrelse er EDW’er ofte dekomponeret i mindre databaser, så slutbrugerne er mere trygge ved at spørge i disse mindre databaser. I betragtning af dette fokuserer vi på et enterprise warehouse for at dække hele spektret af funktionalitet.
Men størrelsen af et warehouse definerer ikke dets tekniske kompleksitet, kravene til analytiske og rapporteringsmuligheder, antallet af datamodeller og selve dataene. Så for at forstå, hvad der gør et warehouse til et warehouse, skal vi dykke ned i dets kernekoncepter og funktionalitet.
Enterprise Data Warehouse koncepter og funktioner
Med alle klokker og fløjter, ligger der i hjertet af ethvert warehouse grundlæggende koncepter og funktioner. Disse søjler definerer et warehouse som et teknologisk fænomen:
Der tjener som den ultimative lagring. Et virksomhedsdatawarehouse er et samlet lager for alle virksomhedens forretningsdata, der nogensinde forekommer i organisationen.
Reflekterer kildedataene. EDW kilder data fra sine oprindelige lagerpladser som Google Analytics, CRM’er, IoT-enheder osv. Hvis dataene er spredt ud over flere systemer, er det uhåndterbart. Så formålet med EDW er at give ligheden af de oprindelige kildedata i et enkelt lager. Da der altid genereres nye, relevante data både inden for og uden for virksomheden, kræver datastrømmen en dedikeret infrastruktur til at håndtere den, før den kommer ind i et warehouse.
Lagerer strukturerede data. De data, der lagres i et EDW, er altid standardiserede og strukturerede. Dette gør det muligt for slutbrugerne at forespørge på dem via BI-grænseflader og udforme rapporter. Og det er det, der adskiller et datawarehouse fra en datasø. Data lakes bruges til at lagre ustrukturerede data til analytiske formål. Men i modsætning til warehouses bruges data lakes mere af datateknikere/forskere til at arbejde med store sæt af rå data.
Subjektorienterede data. Hovedfokus i et warehouse er forretningsdata, der kan vedrøre forskellige domæner. For at forstå, hvad dataene relaterer sig til, er de altid struktureret omkring et specifikt emne kaldet en datamodel. Et eksempel på et emne kan være et salgsområde eller det samlede salg af en given vare. Derudover tilføjes metadata for at forklare i detaljer, hvor hver enkelt oplysning kommer fra.
Tidsafhængig. De indsamlede data er normalt historiske data, fordi de beskriver tidligere begivenheder. For at forstå, hvornår og hvor længe en bestemt tendens har fundet sted, er de fleste lagrede data normalt opdelt i tidsperioder.
Nonvolatile. Når først dataene er placeret i et lager, slettes de aldrig fra det. Dataene kan manipuleres, ændres eller opdateres på grund af kildeændringer, men det er aldrig meningen, at de skal slettes, i hvert fald ikke af slutbrugerne. Når vi taler om historiske data, er sletninger kontraproduktivt for analytiske formål. Alligevel kan der ske generelle revisioner en gang om året for at slippe af med irrelevante data.
Med tanke på grundprincipperne vil vi se på implementeringstyperne af DW’er.
Data warehouse-typer
Med tanke på EDW-funktioner er der altid plads til diskussion om, hvordan det skal udformes teknisk. I tilfælde af datalagring og databehandling er de specifikke og forskellige for forskellige typer virksomheder. Afhængigt af mængden af data, analytisk kompleksitet, sikkerhedsspørgsmål og budget er der naturligvis altid en mulighed for, hvordan systemet skal indrettes.
Klassisk datawarehouse
En samlet lagring, der har sin dedikerede hardware og software, betragtes som en klassisk variant for et EDW. Med fysisk lagring behøver du ikke at opsætte dataintegrationsværktøjer mellem flere databaser. I stedet kan EDW’et forbindes med datakilder via API’er for konstant at hente oplysninger og transformere dem i processen. Så alt arbejdet udføres enten i staging-området (det sted, hvor dataene transformeres, inden de indlæses i DW’et) eller i selve lageret.
Et klassisk datawarehouse anses for at være superlativ til et virtuelt (som vi diskuterer nedenfor), fordi der ikke er noget ekstra abstraktionslag. Det forenkler arbejdet for datateknikere og gør det lettere at styre datastrømmen på forbehandlingssiden samt den egentlige rapportering. Ulemperne ved det klassiske warehouse afhænger af den konkrete implementering, men for de fleste virksomheder er disse:
- Dyr teknologisk infrastruktur, både hardware og software;
- Hyr et team af datateknikere og DevOps-specialister til at opsætte og vedligeholde hele dataplatformen.
Hvornår skal man bruge: Egnet til organisationer af alle størrelser, der ønsker at behandle deres data og gøre brug af dem. Klassiske warehouses giver mulighed for at morfe ind i forskellige arkitektoniske stilarter af dataplatformen, samt at skalere op og ned med vilje.
Virtuelt datawarehouse
Et virtuelt datawarehouse er en type EDW, der anvendes som et alternativ til et klassisk warehouse. I bund og grund er der tale om flere databaser, der er forbundet virtuelt, så de kan forespørges som et enkelt system.
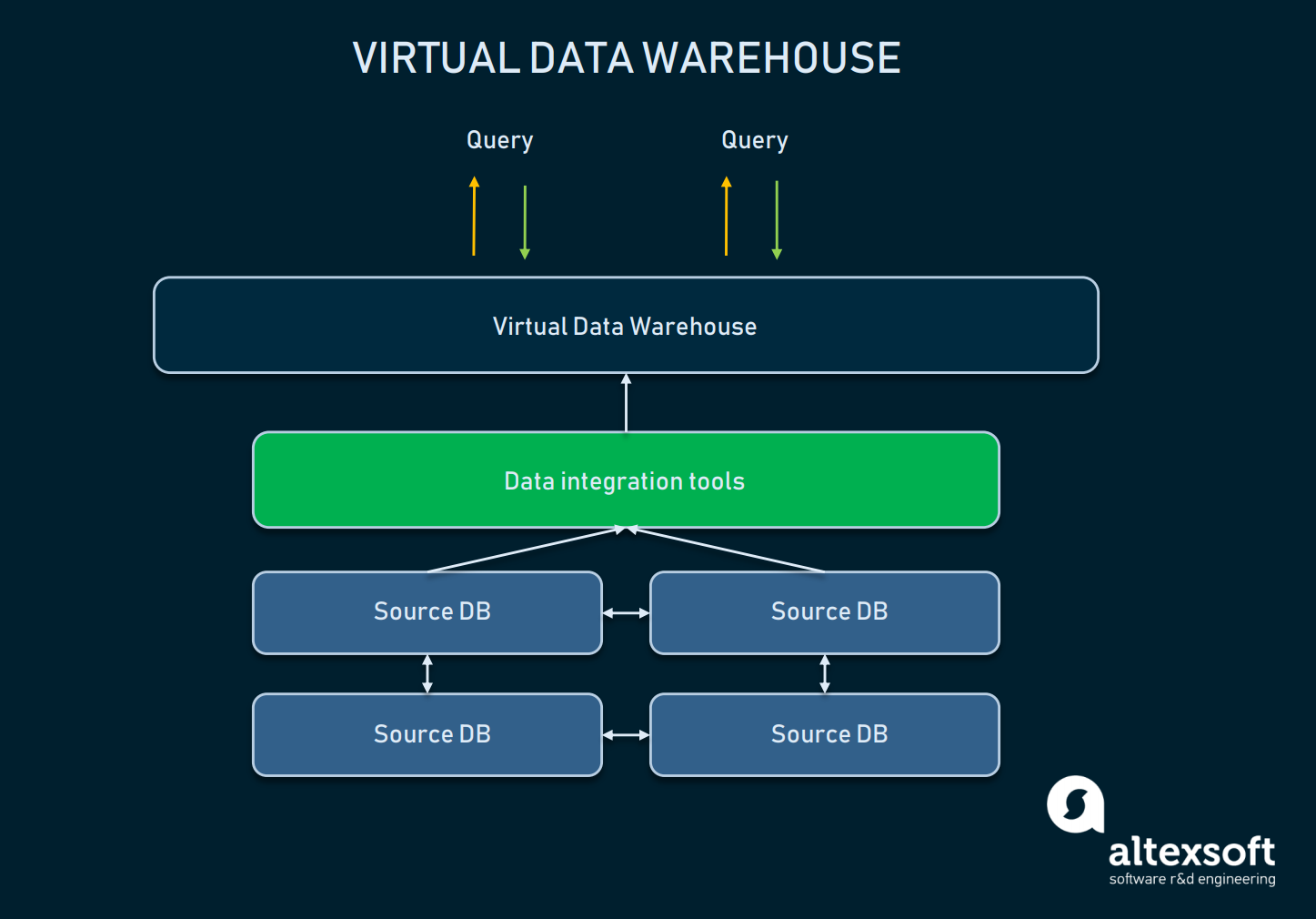
En ordning med relationer mellem abstraktionen af virtuelle DW og kildedatabaser
En sådan tilgang giver organisationer mulighed for at holde det simpelt: Dataene kan forblive i deres kilder, men kan stadig trækkes ved hjælp af analytiske værktøjer. Virtuelle warehouses kan bruges, hvis man ikke ønsker at rode med al den underliggende infrastruktur, eller hvis de data, man har, er let håndterbare som de er. En sådan tilgang har dog mange ulemper:
- Flere databaser vil kræve konstant software- og hardwarevedligeholdelse og omkostninger.
- Dataene, der er gemt i et virtuelt DW, kræver stadig en transformationssoftware for at gøre dem fordøjelige for slutbrugerne og rapporteringsværktøjerne.
- Komplekse dataforespørgsler kan tage for lang tid, da de nødvendige data kan være placeret i to separate databaser.
Hvornår skal man bruge: Velegnet til virksomheder, der har rå data i en standardiseret form, som ikke kræver komplekse analyser. Det passer også til organisationer, der ikke bruger BI systematisk, eller som ønsker at starte med det.
Cloud Data Warehouse
I et årti er cloud/cloudless-teknologier blevet mere af en standard for opsætning af teknologier på organisationsniveau. Du finder utallige udbydere på markedet, der tilbyder warehousing-as-a-service. For at nævne et par stykker:
- Amazon Redshift/ Prisside
- IBM Db2/ Prisside
- Google BigQuery/ Prisside
- Snowflake/ Prisside
- Microsoft SQL Data Warehouse/ Prisside
Alle de nævnte udbydere tilbyder fuldt administreret, skalerbar warehousing som en del af deres BI-værktøjer eller fokuserer på EDW som en selvstændig tjeneste, ligesom Snowflake gør. I dette tilfælde har cloud warehouse-arkitekturen de samme fordele som enhver anden cloud-tjeneste. Dens infrastruktur vedligeholdes for dig, hvilket betyder, at du ikke behøver at opsætte dine egne servere, databaser og værktøjer til at administrere den. Prisen for en sådan tjeneste vil afhænge af mængden af den nødvendige hukommelse og mængden af computerkapaciteter til forespørgsler.
Det eneste aspekt, som du måske er bekymret for i forbindelse med en cloud warehouse-platform, er datasikkerhed. Dine virksomhedsdata er en følsom ting. Så du ønsker at kontrollere, om den leverandør, du har valgt, kan have tillid til, at der ikke sker brud. Det betyder ikke nødvendigvis, at et on-premise warehouse er mere sikkert, men i dette tilfælde er sikkerheden for dine data i dine hænder.
Hvornår skal du bruge: Cloud-platforme er et godt valg for organisationer af enhver størrelse. Hvis du har brug for alt, der er sat op for dig, herunder administreret dataintegration, DW-vedligeholdelse og BI-support.
Enterprise Data Warehouse Architecture
Selv om der er mange arkitektoniske tilgange, der udvider lagerkapaciteterne på den ene eller anden måde, vil vi fokusere på de mest væsentlige. Uden at dykke ned i for mange tekniske detaljer kan hele datapipelinen opdeles i tre lag:
- Rådatalag (datakilder)
- Warehouse og dets økosystem
- Brugergrænseflade (analytiske værktøjer)
Værktøjet, der vedrører udtrækning, transformation og indlæsning af data i et warehouse, er en særskilt kategori af værktøjer, der kaldes ETL. Under ETL-paraplyen udfører dataintegrationsværktøjer også manipulationer med data, før de placeres i et lager. Disse værktøjer opererer mellem et rå datalag og et lager.
Når dataene er indlæst i et lager, kan de også transformeres. Så lageret vil kræve en vis funktionalitet til rensning/standardisering/dimensionalisering. Disse og andre faktorer vil bestemme arkitekturens kompleksitet. Vi vil se på EDW-arkitekturen ud fra voksende organisatoriske behov.
One-tier arkitektur
Givet at dataintegration er velkonfigureret, kan vi vælge vores datawarehouse. I de fleste tilfælde er et datawarehouse en relationel database med moduler, der tillader flerdimensionale data, eller en database, der kan adskille nogle domænespecifikke oplysninger for at lette adgangen. I sin mest primitive form kan warehousing kun have en one-tier-arkitektur.
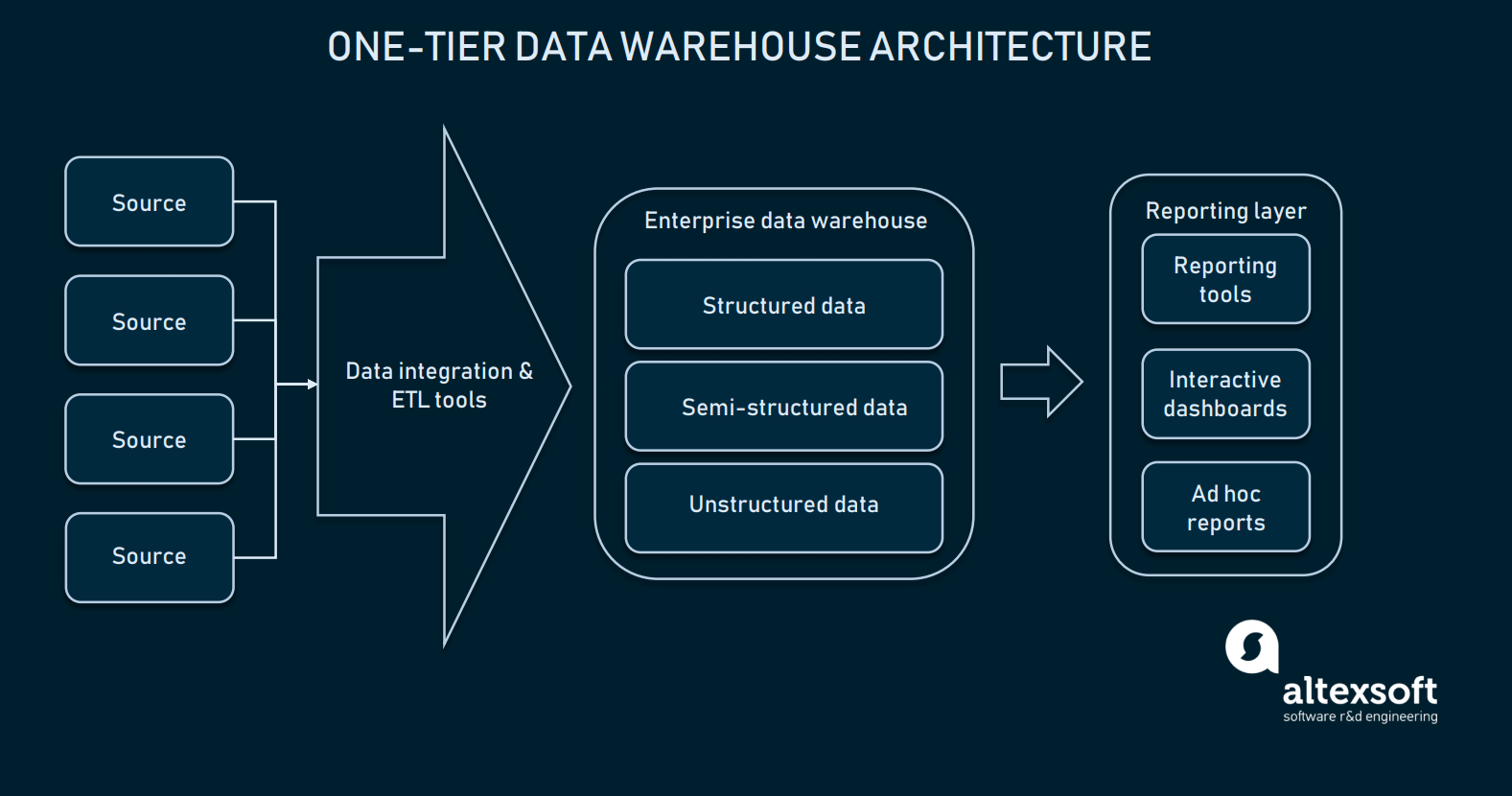
Rapporteringslaget er direkte forbundet med hele databasen i EDW
En one-tier-arkitektur for EDW betyder, at man har en database direkte forbundet med de analytiske grænseflader, hvor slutbrugeren kan lave forespørgsler. Indstilling af den direkte forbindelse mellem en EDW og analytiske værktøjer medfører flere udfordringer:
- Traditionelt set kan du betragte dit lager som et warehouse fra 100 GB data. Hvis du arbejder direkte med det, kan det resultere i rodede forespørgselsresultater samt lav behandlingshastighed.
- Søgning af data direkte fra DW kan kræve præcis indtastning, så systemet vil være i stand til at filtrere ikke-efterspurgte data fra. Hvilket gør det lidt vanskeligt at håndtere præsentationsværktøjer.
- Der findes begrænset fleksibilitet/analytiske muligheder.
Dertil kommer, at one-tier-arkitekturen sætter nogle grænser for rapporteringskompleksiteten. En sådan tilgang anvendes sjældent til store dataplatforme på grund af dens langsommelighed og uforudsigelighed. For at udføre avancerede dataforespørgsler kan et warehouse udvides med instanser på lavt niveau, der gør adgangen til data lettere.
Two-tier arkitektur (data mart lag)
I two-tier arkitektur tilføjes et data mart niveau mellem brugergrænsefladen og EDW. Et datamart er et lager på lavt niveau, der indeholder domænespecifikke oplysninger. Kort sagt er det en anden database i mindre størrelse, der udvider EDW med dedikerede oplysninger til dine salgs-/operative afdelinger, markedsføring osv.
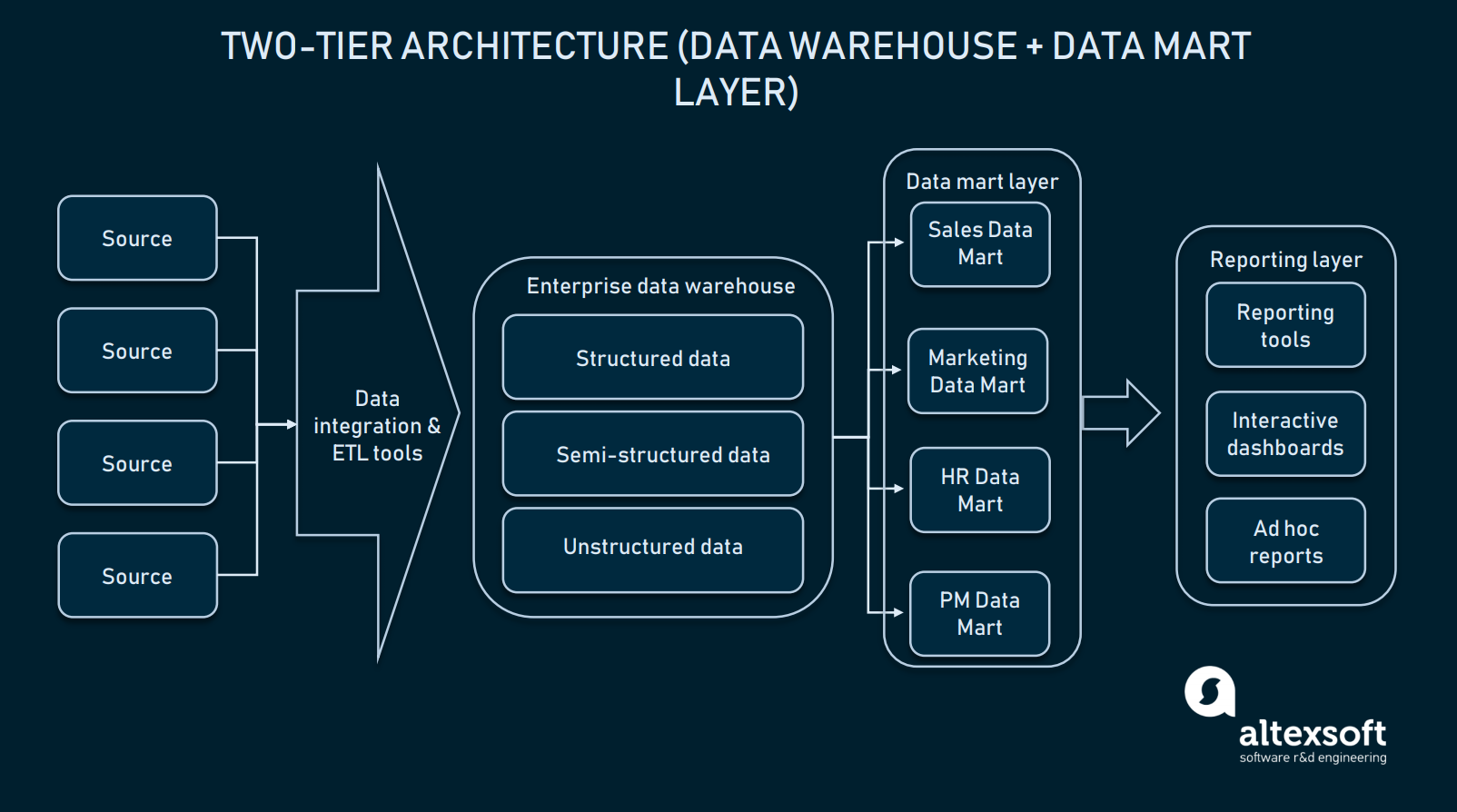
I en tostrenget arkitektur udvides en EDW med datamarts for at levere domænespecifikke data
Skabelsen af datamartlaget vil kræve yderligere ressourcer til etablering af hardware og integration af disse databaser med resten af dataplatformen. Men en sådan tilgang løser problemet med forespørgsler: De enkelte afdelinger får lettere adgang til de nødvendige data, fordi en given mart kun vil indeholde domænespecifikke oplysninger. Desuden vil datamarts begrænse slutbrugernes adgang til data, hvilket gør EDW mere sikker.
Tre-lags arkitektur (Online analytical processing)
Oven på datamartlaget bruger virksomhederne også online analytical processing (OLAP) cubes. En OLAP-kube er en særlig type database, der repræsenterer data fra flere dimensioner. Mens relationelle databaser kun repræsenterer data i to dimensioner (tænk på Excel eller Google Sheets), giver OLAP mulighed for at samle data i flere dimensioner og flytte mellem dimensioner.
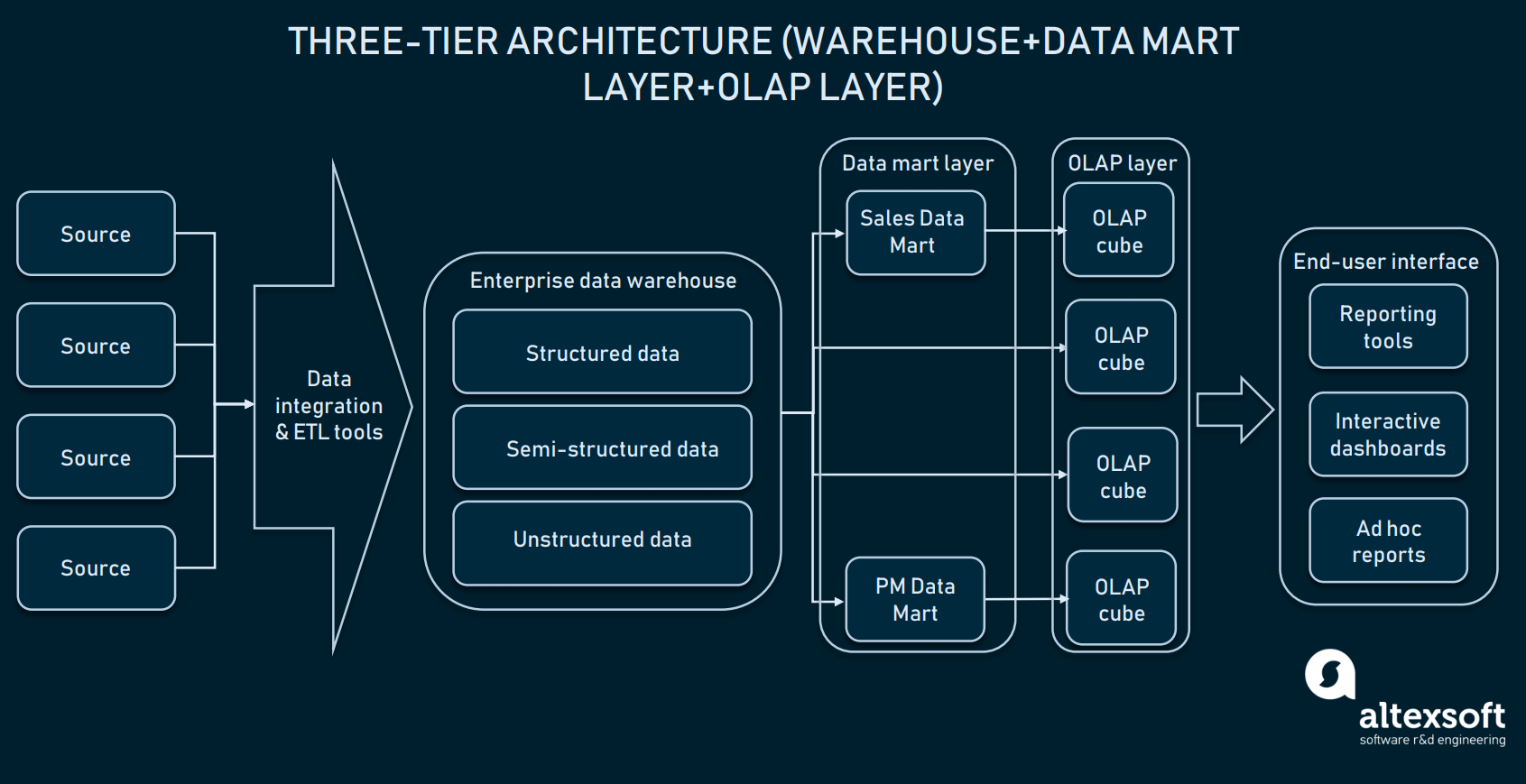
OLAP-cubes lag kan hente oplysninger fra distribuerede marts eller direkte fra EDW
Det er ret svært at forklare med ord, så lad os se på dette praktiske eksempel på, hvordan en cube kan se ud.
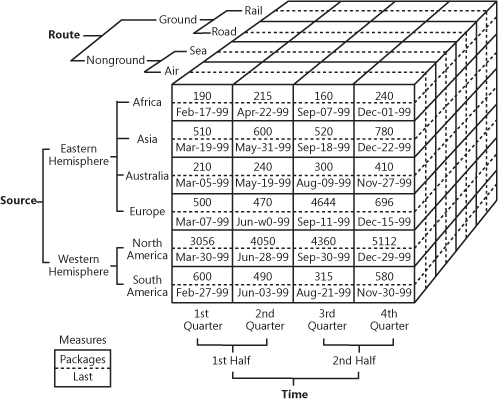
OLAP-kube, der viser flerdimensionale salgsdata
Kilde: oreilly.com
Så, som du kan se, tilføjer en kube dimensioner til dataene. Du kan tænke på det som flere Excel-tabeller, der kombineres med hinanden. Den forreste del af kuben er den sædvanlige todimensionelle tabel, hvor region (Afrika, Asien osv.) er angivet lodret, mens salgstal og datoer er skrevet vandret. Magien begynder, når vi ser på den øverste facet af kuben, hvor salget er segmenteret efter ruter, og hvor den nederste angiver tidsperiode. Det er kendt som multidimensionale data.
Den forretningsmæssige værdi af OLAP er, at det giver brugerne mulighed for at skære dataene ud i tern for at udarbejde detaljerede rapporter. Så længe cubes er optimeret til at arbejde med warehouses, kan de bruges både direkte med en EDW for at give adgang til alle virksomhedens data eller med hver enkelt data mart specifikt. Med hensyn til implementering tilbyder næsten alle warehouse-udbydere OLAP som en service. Som et eksempel kan man se Microsofts dokumentation om deres OLAP-tilbud.
På dette punkt har vi diskuteret et design på højt niveau af en EDW anvendt på organisatoriske behov. Nu vil vi bore ned i de tekniske komponenter, som et lager kan omfatte.
Data Warehouse vs Data Lake vs Data Mart
Når vi taler om datalagringsarkitektur, er vi nødt til at nævne sådanne muligheder som at bruge et data mart eller en data lake i stedet for et warehouse. Ofte blandes de sammen, og vi vil derfor uddybe definitionerne.
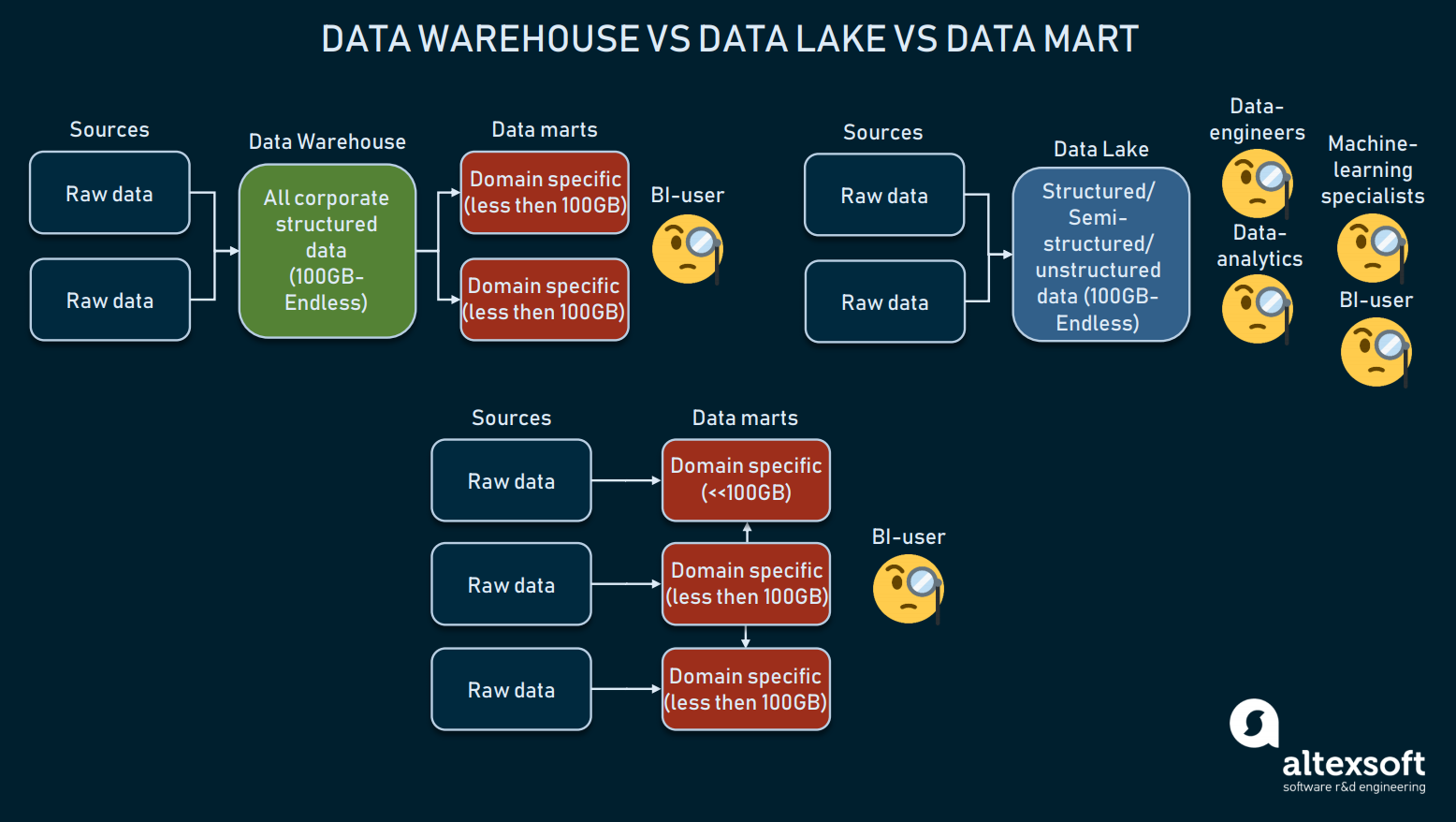
Sammenligning af tre datalagringsformer
Datawarehouses er beregnet til at lagre strukturerede data, så forespørgselsværktøjer og slutbrugere kan få omfattende resultater. Warehouses, der hovedsagelig anvendes til BI, varierer normalt i størrelse mellem 100 GB og uendeligt.
Data lakes anvendes derimod til at lagre hovedsagelig rå eller blandede data. Disse udnyttes ofte til maskinlæring, big data eller data mining-formål. I de sidste par år er datasøer blevet brugt til BI: Rå data indlæses i en sø og transformeres, hvilket er et alternativ til ETL-processen. Selv om denne tilgang har sine fordele og ulemper, kan datasøer være for rodet til at nå strukturerede data.
Så har vi data marts, som også kan bruges som et alternativ til DW. Sådanne modeller (som Kimballs model) forudsætter, at man bruger flere datamarts til at distribuere oplysninger efter domæner og forbinde dem med hinanden. Men på grund af deres lille størrelse (normalt mindre end 100 GB) kan datamarts næppe anvendes af virksomheder. Oftere bruges data marts til at segmentere et stort DW i mere driftsklare DW’er.
Enterprise Data Warehouse Components
Der er mange instrumenter, der bruges til at oprette en warehousing-platform. Vi vil allerede have nævnt de fleste af dem, herunder et warehouse selv. Så lad os få et fugleperspektiv på formålet med de enkelte komponenter og deres funktioner.
Kilder. Det er ganske enkelt databaserne, hvor de rå data er gemt.
Extract, Transform, Load (ETL) eller Extract, Load, Transform (ELT)-lag. Det er de værktøjer, der udfører den faktiske forbindelse med kildedata, deres udtrækning og indlæsning til det sted, hvor de vil blive transformeret. Transformation ensretter dataformatet. ETL- og ELT-tiltag adskiller sig fra hinanden ved, at transformationen i ETL sker før EDW i et stagingområde. ELT er en mere moderne tilgang, som håndterer hele transformationen i et lager.
Staging area. I tilfælde af ETL er staging-området det sted, hvor data indlæses før EDW. Her bliver de renset og transformeret til en given datamodel. Staging-området kan også omfatte værktøj til datakvalitetsstyring.
DW-database. Dataene indlæses til sidst i lagerpladsen. I ELT kan det stadig kræve en vis transformation her. Men på dette stadium vil alle de generelle ændringer blive anvendt, så dataene vil blive indlæst i deres endelige model(er). Som vi nævnte, er datawarehouses oftest relationelle databaser. DW vil også omfatte et databasestyringssystem og yderligere lagring af metadata.
Metadatamodul. Kort sagt er metadata data om data. Det er de forklaringer, der giver brugerne/administratorerne fingerpeg om, hvilket emne/domæne disse oplysninger vedrører. Disse data kan være teknisk meta (f.eks. oprindelig kilde) eller forretningsmeta (f.eks. salgsregion). Alle metadata lagres i et separat modul i EDW og forvaltes af en metadata manager.
Rapporteringslag. Det er værktøjer, der giver slutbrugerne adgang til data. Dette lag, der også kaldes BI-interface, vil fungere som et dashboard til at visualisere data, danne rapporter og trække separate stykker information.
Sluttanke
Forståelse af kæden af værktøjer, der sender data videre, kan hjælpe dig med at finde ud af, hvad der rent faktisk passer til dine krav til dataplatformen. Planlægning af at oprette et lager kan tage flere års planlægning og testning på grund af omfanget i den mest grundlæggende form.
Som virksomhedsejer kan du måske blive forvirret over antallet af muligheder og teknologier, der anvendes, så det er vigtigt at rådføre dig med eksperter inden for warehousing, ETL og BI. Mens eksperterne kan hjælpe dig med det tekniske aspekt, skal du for at definere forretningsformålet tale med dem, der skal bruge de faktiske data i deres arbejde.