




SQL Magazine 7-artikel – SQL Server: Turbine dine forespørgsler med indekserede visninger
Tag dit spørgsmål Markér som afsluttet Annoter
Sigtet med denne artikel er at introducere begrebet indekserede visninger i SQL Server og vise, hvordan du implementerer og bruger denne type visning til at optimere forespørgsler.
View-konceptet
Visninger er også kendt som “virtuelle tabeller”, da de udgør et alternativ til at bruge tabeller til at få adgang til data. En visning er intet andet end en SELECT-anvisning, der er indkapslet i et objekt. Syntaksen for oprettelse af en visning er som vist i Listing 1.
CREATE VIEW nome_da_visão ...) ] AS subconsulta;Se et eksempel på oprettelse og brug af visninger i Listing 1.
Use NorthWind go create view vi_vendas_mes As Select ano = datepart(yyyy,OrderDate), mes = datepart(mm,OrderDate), qtde_total = sum(Quantity) from Orders o inner join od on o.OrderId = od.OrderId group by datepart(yyyy,o.OrderDate), datepart(mm,o.OrderDate) go select * from vi_vendas_mês go ano mes qtde_total contador ----------- ----------- ----------- -------------------- 1996 7 1462 59 1996 8 1322 69 1996 9 1124 57 1996 10 1738 73 1996 11 1735 66Blandt fordelene ved at bruge visninger kan nævnes :
- Forenkling af kode: Du kan skrive komplekse SELECTs én gang, indkapsle dem i visningen og udløse dem fra den, som om det var en hvilken som helst tabel;
- Sikkerhedsspørgsmål: Antag, at du har fortrolige oplysninger i nogle tabeller, og at du derfor ønsker, at kun nogle brugere skal have adgang til dem. Nogle af kolonnerne i disse tabeller skal dog være tilgængelige for alle brugere. En effektiv måde at løse dette problem på er at oprette en visning og skjule de følsomme kolonner. På denne måde kan man undertrykke adgangsrettighederne til den oprindelige tabel og frigive adgangen til visningen.
- Mulighed for optimering af forespørgsler ved at implementere indekserede visninger.
Indekserede visninger i praksis
Visninger indkapsler SELECT-udsagn, hvilket betyder, at når de udløses, udføres de SELECT-udsagn, der er knyttet til dem. Visninger opretter ikke arkiver for de data, de returnerer (som tabellen gør). Det ville være fantastisk, hvis vi kunne “materialisere” resultatet af SELECT-kommandoen, der findes i visningen, i en tabel og oprette indekser for at lette adgangen til det. De indekserede visninger gør netop dette. Udførelse af et SELECT i en indekseret visning har samme effekt som at udføre et select i en konventionel tabel.
Det vigtigste formål med indekserede visninger er at øge ydeevnen, og fordelen ved SQL Server er at tillade udførelsesplaner at overveje den indekserede visning som et middel til at få adgang til data, selv om visningsnavnet ikke var eksplicit i forespørgslen. Dette er muligt i Enterprise Edition af SQL Server 2000, hvor kommandooptimeringsværktøjet kan vælge data direkte i den indekserede visning (i stedet for at vælge de rå data i tabellen), som vi vil se i det følgende.
Skabelse af en indekseret visning trin for trin
- Det første skridt i konfigurationen af miljøet er at indstille tilstanden af nogle parametre i den session, hvor du vil oprette og bruge visningen, for da den indekserede visning er “materialiseret” i en tabel, kan intet forstyrre dens resultat. Forestil dig f.eks. følgende scenario:
- En bestemt indstilling, som påvirker resultatet af et SELECT (f.eks. concat_null_yelds_null), er indstillet, før den indekserede visning oprettes;
- Den indekserede visning oprettes; bemærk, at resultatet af visningen vil blive “materialiseret” på disken i henhold til den indstilling, der er indstillet i det foregående trin;
- Dernæst deaktiveres indstillingen, og den indekserede visning udføres af brugeren. Da visningen er blevet materialiseret, får vi et resultat, der ikke stemmer overens med den aktuelle konfiguration.
Listing 2 viser f.eks. forskellen i resultatet af en kommando, når egenskaben concat_null_yields_null ændres.
set concat_null_yields_null ON print null + 'abc' -------------------------------------- Set concat_null_yields_null OFF print null + 'abc' -------------------------------------- abcForestil dig, hvad der ville ske, hvis den indekserede visning blev oprettet med egenskaben concat_null_yields_null aktiveret, men den aktuelle session var med denne egenskab deaktiveret – det samme SELECT ville føre til forskellige resultater!
Dette problem blev løst på en enkel måde – for at oprette og bruge indekserede visninger er det obligatorisk at konfigurere miljøet i henhold til en liste med standardværdier. På den måde er det umuligt at få forskellige resultater, fordi visningen simpelthen ikke fungerer, hvis en af indstillingerne er indstillet til en ikke-standardiseret værdi.
Tabel 1 viser disse indstillinger og deres respektive standardværdier.
| Indstilling | Id (*) | Krævet tilstand for indekserede visninger | SQL Server 2000-standard | Default på OLE DB- (=ADO) eller ODBC-forbindelser | Default på forbindelser, der bruger DB Library | ||
|---|---|---|---|---|---|---|---|
| ANSI_NULLS | 32 | ON | OFF | ON | OFF | ||
| ANSI_PADDING | 16 | ON | ON | ON | ON | OFF | |
| ANSI_WARNING | 8 | ON | ON | OFF | ON | ON | OFF |
| ARITHABORT | 64 | ON | OFF | OFF | OFF | OFF | |
| CONCAT_NULL_YIELDS_NULL | 4096 | ON | OFF | ON | OFF | OFF | |
| CITERET_IDENTIFIKATOR | 256 | ON | OFF | ON | OFF | ||
| NUMERIC_ROUNDABORT | 8192 | OFF | OFF | OFF | OFF | OFF |
(*) Id’et bruges i kommandoen sp_configure. Læs afsnittet “Krævede indstillinger for indekserede visninger” for at se, hvad de enkelte indstillinger gør. Der er to måder at ændre værdien af en konfiguration på:
- Direkte i sessionen: Kør kommandoen set ON | OFF
- Ændring af den eksisterende serverstandard: Kør sp_Configure ‘user options’, . Id-nummeret for hver enkelt konfiguration kan ses i tabel 1.
Bemærk: AritHabort har id 64 og Quoted_Identifier har id 256. Hvis vi f.eks. vil linke Quoted_Identifier + AritHabort, skal vi udføre sp_cofigure og som parameter overdrage resultatet af 64+256 (=320): sp_configure ‘user options’, 320. Du kan få en komplet liste over de id’er, der er tildelt hver enkelt konfiguration, på http://msdn.microsoft.com/library/default.asp?url=/library/en-us/adminsql/ad_config_9b1q.asp.
For at bekræfte tilstanden af hver af parametrene i tabel 1 skal du bruge funktionen SessionProperty(‘parameternavn’) eller kommandoen DBCC UserOptions.
Så skal du indstille alle parametre i henhold til kolonnen ‘required state for indexed views’ i tabel 1 – hvis dette ikke er gjort, vil SQL Server ikke tillade dig at oprette/udføre den indekserede visning.
Skabelse af den indekserede visning
Vi vil oprette en visning til at summere det daglige solgte beløb i tabellen Order Details, der er placeret i NorthWind-databasen. Se Listing 3.
use NorthWind go create view vi_vendas_mes with SchemaBinding as select ano = datepart(yyyy,OrderDate), mes = datepart(mm,OrderDate), qtde_total = sum(Quantity), contador = count_big(*) from dbo.Orders o inner join dbo. od on o.OrderId = od.OrderId group by datepart(yyyy,o.OrderDate),datepart(mm,o.OrderDate) goVi skal overholde nogle særlige forhold, når vi opretter indekserede visninger:
- Visningen skal være deterministisk. En visning vil være deterministisk, hvis vi kun bruger deterministiske funktioner i dens kode. Den samme SELECT-kommando, der udføres gentagne gange på en indekseret visning (med en statisk base), kan ikke give forskellige resultater. Deterministiske funktioner sikrer, at resultatet af en funktion forbliver uændret, uanset hvor mange gange den udføres. Funktionen DatePart er f.eks. deterministisk, da den altid returnerer det samme resultat for en bestemt dato. Funktionen getdate() returnerer en anden værdi, hver gang den udføres. Du kan finde en komplet liste over SQL Server 2000-deterministiske funktioner på http://msdn.microsoft.com/library/default.asp?url=/library/en-us/createdb/cm_8_des_08_95v7.asp
- Kontroller, at der ikke er nogen syntaksbegrænsninger. De klausuler, funktioner og forespørgselstyper, der er anført nedenfor, kan ikke integrere skemaet for en indekseret visning:
- MIN, MAX,TOP
- VARIANCE,STDEV,AVG
- COUNT(*)
- SUM på kolonner, der tillader nulværdier
- DISTINCT
- ROWSET-funktionen
- Derived tables, self joins, subqueries, outer joins
- DISTINCT
- UNION
- Float, text, ntext og image
- COMPUTE og COMPUTE BY
- HAVING, CUBE og ROLLUP
Det er nødvendigt at oprette de indekserede visninger med SchemaBinding. For at holde indholdet af visningen konsistent kan du ikke ændre strukturen af de tabeller, der ligger til grund for visningen. For at undgå denne slags problemer er det obligatorisk at bruge SchemaBinding, når du opretter indekserede visninger, fordi denne mulighed ikke giver dig mulighed for at ændre tabellens struktur uden først at slette visningen.
For at bruge GROUP BY-klausulen er det obligatorisk at inkludere funktionen COUNT_BIG(*). Funktionen count_big(*) gør det samme som count(*), men returnerer en værdi af typen bigint (8 bytes).
Informer altid ejeren af de objekter, der henvises til i den indekserede visning. Brug select * from dbo.Orders i stedet for select * from Orders, da det er muligt at have tabeller med samme navn, men med forskellige ejere. Da indstillingen schemabinding er obligatorisk, har SQL Server brug for den nøjagtige objektspecifikation for at forhindre ændringer af skemaet.
Skabelse af et klyngeindeks i visningen (materialisering)
Visningen, der blev oprettet i punkt 2, opfører sig endnu ikke som en indekseret visning, fordi resultatet af select-kommandoen ikke er blevet materialiseret til en tabel. Du kan bekræfte dette udsagn ved at køre kommandoen sp_spaceused i Query Analyzer, som returnerer antallet af rækker og den plads, der bruges af tabellerne (Listing 4).
sp_SpaceUsed vi_vendas_mes -------------------------------------------------------------------------------------- Server: Msg 15235, Level 16, State 1, Procedure sp_spaceused, Line 91 Views do not have space allocated.Opdag i Listing 5, at behandlingen af visningen er rent logisk, så meget at værdien for Physical Reads er nul. Bemærk de værdier, der er registreret i logiske læsninger og fysiske læsninger (1672+0+4+0+0=1676) – vi vil bruge disse værdier i vores fremtidige sammenligninger.
Set statistics io ON Select * from vi_vendas_mesgo---------------------------------------------------------ano mes qtde_total contador ----------- ----------- ------------- -------------------- 1996 7 1462 591996 8 1322 691996 9 1124 57.....(23 row(s) affected)Table 'Order Details'. Scan count 830, logical reads 1672, physical reads 0, read-ahead reads 0.Table 'Orders'. Scan count 1, logical reads 4, physical reads 0, read-ahead reads 0.For at kontrollere, om visningen kan indekseres (materialiseret), dvs. om den blev oprettet inden for de standarder og indstillinger, der kræves for indekserede visninger, skal resultatet af følgende SELECT være lig med 1.
select ObjectProperty(object_id('vi_vendas_mes'),'IsIndexable')Da vi har bekræftet forudsætningerne, kan vi nu oprette indekset. Syntaksen har samme format som ved oprettelse af indekser i konventionelle tabeller:
create unique clustered index pk_ano_mes on vi_vendas_mes (ano,mes)Bemærk, at klyngeindekset er påkrævet, fordi det genererer sider med data. Du kan først oprette ikke-klyngeindekser i indekserede visninger, når du har oprettet klyngeindekset.
Nu er det SELECT, der er fundet i visningen, blevet materialiseret, hvilket kan bevises med kommandoen sp_spaceused i Query Analyzer (Listing 6).
sp_SpaceUsed vi_vendas_mêsgo-----------------------------------------------------Name Rows Reserved data index_size Unusedvi_vendas_mes 23 24 KB 8 KB 16 KB 0 KBBrug af indekserede visninger
En måde at få adgang til en indekseret visning (såvel som en konventionel visning) er at henvise til dens navn i SELECT-kommandoen:
select * from vi_vendas_mesSammenlign mængden af flyttede sider i liste 5 (1672+4=1676) med den i liste 7 (2+0=2). Forskellen er ganske betydelig – ved at oprette den indekserede visning blev den samlede I/O reduceret med 1674 sider.
Set statistics io ON select * from vi_vendas_mes go --------------------------------------------------------- ano mes qtde_total contador ----------- ----------- ------------- -------------------- 1996 7 1462 59 1996 9 1124 57 ..... (23 row(s) affected) Table 'vi_vendas_mes'. Scan count 1, logical reads 2, physical reads 0, read-ahead reads 0.Lad os se på et andet eksempel. Figur 1 viser udførelsesplanen for en forespørgsel. Bekræft, at visningen blev valgt, selv om den ikke var til stede i rækken SELECT.
Under opbygningen af forespørgselsudførelsesplanen fandt optimeringsværktøjet, at der allerede fandtes forud opsummerede data til forespørgslen i vi_sales_mes, og valgte at vælge dataene direkte i den indekserede visning.
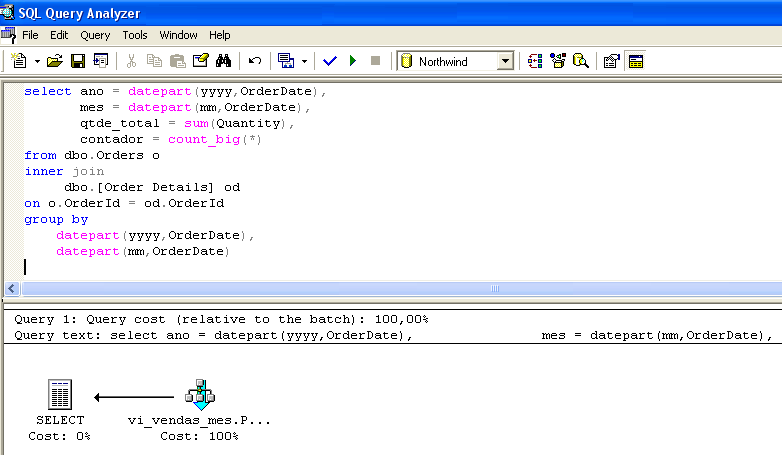
Bemærk, at den forespørgsel, der udføres i figur 1, er identisk med den, der findes i visningen vi_sales_mes. Optimizerens adgang til visningen er imidlertid uafhængig af ligheden mellem den udførte forespørgsel og visningsforespørgslen. Ved forespørgselsprocessorens valg af den indekserede visning tages der kun hensyn til cost-benefit-forholdet. På denne måde behøver de forespørgsler, der udføres, ikke at være identiske med visningen (se figur 3).
Det er dog nødvendigt at følge nogle regler, for at den indekserede visning kan tages i betragtning af forespørgselsoptimeringsværktøjet:
- Den forbindelse, der er til stede i visningen, skal “være indeholdt” i forespørgslen: Hvis forespørgslen udfører en forbindelse mellem tabellerne A og B, og visningen udfører en forbindelse mellem A og C, vil visningen ikke blive udløst i udførelsesplanen. Men hvis forespørgslen udfører et join mellem A,B og C, kan visningen udløses.
- Betingelserne i forespørgslen skal stemme overens med betingelserne i visningen: I SELECT i figur 2 vil den indekserede visning vi_sales_mes ikke blive taget i betragtning, fordi der ikke var en where-klausul i visningens kode, hvilket betød, at rækker med Quantity <= 5 blev beregnet i joinningen.
På den anden side, hvis forespørgslen har where-begrebet where sum(Quantity) > 5, vil visningen vi_sales_mes blive taget i betragtning i udførelsesplanen, fordi forespørgselsbetingelsen er en delmængde af SELECT, der findes i visningen.
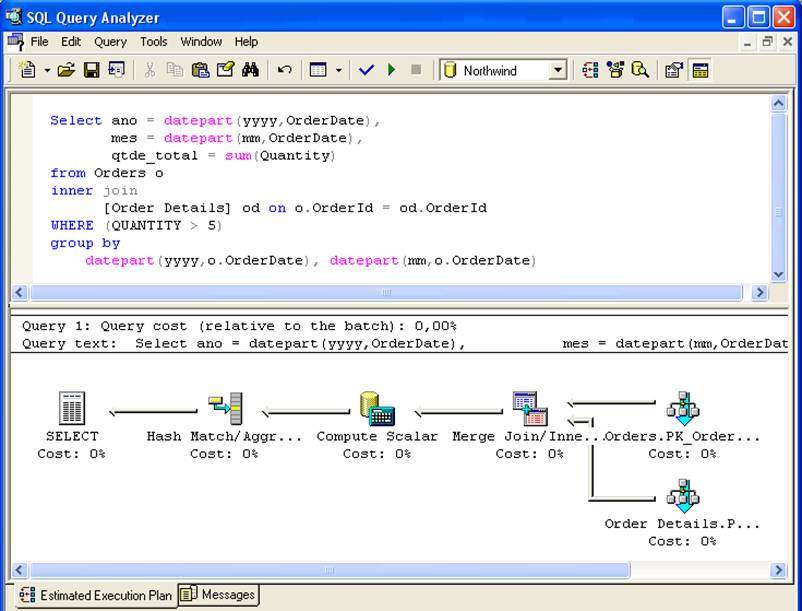
Søjler med aggregeringsfunktioner i forespørgslen skal “være indeholdt” i visningsdefinitionen: Hvis visningen returnerer kolonnen qtde=sum(Quantity), og forespørgslen har en kolonne vlr_unit=sum(UnitPrice), vil visningen ikke blive taget i betragtning.
Figur 3 viser en SELECT-kommando, der gør det muligt at bevise kommandooptimeringens intelligens – AVG(Quantity)-beregningen er blevet erstattet af divisionen mellem SUM(Quantity) / Count_Big(*), repræsenteret ved ikonet Compute Scalar (beregn skalar). Prædikatet where sum(Quantity) > 1500 (repræsenteret ved ikonet Filter) tages også i betragtning.
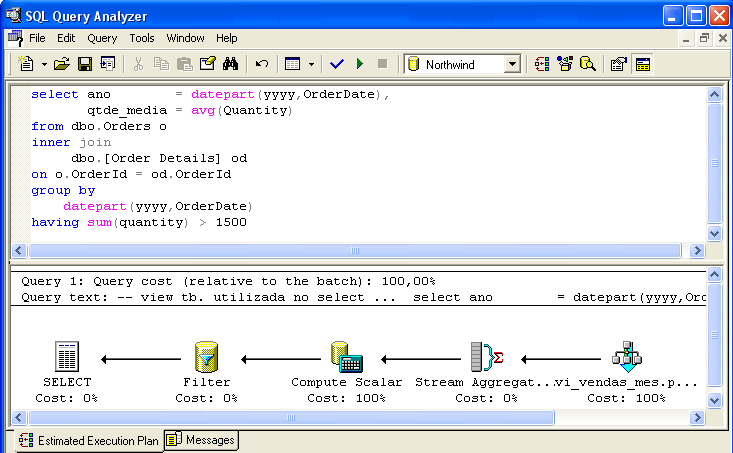
Generelle overvejelser om brug af indekserede visninger:
- Indekserede visninger kan oprettes i alle versioner af SQL Server 2000. Det er dog kun i Enterprise Edition-versionen, at de automatisk vil blive valgt af forespørgselsoptimeringen.
- I andre versioner end Enterprise skal du bruge NoExpand-hinvisningen for at få adgang til den indekserede visning som en konventionel tabel. Hvis NoExpand ikke er anvendt, vil den indekserede visning blive betragtet som en “normal” visning.
Bemærk: Expand-hinvisningen gør det modsatte af NoExpand: den behandler den indekserede visning som en “normal” visning og tvinger SQL Server til at udføre SELECT-anvisningen i kørselsfasen.
- Vedligeholdelsen af en indekseret visning er automatisk (som i indekser); den kræver ingen yderligere synkronisering. I kraft af sin egen egenskab (den gemmer normalt data, der er opsummeret på forhånd), er dens opdatering ofte lidt langsommere end den, der foretages af konventionelle indekser.
- Brug af indekserede visninger i OLTP-baser kræver forsigtighed, for selv om de giver en god ydeevne i forespørgsler, forårsager de overhead i de processer, der ændrer de tabeller, der er relateret til visningen. I situationer, hvor der kræves høj skriveydelse med hyppige opdateringer, anbefales det ikke at oprette indekserede visninger.
- Som det er tilfældet med indekser, analyserer optimeringsværktøjet visningskoden i Enterprise-versioner som en del af processen med at vælge den bedste udførelsesplan for en forespørgsel. Hvis der imidlertid er mange indekserede visninger, der kan udføres for den samme forespørgsel, kan der ske en væsentlig forøgelse af denne valgtid, da alle visninger vil blive analyseret. Brug derfor sund fornuft, når du implementerer visningerne.
Nødvendige indstillinger for indekserede visninger
ANSI_NULLS
Definerer, hvordan sammenligninger med nulværdier udføres (Listing 8).
set ANSI_NULLS ON declare @var char(10) set @var = null if @var = null print 'VERDADEIRO' else print 'FALSO' ------------------------------------- FALSO set ANSI_NULLS OFF declare @var char(10) set @var = null if @var = null print 'VERDADEIRO' else print 'FALSO' -------------------------------------- VERDADEIROANSI_PADDING
Bestemmer, hvordan char-, varchar-, binære og varbinære kolonner skal gemmes, når deres indhold er mindre end den størrelse, der er defineret i tabelstrukturen. SQL Server 2000-standardindstillingen er at holde ansi_padding slået til (=ON); i denne tilstand gælder følgende regler:
- Når du opdaterer char-kolonner, tilføjes der whitespace i slutningen af strengen, hvis den er mindre end den størrelse, der er defineret i kolonnestrukturen. Den samme regel gælder for binære kolonner (i dette tilfælde udfyldes mellemrummet med en sekvens af nuller)
- Varchar eller varbinære kolonner følger ikke ovenstående regel: de beholder altid deres oprindelige størrelse.
ARITHABORT
Hvis den er aktiveret, afsluttes udførelsen af forespørgsler ved division med nul eller en form for overløb.
QUOTED_IDENTIFIER
Hvis den er aktiveret, er det muligt at bruge dobbelte anførselstegn til at angive navne på tabeller, kolonner osv. – På den måde kan disse navne indeholde mellemrum og/eller specialtegn.
CONCAT_NULL_YELDS_NULL
Kontrollerer resultatet af sammenkædning af strenge med nulværdier. Når den er aktiveret, bestemmer den, at denne sammenføjning skal returnere en nulværdi; ellers returneres selve strengen.
ANSI_WARNINGS
Når den er aktiveret, bestemmer den genereringen af fejlmeddelelser, når:
- du bruger opsummeringsfunktioner, og der findes nulværdier i forespørgselsområdet;
- der findes opdelinger med nul eller aritmetisk overløb.
NUMERIC_ROUNDABORT
Styrer, hvordan SQL Server skal fortsætte, når der opstår tab af numerisk præcision i aritmetiske operationer. Hvis parameteren er aktiveret, og en variabel med en præcision på to decimaler modtager en værdi med tre decimaler, vil operationen blive afbrudt. Hvis parameteren er deaktiveret, vil værdien blive afkortet til to decimaler.
Konklusion
Når det kommer til optimering af forespørgsler, er indekserede visninger et godt valg til at udnytte ydeevnen. Derfor skal du grundigt evaluere de forespørgsler, der omhandler opsummeringer, og som udføres med en vis hyppighed, og vælge at oprette indekserede visninger. Resultatet er det hele værd!