




Learn Regex: A Beginner's Guide
In diesem Leitfaden lernen Sie die Regex-Syntax, also die Syntax der regulären Ausdrücke. Am Ende werden Sie in der Lage sein, Regex-Lösungen in den meisten Szenarien anzuwenden, in denen sie bei der Webentwicklung benötigt werden.
Reguläre Ausdrücke haben viele Anwendungsfälle, darunter:
- Validierung von Formulareingaben
- Web-Scraping
- Suchen und Ersetzen
- Filtern von Informationen in umfangreichen Textdateien wie Protokollen
Reguläre Ausdrücke, oder Regex, wie sie allgemein genannt werden, sehen für neue Benutzer kompliziert und einschüchternd aus. Schauen Sie sich dieses Beispiel an:
/^+@+(?:\.+)*$/Das sieht einfach nur wie durcheinandergewürfelter Text aus. Aber verzweifeln Sie nicht, hinter diesem Wahnsinn steckt Methode.

Credit: xkcd
Ich zeige Ihnen, wie Sie reguläre Ausdrücke im Handumdrehen beherrschen. Klären wir zunächst die in diesem Leitfaden verwendete Terminologie:
- Muster: Muster für reguläre Ausdrücke
- Zeichenkette: Testzeichenkette, die für die Übereinstimmung mit dem Muster verwendet wird
- Ziffer: 0-9
- Buchstabe: a-z, A-Z
- Symbol: !$%^&*()_+|~-=`{}:“;'<>?,./
- Leerzeichen: einzelnes Leerzeichen, Tabulator
- Zeichen: bezieht sich auf einen Buchstaben, eine Ziffer oder ein Symbol
Grundlagen
Um Regex mit diesem Leitfaden schnell zu erlernen, besuchen Sie Regex101, wo Sie Regex-Muster erstellen und anhand von Zeichenketten (Text) testen können, die Sie angeben.
Wenn Sie die Website öffnen, müssen Sie die JavaScript-Variante auswählen, da wir diese für diesen Leitfaden verwenden werden. (Die Regex-Syntax ist für alle Sprachen weitgehend gleich, aber es gibt einige kleine Unterschiede.)
Als nächstes müssen Sie die Flags global und multi line in Regex101 deaktivieren. Wir werden sie im nächsten Abschnitt behandeln. Für den Moment betrachten wir die einfachste Form eines regulären Ausdrucks, die wir erstellen können. Geben Sie Folgendes ein:
- Regex-Eingabefeld: cat
- Teststring: rat bat cat sat fat cats eat tat cat mat CAT
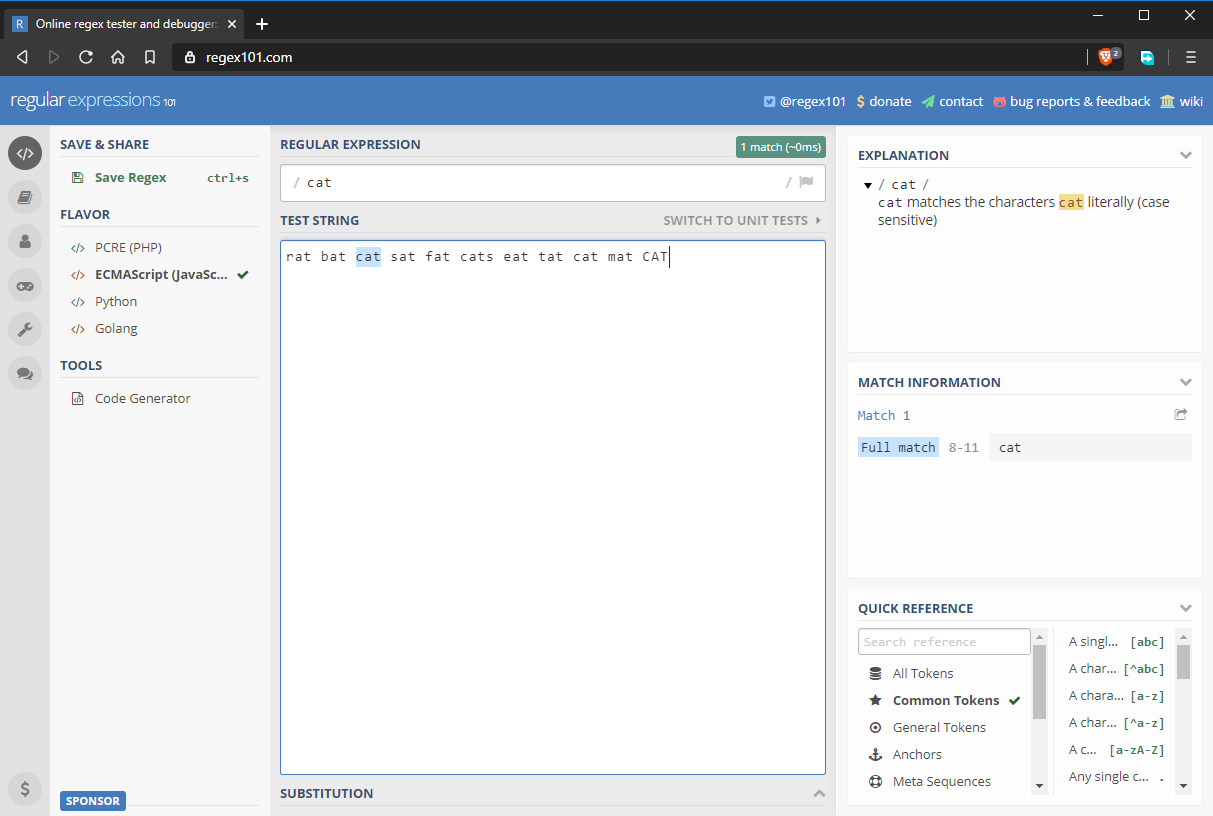
Beachten Sie, dass reguläre Ausdrücke in JavaScript mit / beginnen und enden. Wenn Sie einen regulären Ausdruck in JavaScript-Code schreiben würden, würde er wie folgt aussehen: /cat/ ohne jegliche Anführungszeichen. Im obigen Beispiel entspricht der reguläre Ausdruck der Zeichenkette „cat“. Wie Sie jedoch in der obigen Abbildung sehen können, gibt es mehrere „cat“-Strings, die nicht übereinstimmen. Im nächsten Abschnitt werden wir uns ansehen, warum das so ist.
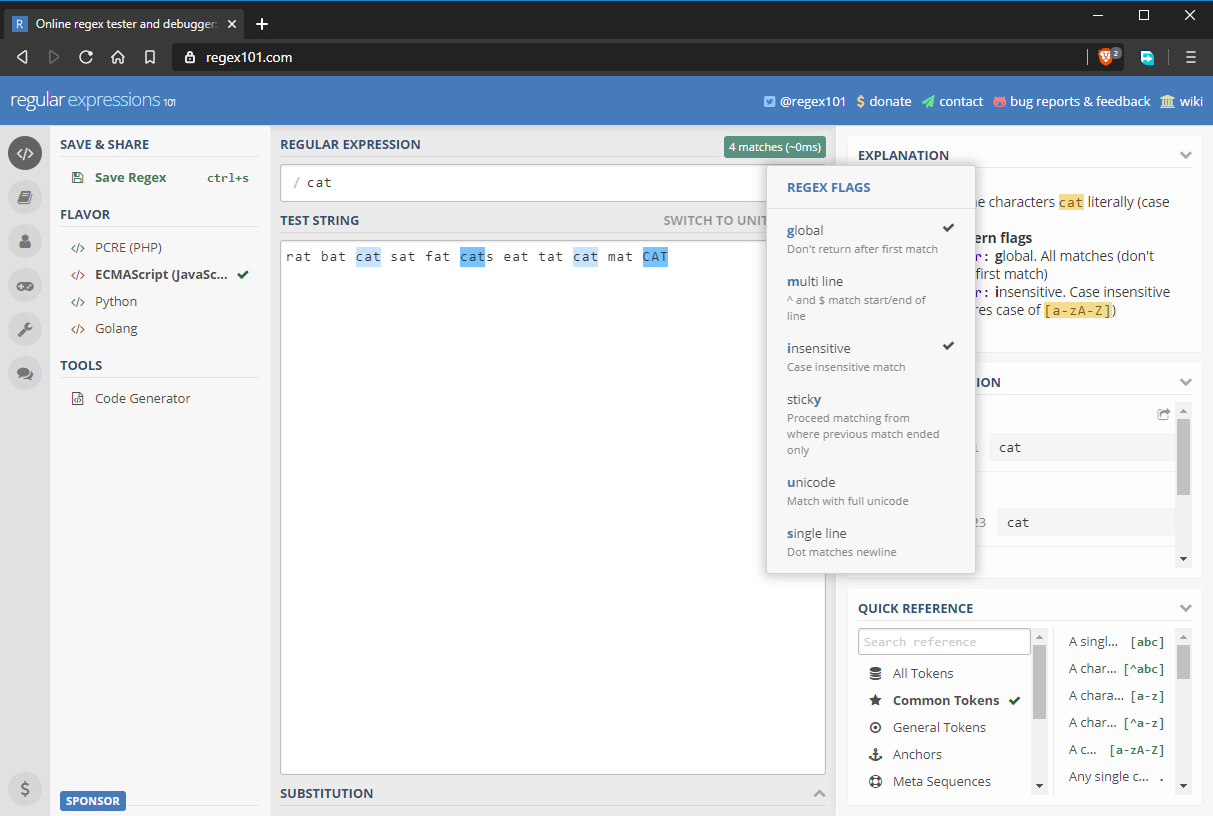
Globale und Groß-/Kleinschreibung nicht berücksichtigende Regex-Flags
Standardmäßig gibt ein Regex-Muster nur die erste gefundene Übereinstimmung zurück. Wenn Sie weitere Übereinstimmungen erhalten möchten, müssen Sie das globale Flag g aktivieren. Regex-Muster unterscheiden standardmäßig auch zwischen Groß- und Kleinschreibung. Sie können dieses Verhalten außer Kraft setzen, indem Sie das Flag i für die Unempfindlichkeit aktivieren. Das aktualisierte Regex-Muster wird nun vollständig als /cat/gi ausgedrückt. Wie Sie unten sehen können, wurden alle „cat“-Strings abgeglichen, einschließlich des Strings mit einer anderen Groß-/Kleinschreibung.
Zeichensätze
Im vorherigen Beispiel haben wir gelernt, wie man exakte Übereinstimmungen unter Berücksichtigung der Groß-/Kleinschreibung durchführt. Was wäre, wenn wir „bat“, „cat“ und „fat“ abgleichen wollten. Dies ist mit Hilfe von Zeichensätzen möglich, die mit gekennzeichnet sind. Im Grunde geben Sie mehrere Zeichen ein, die abgeglichen werden sollen. Zum Beispiel wird at mit mehreren Zeichenfolgen wie folgt übereinstimmen:
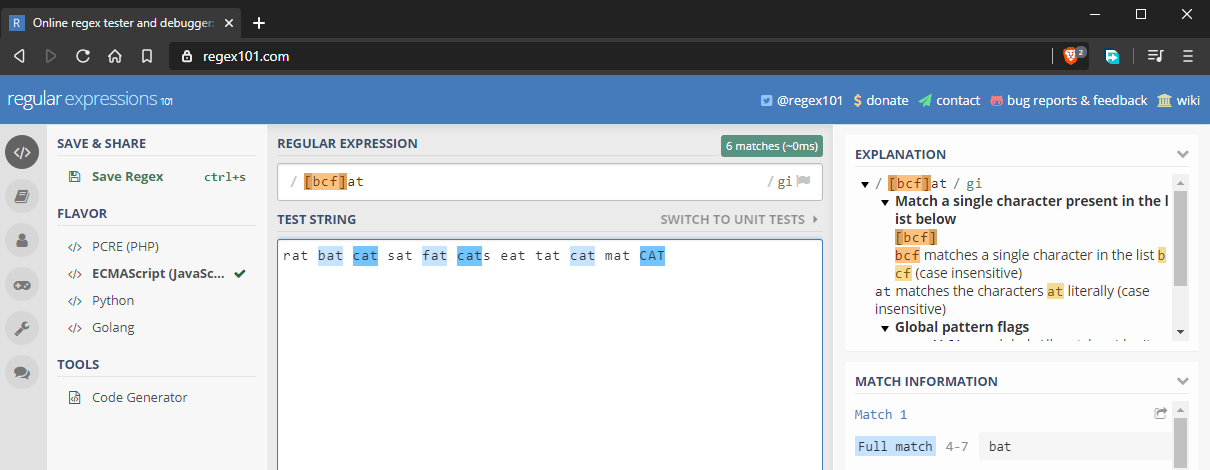
Zeichensätze funktionieren auch mit Ziffern.
Bereiche
Angenommen, wir wollen alle Wörter finden, die mit at enden. Wir könnten das gesamte Alphabet innerhalb des Zeichensatzes angeben, aber das wäre mühsam. Die Lösung ist, Bereiche wie diesen zu verwenden: at:
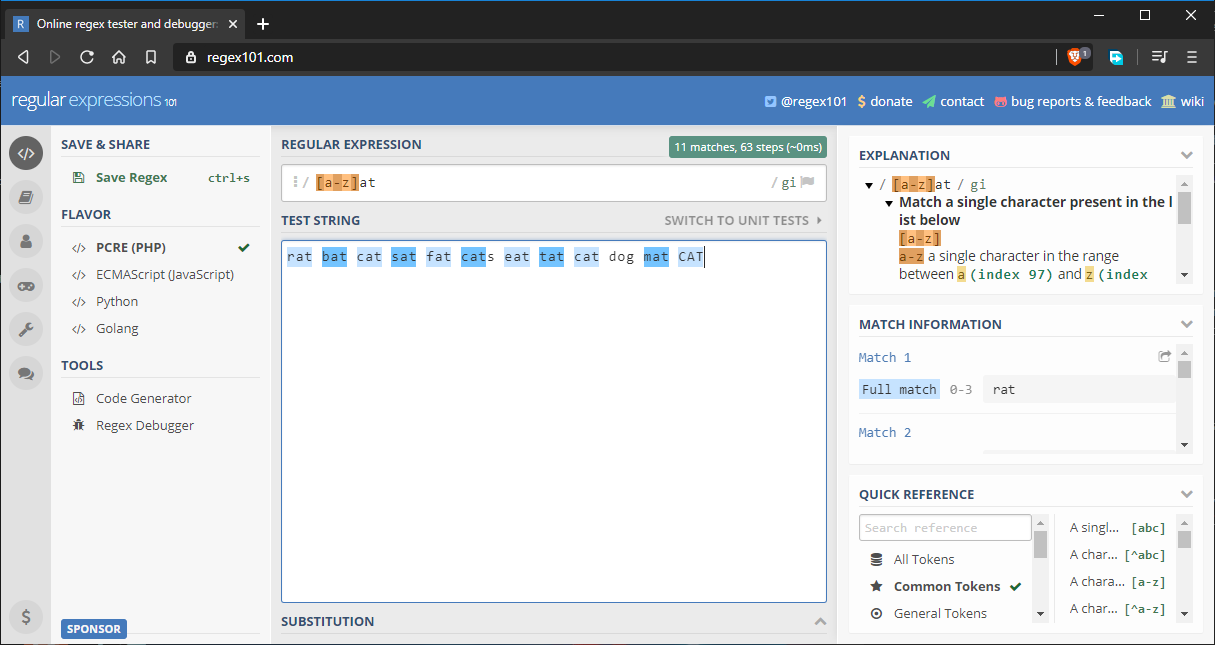
Hier ist die vollständige Zeichenfolge, die getestet wird: rat bat cat sat fat cats eat tat cat dog mat CAT.
Wie Sie sehen können, stimmen alle Wörter wie erwartet überein. Ich habe das Wort dog nur hinzugefügt, um eine ungültige Übereinstimmung zu erzeugen. Hier sind andere Möglichkeiten, wie Sie Bereiche verwenden können:
-
Teilbereich: Auswahlen wie
oder. -
Großer Bereich:
. -
Ziffernbereich:
. -
Symbolbereich: z. B.
. -
Mischbereich: z. B.
umfasst alle Ziffern, Klein- und Großbuchstaben. Beachten Sie, dass ein Bereich nur mehrere Alternativen für ein einzelnes Zeichen in einem Muster angibt.Um besser zu verstehen, wie man einen Bereich definiert, sehen Sie sich am besten die vollständige ASCII-Tabelle an, um zu sehen, wie die Zeichen angeordnet sind.

Wiederholende Zeichen
Angenommen, Sie möchten alle Wörter mit drei Buchstaben finden. Sie würden wahrscheinlich so vorgehen:
Das würde allen Wörtern mit drei Buchstaben entsprechen. Aber was ist, wenn Sie ein Wort mit fünf oder acht Buchstaben finden wollen? Die obige Methode ist mühsam. Es gibt eine bessere Möglichkeit, ein solches Muster mit der Notation der geschweiften Klammern {} auszudrücken. Sie müssen lediglich die Anzahl der sich wiederholenden Zeichen angeben. Hier sind Beispiele:
-
a{5}entspricht „aaaaa“. -
n{3}entspricht „nnn“. -
{4}entspricht einem beliebigen Wort mit vier Buchstaben wie „Tür“, „Zimmer“ oder „Buch“. -
{6,}passt auf jedes Wort mit sechs oder mehr Buchstaben. -
{8,11}passt auf jedes Wort mit acht bis 11 Buchstaben. Eine einfache Passwortüberprüfung kann auf diese Weise durchgeführt werden. -
{11}stimmt mit einer 11-stelligen Zahl überein. Auf diese Weise kann eine einfache Überprüfung von internationalen Telefonnummern durchgeführt werden.
Metacharacters
Metacharacters ermöglichen es Ihnen, Muster für reguläre Ausdrücke zu schreiben, die noch kompakter sind. Gehen wir sie der Reihe nach durch:
-
\dpasst auf jede Ziffer, die gleich ist wie -
\wpasst auf jeden Buchstaben, jede Ziffer und jeden Unterstrich -
\spasst auf ein Leerzeichen – das heißt, ein Leerzeichen oder Tabulator -
\tpasst nur auf ein Tabulatorzeichen
Nach dem, was wir bisher gelernt haben, können wir reguläre Ausdrücke wie diesen schreiben:
-
\w{5}passt auf ein beliebiges Wort mit fünf Buchstaben oder eine fünfstellige Zahl -
\d{11}passt auf eine 11-stellige Zahl, z. B. eine Telefonnummer
Sonderzeichen
Sonderzeichen bringen uns einen Schritt weiter beim Schreiben fortgeschrittener Musterausdrücke:
-
+: Ein oder mehrere Quantoren (das vorangestellte Zeichen muss vorhanden sein und kann optional dupliziert werden). Zum Beispiel passt der Ausdruckc+atauf „cat“, „ccat“ und „ccccccccat“. Sie können das vorangehende Zeichen so oft wiederholen, wie Sie wollen, und Sie erhalten immer noch eine Übereinstimmung. -
?: Null oder ein Quantifizierer (das vorangestellte Zeichen ist optional). Zum Beispiel wird der Ausdruckc?atnur mit „cat“ oder „at“ übereinstimmen. -
*: Null oder mehr Quantifizierer (das vorangestellte Zeichen ist optional und kann optional dupliziert werden). Zum Beispiel passt der Ausdruckc*atauf „at“, „cat“ und „ccccccat“. Es ist wie die Kombination von+und?. -
\: Dieses „Escape-Zeichen“ wird verwendet, wenn wir ein Sonderzeichen wörtlich verwenden wollen. Zum Beispiel passtc\*genau zu „c*“ und nicht zu „ccccccc“. -
: Diese „Negativ“-Notation wird verwendet, um ein Zeichen anzugeben, das innerhalb eines Bereichs nicht übereinstimmen soll. Zum Beispiel passt der Ausdruckbldnicht zu „bald“ oder „bbld“, da die zweiten Buchstaben a bis c negativ sind. Das Muster stimmt jedoch mit „beld“, „bild“, „bold“ usw. überein. -
.: Diese „do“-Notation stimmt mit jeder Ziffer, jedem Buchstaben oder Symbol außer dem Zeilenumbruch überein. Zum Beispiel passt.{8}auf ein achtstelliges Passwort, das aus Buchstaben, Zahlen und Symbolen besteht. z.B. „password“ und „P@ssw0rd“ passen beide.
Aus dem, was wir bisher gelernt haben, können wir eine interessante Vielfalt an kompakten, aber mächtigen regulären Ausdrücken erstellen. Zum Beispiel:
-
.+entspricht einem oder einer unbegrenzten Anzahl von Zeichen. Zum Beispiel „c“ , „cc“ und „bcd#.670“ passen alle. -
+passt auf alle Wörter mit Kleinbuchstaben, unabhängig von der Länge, solange sie mindestens einen Buchstaben enthalten. Zum Beispiel passen „Buch“ und „Sitzungssaal“ beide.
Gruppen
Alle Sonderzeichen, die wir gerade erwähnt haben, betreffen nur ein einzelnes Zeichen oder einen Bereich. Was aber, wenn wir den Effekt auf einen Teil des Ausdrucks anwenden wollen? Dies ist möglich, indem man Gruppen mit runden Klammern – () – erstellt. Zum Beispiel wird das Muster book(.com)? sowohl auf „book“ als auch auf „book.com“ passen, da wir den „.com“-Teil optional gemacht haben.
Hier ist ein komplexeres Beispiel, das in einem realistischen Szenario wie der E-Mail-Validierung verwendet werden würde:
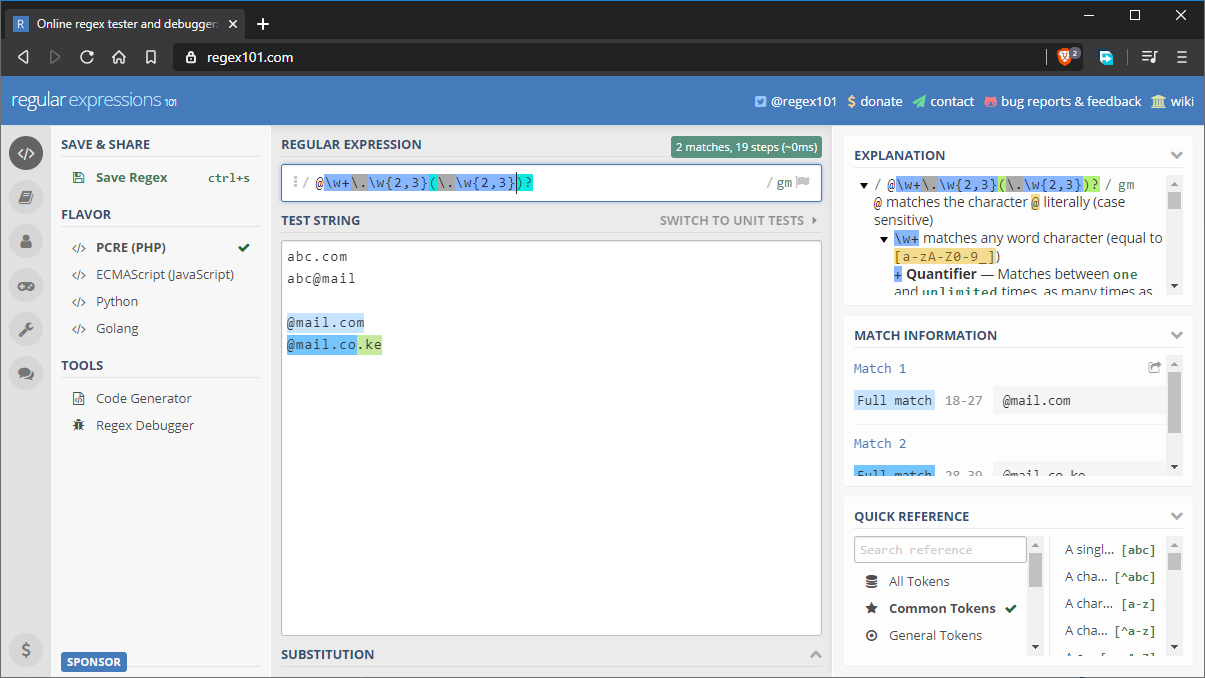
- Muster:
@\w+\.\w{2,3}(\.\w{2,3})? - Teststring:
abc.com abc@mail @mail.com @mail.co.ke
Alternative Zeichen
In regex können wir alternative Zeichen mit dem „Pipe“-Symbol – | – angeben. Dies unterscheidet sich von den zuvor gezeigten Sonderzeichen, da es alle Zeichen auf beiden Seiten des Pipe-Symbols betrifft. Das Muster sat|sit passt zum Beispiel sowohl zu „sat“ als auch zu „sit“. Wir können das Muster als s(a|i)t umschreiben, um dieselben Zeichenfolgen zu finden.
Das obige Muster kann als s(a|i)t ausgedrückt werden, indem () Klammern verwendet werden.
Beginnende und endende Muster
Sie haben vielleicht bemerkt, dass einige positive Übereinstimmungen das Ergebnis einer teilweisen Übereinstimmung sind. Wenn ich zum Beispiel ein Muster für die Zeichenfolge „boo“ geschrieben habe, wird auch die Zeichenfolge „book“ eine positive Übereinstimmung erhalten, obwohl sie keine exakte Übereinstimmung ist. Um hier Abhilfe zu schaffen, verwenden wir die folgenden Notationen:
-
^: am Anfang platziert, passt dieses Zeichen auf ein Muster am Anfang einer Zeichenfolge. -
$: am Ende platziert, passt dieses Zeichen auf ein Muster am Ende der Zeichenfolge.
Um die obige Situation zu beheben, können wir unser Muster als boo$ schreiben. Damit wird sichergestellt, dass die letzten drei Zeichen mit dem Muster übereinstimmen. Es gibt jedoch ein Problem, das wir noch nicht berücksichtigt haben, wie die folgende Abbildung zeigt:
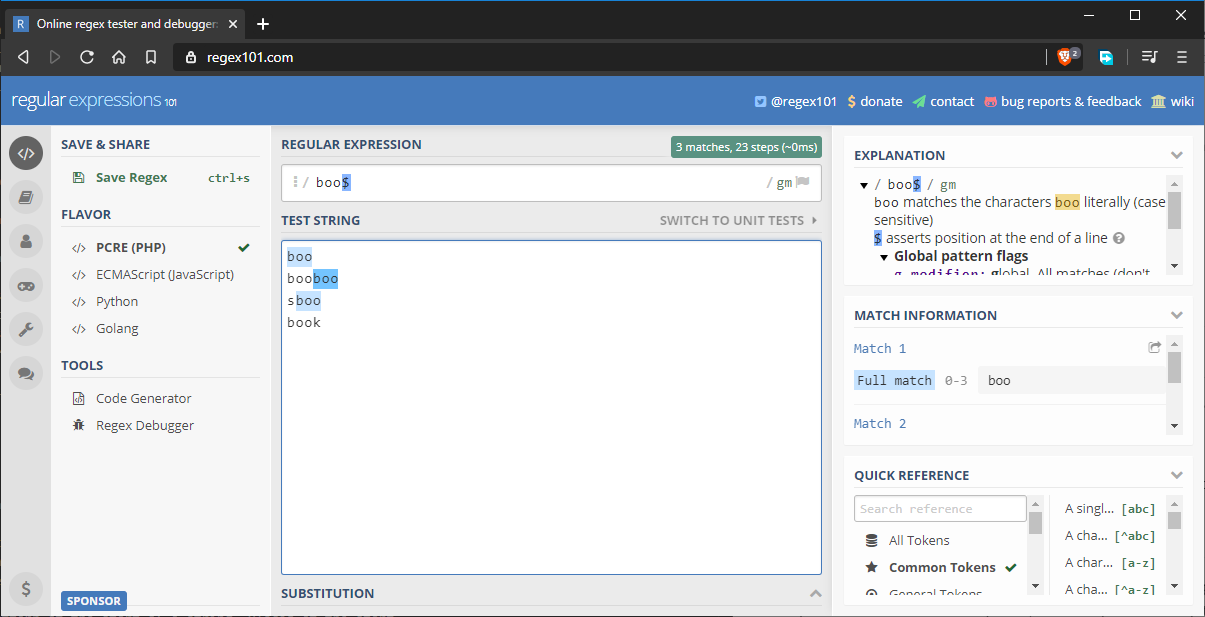
Die Zeichenkette „sboo“ erhält eine Übereinstimmung, da sie immer noch die aktuellen Anforderungen für den Mustervergleich erfüllt. Um dies zu beheben, können wir das Muster wie folgt aktualisieren: ^boo$. Dies wird genau auf das Wort „boo“ passen. Wenn Sie beide verwenden, werden beide Regeln erzwungen. Zum Beispiel: ^{5}$ passt genau auf ein Wort mit fünf Buchstaben. Wenn die Zeichenfolge mehr als fünf Buchstaben hat, passt das Muster nicht.
Regex in JavaScript
// Example 1const regex1=/a-z/ig//Example 2const regex2= new RegExp(//, 'ig')Wenn Sie Node.js auf Ihrem Rechner installiert haben, öffnen Sie ein Terminal und führen Sie den Befehl node aus, um den Node.js-Shell-Interpreter zu starten. Führen Sie dann wie folgt aus:
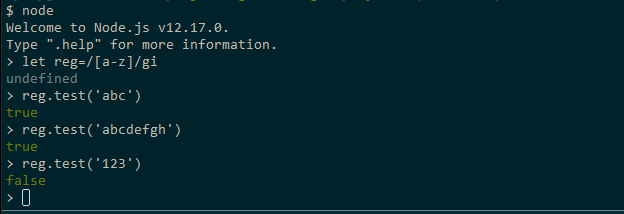
Sie können mit weiteren Regex-Mustern spielen. Wenn Sie fertig sind, verwenden Sie den Befehl .exit, um die Shell zu beenden.
Real World Example: E-Mail-Validierung
Zum Abschluss dieses Leitfadens wollen wir uns noch eine beliebte Anwendung von Regex ansehen, die E-Mail-Validierung. (Wir möchten zum Beispiel überprüfen, ob eine E-Mail-Adresse, die ein Benutzer in ein Formular eingegeben hat, eine gültige E-Mail-Adresse ist.)
Dieses Thema ist komplizierter, als Sie vielleicht denken. Die Syntax für E-Mail-Adressen ist recht einfach: {name}@{domain}. Theoretisch kann eine E-Mail-Adresse eine begrenzte Anzahl von Symbolen wie #-@&%. usw. enthalten. Es kommt jedoch auf die Platzierung dieser Symbole an. Auch die Mailserver haben unterschiedliche Regeln für die Verwendung von Symbolen. Einige Server behandeln zum Beispiel das Symbol + als ungültig. Auf anderen Mail-Servern wird das Symbol für E-Mail-Subadressen verwendet.
Um Ihr Wissen zu testen, versuchen Sie, ein Muster für einen regulären Ausdruck zu erstellen, das nur mit den unten markierten gültigen E-Mail-Adressen übereinstimmt:
# invalid emailabcabc.com# valid email [email protected]@[email protected]@[email protected]# invalid email [email protected]@[email protected]#[email protected]# valid email [email protected]@[email protected][email protected]# invalid domain [email protected]@mail#[email protected]@mail..com# valid domain [email protected]@[email protected]@[email protected]Bitte beachten Sie, dass einige als gültig markierte E-Mail-Adressen für bestimmte Organisationen ungültig sein können, während einige, die als ungültig markiert sind, in anderen Organisationen tatsächlich zulässig sein können. In jedem Fall ist es wichtig, dass Sie lernen, benutzerdefinierte reguläre Ausdrücke für die Organisationen zu erstellen, für die Sie arbeiten, um deren Anforderungen zu erfüllen. Falls Sie nicht weiterkommen, können Sie sich die folgenden möglichen Lösungen ansehen. Beachten Sie, dass keine davon eine 100%ige Übereinstimmung mit den oben genannten gültigen E-Mail-Testzeichenfolgen ergibt.
- Mögliche Lösung 1:
^\w*(\-\w)?(\.\w*)?@\w*(-\w*)?\.\w{2,3}(\.\w{2,3})?$- Mögliche Lösung 2:
^((\.,;:\s@"]+(\.\.,;:\s@"]+)*)|(".+"))@((\{1,3}\.{1,3}\.{1,3}\.{1,3}])|((+\.)+{2,}))$Zusammenfassung
Ich hoffe, Sie haben jetzt die Grundlagen der regulären Ausdrücke gelernt. Wir haben in dieser Kurzanleitung für Einsteiger nicht alle Regex-Funktionen behandelt, aber Sie sollten genug Informationen haben, um die meisten Probleme, die eine Regex-Lösung erfordern, zu lösen. Wenn Sie mehr erfahren möchten, lesen Sie unseren Leitfaden über bewährte Verfahren für die praktische Anwendung von Regex in realen Szenarien.