




Wie gut sind die Meinungsforscher? Analyse des Datensatzes von Five-Thirty-Eight
Wir analysieren den Datensatz des Meinungsforscher-Rankings der ehrwürdigen politischen Vorhersage-Website Five-Thirty-Eight.

Dieses Jahr ist ein Wahljahr und die Umfragen rund um die Wahlen (sowohl allgemeine Präsidentschafts- als auch Repräsentantenhaus-/Senatswahlen) werden immer heißer. In den kommenden Tagen wird es immer spannender werden, mit Tweets, Gegentweets, Kämpfen in den sozialen Medien und endlosem Gezänk im Fernsehen.
Wir wissen, dass nicht alle Umfragen von gleicher Qualität sind. Wie kann man sich also einen Reim auf das Ganze machen? Wie kann man vertrauenswürdige Meinungsforscher anhand von Daten und Analysen identifizieren?

In der Welt der politischen (und einiger anderer Themen wie Sport, soziale Phänomene, Wirtschaft usw.) Vorhersageanalysen ist Five-Thirty-Eight ein beeindruckender Name.
Seit Anfang 2008 veröffentlicht die Website Artikel – in der Regel zur Erstellung oder Analyse statistischer Informationen – zu einer Vielzahl von Themen der aktuellen Politik und politischen Nachrichten. Die Website, die von dem Datenwissenschaftler und Statistiker Nate Silver betrieben wird, erlangte besondere Bekanntheit und weit verbreiteten Ruhm rund um die Präsidentschaftswahlen 2012, als ihr Modell den Gewinner aller 50 Bundesstaaten und des District of Columbia korrekt vorhersagte.
Und bevor Sie spöttisch sagen: „Aber was ist mit der Wahl 2016?“, sollten Sie vielleicht diesen Artikel darüber lesen, dass die Wahl von Donald Trump innerhalb der normalen Fehlerspanne der statistischen Modellierung lag.
Für die politisch neugierigen Leser gibt es hier eine ganze Reihe von Artikeln über die Wahl 2016.
Datenwissenschaftler sollten Gefallen an Five-Thirty-Eight finden, weil es sich nicht scheut, seine Vorhersagemodelle in hochtechnischen Begriffen zu erklären (zumindest komplex genug für den Laien).

Hier geht es um die Übernahme der berühmten t-Verteilung, während die meisten anderen Umfrage-Aggregatoren sich mit der allgegenwärtigen Normalverteilung begnügen.
Über den Einsatz ausgefeilter statistischer Modellierungstechniken hinaus ist das Team um Silver jedoch stolz auf eine einzigartige Methode – die Bewertung von Meinungsforschern -, die dazu beiträgt, dass ihre Modelle äußerst genau und vertrauenswürdig bleiben.
In diesem Artikel analysieren wir ihre Daten zu diesen Rating-Methoden.
Five-Thirty-Eight scheut sich nicht, ihre Prognosemodelle in hochtechnischen Begriffen zu erklären (zumindest komplex genug für den Laien).
Pollster-Rating und -Ranking
Es gibt eine Vielzahl von Meinungsforschern in diesem Land. Sie zu lesen und ihre Qualität zu beurteilen, kann sehr anstrengend und mühsam sein. Auf der Website heißt es: „Das Lesen von Umfragen kann gesundheitsschädlich sein. Zu den Symptomen gehören Rosinenpickerei, Selbstüberschätzung, Verfallen auf dubiose Zahlen und vorschnelle Urteile. Zum Glück haben wir ein Heilmittel.“ (Quelle)
Es gibt Umfragen. Dann gibt es Umfragen über Umfragen. Dann gibt es gewichtete Umfragen von Umfragen. Vor allem aber gibt es Umfragen von Umfragen mit statistisch modellierten und sich dynamisch verändernden Gewichtungen.
Kommt Ihnen eine andere berühmte Ranking-Methode bekannt vor, von der Sie als Datenwissenschaftler gehört haben? Das Produktranking von Amazon oder das Filmranking von Netflix? Wahrscheinlich ja.
Im Wesentlichen verwendet Five-Thirty-Eight dieses Bewertungs-/Rankingsystem, um die Umfrageergebnisse zu gewichten (die Ergebnisse von Meinungsforschern mit hohem Ranking werden höher gewichtet und so weiter und so fort). Five-Thirty-Eight verfolgt auch aktiv die Genauigkeit und die Methoden, die hinter den Ergebnissen der einzelnen Meinungsforscher stehen, und passt seine Rangliste im Laufe des Jahres an.
Es gibt Umfragen. Dann gibt es Umfragen von Umfragen. Dann gibt es gewichtete Umfragen von Umfragen. Vor allem aber gibt es Umfragen von Umfragen mit statistisch modellierten und sich dynamisch verändernden Gewichtungen.
Interessant ist, dass die Methodik des Rankings nicht zwangsläufig dazu führt, dass ein Meinungsforscher mit einem größeren Stichprobenumfang als besser eingestuft wird. Der folgende Screenshot von ihrer Website demonstriert dies deutlich. Während Meinungsforscher wie Rasmussen Reports und HarrisX über größere Stichproben verfügen, ist es das Marist College, das mit einer bescheidenen Stichprobengröße die Bewertung A+ erhält.
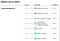
Glücklicherweise stellen sie ihre Umfrage-Ranking-Daten (zusammen mit fast allen anderen Datensätzen) hier auf Github zur Verfügung. Und wenn Sie nur an einer schön aussehenden Tabelle interessiert sind, hier ist sie.
Natürlich möchten Sie als Datenwissenschaftler vielleicht tiefer in die Rohdaten eindringen und Dinge verstehen wie,
- wie ihr numerisches Ranking mit der Genauigkeit der Meinungsforscher korreliert
- ob sie eine parteipolitische Voreingenommenheit bei der Auswahl bestimmter Meinungsforscher haben (in den meisten Fällen können sie entweder als den Demokraten oder den Republikanern zugeneigt kategorisiert werden)
- Wer sind die am besten bewerteten Meinungsforscher? Führen sie viele Umfragen durch oder sind sie selektiv?
Wir haben versucht, den Datensatz zu analysieren, um solche Erkenntnisse zu gewinnen. Schauen wir uns den Code und die Ergebnisse an?
Die Analyse
Das Jupyter Notebook findet ihr hier auf meinem Github Repo.
Die Quelle
Zu Beginn kannst du die Daten direkt von ihrem Github in einen Pandas DataFrame ziehen, wie folgt,

Es gibt 23 Spalten in diesem Datensatz. So sehen sie aus:

Einige Umwandlungen und Bereinigungen
Wir stellen fest, dass eine Spalte etwas mehr Platz hat. Einige andere müssen möglicherweise extrahiert und in Datentypen umgewandelt werden.



Nach Anwendung dieser Extraktion hat der neue DataFrame zusätzliche Spalten, was ihn für Filterung und statistische Modellierung besser geeignet macht.

Untersuchung und Quantisierung der Spalte „538 Grades“
Die Spalte „538 Grades“ enthält den Kern des Datensatzes – die Briefnote für den Befragten. Wie bei einer normalen Prüfung ist A+ besser als A, und A ist besser als B+. Wenn wir die Anzahl der Buchstabennoten grafisch darstellen, sehen wir insgesamt 15 Abstufungen von A+ bis F.

Anstatt mit so vielen kategorischen Abstufungen zu arbeiten, können wir sie zu einer kleinen Anzahl von numerischen Noten zusammenfassen – 4 für A+/A/A-, 3 für die B’s, usw.

Boxplots
Bei der visuellen Analyse können wir mit Boxplots beginnen.
Angenommen, wir wollen prüfen, welche Umfragemethode in Bezug auf den Vorhersagefehler besser abschneidet. Der Datensatz enthält eine Spalte mit der Bezeichnung „Simple Average Error“, die wie folgt definiert ist: „Der durchschnittliche Fehler des Unternehmens, berechnet als die Differenz zwischen dem ermittelten Ergebnis und dem tatsächlichen Ergebnis für den Abstand zwischen den beiden Erstplatzierten im Rennen.“

Dann könnte es von Interesse sein, zu überprüfen, ob Meinungsforscher mit einer bestimmten parteipolitischen Ausrichtung erfolgreicher sind, die Wahlen richtig vorherzusagen als andere.

Ist Ihnen etwas Interessantes aufgefallen? Wenn Sie ein fortschrittlicher, liberal denkender Mensch sind, werden Sie höchstwahrscheinlich der Demokratischen Partei angehören. Aber im Durchschnitt sagen die Meinungsforscher, die den Republikanern zugeneigt sind, die Wahlen genauer und mit weniger Schwankungen voraus. Achten Sie also besser auf diese Umfragen!
Eine weitere interessante Spalte in dem Datensatz heißt „NCPP/AAPOR/Roper“. Sie „gibt an, ob das Meinungsforschungsinstitut Mitglied des National Council on Public Polls, Unterzeichner der Transparenzinitiative der American Association for Public Opinion Research oder Mitwirkender im Datenarchiv des Roper Center for Public Opinion Research war. Eine Mitgliedschaft bedeutet, dass eine solidere Meinungsforschungsmethodik angewandt wird“ (Quelle).
Wie lässt sich die Stichhaltigkeit der oben genannten Behauptung beurteilen? Der Datensatz enthält eine Spalte mit der Bezeichnung „Advanced Plus-Minus“, bei der es sich um „einen Wert handelt, der die Ergebnisse eines Meinungsforschungsinstituts mit denen anderer Meinungsforschungsinstitute vergleicht, die dieselben Rennen untersuchen, und der die jüngsten Ergebnisse stärker gewichtet. Negative Werte sind günstig und weisen auf eine überdurchschnittliche Qualität hin“ (Quelle).
Hier ist ein Boxplot zwischen diesen beiden Parametern. Die Meinungsforscher, die mit NCCP/AAPOR/Roper assoziiert sind, weisen nicht nur eine niedrigere Fehlerquote auf, sondern auch eine deutlich geringere Variabilität. Ihre Vorhersagen scheinen stabil und robust zu sein.

Wenn Sie ein progressiver, liberal denkender Mensch sind, werden Sie aller Wahrscheinlichkeit nach der Demokratischen Partei angehören. Aber im Durchschnitt sagen die Meinungsforscher mit republikanischer Tendenz die Wahlen genauer und mit weniger Schwankungen voraus.
Streuungs- und Regressionsdiagramme
Um die Korrelation zwischen den Parametern zu verstehen, können wir uns die Streuungsdiagramme mit Regressionsanpassung ansehen. Wir verwenden die Python-Bibliotheken Seaborn und Scipy und eine angepasste Funktion zur Erstellung dieser Diagramme.
Zum Beispiel können wir die „Races Called Correctly“ mit dem „Predictive Plus-Minus“ in Beziehung setzen. Laut Five-Thirty-Eight ist der „Predictive Plus-Minus“ „eine Prognose darüber, wie genau der Meinungsforscher bei zukünftigen Wahlen sein wird. Er wird berechnet, indem der Advanced Plus-Minus-Wert eines Meinungsforschers auf einen Mittelwert zurückgeführt wird, der auf unseren Proxies für methodische Qualität basiert.“ (Quelle)

Oder wir können prüfen, wie die von uns definierte „Numerische Note“ mit dem Durchschnitt der Meinungsumfragefehler korreliert. Ein negativer Trend deutet darauf hin, dass ein höherer numerischer Wert mit einem niedrigeren Umfragefehler einhergeht.

Wir können auch prüfen, ob die „Anzahl der Umfragen für die Parteilichkeitsanalyse“ dazu beiträgt, den „Grad der parteilichen Parteilichkeit“, der jedem Meinungsforscher zugewiesen wird, zu verringern. Wir können eine abwärts gerichtete Beziehung beobachten, was darauf hindeutet, dass die Verfügbarkeit einer großen Anzahl von Umfragen dazu beiträgt, den Grad der parteiischen Voreingenommenheit zu verringern. Die Beziehung scheint jedoch stark nichtlinear zu sein, und eine logarithmische Skalierung wäre für die Anpassung der Kurve besser gewesen.

Kann man aktiveren Meinungsforschern mehr trauen? Wir zeichnen das Histogramm der Anzahl der Umfragen auf und sehen, dass es einem negativen Potenzgesetz folgt. Wir können die Meinungsforscher mit einer sehr niedrigen und einer sehr hohen Zahl von Umfragen herausfiltern und ein eigenes Streudiagramm erstellen. Wir stellen jedoch fest, dass zwischen der Anzahl der Umfragen und dem Predictive Plus-Minus-Wert fast keine Korrelation besteht. Daher führt eine große Anzahl von Umfragen nicht unbedingt zu einer hohen Umfragequalität und Vorhersagekraft.