




Hoe goed zijn de opiniepeilers? Analyse van de dataset van Five-Thirty-Eight
We analyseren de dataset met pollers van de eerbiedwaardige politieke voorspellingswebsite Five-Thirty-Eight.

Dit is een verkiezingsjaar en de opiniepeilingen rond de verkiezingen (zowel de algemene presidentsverkiezingen als de verkiezingen voor het Huis van Afgevaardigden en de Senaat) zijn in volle gang. Dit zal de komende dagen steeds spannender worden, met tweets, counter-tweets, gevechten op sociale media en eindeloze punditry op de televisie.
We weten dat niet alle peilingen van dezelfde kwaliteit zijn. Dus, hoe maak je zin van dit alles? Hoe identificeer je betrouwbare opiniepeilers met behulp van gegevens en analyses?

In de wereld van politieke (en sommige andere zaken zoals sport, sociale fenomenen, economie, enz.) voorspellende analyses is Five-Thirty-Eight een geduchte naam.
Sinds begin 2008 publiceert de site artikelen – waarbij meestal statistische informatie wordt opgesteld of geanalyseerd – over een breed scala aan onderwerpen in de huidige politiek en het politieke nieuws. De website, gerund door de rockstar datawetenschapper en statisticus Nate Silver, bereikte bijzondere bekendheid en wijdverspreide roem rond de presidentsverkiezingen van 2012 toen zijn model de winnaar van alle 50 staten en het District of Columbia correct voorspelde.
En voordat u spot en zegt “Maar hoe zit het dan met de verkiezingen van 2016?”, kunt u er goed aan doen dit stuk te lezen over hoe de verkiezing van Donald Trump binnen de normale foutmarge van statistische modellering lag.
Voor de meer politiek-geïnteresseerde lezers hebben ze hier een hele zak met artikelen over de verkiezingen van 2016.
Data science beoefenaars zouden Five-Thirty-Eight een warm hart moeten toedragen omdat ze er niet voor terugdeinzen hun voorspellende modellen uit te leggen in termen van zeer technische termen (in ieder geval complex genoeg voor de leek).

Hier hebben ze het over het gebruik van de beroemde t-verdeling, terwijl de meeste andere opiniepeilers wellicht genoegen nemen met de alomtegenwoordige normale verdeling.
Het team onder leiding van Silver gaat echter verder dan het gebruik van geavanceerde statistische modelleringstechnieken en gaat prat op een unieke methodologie – pollster rating – om ervoor te zorgen dat hun modellen uiterst nauwkeurig en betrouwbaar blijven.
In dit artikel analyseren we hun gegevens over deze ratingmethoden.
Five-Thirty-Eight schrikt er niet voor terug om hun voorspellende modellen in zeer technische termen uit te leggen (in ieder geval ingewikkeld genoeg voor leken).
Pollster rating and ranking
Er is een veelheid aan opiniepeilers actief in dit land. Het lezen en beoordelen van de kwaliteit van deze opiniepeilers kan zeer vermoeiend en moeilijk zijn. Op de website staat: “Het lezen van opiniepeilingen kan gevaarlijk zijn voor je gezondheid. Symptomen zijn kersen plukken, overmoed, vallen voor junky cijfers, en overhaast oordelen. Gelukkig hebben we een remedie.” (bron)
Er zijn peilingen. Dan, zijn er opiniepeilingen van opiniepeilingen. Dan zijn er gewogen peilingen van peilingen. Bovenal is er een peiling van peilingen met gewichten die statistisch gemodelleerd zijn en dynamisch veranderen.
Klinkt dit bekend in de oren van andere beroemde rangschikkingsmethodologieën waar je als datawetenschapper over hebt gehoord? Amazon’s product ranking of Netflix’s film ranking? Waarschijnlijk wel.
Essentially, Five-Thirty-Eight gebruikt dit rating/ranking systeem om de poll resultaten te wegen (hoog gerangschikte pollers’ resultaten krijgen een hoger belang en zo en zo). Ze houden ook actief de nauwkeurigheid en methodologieën achter de resultaten van elke opiniepeiler bij en passen hun rangorde in de loop van het jaar aan.
Er zijn opiniepeilingen. Dan zijn er opiniepeilingen van opiniepeilingen. Dan zijn er gewogen opiniepeilingen van opiniepeilingen. En bovenal is er een peiling van peilingen met statistisch gemodelleerde en dynamisch veranderende gewichten.
Het is interessant om op te merken dat hun rangschikkingsmethode een opiniepeiler met een grotere steekproefomvang niet noodzakelijkerwijs als een betere beoordeelt. De volgende schermafbeelding van hun website laat dit duidelijk zien. Hoewel opiniepeilers als Rasmussen Reports en HarrisX een grotere steekproefomvang hebben, is het in feite Marist College dat een A+ rating krijgt met een bescheiden steekproefomvang.
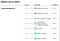
Gelukkig zijn de gegevens van hun opiniepeilingen (samen met bijna al hun andere datasets) ook open source, hier op Github. En als u alleen geïnteresseerd bent in een mooi ogende tabel, hier is hij.
Natuurlijk wil je als datawetenschapper dieper in de ruwe gegevens kijken en dingen begrijpen als,
- hoe hun numerieke rangschikking correleert met de nauwkeurigheid van de opiniepeilers
- als ze een partijdige vooringenomenheid hebben bij het selecteren van bepaalde opiniepeilers (in de meeste gevallen kunnen ze worden gecategoriseerd als Democratisch-gezind of Republikeins-gezind)
- wie zijn de top-rated opiniepeilers? Voeren ze veel peilingen uit of zijn ze selectief?
We hebben geprobeerd de dataset te analyseren om dergelijke inzichten te verkrijgen. Laten we eens graven in de code en de bevindingen, zullen we?
De analyse
Je kunt het Jupyter Notebook hier vinden op mijn Github repo.
De bron
Om te beginnen, kunt u de gegevens rechtstreeks van hun Github, in een Pandas DataFrame, als volgt,

Er zijn 23 kolommen in deze dataset. Zo zien ze eruit,

Enige transformatie en opschoning
We zien dat een kolom wat extra ruimte heeft. Een paar andere kolommen moeten wellicht worden geëxtraheerd en van een gegevenstype worden voorzien.



Na toepassing van deze extractie, heeft het nieuwe DataFrame extra kolommen, waardoor het beter geschikt is voor filtering en statistische modellering.

Onderzoeken en kwantificeren van de kolom “538 Grades”
De kolom “538 Grades” bevat de crux van de dataset – het lettercijfer voor de opiniepeiler. Net als bij een gewoon examen is A+ beter dan A, en A is beter dan B+. Als we de tellingen van de lettercijfers plotten, zien we in totaal 15 gradaties, van A+ tot F.

In plaats van met zoveel categorische gradaties te werken, willen we ze misschien combineren tot een klein aantal numerieke gradaties – 4 voor A+/A/A-, 3 voor de B’s, enz.

Boxplots
Op het gebied van visuele analyse kunnen we beginnen met boxplots.
Stel dat we willen nagaan welke peilingmethode beter presteert in termen van voorspellingsfout. De dataset heeft een kolom genaamd “Simple Average Error”, die is gedefinieerd als “De gemiddelde fout van het bedrijf, berekend als het verschil tussen het gepeilde resultaat en het werkelijke resultaat voor de marge die de top twee finishers in de race scheidt.”

Dan kunnen we geïnteresseerd zijn in het nagaan of opiniepeilers met een bepaalde partijdige voorkeur er beter in slagen de verkiezingen correct te noemen dan anderen.

Merkt u hierboven iets interessants op? Als u een progressieve, liberale denker bent, bent u naar alle waarschijnlijkheid partijdig aan de Democratische partij. Maar gemiddeld genomen noemen de opiniepeilers met een Republikeinse voorkeur de verkiezingen nauwkeuriger en met minder variabiliteit. Pas maar op voor die peilingen!
Een andere interessante kolom in de dataset heet “NCPP/AAPOR/Roper”. Deze kolom “geeft aan of het opiniebureau lid was van de National Council on Public Polls, het transparantie-initiatief van de American Association for Public Opinion Research heeft ondertekend, of een bijdrage heeft geleverd aan het gegevensarchief van het Roper Center for Public Opinion Research. In feite geeft een lidmaatschap aan dat men zich houdt aan een robuustere opiniepeilingsmethode” (bron).
Hoe kan men de geldigheid van de bovengenoemde bewering beoordelen? De dataset heeft een kolom met de naam “Advanced Plus-Minus”, die “een score is die het resultaat van een opiniepeiler vergelijkt met dat van andere opiniepeilers die dezelfde wedstrijden onderzoeken en die recente resultaten zwaarder laat meewegen. Negatieve scores zijn gunstig en wijzen op een bovengemiddelde kwaliteit” (bron).
Hier ziet u een boxplot tussen deze twee parameters. Niet alleen vertonen de opiniepeilers, verbonden aan NCCP/AAPOR/Roper, een lagere foutenscore, maar zij vertonen ook een aanzienlijk geringe variabiliteit. Hun voorspellingen lijken stabiel en robuust te zijn.

Als u een progressieve, liberale denker bent, bent u naar alle waarschijnlijkheid partijdig aan de Democratische partij. Maar gemiddeld genomen noemen de opiniepeilers met een Republikeinse voorkeur de verkiezingen nauwkeuriger en met minder variabiliteit.
Scatter plots en regressie plots
Om de correlatie tussen parameters te begrijpen, kunnen we kijken naar de scatter plots met regressie fit. Wij gebruiken de Seaborn en Scipy Python bibliotheken en een aangepaste functie voor het genereren van deze plots.
Om een voorbeeld te geven, kunnen wij de “Races Called Correctly” relateren aan de “Predictive Plus-Minus”. Volgens Five-Thirty-Eight is de “Predictive Plus-Minus” “een projectie van hoe nauwkeurig de opiniepeiler zal zijn bij toekomstige verkiezingen. Het wordt berekend door de Advanced Plus-Minus score van een opiniepeiler terug te brengen naar een gemiddelde op basis van onze maatstaven voor methodologische kwaliteit.” (bron)

Of, we kunnen nagaan hoe de “Numeric Grade” die we gedefinieerd hebben, correleren met het gemiddelde van de peilingfouten. Een negatieve trend geeft aan dat een hogere numerieke graad samenhangt met een lagere peilingfout.

We kunnen ook nagaan of het “aantal peilingen voor vertekeningsanalyse” helpt bij het verlagen van de “Partijdige vertekeningsgraad” die aan elke opiniepeiler wordt toegekend. We kunnen een neerwaartse relatie waarnemen, wat erop wijst dat de beschikbaarheid van een groot aantal opiniepeilingen de mate van partijdige vooringenomenheid helpt te verminderen. Het verband lijkt echter zeer niet-lineair en een logaritmische schaling zou beter zijn geweest om de curve te passen.

Moeten meer actieve opiniepeilers meer worden vertrouwd? We plotten het histogram van het aantal peilingen en zien dat het een negatieve machtswet volgt. We kunnen de opiniepeilers met zowel een zeer laag als een zeer hoog aantal peilingen eruit filteren en een aangepaste spreidingsdiagram maken. We zien echter een bijna onbestaande correlatie tussen het aantal peilingen en de voorspellende Plus-Minus score. Een groot aantal peilingen leidt dus niet noodzakelijk tot een hoge peilingkwaliteit en voorspellende kracht.