




Introductie tot Database Design
Identifying Attributes
De data-elementen die je voor elke entiteit wilt opslaan, worden ‘attributen’ genoemd.
Van de producten die je verkoopt, wil je bijvoorbeeld weten wat de prijs is, wat de naam van de fabrikant is, en wat het typenummer is. Van de klanten weet u hun klantnummer, hun naam, en hun adres. Van de winkels weet je de locatiecode, de naam, het adres. Van de verkopen weet je wanneer ze hebben plaatsgevonden, in welke winkel, welke producten er zijn verkocht, en het totaalbedrag van de verkoop. Van de verkoper weet je zijn personeelsnummer, naam, en adres. Wat er precies in komt te staan is nog niet van belang; het gaat er alleen nog om wat u wilt bewaren.
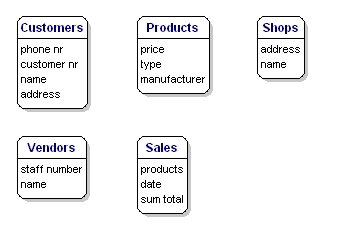
Figuur 6: Entiteiten met attributen.
Gegevens die zijn afgeleid
Gegevens die zijn afgeleid van de andere gegevens die u al hebt opgeslagen. In dit geval is het “totaalbedrag” een klassiek geval van afgeleide gegevens. U weet precies wat er is verkocht en wat elk product kost, zodat u altijd kunt berekenen hoeveel de som van de verkopen is. Het is dus eigenlijk niet nodig om het totaal op te slaan.
Waarom wordt het dan hier opgeslagen? Wel, omdat het een verkoop is, en de prijs van het produkt kan in de loop der tijd variëren. Een product kan vandaag 10 euro kosten en volgende maand 8 euro, en voor uw administratie moet u weten wat het kostte op het moment van de uitverkoop, en de gemakkelijkste manier om dat te doen is het hier op te slaan. Er zijn veel elegantere manieren, maar die zijn te diepzinnig voor dit artikel.
Presenteren van Entiteiten en Relaties: Entity Relationship Diagram (ERD)
Het Entity Relationship Diagram (ERD) geeft een grafisch overzicht van de database. Er zijn verschillende stijlen en typen ER Diagrams. Een veelgebruikte notatie is de “crowfeet” notatie, waarbij entiteiten worden weergegeven als rechthoeken en de relaties tussen de entiteiten worden weergegeven als lijnen tussen de entiteiten. De tekens aan het eind van de lijnen geven het type relatie aan. De zijde van de relatie die verplicht is voor het bestaan van de andere wordt aangegeven met een streepje op de lijn. Niet verplichte entiteiten worden aangegeven met een cirkel. “Veel” wordt aangegeven door een “kraaienpoot”; de relatie-lijn splitst zich op in drie lijnen.
In dit artikel maken we gebruik van DeZign for Databases om onze database te ontwerpen en te presenteren.
Een 1:1 verplichte relatie wordt als volgt weergegeven:
Figuur 7: Verplichte één op één relatie.
Een 1:N verplichte relatie:
Figuur 8: Verplichte één-op-veel relatie.
Een M:N-relatie is:
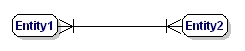
Figuur 9: Verplichte veel-op-veel-relatie.
Het model van ons voorbeeld ziet er als volgt uit:
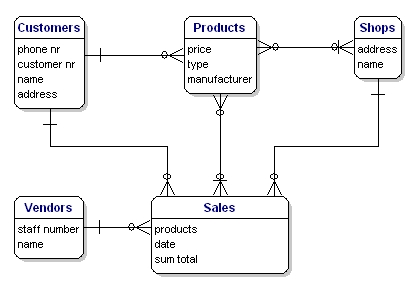
Figuur 10: Model met relaties.
Het toewijzen van sleutels
Priminaire sleutels
Een primaire sleutel (PK) is een of meer gegevensattributen die een entiteit op unieke wijze identificeren. Een sleutel die uit twee of meer attributen bestaat, wordt een samengestelde sleutel genoemd. Alle attributen die deel uitmaken van een primaire sleutel moeten in elk record een waarde hebben (die niet leeg mag blijven) en de combinatie van de waarden binnen deze attributen moet uniek zijn in de tabel.
In het voorbeeld zijn er een paar voor de hand liggende kandidaten voor de primaire sleutel. Klanten hebben allemaal een klantnummer, producten hebben allemaal een uniek productnummer en de verkoop heeft een verkoopnummer. Elk van deze gegevens is uniek en elk record zal een waarde bevatten, dus deze attributen kunnen een primaire sleutel zijn. Vaak wordt een kolom met een geheel getal gebruikt voor de primaire sleutel, zodat een record gemakkelijk kan worden gevonden aan de hand van het nummer.
Link-entities verwijzen meestal naar de primaire-sleutelattributen van de entiteiten die ze koppelen. De primaire sleutel van een link-entiteit is gewoonlijk een verzameling van deze referentie-attributen. Bijvoorbeeld in de Sales_details entiteit zouden we de combinatie van de PK’s van de sales en products entiteiten kunnen gebruiken als de PK van Sales_details. Op deze manier dwingen we af dat hetzelfde product(type) slechts eenmaal in dezelfde verkoop kan worden gebruikt. Meerdere artikelen van hetzelfde producttype in een verkoop moeten worden aangegeven met de hoeveelheid.
In de ERD worden de primary key attributen aangegeven met de tekst ‘PK’ achter de naam van het attribuut. In het voorbeeld heeft alleen de entiteit ‘winkel’ geen voor de hand liggende kandidaat voor de PK, dus zullen we voor die entiteit een nieuw attribuut introduceren: shopnr.
Foreign Keys
De Foreign Key (FK) in een entiteit is de verwijzing naar de primaire sleutel van een andere entiteit. In de ERD wordt dat attribuut aangeduid met “FK” achter de naam. De foreign key van een entiteit kan ook onderdeel zijn van de primary key, in dat geval wordt het attribuut aangeduid met “PF” achter de naam. Dit is meestal het geval bij de link-entiteiten, omdat je twee instanties meestal maar 1 keer aan elkaar koppelt (bij 1 verkoop wordt maar 1 keer 1 producttype verkocht).
Als we alle link-entiteiten, PK’s en FK’s in de ERD zetten, krijgen we het model zoals hieronder is weergegeven. Merk op dat het attribuut “producten” niet meer nodig is in “Verkoop”, omdat “verkochte producten” nu in de link-tabel is opgenomen. In de koppeltabel werd nog een veld toegevoegd, “hoeveelheid”, dat aangeeft hoeveel producten werden verkocht. Het hoeveelheidsveld werd ook toegevoegd in de voorraad-tabel, om aan te geven hoeveel producten er nog in voorraad zijn.
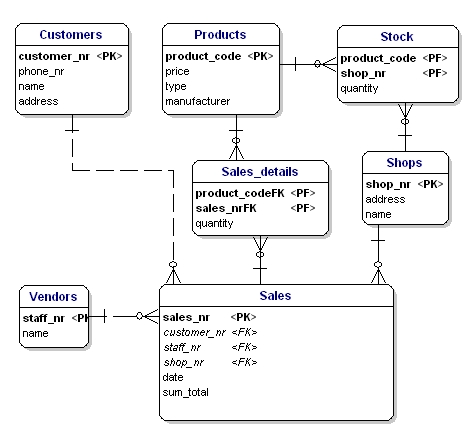
Figuur 11: Primaire sleutels en vreemde sleutels.
Het gegevenstype van het attribuut bepalen
Nu is het tijd om uit te zoeken welke gegevenstypen voor de attributen moeten worden gebruikt. Er zijn een heleboel verschillende datatypes. Een paar zijn gestandaardiseerd, maar veel databases hebben hun eigen datatypes die allemaal hun eigen voordelen hebben. Sommige databases bieden de mogelijkheid om je eigen datatypes te definiëren, voor het geval de standaardtypes niet kunnen wat je nodig hebt.
De standaard gegevenstypen die elke database kent, en die het meest gebruikt worden, zijn: CHAR, VARCHAR, TEXT, FLOAT, DOUBLE, en INT.
Text:
- CHAR(lengte) – bevat tekst (tekens, cijfers, interpunctie…). CHAR heeft als eigenschap dat het altijd een vast aantal posities opslaat. Als u een CHAR(10) definieert, kunt u maximaal tien posities opslaan, maar als u slechts twee posities gebruikt, zal de database toch 10 posities opslaan. De resterende acht posities zullen worden opgevuld met spaties.
- VARCHAR(lengte) – bevat tekst (tekens, cijfers, interpunctie…). VARCHAR is hetzelfde als CHAR, het verschil is dat VARCHAR slechts zoveel ruimte inneemt als nodig is.
- TEXT – kan grote hoeveelheden tekst bevatten. Afhankelijk van het type database kan dit oplopen tot gigabytes.
Numbers:
- INT – bevat een positief of negatief geheel getal. Veel databases kennen variaties op de INT, zoals TINYINT, SMALLINT, MEDIUMINT, BIGINT, INT2, INT4, INT8. Deze variaties verschillen van de INT alleen in de grootte van het getal dat erin past. Een gewone INT is 4 bytes (INT4) en er passen cijfers in van -2147483647 tot +2147483646, of als u hem als UNSIGNED definieert van 0 tot 4294967296. De INT8, of BIGINT, kan nog groter worden, van 0 tot 18446744073709551616, maar neemt wel 8 bytes schijfruimte in, zelfs als er maar een klein getal in zit.
- FLOAT, DOUBLE – Hetzelfde idee als INT, maar kan ook drijvende komma getallen opslaan. . Merk op dat dit niet altijd perfect werkt. Bijvoorbeeld in MySQL is het rekenen met deze floating point getallen niet perfect, (1/3)*3 zal met MySQL’s floats resulteren in 0.9999999, niet 1.
Andere types:
- BLOB – voor binaire data zoals bestanden.
- INET – voor IP adressen. Ook te gebruiken voor netmasks.
In ons voorbeeld zijn de gegevenstypen als volgt:
Figuur 12: Gegevensmodel met de gegevenstypen.
Normalisatie
Normalisatie maakt uw gegevensmodel flexibel en betrouwbaar. Het genereert wel wat overhead omdat je meestal meer tabellen krijgt, maar het stelt je in staat om veel dingen met je datamodel te doen zonder dat je het hoeft aan te passen. Meer over databasenormalisatie leest u in dit artikel.
Normalisatie, de eerste vorm
De eerste vorm van normalisatie stelt dat er geen herhalende groepen kolommen in een entiteit mogen zijn. We hadden een entiteit “verkoop” kunnen maken met attributen voor elk van de gekochte producten. Dit zou er als volgt uitzien:

Figuur 13: Niet in de 1e normaalvorm.
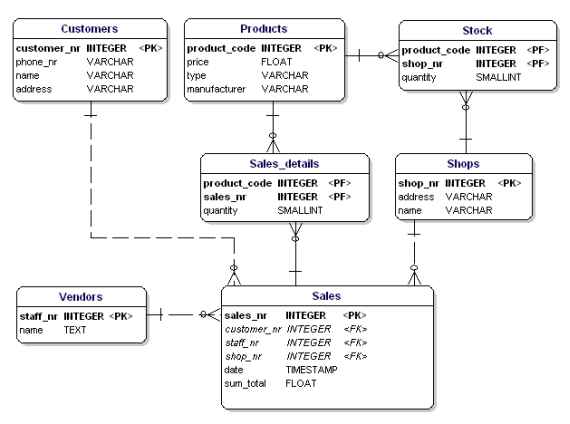
Wat hier fout aan is, is dat er nu maar 3 producten kunnen worden verkocht. Als je 4 producten zou moeten verkopen dan zou je een tweede verkoop moeten starten of je datamodel moeten aanpassen door ‘product4’ attributen toe te voegen. Beide oplossingen zijn ongewenst. In deze gevallen moet je altijd een nieuwe entiteit maken die je koppelt aan de oude entiteit via een one-to-many relatie.
Figuur 14: In overeenstemming met de 1e normale vorm.
Normalisatie, de tweede vorm
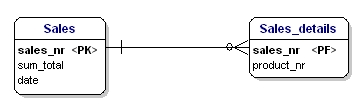
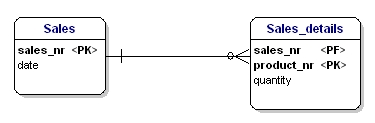
De tweede vorm van normalisatie stelt dat alle attributen van een entiteit volledig afhankelijk moeten zijn van de gehele primaire sleutel. Dit betekent dat elk attribuut van een entiteit alleen kan worden geïdentificeerd via de gehele primaire sleutel. Stel dat we de datum in de Sales_details entiteit hadden:

Figuur 15: Niet in 2e normale vorm.
Deze entiteit is niet volgens de 2e normalisatievorm, want om de datum van een verkoop te kunnen opzoeken, hoef ik niet te weten wat er verkocht is (productnr), het enige wat ik moet weten is het verkoopnummer. Dit werd opgelost door de tabellen op te splitsen in de tabel Verkoop en de tabel Verkoop_details:
Figuur 16: In overeenstemming met de 2e normale vorm.
Nu is elk attribuut van de entiteiten afhankelijk van de hele PK van de entiteit. De datum is afhankelijk van het verkoopnummer, en de hoeveelheid is afhankelijk van het verkoopnummer en het verkochte product.
Normalisatie, de derde vorm
De derde vorm van normalisatie stelt dat alle attributen direct afhankelijk moeten zijn van de primaire sleutel, en niet van andere attributen. Dit lijkt te zijn wat de tweede vorm van normalisatie stelt, maar in de tweede vorm wordt eigenlijk het tegenovergestelde gesteld. Bij de tweede vorm van normalisatie wijs je attributen aan via de PK, bij de derde vorm van normalisatie moet elk attribuut afhankelijk zijn van de PK, en van niets anders.

Figuur 17: Niet in de derde normalisatievorm.
In dit geval is de prijs van een los product afhankelijk van het bestelnummer, en is het bestelnummer afhankelijk van het productnummer en het verkoopnummer. Dit is niet volgens de derde vorm van normalisatie. Opnieuw lost het opsplitsen van de tabellen dit op.
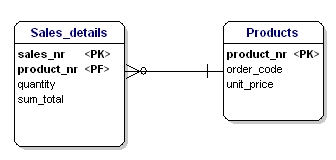
Figuur 18: In overeenstemming met de derde normalisatievorm.
Normalisatie, meer vormen
Er zijn meer normalisatievormen dan de drie hierboven genoemde, maar die zijn niet van groot belang voor de gemiddelde gebruiker. Deze andere vormen zijn zeer gespecialiseerd voor bepaalde toepassingen. Als u zich houdt aan de ontwerpregels en de normalisatie die in dit artikel zijn genoemd, zult u een ontwerp maken dat voor de meeste toepassingen uitstekend werkt.
Normalized Data Model
Als u de normalisatieregels toepast, zult u zien dat de ‘fabrikant’ in de producttabel ook een aparte tabel moet zijn:
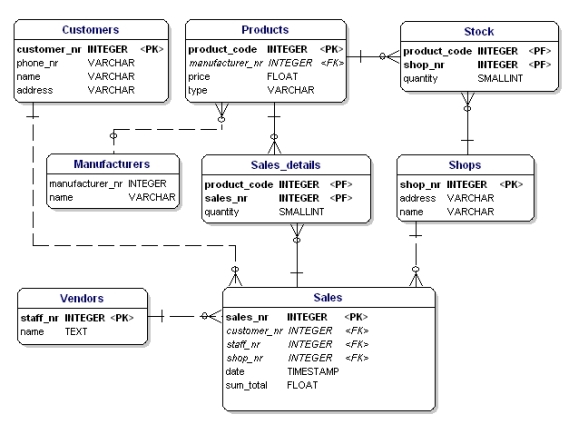
Figuur 19: Gegevensmodel volgens de 1e, 2e en 3e normale vorm.