




Analisi statistica: Significatività e intervalli di confidenza
In qualsiasi analisi statistica, è probabile che si lavori con un campione, piuttosto che con i dati dell’intera popolazione. Il vostro risultato potrebbe quindi non rappresentare l’intera popolazione – e potrebbe anche essere molto impreciso se il campionamento non è stato molto buono.
Avete quindi bisogno di un modo per misurare quanto siete certi che il vostro risultato sia accurato e non si sia verificato semplicemente per caso. Gli statistici usano due concetti collegati per questo: fiducia e significatività.
Questa pagina spiega questi concetti.
Significatività statistica
Il termine significatività ha un significato molto particolare in statistica. Ti dice quanto è probabile che il tuo risultato non si sia verificato per caso.

Nel diagramma, il cerchio blu rappresenta l’intera popolazione. Quando prendete un campione, il vostro campione potrebbe provenire da tutta la popolazione. Tuttavia, è più probabile che sia più piccolo. Se è tutto all’interno del cerchio giallo, avresti coperto un bel po’ della popolazione. Tuttavia, potreste anche essere sfortunati (o aver progettato male la vostra procedura di campionamento), e campionare solo dal piccolo cerchio rosso. Questo avrebbe serie implicazioni sul fatto che il vostro campione sia rappresentativo dell’intera popolazione.
Uno dei modi migliori per assicurarsi di coprire più popolazione è usare un campione più grande. La dimensione del campione influisce fortemente sull’accuratezza dei vostri risultati (e c’è di più su questo nella nostra pagina su Campionamento e disegno del campione).
Tuttavia, anche un altro elemento influisce sull’accuratezza: la variazione all’interno della popolazione stessa. Potete valutarla guardando le misure della diffusione dei vostri dati (e per saperne di più su questo, consultate la nostra pagina su Analisi statistica semplice). Dove c’è più variazione, c’è più possibilità che tu scelga un campione che non è tipico.
Il concetto di significatività riunisce semplicemente la dimensione del campione e la variazione della popolazione, e fa una valutazione numerica delle possibilità che tu abbia commesso un errore di campionamento: cioè, che il tuo campione non rappresenti la tua popolazione.
La significatività è espressa come una probabilità che i tuoi risultati siano avvenuti per caso, comunemente nota come valore p. In genere si cerca che sia inferiore a un certo valore, di solito 0,05 (5%) o 0,01 (1%), anche se alcuni risultati riportano anche 0,10 (10%).
Ipotesi nulla e alternativa
Quando si esegue un esperimento o una ricerca di mercato, in genere si vuole sapere se ciò che si sta facendo ha un effetto. Si può quindi esprimere come ipotesi:
-x avrà un effetto su y.
Questa è conosciuta in statistica come “ipotesi alternativa”, spesso chiamata H1.
L'”ipotesi nulla”, o H0, è che x non ha alcun effetto su y.
Statisticamente parlando, lo scopo del test di significatività è quello di vedere se i risultati suggeriscono che è necessario rifiutare l’ipotesi nulla – nel qual caso, l’ipotesi alternativa è più probabile che sia vera.
Se i tuoi risultati non sono significativi, non puoi rifiutare l’ipotesi nulla e devi concludere che non c’è alcun effetto.
Il valore p è la probabilità che avresti ottenuto i risultati che hai ottenuto se l’ipotesi nulla è vera.
Calcolo della significatività
Un modo per calcolare la significatività è usare un punteggio z. Questo descrive la distanza di un punto di dati dalla media, in termini di numero di deviazioni standard (per saperne di più su media e deviazione standard, vedi la nostra pagina su Analisi statistica semplice).
Per un semplice confronto, lo z-score è calcolato usando la formula:
$$z=frac{x – \mu}{sigma}$$
dove \(x\) è il punto dei dati, \(\mu\) è la media della popolazione o distribuzione, e \(\sigma\) è la deviazione standard.
Per esempio, supponiamo di voler verificare se un’applicazione di gioco è più popolare di altri giochi. Diciamo che l’app gioco mediamente viene scaricata 1000 volte, con una deviazione standard di 110. Il nostro gioco è stato scaricato 1200 volte. Il suo punteggio z è:
$$z=\frac{1200-1000}{110}=1.81$$
Un punteggio z più alto segnala che il risultato è meno probabile che si sia verificato per caso.
Puoi usare una tabella statistica z standard per convertire il tuo punteggio z in un valore p. Se il vostro p-value è inferiore al livello di significatività desiderato, allora i vostri risultati sono significativi.
Utilizzando la tabella z, lo z-score per la nostra game app (1,81) si converte in un p-value di 0,9649. Questo è meglio del nostro livello desiderato del 5% (0,05) (perché 1-0,9649 = 0,0351, o 3,5%), quindi possiamo dire che questo risultato è significativo.
Nota che c’è una leggera differenza per un campione da una popolazione, dove lo z-score è calcolato usando la formula:
$$z=frac{(x-\mu)}{(\sigma/\sqrt n)}$$
dove x è il punto dei dati (solitamente la media del campione), µ è la media della popolazione o distribuzione, σ è la deviazione standard, e √n è la radice quadrata della dimensione del campione.
Un esempio renderà tutto più chiaro.
Supponiamo che stiate controllando se gli studenti di biologia tendono ad ottenere voti migliori dei loro compagni che studiano altre materie. Potreste scoprire che il voto medio per un campione di 40 biologi è 80, con una deviazione standard di 5, rispetto a 78 per tutti gli studenti di quella università o scuola.
$$z=frac{(80-78)}{(5/\sqrt 40)}=2.53$$
Utilizzando la tabella z, 2.53 corrisponde a un p-value di 0.9943. Potete sottrarre questo da 1 per ottenere 0,0054. Questo è inferiore all’1%, quindi possiamo dire che questo risultato è significativo al livello dell’1%, e che i biologi ottengono risultati migliori nei test rispetto alla media degli studenti di questa università.
Nota che questo non significa necessariamente che i biologi sono più intelligenti o migliori nel superare i test di quelli che studiano altre materie. Potrebbe, infatti, significare che i test di biologia sono più facili di quelli di altre materie. Trovare un risultato significativo NON è una prova di causalità, ma vi dice che potrebbe esserci un problema che volete esaminare.
C’è di più sui test di significatività delle medie dei campioni, e sulle differenze di test tra gruppi, nella nostra pagina su Sviluppo e test di ipotesi.
Intervalli di confidenza
Un intervallo di confidenza (o livello di confidenza) è un intervallo di valori che hanno una data probabilità che il valore vero si trovi al suo interno.
Effettivamente, misura quanto siete sicuri che la media del vostro campione (la media del campione) sia la stessa della media della popolazione totale da cui il vostro campione è stato preso (la media della popolazione).
Per esempio, se la vostra media è 12,4, e il vostro intervallo di confidenza al 95% è 10,3-15,6, questo significa che siete sicuri al 95% che il vero valore della vostra media della popolazione sia compreso tra 10,3 e 15,6. In altre parole, potrebbe non essere 12,4, ma sei ragionevolmente sicuro che non sia molto diverso.
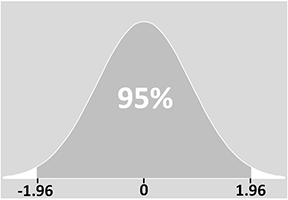
Il diagramma qui sotto mostra questo in pratica per una variabile che segue una distribuzione normale (per saperne di più, vedi la nostra pagina sulle distribuzioni statistiche).

Il significato preciso di un intervallo di confidenza è che se tu dovessi fare il tuo esperimento molte, molte volte, il 95% degli intervalli che hai costruito da questi esperimenti conterrebbe il vero valore. In altre parole, nel 5% dei tuoi esperimenti, il tuo intervallo NON conterrebbe il vero valore.
Puoi vedere dal diagramma che c’è un 5% di possibilità che l’intervallo di confidenza non includa la media della popolazione (le due “code” del 2,5% su entrambi i lati). In altre parole, in uno su 20 campioni o esperimenti, il valore che otteniamo per l’intervallo di confidenza non includerà la vera media: la media della popolazione cadrà effettivamente al di fuori dell’intervallo di confidenza.
Calcolo dell’intervallo di confidenza
Il calcolo di un intervallo di confidenza utilizza i valori del tuo campione e alcune misure standard (media e deviazione standard) (e per maggiori informazioni su come calcolarle, vedi la nostra pagina su Analisi statistica semplice).
È più facile da capire con un esempio.
Supponiamo di aver campionato l’altezza di un gruppo di 40 persone e di aver scoperto che la media era 159,1 cm, e la deviazione standard era 25,4.
Deviazione standard per gli intervalli di confidenza
Idealmente, si dovrebbe usare la deviazione standard della popolazione per calcolare l’intervallo di confidenza. Tuttavia, è molto improbabile che tu sappia quale fosse.
Per fortuna, si può usare la deviazione standard del campione, purché si abbia un campione abbastanza grande. Il punto limite è generalmente concordato per una dimensione del campione di 30 o più, ma più grande è, meglio è.
Abbiamo bisogno di capire se la nostra media è una stima ragionevole delle altezze di tutte le persone, o se abbiamo scelto un campione particolarmente alto (o basso).
Usiamo una formula per calcolare un intervallo di confidenza. Questa è:
$$mean \pm z \frac{(SD)}{sqrt n}$$
Dove SD = deviazione standard, e n è il numero di osservazioni o la dimensione del campione.
Il valore z è preso dalle tabelle statistiche per la nostra distribuzione di riferimento scelta. Queste tabelle forniscono il valore z per un particolare intervallo di confidenza (ad esempio, 95% o 99%).
In questo caso, stiamo misurando le altezze delle persone, e sappiamo che le altezze della popolazione seguono una distribuzione (grosso modo) normale (per saperne di più, vedi la nostra pagina sulle distribuzioni statistiche).Possiamo quindi utilizzare i valori per una distribuzione normale.
Il valore z per un intervallo di confidenza del 95% è 1,96 per la distribuzione normale (preso da tabelle statistiche standard).
Utilizzando la formula sopra, l’intervallo di confidenza del 95% è quindi:
$$159,1 \pm 1,96 \frac{(25,4)}{sqrt 40}$$
Facendo questo calcolo, troviamo che l’intervallo di confidenza è 151,23-166,97 cm. È quindi ragionevole dire che siamo quindi sicuri al 95% che la media della popolazione cada in questo intervallo.
Comprensione del punteggio z o valore z
Il punteggio z è una misura delle deviazioni standard dalla media. Nel nostro esempio, quindi, sappiamo che il 95% dei valori cadrà entro ± 1,96 deviazioni standard dalla media:
Valutare il tuo intervallo di confidenza
Come regola generale, un piccolo intervallo di confidenza è meglio. L’intervallo di confidenza si restringe all’aumentare della dimensione del campione, motivo per cui è sempre preferibile un campione più grande. Come spiega la nostra pagina sul campionamento e il disegno del campione, il tuo esperimento ideale dovrebbe coinvolgere l’intera popolazione, ma questo non è solitamente possibile.
Conclusione
Gli intervalli di confidenza e la significatività sono modi standard per mostrare la qualità dei tuoi risultati statistici. Ci si aspetta che tu li riporti abitualmente quando effettui un’analisi statistica, e in genere dovresti riportare cifre precise. Questo assicurerà che la tua ricerca sia valida e affidabile.
.