




Introduzione al Database Design
Identificazione degli attributi
I dati che volete salvare per ogni entità sono chiamati ‘attributi’.
Dei prodotti che vendete, volete sapere, per esempio, qual è il prezzo, qual è il nome del produttore, e qual è il numero del tipo. Dei clienti si conosce il loro numero di cliente, il loro nome e l’indirizzo. Dei negozi si conosce il codice del luogo, il nome, l’indirizzo. Delle vendite si sa quando sono avvenute, in quale negozio, quali prodotti sono stati venduti, e la somma totale della vendita. Del venditore si conosce il numero del suo staff, il nome e l’indirizzo. Ciò che sarà incluso precisamente non è ancora importante; si tratta ancora solo di ciò che si vuole salvare.
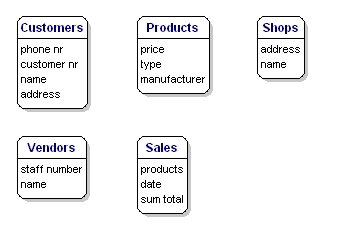
Figura 6: Entità con attributi.
Dati derivati
I dati derivati sono dati che derivano da altri dati che hai già salvato. In questo caso la ‘somma totale’ è un caso classico di dati derivati. Sapete esattamente cosa è stato venduto e quanto costa ogni prodotto, quindi potete sempre calcolare a quanto ammonta la somma totale delle vendite. Quindi in realtà non è necessario salvare la somma totale.
Perché allora viene salvato qui? Beh, perché è una vendita, e il prezzo del prodotto può variare nel tempo. Un prodotto può avere un prezzo di 10 euro oggi e di 8 euro il mese prossimo, e per la vostra amministrazione avete bisogno di sapere quanto costava al momento della vendita, e il modo più semplice per farlo è salvarlo qui. Ci sono molti modi più eleganti, ma sono troppo profondi per questo articolo.
Presentare entità e relazioni: Entity Relationship Diagram (ERD)
L’Entity Relationship Diagram (ERD) fornisce una panoramica grafica del database. Ci sono diversi stili e tipi di ER Diagrams. Una notazione molto usata è la notazione ‘crowfeet’, dove le entità sono rappresentate come rettangoli e le relazioni tra le entità sono rappresentate come linee tra le entità. I segni alla fine delle linee indicano il tipo di relazione. Il lato della relazione che è obbligatorio per l’altro sarà indicato con un trattino sulla linea. Le entità non obbligatorie sono indicate con un cerchio. “Molti” è indicato attraverso un ‘piede di porco’; la linea di relazione si divide in tre linee.
In questo articolo facciamo uso di DeZign for Databases per disegnare e presentare il nostro database.
Una relazione obbligatoria 1:1 è rappresentata come segue:
Figura 7: Relazione obbligatoria uno a uno.
Una relazione obbligatoria 1:N:
Figura 8: Relazione obbligatoria uno a molti.
Una relazione M:N è:
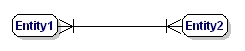
Figura 9: Relazione obbligatoria molti a molti.
Il modello del nostro esempio sarà come questo:
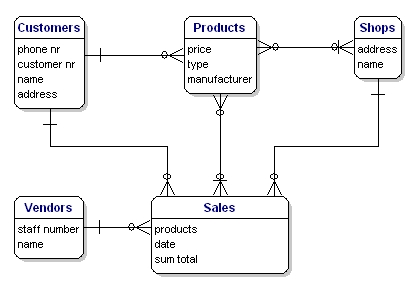
Figura 10: Modello con relazioni.
Assegnazione delle chiavi
Chiavi primarie
Una chiave primaria (PK) è uno o più attributi di dati che identificano univocamente un’entità. Una chiave che consiste di due o più attributi è chiamata chiave composita. Tutti gli attributi parte di una chiave primaria devono avere un valore in ogni record (che non può essere lasciato vuoto) e la combinazione dei valori all’interno di questi attributi deve essere unica nella tabella.
Nell’esempio ci sono alcuni candidati ovvi per la chiave primaria. I clienti hanno tutti un numero di cliente, i prodotti hanno tutti un numero di prodotto unico e le vendite hanno un numero di vendita. Ognuno di questi dati è unico e ogni record conterrà un valore, quindi questi attributi possono essere una chiave primaria. Spesso si usa una colonna intera per la chiave primaria in modo che un record possa essere facilmente trovato attraverso il suo numero.
Le entità di collegamento di solito fanno riferimento agli attributi della chiave primaria delle entità che collegano. La chiave primaria di un’entità di collegamento è di solito un insieme di questi attributi di riferimento. Per esempio, nell’entità Sales_details potremmo usare la combinazione delle PK delle entità sales e products come PK di Sales_details. In questo modo si applica che lo stesso prodotto (tipo) può essere usato solo una volta nella stessa vendita. Più articoli dello stesso tipo di prodotto in una vendita devono essere indicati dalla quantità.
Nell’ERD gli attributi chiave primaria sono indicati dal testo ‘PK’ dietro il nome dell’attributo. Nell’esempio solo l’entità ‘shop’ non ha un candidato ovvio per il PK, così introdurremo un nuovo attributo per quell’entità: shopnr.
Chiavi straniere
La Foreign Key (FK) in un’entità è il riferimento alla chiave primaria di un’altra entità. Nell’ERD questo attributo sarà indicato con ‘FK’ dietro il suo nome. La chiave esterna di un’entità può anche essere parte della chiave primaria, in questo caso l’attributo sarà indicato con ‘PF’ dietro il suo nome. Questo è di solito il caso delle entità di collegamento, perché di solito si collegano due istanze solo una volta insieme (con 1 vendita solo 1 tipo di prodotto viene venduto 1 volta).
Se mettiamo tutte le entità di collegamento, PK e FK nell’ERD, otteniamo il modello come mostrato sotto. Notate che l’attributo “prodotti” non è più necessario in “Vendite”, perché “prodotti venduti” è ora incluso nella tabella dei collegamenti. Nella link-table è stato aggiunto un altro campo, ‘quantity’, che indica quanti prodotti sono stati venduti. Il campo quantità è stato aggiunto anche nella tabella delle scorte, per indicare quanti prodotti sono ancora in magazzino.
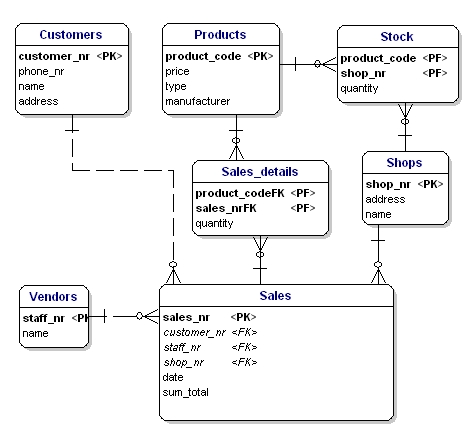
Figura 11: Chiavi primarie e chiavi esterne.
Definire il tipo di dati dell’attributo
Ora è il momento di capire quali tipi di dati devono essere usati per gli attributi. Ci sono molti tipi di dati diversi. Alcuni sono standardizzati, ma molti database hanno i loro tipi di dati che hanno tutti i loro vantaggi. Alcuni database offrono la possibilità di definire i propri tipi di dati, nel caso in cui i tipi standard non possano fare le cose di cui avete bisogno.
I tipi di dati standard che ogni database conosce, e che sono più usati, sono: CHAR, VARCHAR, TEXT, FLOAT, DOUBLE e INT.
Testo:
- CHAR(lunghezza) – include il testo (caratteri, numeri, punteggiature…). CHAR ha come caratteristica che salva sempre una quantità fissa di posizioni. Se definite un CHAR(10) potete salvare fino a dieci posizioni al massimo, ma se usate solo due posizioni il database salverà comunque 10 posizioni. Le otto posizioni rimanenti saranno riempite da spazi.
- VARCHAR(length) – include testo (caratteri, numeri, punteggiatura…). VARCHAR è lo stesso di CHAR, la differenza è che VARCHAR prende solo tutto lo spazio necessario.
- TEXT – può contenere grandi quantità di testo. A seconda del tipo di database questo può arrivare a gigabyte.
Numeri:
- INT – contiene un numero intero positivo o negativo. Molti database hanno variazioni dell’INT, come TINYINT, SMALLINT, MEDIUMINT, BIGINT, INT2, INT4, INT8. Queste variazioni differiscono dall’INT solo per la dimensione della cifra che ci sta dentro. Un INT normale è di 4 byte (INT4) e si adatta a cifre da -2147483647 a +2147483646, o se lo si definisce come UNSIGNED da 0 a 4294967296. L’INT8, o BIGINT, può diventare ancora più grande come dimensione, da 0 a 18446744073709551616, ma prende fino a 8 byte di spazio su disco, anche se c’è solo un piccolo numero in esso.
- FLOAT, DOUBLE – La stessa idea di INT, ma può anche memorizzare numeri in virgola mobile. . Notate che questo non funziona sempre perfettamente. Per esempio in MySQL il calcolo con questi numeri in virgola mobile non è perfetto, (1/3)*3 risulterà con i float di MySQL in 0.9999999, non 1.
Altri tipi:
- BLOB – per dati binari come i file.
- INET – per indirizzi IP. Utilizzabile anche per le netmask.
Per il nostro esempio i tipi di dati sono i seguenti:
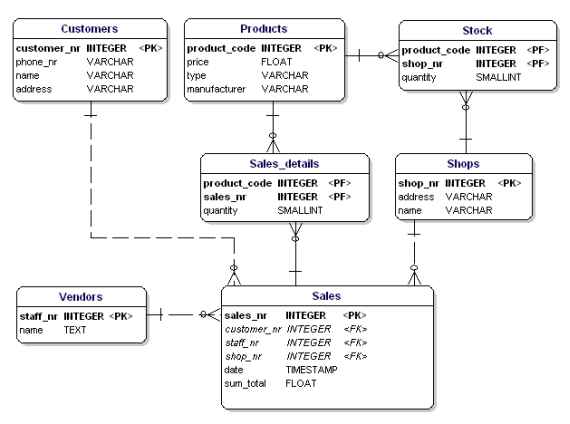
Figura 12: Modello di dati che mostra i tipi di dati.
Normalizzazione
La normalizzazione rende il tuo modello di dati flessibile e affidabile. Genera un po’ di overhead perché di solito si ottengono più tabelle, ma permette di fare molte cose con il modello di dati senza doverlo regolare. Puoi leggere di più sulla normalizzazione del database in questo articolo.
Normalizzazione, la prima forma
La prima forma di normalizzazione afferma che non ci possono essere gruppi ripetuti di colonne in un’entità. Avremmo potuto creare un’entità ‘vendite’ con attributi per ogni prodotto acquistato. Questo sarebbe come questo:

Figura 13: Non in 1a forma normale.
Quello che è sbagliato in questo è che ora solo 3 prodotti possono essere venduti. Se dovessi vendere 4 prodotti allora dovresti iniziare una seconda vendita o aggiustare il tuo modello di dati aggiungendo gli attributi ‘product4’. Entrambe le soluzioni sono indesiderate. In questi casi dovresti sempre creare una nuova entità che colleghi alla vecchia tramite una relazione uno a molti.
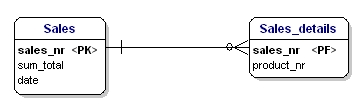
Figura 14: Secondo la prima forma normale.
Normalizzazione, la seconda forma
La seconda forma di normalizzazione afferma che tutti gli attributi di un’entità dovrebbero essere completamente dipendenti dall’intera chiave primaria. Questo significa che ogni attributo di un’entità può essere identificato solo attraverso l’intera chiave primaria. Supponiamo di avere la data nell’entità Sales_details:

Figura 15: Non nella seconda forma normale.
Questa entità non è secondo la seconda forma di normalizzazione, perché per poter cercare la data di una vendita, non devo sapere cosa viene venduto (productnr), l’unica cosa che devo sapere è il numero di vendita. Questo è stato risolto dividendo le tabelle in vendite e Sales_details:
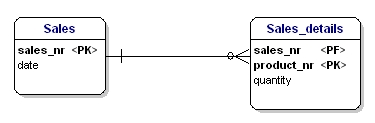
Figura 16: Secondo la seconda forma normale.
Ora ogni attributo delle entità dipende dall’intero PK dell’entità. La data dipende dal numero di vendita, e la quantità dipende dal numero di vendita e dal prodotto venduto.
Normalizzazione, la terza forma
La terza forma di normalizzazione afferma che tutti gli attributi devono essere direttamente dipendenti dalla chiave primaria, e non da altri attributi. Questo sembra essere ciò che afferma la seconda forma di normalizzazione, ma nella seconda forma si afferma in realtà il contrario. Nella seconda forma di normalizzazione si indicano gli attributi attraverso la PK, nella terza forma di normalizzazione ogni attributo deve essere dipendente dalla PK, e nient’altro.

Figura 17: Non nella terza forma normale.
In questo caso il prezzo di un prodotto sfuso dipende dal numero d’ordine, e il numero d’ordine dipende dal numero di prodotto e dal numero di vendita. Questo non è secondo la terza forma di normalizzazione. Di nuovo, dividere le tabelle risolve questo.
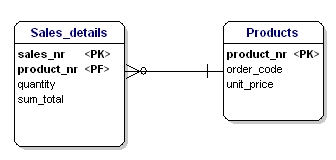
Figura 18: Secondo la terza forma normale.
Normalizzazione, altre forme
Ci sono altre forme di normalizzazione oltre alle tre menzionate sopra, ma quelle non sono di grande interesse per l’utente medio. Queste altre forme sono altamente specializzate per certe applicazioni. Se vi attenete alle regole di design e alla normalizzazione menzionata in questo articolo, creerete un design che funziona benissimo per la maggior parte delle applicazioni.
Modello di dati normalizzato
Se applichi le regole di normalizzazione, troverai che anche il ‘produttore’ nella tabella dei prodotti dovrebbe essere una tabella separata:
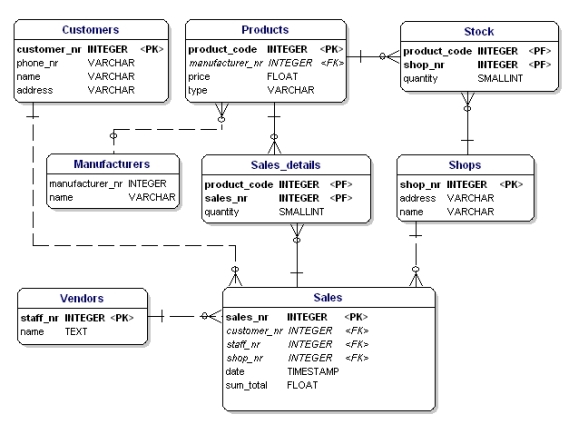
Figura 19: Modello di dati secondo la 1°, 2° e 3° forma normale.