




Artykuł SQL Magazine 7 – SQL Server: Turbine your queries with indexed views
Take your question Mark as completed Annotate
Celem tego artykułu jest wprowadzenie koncepcji widoków indeksowanych SQL Server oraz pokazanie, jak zaimplementować i wykorzystać ten typ widoku do optymalizacji zapytań.
Koncepcja widoku
Widoki są również znane jako „wirtualne tabele”, ponieważ stanowią alternatywę dla używania tabel w celu uzyskania dostępu do danych. Widok to nic innego jak instrukcja SELECT zamknięta w obiekcie. Składnia tworzenia widoku jest taka jak na listingu 1.
CREATE VIEW nome_da_visão ...) ] AS subconsulta;Zobacz przykład tworzenia i używania widoku na listingu 1.
Use NorthWind go create view vi_vendas_mes As Select ano = datepart(yyyy,OrderDate), mes = datepart(mm,OrderDate), qtde_total = sum(Quantity) from Orders o inner join od on o.OrderId = od.OrderId group by datepart(yyyy,o.OrderDate), datepart(mm,o.OrderDate) go select * from vi_vendas_mês go ano mes qtde_total contador ----------- ----------- ----------- -------------------- 1996 7 1462 59 1996 8 1322 69 1996 9 1124 57 1996 10 1738 73 1996 11 1735 66Wśród zalet używania widoków możemy wymienić :
- Uproszczenie kodu: możesz napisać raz złożone SELECTy, zamknąć je w widoku i wyzwalać je z niego, tak jakby to była dowolna tabela;
- Kwestie bezpieczeństwa: załóżmy, że masz poufne informacje w niektórych tabelach i dlatego chcesz, aby tylko niektórzy użytkownicy mieli do nich dostęp. Jednakże, niektóre kolumny w tych tabelach muszą być dostępne dla wszystkich użytkowników. Skutecznym sposobem na rozwiązanie tego problemu jest utworzenie widoku i ukrycie wrażliwych kolumn.
- Możliwość optymalizacji zapytań poprzez implementację indeksowanych widoków.
Indeksowane widoki w praktyce
Widoki hermetyzują instrukcje SELECT, co oznacza, że za każdym razem, gdy są wyzwalane, wykonywane są związane z nimi instrukcje SELECT. Widoki nie tworzą repozytoriów dla danych, które zwracają (tak jak robi to tabela). Cóż, byłoby świetnie, gdybyśmy mogli „zmaterializować” w tabeli wynik polecenia SELECT znaleziony w widoku, tworząc indeksy ułatwiające dostęp do niego. Cóż, widoki indeksowane właśnie to robią. Wykonanie SELECT w widoku indeksowanym ma taki sam efekt jak wykonanie select w konwencjonalnej tabeli.
Głównym celem widoków indeksowanych jest zwiększenie wydajności, a zaletą SQL Server jest umożliwienie planom wykonania uwzględnienia widoku indeksowanego jako środka dostępu do danych, nawet jeśli nazwa widoku nie była jawna w zapytaniu. Jest to możliwe w wersji Enterprise Edition SQL Server 2000, gdzie optymalizator poleceń może wybierać dane bezpośrednio w widoku indeksowanym (zamiast wybierać surowe dane istniejące w tabeli), co zobaczymy dalej.
Tworzenie widoku indeksowanego krok po kroku
- Konfigurując środowisko, pierwszym krokiem jest ustawienie stanu niektórych parametrów w sesji, w której chcemy utworzyć i używać widok, ponieważ jako, że widok indeksowany jest „zmaterializowany” w tabeli, nic nie może zakłócić jego wyniku. Wyobraźmy sobie na przykład następujący scenariusz:
- Pewne ustawienie, które wpływa na wynik SELECT (np. concat_null_yelds_null), jest ustawione przed utworzeniem widoku indeksowanego;
- Widok indeksowany jest tworzony; zauważ, że wynik widoku będzie „zmaterializowany” na dysku zgodnie z ustawieniem ustawionym w poprzednim kroku;
- Potem ustawienie jest wyłączone, a widok indeksowany jest wykonywany przez użytkownika. Ponieważ widok został zmaterializowany, otrzymamy wynik niezgodny z bieżącą konfiguracją.
Na przykład na listingu 2 pokazano różnicę w wyniku działania polecenia po zmianie właściwości concat_null_yields_null.
set concat_null_yields_null ON print null + 'abc' -------------------------------------- Set concat_null_yields_null OFF print null + 'abc' -------------------------------------- abcWyobraź sobie, co by się stało, gdyby widok indeksowany został utworzony z włączoną właściwością concat_null_yields_null, ale bieżąca sesja była z wyłączoną tą właściwością – ten sam SELECT prowadziłby do różnych wyników!
Problem ten został rozwiązany w prosty sposób – aby tworzyć i używać widoki indeksowane, należy obowiązkowo skonfigurować środowisko według listy wartości domyślnych. W ten sposób nie można uzyskać innych wyników, ponieważ widok po prostu nie będzie działał, jeśli którekolwiek z ustawień zostanie ustawione na wartość spoza wartości domyślnych.
Tabela 1 wyświetla te ustawienia i ich odpowiednie wartości domyślne.
| Zestawienie | Id (*) | Wymagany stan dla widoków indeksowanych | SQL Server 2000 default | Domyślnie dla połączeń OLE DB (=ADO) lub ODBC | Domyślnie dla połączeń wykorzystujących biblioteki DB | |
|---|---|---|---|---|---|---|
| ANSI_NULLS | 32 | ON | OFF | ON | OFF | |
| ANSI_PADDING | 16 | ON | ON | OFF | ||
| ANSI_WARNING | 8 | ON | ON | OFF | ON | OFF |
| ARITHABORT | 64 | ON | OFF | OFF | OFF | OFF |
| CONCAT_NULL_YIELDS_NULL | 4096 | ON | OFF | ON | OFF | |
| QUOTED_IDENTIFIER | 256 | ON | OFF | ON | OFF | |
| NUMERIC_ROUNDABORT | 8192 | OFF | OFF | OFF | OFF |
(*) Id jest używane w poleceniu sp_configure. Aby sprawdzić, co każde z ustawień robi, przeczytaj sekcję „Wymagane ustawienia dla widoków indeksowanych”. Istnieją dwa sposoby na zmianę wartości konfiguracji:
- Bezpośrednio w sesji: uruchom polecenie set ON | OFF
- Zmiana istniejącej wartości domyślnej serwera: uruchom sp_Configure 'user options’, . Numer identyfikacyjny każdej konfiguracji można zobaczyć w tabeli 1.
Uwaga: AritHabort ma id 64, a Quoted_Identifier ma id 256. Aby połączyć np. Quoted_Identifier + AritHabort, wykonalibyśmy sp_cofigure, przekazując jako parametr wynik 64+256 (=320): sp_configure 'user options’, 320. Aby uzyskać pełną listę identyfikatorów przypisanych do każdej konfiguracji, przejdź do http://msdn.microsoft.com/library/default.asp?url=/library/en-us/adminsql/ad_config_9b1q.asp.
Aby potwierdzić stan każdego z parametrów w tabeli 1, użyj funkcji SessionProperty(’nazwa parametru’) lub polecenia DBCC UserOptions.
W ten sposób należy ustawić wszystkie parametry zgodnie z kolumną 'stan wymagany dla widoków indeksowanych’ w tabeli 1 – jeśli nie zostanie to zrobione, SQL Server nie pozwoli na utworzenie/wykonanie widoku indeksowanego.
Tworzenie widoku indeksowanego
Utworzymy widok sumujący dzienną ilość sprzedanych towarów w tabeli Order Details, znajdującej się w bazie NorthWind. Zobacz Listing 3.
use NorthWind go create view vi_vendas_mes with SchemaBinding as select ano = datepart(yyyy,OrderDate), mes = datepart(mm,OrderDate), qtde_total = sum(Quantity), contador = count_big(*) from dbo.Orders o inner join dbo. od on o.OrderId = od.OrderId group by datepart(yyyy,o.OrderDate),datepart(mm,o.OrderDate) goPodczas tworzenia widoków indeksowanych musimy przestrzegać pewnych prawidłowości:
- Widok musi być deterministyczny. Widok będzie deterministyczny, jeśli w jego kodzie będziemy używać tylko deterministycznych funkcji. To samo polecenie SELECT wykonane wielokrotnie na widoku indeksowanym (z uwzględnieniem statycznej bazy) nie może dać różnych wyników. Funkcje deterministyczne zapewniają, że wynik działania funkcji pozostanie niezmieniony bez względu na to, ile razy zostanie ona wykonana. Funkcja DatePart, na przykład, jest deterministyczna, ponieważ zawsze zwraca ten sam wynik dla określonej daty. Funkcja getdate() będzie zwracała inną wartość za każdym razem, gdy zostanie wykonana. Aby uzyskać pełną listę funkcji deterministycznych SQL Server 2000, przejdź do http://msdn.microsoft.com/library/default.asp?url=/library/en-us/createdb/cm_8_des_08_95v7.asp
- Sprawdź, czy nie ma ograniczeń składni. Klauzule, funkcje i typy zapytań wymienione poniżej nie mogą zawierać schematu widoku indeksowanego:
- MIN, MAX,TOP
- VARIANCE,STDEV,AVG
- COUNT(*)
- SUM na kolumnach, które dopuszczają wartości null
- DISTINCT
- Funkcja ROWSET
- Tablice pochodne, złączenia własne, podzapytania, outer joins
- DISTINCT
- UNION
- Float, text, ntext i image
- COMPUTE i COMPUTE BY
- HAVING, CUBE i ROLLUP
Niezbędne jest tworzenie widoków indeksowanych za pomocą SchemaBinding. Aby zachować spójność zawartości widoku, nie możesz zmieniać struktury tabel, z których pochodzi widok. Aby uniknąć tego typu problemów, obowiązkowe jest użycie SchemaBinding podczas tworzenia widoków indeksowanych, ponieważ opcja ta nie pozwala na zmianę struktury tabeli bez wcześniejszego usunięcia widoku.
Aby użyć klauzuli GROUP BY, obowiązkowe jest dołączenie funkcji COUNT_BIG(*). Funkcja count_big(*) robi to samo co count(*), ale zwraca wartość typu bigint (8 bajtów).
Zawsze informuj właściciela obiektów, do których odwołujesz się w widoku indeksowanym. Użyj select * from dbo.Orders zamiast select * from Orders, ponieważ możliwe jest posiadanie tabel o tej samej nazwie, ale różnych właścicielach. Ponieważ opcja schemabinding jest obowiązkowa, SQL Server potrzebuje dokładnej specyfikacji obiektu, aby ograniczyć zmiany schematu.
Tworzenie indeksu klastrowego w widoku (materializacja)
Widok utworzony w punkcie 2 nie zachowuje się jeszcze jak widok indeksowany, ponieważ wynik polecenia select nie został zmaterializowany do tabeli. Możesz potwierdzić to stwierdzenie, uruchamiając polecenie sp_spaceused w Query Analyzer, które zwraca liczbę wierszy i zajętą przestrzeń przez tabele (Listing 4).
sp_SpaceUsed vi_vendas_mes -------------------------------------------------------------------------------------- Server: Msg 15235, Level 16, State 1, Procedure sp_spaceused, Line 91 Views do not have space allocated.Zauważ na Listingu 5, że przetwarzanie widoku jest czysto logiczne, do tego stopnia, że wartość parametru Physical Reads wynosi zero. Zwróć uwagę na wartości zarejestrowane w Logical Reads i Physical Reads (1672+0+4+0=1676) – będziemy używać tych wartości w naszych przyszłych porównaniach.
Set statistics io ON Select * from vi_vendas_mesgo---------------------------------------------------------ano mes qtde_total contador ----------- ----------- ------------- -------------------- 1996 7 1462 591996 8 1322 691996 9 1124 57.....(23 row(s) affected)Table 'Order Details'. Scan count 830, logical reads 1672, physical reads 0, read-ahead reads 0.Table 'Orders'. Scan count 1, logical reads 4, physical reads 0, read-ahead reads 0.Aby sprawdzić, czy widok może być indeksowany (materializowany), czyli czy został utworzony w standardach i ustawieniach wymaganych dla widoków indeksowanych, wynik poniższego SELECT powinien być równy 1.
select ObjectProperty(object_id('vi_vendas_mes'),'IsIndexable')Potwierdzając warunki wstępne, możemy teraz utworzyć indeks. Składnia ma taki sam format używany podczas tworzenia indeksów w konwencjonalnych tabelach:
create unique clustered index pk_ano_mes on vi_vendas_mes (ano,mes)Zauważ, że indeks klastrowy jest wymagany, ponieważ generuje strony danych. Indeksy nieklastrowe w widokach indeksowanych można tworzyć dopiero po utworzeniu indeksu klastrowego.
Teraz SELECT znaleziony w widoku został zmaterializowany. co można udowodnić za pomocą polecenia sp_spaceused w Query Analyzer (Listing 6).
sp_SpaceUsed vi_vendas_mêsgo-----------------------------------------------------Name Rows Reserved data index_size Unusedvi_vendas_mes 23 24 KB 8 KB 16 KB 0 KBUżycie widoków indeksowanych
Jednym ze sposobów dostępu do widoku indeksowanego (podobnie jak do widoku konwencjonalnego) jest odwołanie się do jego nazwy w poleceniu SELECT:
select * from vi_vendas_mesPorównaj objętość stron przeniesionych w Listingu 5 (1672+4=1676) z objętością w Listingu 7 (2+0=2). Różnica jest dość znacząca – utworzenie widoku indeksowanego zmniejszyło całkowite wymagane I/O o 1674 strony.
Set statistics io ON select * from vi_vendas_mes go --------------------------------------------------------- ano mes qtde_total contador ----------- ----------- ------------- -------------------- 1996 7 1462 59 1996 9 1124 57 ..... (23 row(s) affected) Table 'vi_vendas_mes'. Scan count 1, logical reads 2, physical reads 0, read-ahead reads 0.Przyjrzyjrzyjmy się kolejnemu przykładowi. Rysunek 1 przedstawia plan wykonania zapytania. Potwierdź, że widok został wybrany, mimo że nie był obecny w wierszu SELECT.
Podczas konstruowania planu wykonania zapytania optymalizator stwierdził, że w vi_sales_mes znajdują się już wstępnie podsumowane dane dla zapytania i wybrał wybór danych bezpośrednio w widoku indeksowanym.
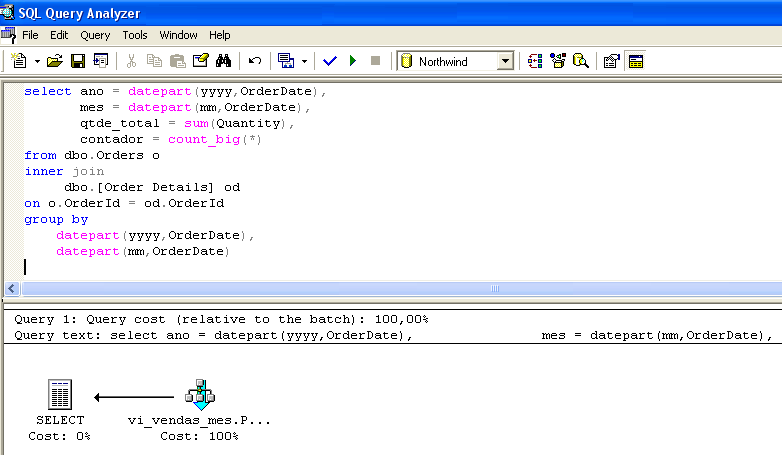
Zauważmy, że zapytanie wykonane na rysunku 1 jest identyczne z tym, które znajduje się w widoku vi_sales_mes. Jednak dostęp do widoku przez optymalizator jest niezależny od podobieństwa pomiędzy zapytaniem wykonywanym a zapytaniem widoku. Wybór widoku indeksowanego przez procesor zapytań uwzględnia jedynie stosunek kosztów do korzyści. W ten sposób wykonywane zapytania nie muszą być identyczne z widokiem (patrz rysunek 3).
Należy jednak przestrzegać pewnych zasad, aby widok indeksowany był brany pod uwagę przez optymalizator zapytań:
- Złączenie występujące w widoku musi być „zawarte” w zapytaniu: jeśli zapytanie wykonuje złączenie między tabelami A i B, a widok wykonuje złączenie między A i C, to widok nie zostanie wywołany w planie wykonania. Jeśli jednak zapytanie wykona join pomiędzy A,B i C, widok może zostać uruchomiony.
- Warunki określone w zapytaniu muszą zgadzać się z warunkami w widoku: w SELECT na rysunku 2, indeksowany widok vi_sales_mes nie będzie brany pod uwagę, ponieważ klauzula where nie była obecna w kodzie widoku, co spowodowało, że wiersze z ilością <= 5 zostały obliczone w joincie.
Z drugiej strony, jeśli zapytanie ma warunek where where sum(Ilość) > 5, to widok vi_sales_mes zostanie uwzględniony w planie wykonania, ponieważ warunek zapytania jest podzbiorem SELECT występującym w widoku.
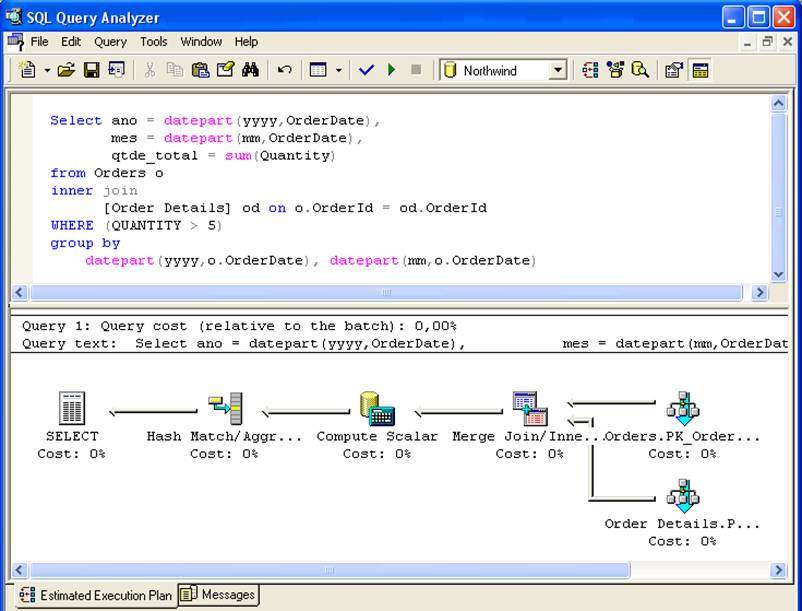
Kolumny z funkcjami agregującymi w zapytaniu muszą „mieścić się” w definicji widoku: jeśli widok zwraca kolumnę qtde=suma(Ilość), a zapytanie ma kolumnę vlr_unit=suma(UnitPrice), to widok nie zostanie uwzględniony.
Rysunek 3 przedstawia polecenie SELECT, które pozwala wykazać się inteligencją optymalizatora poleceń – obliczenie AVG(Ilość) zostało zastąpione dzieleniem SUM(Ilość) / Count_Big(*), reprezentowanym przez ikonę Compute Scalar. Uwzględniany jest również predykat where sum(Ilość) > 1500 (reprezentowany przez ikonę Filtr).
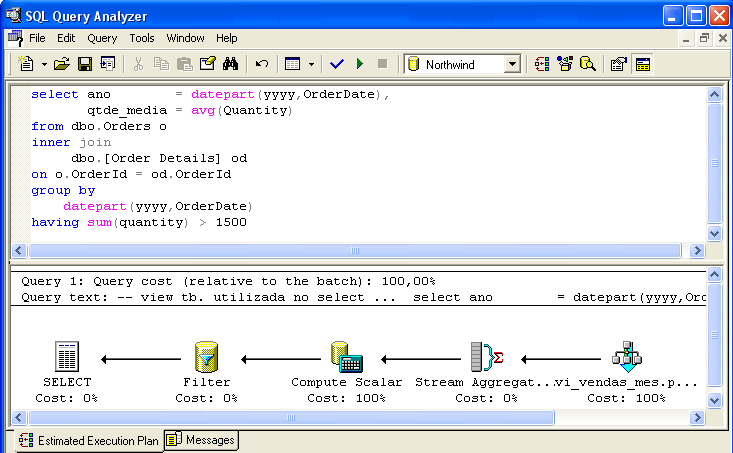
Ogólne uwagi na temat używania widoków indeksowanych:
- Widoki indeksowane można tworzyć w dowolnej wersji SQL Server 2000. Jednak tylko w wersji Enterprise Edition będą one automatycznie wybierane przez optymalizator zapytań.
- W wersjach innych niż Enterprise, musisz użyć podpowiedzi NoExpand, aby uzyskać dostęp do widoku indeksowanego jak do zwykłej tabeli. Jeśli opcja NoExpand nie zostanie użyta, indeksowany widok będzie traktowany jako „normalny” widok.
Uwaga: Podpowiedź Expand działa odwrotnie niż NoExpand: traktuje widok indeksowany jako „normalny” widok, zmuszając SQL Server do wykonania instrukcji SELECT w fazie run-time.
- Utrzymanie widoku indeksowanego jest automatyczne (tak jak w indeksach); nie wymaga żadnej dodatkowej synchronizacji. Ze względu na swoją specyfikę (przechowuje zwykle wstępnie podsumowane dane), jego aktualizacja jest nieco wolniejsza niż w przypadku konwencjonalnych indeksów.
- Używanie indeksowanych widoków w bazach OLTP wymaga ostrożności, gdyż choć prezentują one dużą wydajność w zapytaniach, powodują narzut w procesach modyfikujących tabele powiązane w widoku. W sytuacjach, w których wymagana jest wysoka wydajność zapisu, z częstymi aktualizacjami, tworzenie indeksowanych widoków nie jest zalecane.
- Podobnie jak w przypadku indeksów, optymalizator przeanalizuje kod widoku w wersjach Enterprise jako część procesu wyboru najlepszego planu wykonania dla zapytania. Jednakże, jeśli istnieje wiele indeksowanych widoków możliwych do wykonania dla tego samego zapytania, może nastąpić znaczny wzrost czasu wyboru, ponieważ wszystkie widoki zostaną przeanalizowane. Dlatego podczas implementacji widoków należy kierować się zdrowym rozsądkiem.
Required Settings for Indexed Views
ANSI_NULLS
Definiuje sposób wykonywania porównań z wartościami null (Listing 8).
set ANSI_NULLS ON declare @var char(10) set @var = null if @var = null print 'VERDADEIRO' else print 'FALSO' ------------------------------------- FALSO set ANSI_NULLS OFF declare @var char(10) set @var = null if @var = null print 'VERDADEIRO' else print 'FALSO' -------------------------------------- VERDADEIROANSI_PADDING
Określa, w jaki sposób powinny być przechowywane kolumny char, varchar, binary i varbinary, gdy ich zawartość jest mniejsza niż rozmiar określony w strukturze tabeli. Domyślnie SQL Server 2000 utrzymuje ansi_padding włączony (=ON); w tym stanie obowiązują następujące reguły:
- Podczas aktualizacji kolumn char, białe spacje będą dodawane na końcu łańcucha, jeśli jest on mniejszy niż rozmiar zdefiniowany w strukturze kolumny. Ta sama zasada dotyczy kolumn binarnych (w tym przypadku przestrzeń jest wypełniana ciągiem zer)
- Kolumny varbinary lub varchar nie stosują się do powyższej zasady: zawsze zachowują swój oryginalny rozmiar.
ARITHABORT
Gdy włączone, kończy wykonywanie zapytania po napotkaniu dzielenia przez zero lub jakiegoś rodzaju przepełnienia.
QUOTED_IDENTIFIER
Gdy włączone, pozwala na użycie podwójnych cudzysłowów do określenia nazw tabel, kolumn itp. – W ten sposób nazwy te mogą zawierać spacje lub znaki specjalne.
CONCAT_NULL_YELDS_NULL
Kontroluje wynik konkatenacji łańcuchów z wartościami null. Gdy włączone, określa, że to złączenie musi zwracać wartość null; w przeciwnym razie zwróci sam łańcuch znaków.
ANSI_WARNINGS
Gdy włączone, określa generowanie komunikatów o błędach, gdy:
- używasz funkcji podsumowujących i wartości null są znalezione w zakresie zapytania;
- podziały przez zero lub przepełnienie arytmetyczne są znalezione.
NUMERIC_ROUNDABORT
Wpływa na sposób postępowania serwera SQL w przypadku utraty precyzji operacji arytmetycznych. Jeżeli parametr jest włączony i zmienna o precyzji dwóch miejsc po przecinku otrzyma wartość z trzema miejscami po przecinku, to operacja zostanie przerwana. Jeśli parametr jest wyłączony, wartość zostanie obcięta do dwóch miejsc po przecinku.
Wnioski
Jeśli chodzi o optymalizację zapytań, widoki indeksowane są dobrym wyborem do wykorzystania wydajności. Tak więc, dokładnie ocenić zapytania, które zajmują się podsumowaniami i są wykonywane z pewną częstotliwością i przejść do tworzenia indeksowanych widoków. Wynik jest tego wart!