




Jak dobrzy są ankieterzy? Analyzing Five-Thirty-Eight’s dataset
Analizujemy zestaw danych rankingowych ankieterów z czcigodnej strony internetowej Five-Thirty-Eight.

Jest to rok wyborczy i scena sondażowa wokół wyborów (zarówno ogólnych prezydenckich, jak i do Izby/Senatu) rozgrzewa się. To będzie coraz bardziej ekscytujące w najbliższych dniach, z tweety, kontr-tweety, walki w mediach społecznościowych, i niekończące się punditry w telewizji.
Wiemy, że nie wszystkie sondaże są tej samej jakości. Jak więc nadać temu wszystkiemu sens? Jak zidentyfikować godnych zaufania ankieterów za pomocą danych i analityki?

W świecie politycznej (i kilku innych spraw, takich jak sport, zjawiska społeczne, ekonomia, itp.) analizy predykcyjnej, Five-Thirty-Eight to groźna nazwa.
Od początku 2008 roku strona publikuje artykuły – zazwyczaj tworzące lub analizujące informacje statystyczne – na wiele tematów z zakresu bieżącej polityki i wiadomości politycznych. Strona internetowa, prowadzona przez gwiazdę danych naukowca i statystyka Nate’a Silvera, osiągnęła szczególną widoczność i powszechną sławę wokół wyborów prezydenckich w 2012 r., kiedy jej model poprawnie przewidział zwycięzcę we wszystkich 50 stanach i Dystrykcie Kolumbii.
I zanim zaczniesz szydzić i mówić „Ale co z wyborami w 2016 roku?”, możesz być dobrze poinformowany, aby przeczytać ten kawałek na temat tego, jak wybór Donalda Trumpa mieścił się w normalnym marginesie błędu modelowania statystycznego.
Dla bardziej dociekliwych politycznie czytelników, mają cały worek artykułów na temat wyborów w 2016 roku tutaj.
Praktycy data science powinni polubić Five-Thirty-Eight, ponieważ nie stroni od wyjaśniania swoich modeli predykcyjnych w kategoriach wysoce technicznych (przynajmniej wystarczająco skomplikowanych dla laików).

Here, they are talking about adopting the famous t-distribution, while most other poll aggregators may just be happy with the ubiquititeous Normal distribution.
However, going beyond the use of sophisticated statistical modeling techniques, the team under Silver prides itself on a unique methodology – pollster rating – to help their models remain highly accurate and trustworthy.
W tym artykule analizujemy ich dane dotyczące tych metod ratingowych.
Five-Thirty-Eight nie stroni od wyjaśniania swoich modeli prognostycznych w kategoriach wysoce technicznych (przynajmniej na tyle skomplikowanych, aby laik mógł je zrozumieć).
Pollster rating i ranking
W tym kraju działa mnóstwo ankieterów. Czytanie i ocenianie ich jakości może być bardzo uciążliwe i uciążliwe. Jak napisano na stronie internetowej, „Czytanie sondaży może być niebezpieczne dla zdrowia. Objawy obejmują cherry-picking, nadmiernej pewności siebie, wpadając na śmieciowych numerów, i spiesząc się do osądu. Na szczęście, mamy na to lekarstwo.” (źródło)
Istnieją sondaże. Następnie, są sondaże sondaży. Następnie, są ważone sondaże sondaży. Przede wszystkim istnieje sondaż sondaży z wagami, które są statystycznie modelowane i dynamicznie zmieniające się wagi.
Brzmi znajomo do innych słynnych metodologii rankingowych, o których słyszałeś jako data scientist? Ranking produktów Amazona lub ranking filmów Netflixa? Prawdopodobnie tak.
Podstawowo, Five-Thirty-Eight używa tego ratingu/ systemu rankingowego do ważenia wyników sondaży (wysoko oceniane wyniki ankieterów mają większe znaczenie i tak dalej). They also actively track the accuracy and methodologies behind each pollster’s result and adjust their ranking throughout the year.
There are polls. Następnie, są sondaże sondaży. Następnie, są ważone sondaże sondaży. Przede wszystkim, istnieje sondaż sondaży z wagami, które są statystycznie modelowane i dynamicznie zmieniają wagi.
Ciekawe jest to, że ich metodologia rankingu niekoniecznie ocenia ankietera z większą próbką jako lepszego. Poniższy zrzut ekranu z ich strony internetowej wyraźnie to demonstruje. Podczas gdy ankieterzy tacy jak Rasmussen Reports i HarrisX mają większą próbę, to w rzeczywistości Marist College otrzymuje ocenę A+ przy skromnej próbie.
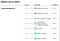
Na szczęście, oni również udostępniają swoje dane rankingowe ankieterów (wraz z prawie wszystkimi innymi zbiorami danych) tutaj na Githubie. A jeśli jesteś zainteresowany tylko ładnie wyglądającą tabelą, oto ona.
Naturalnie, jako naukowiec zajmujący się danymi, możesz chcieć spojrzeć głębiej na surowe dane i zrozumieć takie rzeczy jak,
- jak ich numeryczny ranking koreluje z dokładnością ankieterów
- czy mają partyzancką tendencję do wybierania poszczególnych ankieterów (w większości przypadków, mogą być skategoryzowani jako skłaniający się ku Demokratom lub Republikanom)
- kim są najwyżej oceniani ankieterzy? Czy przeprowadzają oni wiele sondaży, czy też są wybiórczy?
Próbowaliśmy przeanalizować zbiór danych w celu uzyskania takich spostrzeżeń. Zajrzyjmy do kodu i wyników, dobrze?
Analiza
Notatnik Jupytera można znaleźć na moim repo na Githubie.
Źródło
Na początek możesz wyciągnąć dane bezpośrednio z ich Githuba, do Pandas DataFrame, w następujący sposób,

W tym zbiorze danych znajdują się 23 kolumny. Oto jak one wyglądają,

Trochę transformacji i czyszczenia
Zauważamy, że pewna kolumna ma trochę dodatkowego miejsca. Kilka innych może wymagać ekstrakcji i konwersji typu danych.



Po zastosowaniu tej ekstrakcji, nowa DataFrame posiada dodatkowe kolumny, co czyni ją bardziej odpowiednią do filtrowania i modelowania statystycznego.

Badanie i kwantyzacja kolumny „538 Grade”
Kolumna „538 Grades” zawiera sedno zbioru danych – ocenę literową dla ankietera. Tak jak na zwykłym egzaminie, A+ jest lepsze od A, a A jest lepsze od B+. Jeśli wykreślimy liczbę ocen literowych, zaobserwujemy 15 stopni, w sumie od A+ do F.

Zamiast pracować z tak wieloma kategorycznymi stopniami, możemy chcieć połączyć je w niewielką liczbę stopni liczbowych – 4 dla A+/A/A-, 3 dla B’s, itd.

Boxplots
Przejście do analityki wizualnej możemy zacząć od boxplots.
Załóżmy, że chcemy sprawdzić, która metoda ankietowania wypada lepiej pod względem błędu predykcji. W zbiorze danych znajduje się kolumna o nazwie „Simple Average Error”, która jest zdefiniowana jako „Średni błąd firmy, obliczony jako różnica między wynikiem sondażu a rzeczywistym wynikiem dla marginesu oddzielającego dwóch najlepszych finiszerów w wyścigu.”

Wtedy możemy być zainteresowani sprawdzeniem, czy ankieterzy z pewną partyzancką stronniczością są bardziej skuteczni w nazywaniu wyborów poprawnie niż inni.

Zauważyłeś powyżej coś ciekawego? Jeśli jesteś postępowym, liberalnym myślicielem, z dużym prawdopodobieństwem możesz być partyzantem Partii Demokratycznej. Ale, średnio rzecz biorąc, ankieterzy z republikańskimi tendencjami, nazywa wybory dokładniej i z mniejszą zmiennością. Lepiej uważaj na te sondaże!
Inna interesująca kolumna w zbiorze danych nazywa się „NCPP/AAPOR/Roper”. Wskazuje ona, czy dana firma badawcza była członkiem National Council on Public Polls, sygnatariuszem inicjatywy American Association for Public Opinion Research na rzecz przejrzystości, czy też współtworzyła archiwum danych Roper Center for Public Opinion Research. Efektywnie, członkostwo wskazuje na przestrzeganie bardziej solidnej metodologii badania opinii publicznej” (źródło).
Jak ocenić prawdziwość powyższego twierdzenia? The dataset has a column called „Advanced Plus-Minus”, which is „a score that compares a pollster’s result against other polling firms surveying the same races and that weighs recent results more heavily. Negatywne wyniki są korzystne i wskazują na ponadprzeciętną jakość” (źródło).
Tutaj znajduje się wykres boxplot pomiędzy tymi dwoma parametrami. Nie tylko ankieterzy, związani z NCCP/AAPOR/Roper, wykazują niższy wynik błędu, ale także wykazują znacznie niską zmienność. Ich przewidywania wydają się być stałe i solidne.

Jeśli jesteś progresywnym, liberalnym myślicielem, z całym prawdopodobieństwem, możesz być partyzantem Partii Demokratycznej. Ale, średnio, ankieterzy z republikańskim stronnictwem, nazywa wybory dokładniej i z mniejszą zmiennością.
Scatter i działki regresji
Aby zrozumieć korelację między parametrami, możemy spojrzeć na działki rozproszenia z dopasowaniem regresji. Używamy bibliotek Seaborn i Scipy Python oraz niestandardowej funkcji do generowania tych działek.
Na przykład, możemy odnieść „Wyścigi wywołane poprawnie” do „Predictive Plus-Minus”. Zgodnie z Five-Thirty-Eight, „Predictive Plus-Minus” jest „projekcją tego, jak dokładny będzie ankieter w przyszłych wyborach. Jest on obliczany poprzez odwrócenie wyniku Advanced Plus-Minus ankietera do średniej opartej na naszych wskaźnikach jakości metodologicznej.” (źródło)

Or, możemy sprawdzić jak zdefiniowany przez nas „Numeric Grade”, koreluje ze średnią błędów sondaży. Negatywny trend wskazuje, że wyższa ocena numeryczna wiąże się z niższym błędem sondażu.

Możemy również sprawdzić, czy „# of Polls for Bias Analysis” pomaga w zmniejszeniu „Partisan Bias Degree”, który jest przypisany do każdego ankietera. Możemy zaobserwować zależność w dół, wskazującą, że dostępność dużej liczby sondaży pomaga zmniejszyć stopień stronniczości. Jednakże, zależność wygląda na wysoce nieliniową i logarytmiczne skalowanie byłoby lepsze do dopasowania krzywej.

Czy bardziej aktywnym ankieterom należy bardziej ufać? Wykreślamy histogram liczby ankiet i widzimy, że jest on zgodny z ujemnym prawem potęgowym. Możemy odfiltrować ankieterów z bardzo niską i bardzo wysoką liczbą sondaży i stworzyć własny wykres rozrzutu. Jednakże, obserwujemy prawie nieistniejącą korelację pomiędzy # of Polls a wynikiem Predictive Plus-Minus. W związku z tym, duża liczba sondaży niekoniecznie prowadzi do wysokiej jakości sondażu i mocy predykcyjnej.