




Naucz się Regex: A Beginner's Guide
W tym przewodniku nauczysz się regex, czyli składni wyrażeń regularnych. Pod koniec będziesz w stanie stosować rozwiązania regex w większości scenariuszy, które wymagają tego w pracy nad tworzeniem stron internetowych.
Wyrażenia regularne mają wiele zastosowań, które obejmują:
- sprawdzanie poprawności danych wejściowych w formularzach
- skrobanie stron internetowych
- wyszukiwanie i zamiana
- filtrowanie informacji w ogromnych plikach tekstowych, takich jak logi
Wyrażenia regularne, lub regex, jak są powszechnie nazywane, wyglądają skomplikowanie i onieśmielają nowych użytkowników. Spójrz na ten przykład:
/^+@+(?:\.+)*$/To po prostu wygląda jak zniekształcony tekst. Ale nie rozpaczaj, za tym szaleństwem kryje się metoda.

Credit: xkcd
Pokażę ci, jak opanować wyrażenia regularne w mgnieniu oka. Najpierw wyjaśnijmy terminologię używaną w tym poradniku:
- pattern: wzorzec wyrażenia regularnego
- string: ciąg testowy używany do dopasowania wzorca
- cyfra: 0-9
- litera: a-z, A-Z
- symbol: !$%^&*()_+|~-=`{}:”;'<>?,./
- spacja: pojedyncza biała spacja, tabulator
- znak: odnosi się do litery, cyfry lub symbolu
Podstawy
Aby szybko nauczyć się regexu dzięki temu przewodnikowi, odwiedź stronę Regex101, gdzie możesz tworzyć wzorce regex i testować je na podanych ciągach znaków (tekstach).
Gdy otworzysz stronę, będziesz musiał wybrać smak JavaScript, ponieważ to jest to, czego będziemy używać w tym przewodniku. (Składnia Regex jest w większości taka sama dla wszystkich języków, ale są pewne drobne różnice.)
Następnie musisz wyłączyć flagi global i multi line w Regex101. Zajmiemy się nimi w następnej sekcji. Na razie przyjrzymy się najprostszej formie wyrażenia regularnego, jaką możemy zbudować. Wprowadź następujące dane:
- pole wejściowe regex: cat
- ciąg testowy: rat bat cat sat fat cats eat tat cat mat CAT
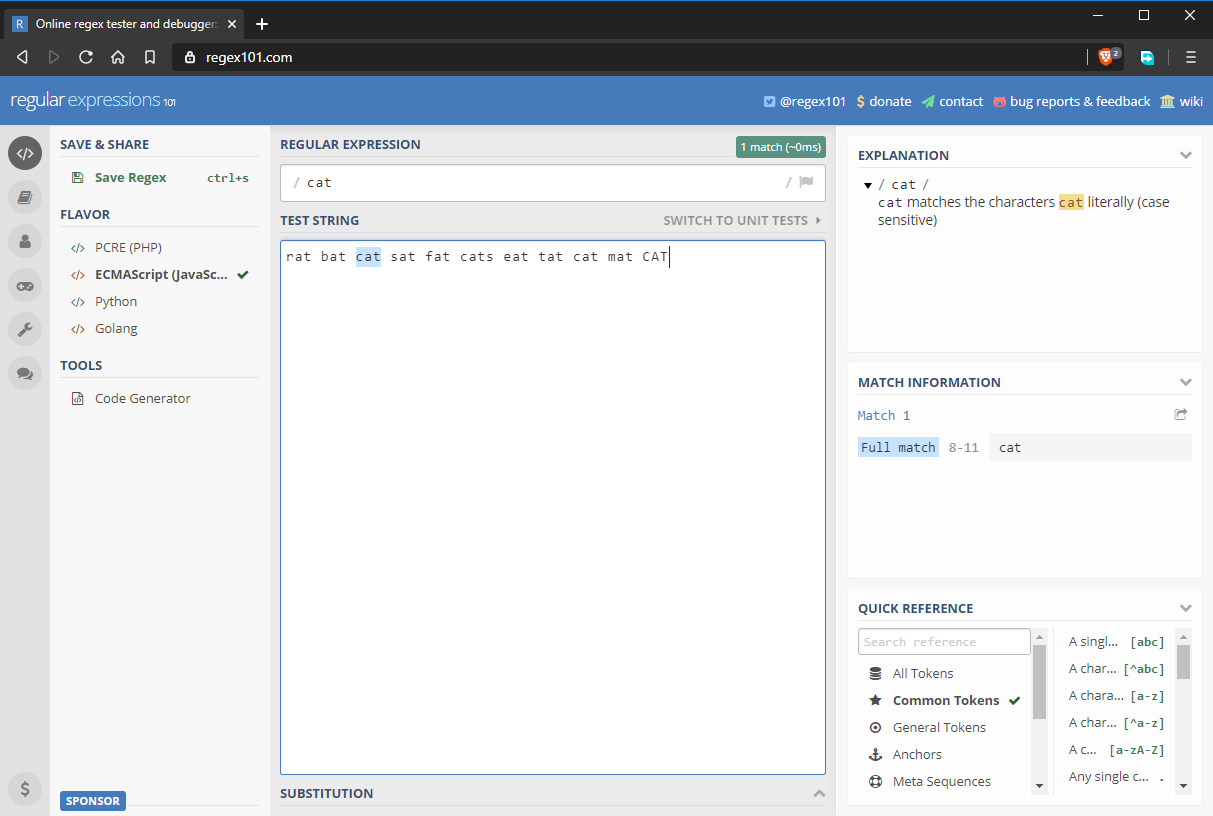
Zauważ, że wyrażenia regularne w JavaScript zaczynają się i kończą na /. Gdybyś miał napisać wyrażenie regularne w kodzie JavaScript, wyglądałoby ono tak: /cat/ bez żadnych cudzysłowów. W powyższym stanie, wyrażenie regularne pasuje do ciągu „kot”. Jednakże, jak widać na powyższym obrazku, istnieje kilka ciągów „cat”, które nie są dopasowane. W następnej sekcji, przyjrzymy się dlaczego.
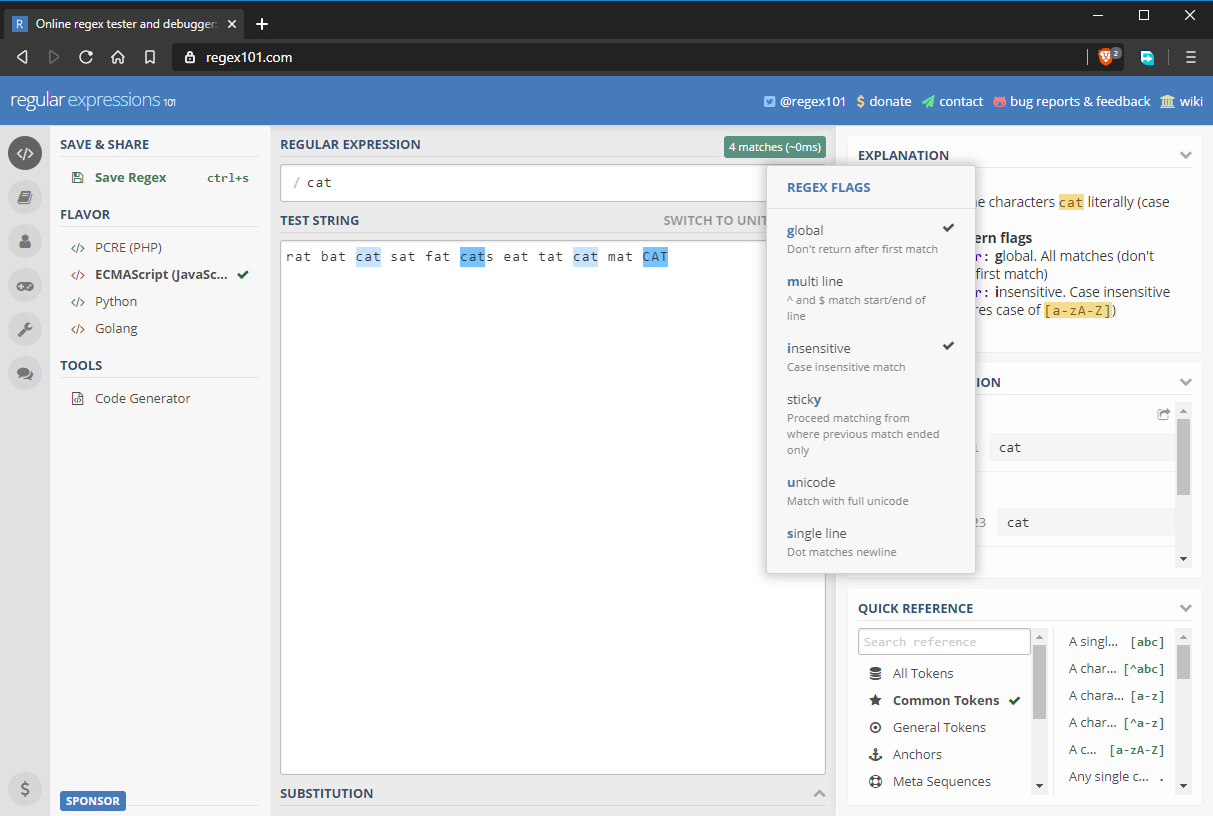
Global and Case Insensitive Regex Flags
Domyślnie, wzorzec regex zwróci tylko pierwsze znalezione dopasowanie. Jeśli chcesz zwrócić dodatkowe dopasowania, musisz włączyć flagę globalną, oznaczoną jako g. Domyślnie we wzorcach regex rozróżniana jest również wielkość liter. Możesz zastąpić to zachowanie przez włączenie flagi niewrażliwości na wielkość liter, oznaczonej i. Zaktualizowany wzorzec regex jest teraz w pełni wyrażony jako /cat/gi. Jak widać poniżej, wszystkie łańcuchy „cat” zostały dopasowane, włączając ten z inną wielkością liter.
Zestawy znaków
W poprzednim przykładzie, dowiedzieliśmy się jak wykonać dokładne dopasowanie z uwzględnieniem wielkości liter. Co jeśli chcielibyśmy dopasować „bat”, „cat”, oraz „fat”. Możemy to zrobić używając zestawów znaków, oznaczanych symbolem . Zasadniczo, wprowadzasz wiele znaków, które chcesz dopasować. Na przykład, at dopasuje wiele łańcuchów w następujący sposób:
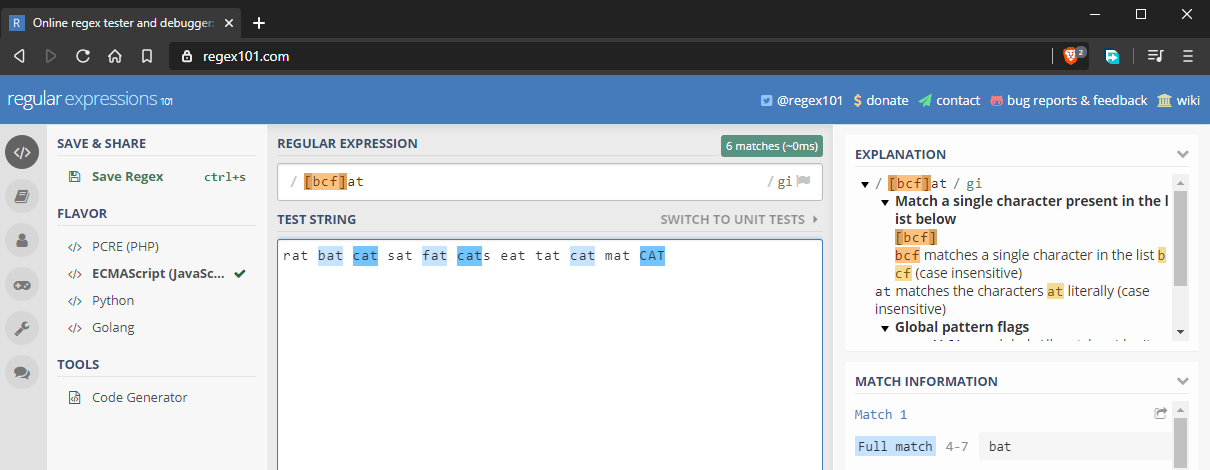
Zestawy znaków działają również z cyframi.
Zakresy
Załóżmy, że chcemy dopasować wszystkie słowa, które kończą się na at. Moglibyśmy podać pełny alfabet wewnątrz zestawu znaków, ale byłoby to uciążliwe. Rozwiązaniem jest użycie zakresów takich jak ten at:
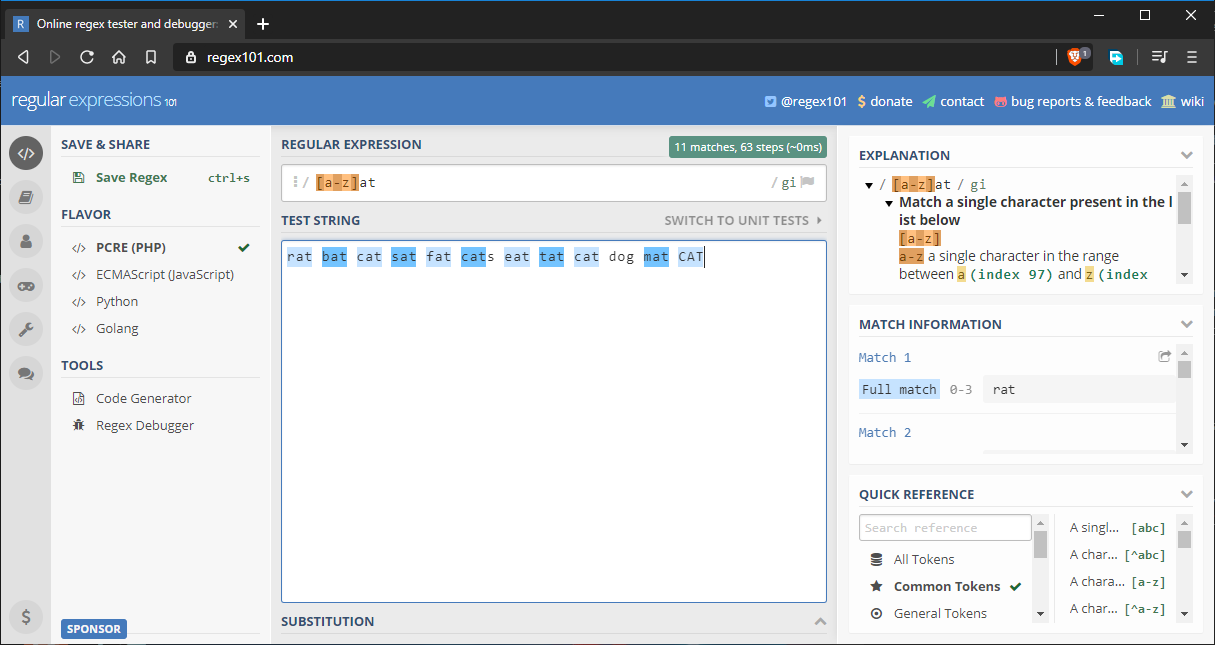
Tutaj jest pełny łańcuch, który jest testowany: rat bat cat sat fat cats eat tat cat dog mat CAT.
Jak widać, wszystkie słowa są dopasowywane zgodnie z oczekiwaniami. Dodałem słowo dog tylko po to, aby wrzucić niepoprawne dopasowanie. Oto inne sposoby użycia zakresów:
-
Zakres częściowy: selekcje takie jak
lub. -
Zakres kapitalizowany:
. -
Zakres cyfr:
. -
Zakres symboli: na przykład
. -
Zakres mieszany: na przykład
obejmuje wszystkie cyfry, małe i wielkie litery. Należy pamiętać, że zakres określa tylko wiele alternatyw dla pojedynczego znaku we wzorcu.Aby lepiej zrozumieć, jak zdefiniować zakres, najlepiej spojrzeć na pełną tabelę ASCII, aby zobaczyć, jak znaki są uporządkowane.

Powtarzające się znaki
Powiedzmy, że chciałbyś dopasować wszystkie trzyliterowe słowa. Prawdopodobnie zrobiłbyś to w ten sposób:
To dopasowałoby wszystkie trzyliterowe słowa. Ale co jeśli chcesz dopasować słowo pięcio- lub ośmioznakowe. Powyższa metoda jest żmudna. Istnieje lepszy sposób na wyrażenie takiego wzorca przy użyciu notacji {} nawiasów klamrowych. Wszystko co musisz zrobić, to określić liczbę powtarzających się znaków. Oto przykłady:
-
a{5}będzie pasować do „aaaaa”. -
n{3}będzie pasować do „nnn”. -
{4}będzie pasować do dowolnego czteroliterowego słowa, takiego jak „drzwi”, „pokój” lub „książka”. -
{6,}dopasuje każde słowo składające się z sześciu lub więcej liter. -
{8,11}dopasuje każde słowo składające się z od ośmiu do 11 liter. Podstawowa walidacja hasła może być przeprowadzona w ten sposób. -
{11}dopasuje 11-cyfrową liczbę. Podstawowa walidacja telefonu międzynarodowego może być przeprowadzona w ten sposób.
Metacharacters
Metacharacters pozwalają na pisanie wzorców wyrażeń regularnych, które są jeszcze bardziej zwarte. Prześledźmy je jeden po drugim:
-
\ddopasowuje każdą cyfrę, która jest taka sama jak -
\wdopasowuje każdą literę, cyfrę i znak podkreślenia -
\sdopasowuje znak białej przestrzeni – tzn, spacja lub tabulator -
\tpasuje tylko do znaku tabulacji
Z tego, czego nauczyliśmy się do tej pory, możemy napisać wyrażenie regularne takie jak to:
-
\w{5}pasuje do dowolnego pięcioliterowego słowa lub pięciocyfrowej liczby -
\d{11}pasuje do 11-cyfrowej liczby, takiej jak numer telefonu
Znaki specjalne
Znaki specjalne przenoszą nas o krok dalej w pisanie bardziej zaawansowanych wyrażeń wzorcowych:
-
+: Jeden lub więcej kwantyfikatorów (poprzedzający znak musi istnieć i może być opcjonalnie powielony). Na przykład, wyrażeniec+atbędzie pasować do „cat”, „ccat” i „ccccccccat”. Możesz powtórzyć poprzedzający znak tyle razy, ile chcesz, a i tak otrzymasz dopasowanie. -
?: Zerowy lub jeden kwantyfikator (poprzedzający znak jest opcjonalny). Na przykład, wyrażeniec?atbędzie pasować tylko do „cat” lub „at”. -
*: Zero lub więcej kwantyfikatorów (poprzedzający znak jest opcjonalny i może być opcjonalnie powielony). Na przykład, wyrażeniec*atbędzie pasowało do „at”, „cat” i „ccccccat”. To jest jak kombinacja+i?. -
\: ten „znak ucieczki” jest używany, gdy chcemy użyć znaku specjalnego dosłownie. Na przykład,c\*będzie dokładnie pasować do „c*”, a nie do „ccccccc”. -
: ta notacja „negacji” jest używana do wskazania znaku, który nie powinien być dopasowywany w danym zakresie. Na przykład, wyrażeniebldnie będzie pasować do „bald” lub „bbld”, ponieważ drugie litery od a do c są ujemne. Jednak wzorzec będzie pasował do „beld”, „bild”, „bold” i tak dalej. -
.: ta notacja „do” dopasuje każdą cyfrę, literę lub symbol z wyjątkiem nowej linii. Na przykład,.{8}będzie pasować do ośmioznakowego hasła składającego się z liter, cyfr i symboli. na przykład, „password” i „P@ssw0rd” będą pasować.
Z tego, czego nauczyliśmy się do tej pory, możemy stworzyć interesującą odmianę kompaktowych, ale potężnych wyrażeń regularnych. Na przykład:
-
.+dopasowuje jeden lub nieograniczoną liczbę znaków. Na przykład, „c” , „cc” i „bcd#.670” będą pasować. -
+będzie pasować do wszystkich słów pisanych małymi literami, niezależnie od długości, tak długo, jak zawierają one co najmniej jedną literę. Na przykład, „book” i „boardroom” będą pasować.
Grupy
Wszystkie znaki specjalne, które właśnie wymieniliśmy, mają wpływ tylko na pojedynczy znak lub zestaw zakresów. A co jeśli chcielibyśmy, aby efekt dotyczył fragmentu wyrażenia? Możemy to zrobić tworząc grupy za pomocą nawiasów okrągłych – (). Na przykład, wzorzec book(.com)? będzie pasował zarówno do „book” jak i „book.com”, ponieważ część „.com” jest opcjonalna.
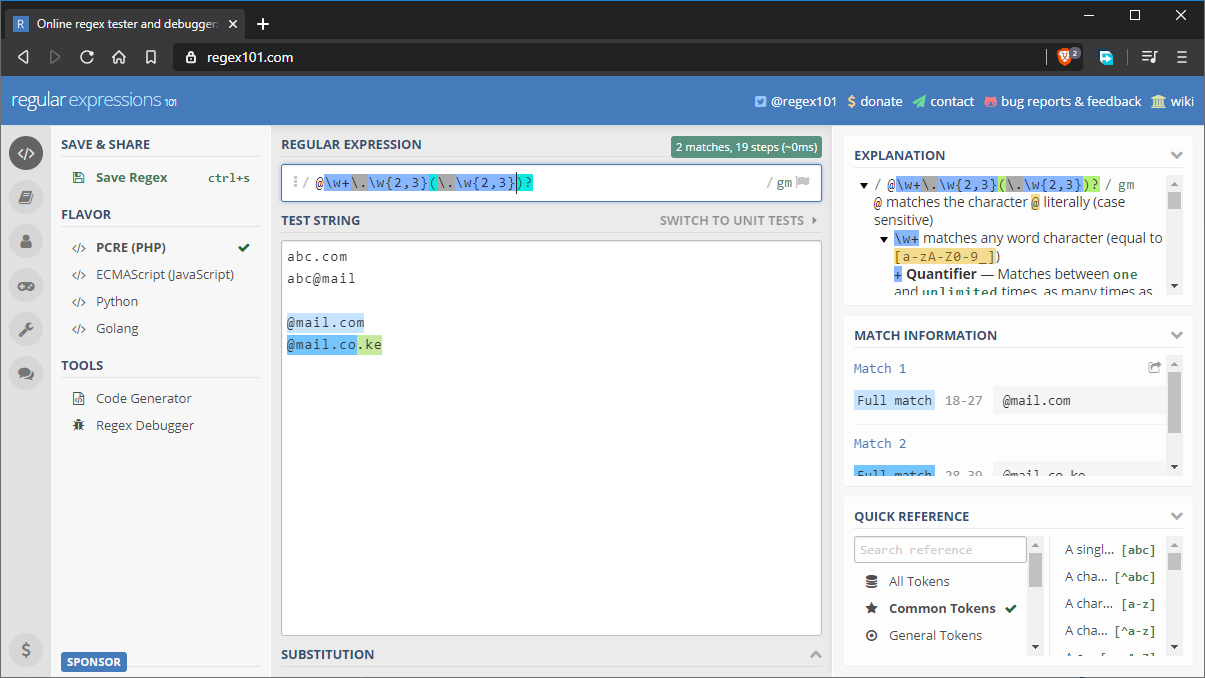
Oto bardziej złożony przykład, który mógłby być użyty w realistycznym scenariuszu, takim jak walidacja emaili:
- wzorzec:
@\w+\.\w{2,3}(\.\w{2,3})? - test string:
abc.com abc@mail @mail.com @mail.co.ke
Znaki alternatywne
W regexie możemy określić znaki alternatywne za pomocą symbolu „pipe” – |. Różni się to od znaków specjalnych, które pokazaliśmy wcześniej, ponieważ wpływa na wszystkie znaki po każdej stronie symbolu rury. Na przykład, wzorzec sat|sit będzie pasował zarówno do ciągów „sat” jak i „sit”. Możemy przepisać wzorzec jako s(a|i)t, aby dopasować te same ciągi znaków.
Powyższy wzorzec może być wyrażony jako s(a|i)t poprzez użycie () nawiasów.
Wzorce początkowe i końcowe
Mogłeś zauważyć, że niektóre pozytywne dopasowania są wynikiem częściowego dopasowania. Na przykład, jeśli napisałem wzorzec pasujący do ciągu „boo”, ciąg „book” również otrzyma pozytywne dopasowanie, mimo że nie jest to dokładne dopasowanie. Aby temu zaradzić, użyjemy następujących notacji:
-
^: umieszczony na początku, ten znak pasuje do wzorca na początku łańcucha. -
$: umieszczony na końcu, ten znak pasuje do wzorca na końcu łańcucha.
Aby naprawić powyższą sytuację, możemy zapisać nasz wzorzec jako boo$. Zapewni to, że ostatnie trzy znaki będą pasowały do wzorca. Jest jednak jeden problem, którego jeszcze nie wzięliśmy pod uwagę, jak pokazuje poniższy obrazek:
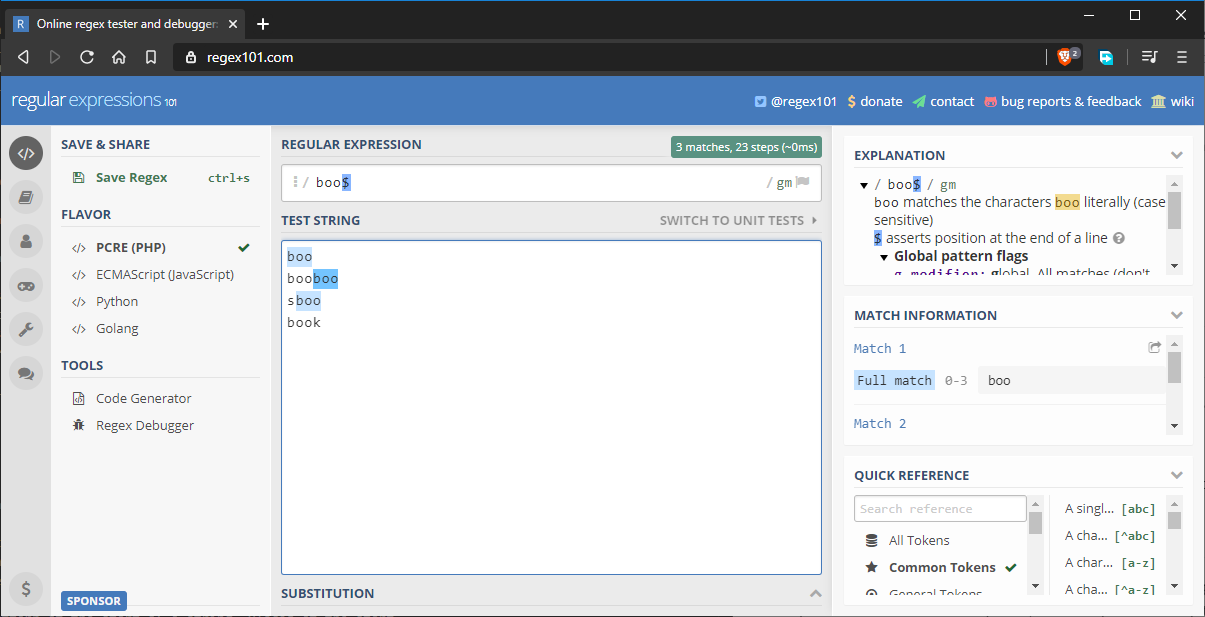
Ciąg „sboo” zostaje dopasowany, ponieważ nadal spełnia aktualne wymagania dopasowania wzorca. Aby to naprawić, możemy zaktualizować wzorzec w następujący sposób: ^boo$. To będzie ściśle pasować do słowa „boo”. Jeśli użyjesz obu z nich, obie reguły będą egzekwowane. Na przykład, ^{5}$ ściśle pasuje do pięcioliterowego słowa. Jeśli ciąg ma więcej niż pięć liter, wzorzec nie pasuje.
Regex w JavaScript
// Example 1const regex1=/a-z/ig//Example 2const regex2= new RegExp(//, 'ig')Jeśli masz Node.js zainstalowany na swoim komputerze, otwórz terminal i wykonaj polecenie node, aby uruchomić interpreter powłoki Node.js. Następnie wykonaj następujące polecenie:
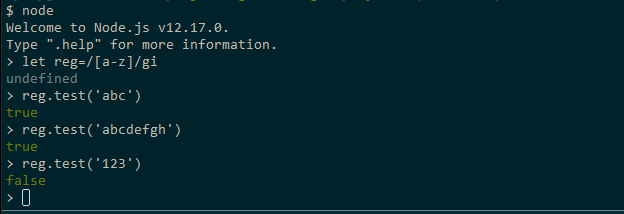
Nie krępuj się grać z większą ilością wzorców regex. Po zakończeniu użyj polecenia .exit, aby wyjść z powłoki.
Przykład z realnego świata: Sprawdzanie poprawności e-maili
Jak zakończymy ten przewodnik, spójrzmy na popularne zastosowanie regex, sprawdzanie poprawności e-maili. (Na przykład, możemy chcieć sprawdzić, czy adres e-mail, który użytkownik wpisał do formularza, jest poprawnym adresem e-mail.)
Ten temat jest bardziej skomplikowany, niż mogłoby się wydawać. Składnia adresu e-mail jest dość prosta: {name}@{domain}. W teorii, adres e-mail może zawierać ograniczoną liczbę symboli, takich jak #-@&%. itp. Jednak umiejscowienie tych symboli ma znaczenie. Serwery pocztowe mają również różne zasady dotyczące używania symboli. Na przykład, niektóre serwery traktują symbol + jako nieprawidłowy. W innych serwerach poczty symbol ten jest używany do podadresowania wiadomości e-mail.
Jako wyzwanie do sprawdzenia swojej wiedzy, spróbuj zbudować wzór wyrażenia regularnego, który pasuje tylko do prawidłowych adresów e-mail zaznaczonych poniżej:
# invalid emailabcabc.com# valid email [email protected]@[email protected]@[email protected]# invalid email [email protected]@[email protected]#[email protected]# valid email [email protected]@[email protected][email protected]# invalid domain [email protected]@mail#[email protected]@mail..com# valid domain [email protected]@[email protected]@[email protected]Uważaj, że niektóre adresy e-mail oznaczone jako prawidłowe mogą być nieprawidłowe dla niektórych organizacji, podczas gdy niektóre oznaczone jako nieprawidłowe mogą być dozwolone w innych organizacjach. Tak czy inaczej, nauka tworzenia niestandardowych wyrażeń regularnych dla organizacji, dla których pracujesz, jest najważniejsza, aby zaspokoić ich potrzeby. W przypadku, gdy utkniesz, możesz spojrzeć na następujące możliwe rozwiązania. Zwróć uwagę, że żadne z nich nie da ci 100% dopasowania do powyższych ważnych ciągów testowych emaili.
- Możliwe rozwiązanie 1:
^\w*(\-\w)?(\.\w*)?@\w*(-\w*)?\.\w{2,3}(\.\w{2,3})?$- Możliwe rozwiązanie 2:
^((\.,;:\s@"]+(\.\.,;:\s@"]+)*)|(".+"))@((\{1,3}\.{1,3}\.{1,3}\.{1,3}])|((+\.)+{2,}))$Podsumowanie
Mam nadzieję, że poznałeś już podstawy wyrażeń regularnych. Nie omówiliśmy wszystkich funkcji regex w tym szybkim przewodniku dla początkujących, ale powinieneś mieć wystarczająco dużo informacji, aby poradzić sobie z większością problemów, które wymagają rozwiązania za pomocą regex. Aby dowiedzieć się więcej, przeczytaj nasz przewodnik na temat najlepszych praktyk praktycznego zastosowania regex w rzeczywistych scenariuszach.