




Uszkodzone pakiety: Fragmentacja IP jest wadliwa
W przeciwieństwie do publicznej sieci telefonicznej, Internet ma konstrukcję Packet Switched. Ale tylko jak duże mogą być te pakiety?
 CC BY 2.0 image by ajmexico, inspired by
CC BY 2.0 image by ajmexico, inspired by
To stare pytanie i IPv4 RFCs odpowiadają na nie dość jasno. Pomysł polegał na podzieleniu problemu na dwa oddzielne problemy:
-
Jaki jest maksymalny rozmiar pakietu, który może być obsługiwany przez systemy operacyjne na obu końcach?
-
Jaki jest maksymalny dozwolony rozmiar datagramu, który może być bezpiecznie przepchnięty przez fizyczne połączenia między hostami?
Gdy pakiet jest zbyt duży dla fizycznego łącza, router pośredni może pociąć go na wiele mniejszych datagramów, aby się zmieścił. Proces ten nazywany jest fragmentacją IP „do przodu”, a mniejsze datagramy nazywane są fragmentami IP.
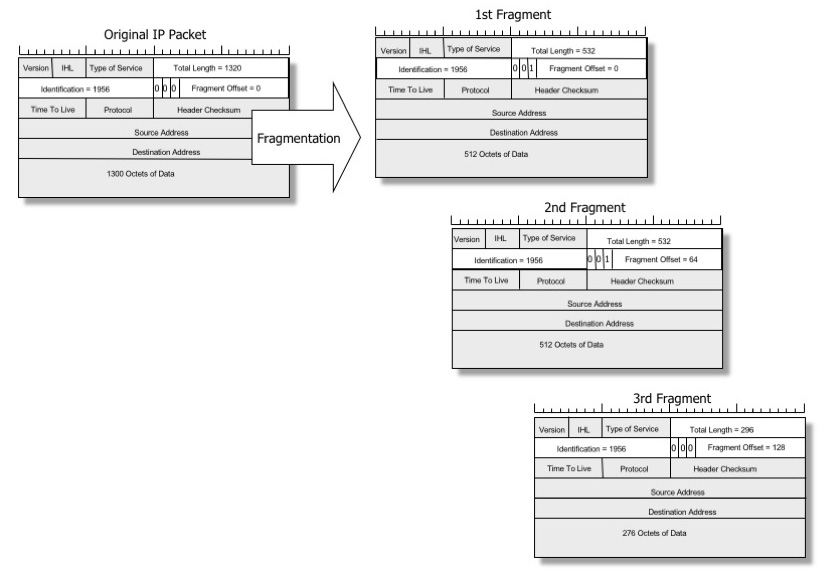 Obraz autorstwa Geoffa Hustona, reprodukowany za zgodą
Obraz autorstwa Geoffa Hustona, reprodukowany za zgodą
Specyfikacja IPv4 określa minimalne wymagania. Z RFC791:
Every internet destination must be able to receive a datagramof 576 octets either in one piece or in fragments tobe reassembled. Every internet module must be able to forward a datagram of 68octets without further fragmentation. Pierwsza wartość – dozwolony rozmiar ponownie złożonego pakietu – nie jest zazwyczaj problematyczna. IPv4 definiuje to minimum jako 576 bajtów, ale popularne systemy operacyjne radzą sobie z bardzo dużymi pakietami, zwykle do 65KiB.
Druga wartość jest bardziej kłopotliwa. Wszystkie fizyczne połączenia mają nieodłączne limity wielkości datagramów, zależne od konkretnego medium, z którego korzystają. Na przykład Frame Relay może wysyłać datagramy o rozmiarze od 46 do 4 470 bajtów. ATM używa stałych 53 bajtów, klasyczny Ethernet może robić od 64 do 1500 bajtów.
Specyfikacja określa minimalne wymaganie – każde fizyczne łącze musi być w stanie transmitować datagramy o wielkości co najmniej 68 bajtów. Dla IPv6 ta minimalna wartość została podniesiona do 1280 bajtów (patrz RFC2460).
Z drugiej strony, maksymalny rozmiar datagramu, który może być przesyłany bez fragmentacji nie jest określony przez żadną specyfikację i różni się w zależności od typu łącza. Wartość ta jest nazywana MTU (Maximum Transmission Unit).
MTU definiuje maksymalny rozmiar datagramu na lokalnym łączu fizycznym. Internet jest stworzony z niejednorodnych sieci, a na drodze między dwoma hostami mogą znajdować się łącza o krótszych wartościach MTU. Maksymalny rozmiar pakietu, który może być przesłany bez fragmentacji pomiędzy dwoma zdalnymi hostami jest nazywany Path MTU, i może być potencjalnie różny dla każdego połączenia.
Unikaj fragmentacji
Można by pomyśleć, że dobrze jest budować aplikacje, które przesyłają bardzo duże pakiety i polegać na routerach w celu wykonania fragmentacji IP. To nie jest dobry pomysł. Problemy z tym podejściem zostały po raz pierwszy omówione przez Kenta i Mogula w 1987 roku. Oto kilka najważniejszych punktów:
-
Aby z powodzeniem ponownie złożyć pakiet, wszystkie fragmenty muszą zostać dostarczone. Żaden fragment nie może stać się uszkodzony lub zgubić się w locie. Po prostu nie ma sposobu na powiadomienie drugiej strony o brakujących fragmentach!
-
Ostatni fragment prawie nigdy nie będzie miał optymalnego rozmiaru. Dla dużych transferów oznacza to, że znaczna część ruchu będzie składała się z nieoptymalnych krótkich datagramów – marnowanie cennych zasobów routera.
-
Przed ponownym złożeniem host musi przechowywać częściowe, fragmentaryczne datagramy w pamięci. Stwarza to możliwość ataków na wyczerpanie pamięci.
-
Kolejne fragmenty pozbawione są nagłówka wyższej warstwy. Nagłówek TCP lub UDP jest obecny tylko w pierwszym fragmencie. Uniemożliwia to firewallom filtrowanie fragmentów datagramów na podstawie takich kryteriów jak porty źródłowe czy docelowe.
Bardziej szczegółowy opis problemów związanych z fragmentacją IP można znaleźć w tych artykułach autorstwa Geoffa Hustona:
- Evaluating IPv4 and IPv6 packet fragmentation
- Fragmenting IPv6
Don’t fragment – ICMP Packet too big
Obraz autorstwa Geoffa Hustona, reprodukowany za zgodą
Rozwiązanie tych problemów zostało zawarte w protokole IPv4. Nadawca może ustawić flagę DF (Don’t Fragment) w nagłówku IP, prosząc pośrednie routery, aby nigdy nie wykonywały fragmentacji pakietu. Zamiast tego router z łączem o mniejszym MTU wyśle komunikat ICMP „wstecz” i poinformuje nadawcę, aby zmniejszył MTU dla tego połączenia.
Protokół TCP zawsze ustawia flagę DF. Stos sieciowy uważnie przygląda się przychodzącym komunikatom ICMP „Packet too big” i śledzi charakterystykę „path MTU” dla każdego połączenia. Technika ta nazywana jest „path MTU discovery” i jest najczęściej używana dla TCP, chociaż może być również stosowana dla innych protokołów opartych na IP. Możliwość dostarczania komunikatów ICMP „Packet too big” jest krytyczna dla utrzymania optymalnego działania stosu TCP.
Jak w rzeczywistości działa Internet
W idealnym świecie, urządzenia połączone z Internetem współpracowałyby i poprawnie obsługiwałyby fragmenty datagramów i związane z nimi pakiety ICMP. W rzeczywistości jednak, fragmenty IP i pakiety ICMP są bardzo często filtrowane.
Wynika to z faktu, że współczesny Internet jest o wiele bardziej złożony niż przewidywano 36 lat temu. Dzisiaj w zasadzie nikt nie jest podłączony bezpośrednio do publicznego Internetu.
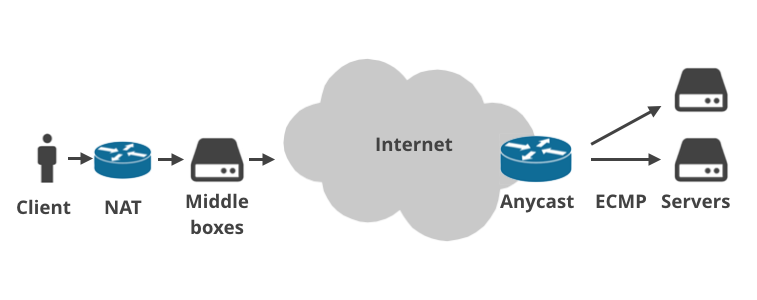
Urządzenia klientów łączą się poprzez routery domowe, które wykonują NAT (Network Address Translation) i zazwyczaj egzekwują reguły zapory. Coraz częściej na ścieżce pakietów znajduje się więcej niż jedna instalacja NAT (np. carrier-grade NAT). Następnie, pakiety trafiają do infrastruktury ISP, gdzie znajdują się „skrzynki pośredniczące” ISP. Wykonują one wszelkiego rodzaju dziwne rzeczy na ruchu: egzekwują limity, dławią połączenia, prowadzą logowanie, porywają żądania DNS, wprowadzają rządowe zakazy stron internetowych, wymuszają przezroczyste buforowanie lub prawdopodobnie „optymalizują” ruch w jakiś inny magiczny sposób. Środkowe skrzynki są używane zwłaszcza przez mobilnych telcos.
Podobnie, często istnieje wiele warstw między serwerem a publicznym Internetem. Dostawcy usług czasami używają Anycast BGP routing. To znaczy: obsługują te same zakresy IP z wielu fizycznych lokalizacji na całym świecie. Z drugiej strony, w centrach danych coraz popularniejsze jest używanie ECMP Equal Cost Multi Path do równoważenia obciążenia.
Każda z tych warstw między klientem a serwerem może spowodować problem z Path MTU. Pozwól, że zilustruję to czterema scenariuszami.
1. Klient -> Serwer DF+ / ICMP
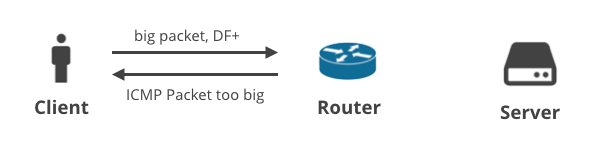
W pierwszym scenariuszu, klient przesyła pewne dane do serwera używając TCP, więc flaga DF jest ustawiona na wszystkich pakietach. Jeśli klientowi nie uda się przewidzieć odpowiedniego MTU, router pośredni porzuci duże pakiety i wyśle do klienta powiadomienie ICMP „Packet too big”. Te pakiety ICMP mogą zostać porzucone przez źle skonfigurowane urządzenia NAT klienta lub pośrednie skrzynki ISP.
Zgodnie z artykułem Maikela de Boera i Jeffreya Bosmy z 2012 roku około 5% hostów IPv4 i 1% hostów IPv6 blokuje przychodzące pakiety ICMP.
Moje doświadczenie to potwierdza. Komunikaty ICMP są rzeczywiście często odrzucane ze względu na postrzegane korzyści związane z bezpieczeństwem, ale jest to stosunkowo łatwe do naprawienia. Większy problem jest z niektórymi mobilnymi dostawcami usług internetowych z dziwnymi skrzynkami pośrednimi. Często całkowicie ignorują one ICMP i wykonują bardzo agresywne przepisywanie połączeń. Na przykład Orange Polska nie tylko ignoruje przychodzące komunikaty ICMP „Packet too big”, ale także przepisuje stan połączenia i zaciska MSS na nienegocjowalne 1344 bajty.
2. Klient -> Serwer DF- / fragmentacja
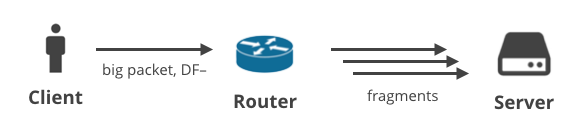
W następnym scenariuszu, klient przesyła jakieś dane protokołem innym niż TCP, który ma wyczyszczoną flagę DF. Na przykład, może to być użytkownik grający w grę używającą UDP, lub prowadzący rozmowę głosową. Duże pakiety wychodzące mogą zostać pofragmentowane w jakimś punkcie ścieżki.
Możemy to emulować, uruchamiając ping z dużym rozmiarem ładunku:
$ ping -s 2048 facebook.comTen konkretny ping zawiedzie przy ładunkach większych niż 1472 bajty. Każdy większy rozmiar zostanie pofragmentowany i nie zostanie poprawnie dostarczony. Istnieje wiele powodów, dla których serwery mogą źle obsługiwać fragmenty, ale jednym z popularnych problemów jest użycie ECMP load balancing. Ze względu na haszowanie ECMP, pierwszy datagram zawierający nagłówek protokołu prawdopodobnie zostanie przeniesiony do innego serwera niż reszta fragmentów, uniemożliwiając ponowne złożenie.
W celu uzyskania bardziej szczegółowej dyskusji na ten temat, zobacz:
- Nasz poprzedni artykuł na temat ECMP.
- Jak Google próbuje rozwiązać problemy z fragmentacją ECMP za pomocą Maglev L4 Load balancer.
Ponadto, błędna konfiguracja serwera i routera jest istotnym problemem. Według RFC7852 od 30% do 55% serwerów odrzuca datagramy IPv6 zawierające nagłówek fragmentacji.
3. Serwer ->Klient DF+ / ICMP
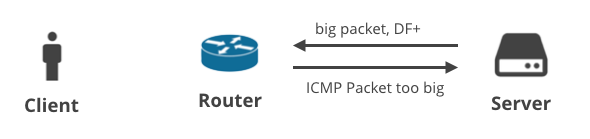
Kolejny scenariusz dotyczy klienta pobierającego dane przez TCP. Gdy serwer nie przewidzi prawidłowego MTU, powinien otrzymać komunikat ICMP „Packet too big”. Proste, prawda?
Niestety, tak nie jest, ponownie z powodu routingu ECMP. Komunikat ICMP najprawdopodobniej zostanie dostarczony do niewłaściwego serwera – 5-tuple hash pakietu ICMP nie będzie pasował do 5-tuple hash problematycznego połączenia. Pisaliśmy o tym w przeszłości i stworzyliśmy prostego demona przestrzeni użytkownika, który rozwiązuje ten problem. Działa on poprzez rozgłaszanie przychodzącego powiadomienia ICMP „Packet too big” do wszystkich serwerów ECMP, mając nadzieję, że ten z problematycznym połączeniem je zobaczy.
Dodatkowo, z powodu routingu Anycast, ICMP może zostać dostarczony do niewłaściwego centrum danych! Routing internetowy jest często asymetryczny i najlepsza ścieżka z routera pośredniego może skierować pakiety ICMP w niewłaściwe miejsce.
Brakujące powiadomienia ICMP „Packet too big” mogą powodować zacinanie się połączeń i kończenie czasu. Jest to często nazywane PMTU blackhole. Aby pomóc w tym pesymistycznym przypadku Linux implementuje obejście – MTU Probing RFC4821. MTU Probing próbuje automatycznie zidentyfikować pakiety porzucone z powodu niewłaściwego MTU i używa heurystyki do dostrojenia go. Funkcja ta jest kontrolowana przez sysctl:
$ echo 1 > /proc/sys/net/ipv4/tcp_mtu_probingAle sondowanie MTU nie jest pozbawione własnych problemów. Po pierwsze, ma tendencję do błędnego klasyfikowania strat pakietów związanych z przeciążeniem jako problemów z MTU. Długo działające połączenia mają tendencję do kończenia się z obniżonym MTU. Po drugie, Linux nie implementuje MTU Probing dla IPv6.
4. Serwer -> Klient DF- / fragmentacja
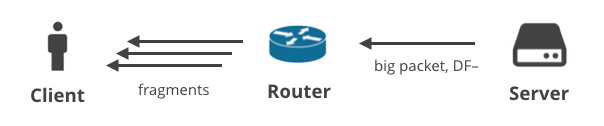
Wreszcie, istnieje sytuacja, w której serwer wysyła duże pakiety używając protokołu nie-TCP z wyczyszczonym bitem DF. W tym scenariuszu duże pakiety zostaną pofragmentowane na drodze do klienta. Sytuacja ta jest najlepiej zilustrowana na przykładzie dużych odpowiedzi DNS. Oto dwa żądania DNS, które wygenerują duże odpowiedzi i zostaną dostarczone do klienta jako wiele fragmentów IP:
$ dig +notcp +dnssec DNSKEY org @199.19.56.1$ dig +notcp +dnssec DNSKEY org @2001:500:f::1Te żądania mogą zawieść z powodu wspomnianego już źle skonfigurowanego routera domowego, uszkodzonego NAT, uszkodzonej instalacji ISP lub zbyt restrykcyjnych ustawień firewalla.
Według Boer i Bosma około 6% hostów IPv4 i 10% hostów IPv6 blokuje przychodzące fragmenty datagramów.
Tutaj znajduje się kilka linków zawierających więcej informacji o specyficznych problemach z fragmentacją wpływających na DNS:
- DNS-OARC Reply Size Test
- IPv6, Large UDP Packets and the DNS
Ale Internet wciąż działa!
Przy tych wszystkich rzeczach, które idą źle, jak to się dzieje, że internet wciąż działa?
 CC BY-SA 3.0, źródło: Wikipedia
CC BY-SA 3.0, źródło: Wikipedia
Wynika to głównie z sukcesu Ethernetu. Zdecydowana większość łączy w publicznym internecie to Ethernet (lub pochodna) i obsługuje MTU 1500 bajtów.
Jeśli ślepo przyjmiesz MTU równe 1500, będziesz zaskoczony, jak często będzie to działało po prostu dobrze. Internet nadal działa głównie dlatego, że wszyscy używamy MTU równego 1500 i rzadko musimy wykonywać fragmentację IP i wysyłać komunikaty ICMP.
To przestaje działać w nietypowej konfiguracji z łączami o niestandardowym MTU. VPN-y i inne oprogramowanie tuneli sieciowych musi być ostrożne, aby zapewnić, że fragmentacje i komunikaty ICMP działają dobrze.
Jest to szczególnie widoczne w świecie IPv6, gdzie wielu użytkowników łączy się przez tunele. Posiadanie zdrowego przejścia ICMP w obie strony jest bardzo ważne, zwłaszcza że fragmentacja w IPv6 w zasadzie nie działa (przytoczyliśmy dwa źródła twierdzące, że między 10% a 50% hostów IPv6 blokuje nagłówek Fragment IPv6).
Ponieważ problemy z Path MTU w IPv6 są tak powszechne, wiele serwerów IPv6 zaciska Path MTU do zalecanego przez protokół minimum 1280 bajtów. Takie podejście pozwala przehandlować trochę wydajności za najlepszą niezawodność.
Online ICMP blackhole checker
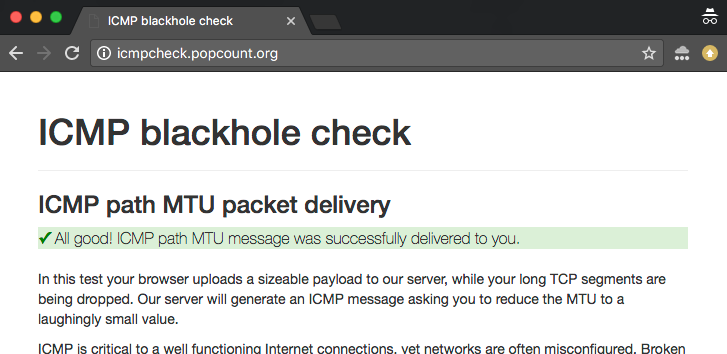
Aby pomóc w badaniu i usuwaniu błędów, zbudowaliśmy tester online. Możesz znaleźć dwie wersje testu:
- Wersja IPv4: http://icmpcheck.popcount.org
- IPv6 wersja: http://icmpcheckv6.popcount.org
Strony te uruchamiają dwa testy:
- Pierwszy test dostarczy komunikaty ICMP do twojego komputera, z zamiarem zmniejszenia Path MTU do śmiesznie małej wartości.
- Drugi test wyśle z powrotem do ciebie fragmentaryczne datagramy.
Otrzymanie „pass” w obu tych testach powinno dać ci rozsądną pewność, że Internet po twojej stronie kabla zachowuje się dobrze.
Łatwo jest również uruchomić testy z linii poleceń, na wypadek gdybyś chciał je uruchomić na serwerze:
perl -e "print 'packettoolongyaithuji6reeNab4XahChaeRah1diej4' x 180" > payload.bincurl -v -s http://icmpcheck.popcount.org/icmp --data @payload.bincurl -v -s http://icmpcheckv6.popcount.org/icmp --data @payload.binTo powinno zredukować path MTU do naszego serwera do 905 bajtów. Możesz to zweryfikować zaglądając do tablicy cache routingu. Na Linuksie zrobisz to za pomocą:
ip route get `dig +short icmpcheck.popcount.org`Możesz wyczyścić routing cache na Linuksie:
ip route flush cache to `dig +short icmpcheck.popcount.org`Drugi test sprawdza czy fragmenty są poprawnie dostarczane do klienta:
curl -v -s http://icmpcheck.popcount.org/frag -o /dev/nullcurl -v -s http://icmpcheckv6.popcount.org/frag -o /dev/nullPodsumowanie
W tym wpisie na blogu opisaliśmy problemy z wykrywaniem wartości Path MTU w internecie. Datagramy ICMP i fragmenty są często blokowane po obu stronach połączenia. Klienci mogą napotkać źle skonfigurowane firewalle, urządzenia NAT lub korzystać z usług dostawców Internetu, którzy agresywnie przechwytują połączenia. Klienci często korzystają również z VPN-ów lub tuneli IPv6, które, źle skonfigurowane, mogą powodować problemy z MTU ścieżki.
Serwery z drugiej strony coraz częściej polegają na Anycast lub ECMP. Obie te rzeczy, jak również błędna konfiguracja routerów i firewalli są często przyczyną porzucania datagramów ICMP i fragmentów.
Na koniec, mamy nadzieję, że test online jest przydatny i może dać ci więcej wglądu w wewnętrzne funkcjonowanie twojej sieci. Test zawiera użyteczne przykłady składni tcpdump, przydatne do uzyskania lepszego wglądu. Szczęśliwego debugowania sieci!
Czy rozwiązywanie problemów z fragmentacją dla 10% Internetu jest ekscytujące? Zatrudniamy inżynierów systemowych, programistów Golang, programistów C oraz stażystów w wielu lokalizacjach! Dołącz do nas w San Francisco, Londynie, Austin, Champaign i Warszawie.
-
W IPv6 fragmentacja „forward” działa nieco inaczej niż w IPv4. Routery pośrednie nie mogą fragmentować pakietów, ale źródło nadal może to robić. Jest to często mylące – host może zostać poproszony o fragmentację pakietu, który przesłał w przeszłości. Nie ma to sensu w przypadku protokołów bezstanowych, takich jak DNS. ︎
-
Na marginesie, istnieje również „minimalna jednostka transmisji”! W powszechnie używanym ramkowaniu Ethernet, każdy transmitowany datagram musi mieć co najmniej 64 bajty na warstwie 2. Przekłada się to na 22 bajty na warstwie UDP i 10 bajtów na warstwie TCP. Wiele implementacji wykorzystywało wyciek niezainicjowanej pamięci przy krótszych pakietach! ︎
-
Ściśle mówiąc w IPv4 pakiet ICMP jest nazwany „Destination Unreachable, Fragmentation Needed and Don’t Fragment został ustawiony”. Ale uważam, że opis błędu IPv6 ICMP „Packet too big” jest o wiele bardziej zrozumiały. ︎
-
Jako wskazówka, stos TCP również zawiera maksymalną dozwoloną wartość „MSS” w pakietach SYN (MSS jest w zasadzie wartością MTU pomniejszoną o rozmiar nagłówków IP i TCP). Pozwala to hostom wiedzieć, jakie jest MTU na ich łączach. Uwaga: to nie mówi jakie jest MTU na kilkudziesięciu łączach internetowych pomiędzy dwoma hostami! ︎
-
Let’s err on on the safe side. Lepszym MTU jest 1492, aby dostosować się do połączeń DSL i PPPoE. ︎