




Wprowadzenie do projektowania baz danych
Identyfikacja atrybutów
Elementy danych, które chcesz zapisać dla każdej jednostki nazywane są „atrybutami”.
O produktach, które sprzedajesz, chcesz wiedzieć, na przykład, jaka jest cena, jaka jest nazwa producenta i jaki jest numer typu. O klientach wiesz, jaki jest ich numer klienta, imię i nazwisko oraz adres. Na temat sklepów znasz kod lokalizacji, nazwę, adres. O sprzedaży wiesz, kiedy się odbyła, w którym sklepie, jakie produkty zostały sprzedane i jaka była suma sprzedaży. O sprzedawcy wiesz, jaki jest jego numer personalny, nazwisko i adres. To, co dokładnie zostanie uwzględnione, nie ma jeszcze znaczenia, chodzi tylko o to, co chcesz zapisać.
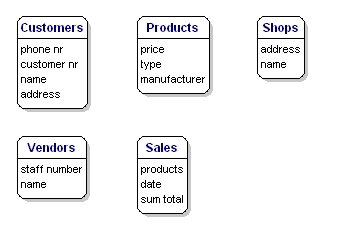
Rysunek 6: Podmioty z atrybutami.
Dane pochodne
Dane pochodne to dane, które wynikają z innych danych, które już zapisałeś. W tym przypadku „suma całkowita” jest klasycznym przypadkiem danych pochodnych. Wiesz dokładnie, co zostało sprzedane i ile kosztuje każdy produkt, więc zawsze możesz obliczyć, ile wynosi suma sprzedaży. Więc naprawdę nie jest konieczne zapisywanie sumy całkowitej.
Dlaczego więc jest ona zapisywana tutaj? Cóż, ponieważ jest to sprzedaż, a cena produktu może się zmieniać w czasie. Produkt może być wyceniony na 10 euro dzisiaj i na 8 euro w przyszłym miesiącu, a dla administracji musisz wiedzieć, ile kosztował w momencie sprzedaży, a najprostszym sposobem na to jest zapisanie go tutaj. Istnieje wiele bardziej eleganckich sposobów, ale są one zbyt głębokie dla tego artykułu.
Przedstawianie encji i relacji: Entity Relationship Diagram (ERD)
Diagram relacji encji (ERD) daje graficzny przegląd bazy danych. Istnieje kilka stylów i typów diagramów ERD. Często używaną notacją jest notacja „crowfeet”, gdzie encje są reprezentowane jako prostokąty, a relacje między encjami są reprezentowane jako linie między encjami. Znaki na końcu linii wskazują na typ relacji. Strona relacji, która jest obowiązkowa dla drugiej, aby istnieć, będzie wskazana przez kreskę na linii. Nieobowiązkowe podmioty są oznaczone kółkiem. Wiele” jest wskazywane przez „kurze łapki”; linia relacji rozdziela się na trzy linie.
W tym artykule wykorzystamy DeZign for Databases do zaprojektowania i przedstawienia naszej bazy danych.
Obligatoryjna relacja 1:1 jest przedstawiona w następujący sposób:
Rysunek 7: Obligatoryjna relacja jeden do jednego.
Obligatoryjna relacja 1:N przedstawia się następująco:
Rysunek 8: Obligatoryjna relacja jeden do wielu.
A relacja M:N obowiązkowa to:
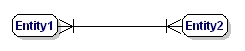
Rysunek 9: Relacja obowiązkowa wiele do wielu.
Model naszego przykładu będzie wyglądał następująco:
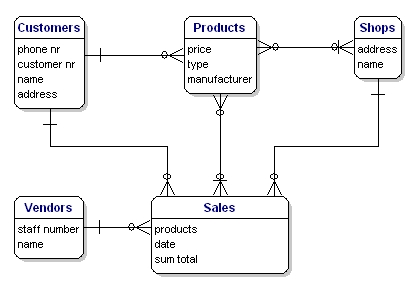
Rysunek 10: Model z relacjami.
Przypisywanie kluczy
Klucze główne
Klucz główny (PK) to jeden lub więcej atrybutów danych, które jednoznacznie identyfikują encję. Klucz, który składa się z dwóch lub więcej atrybutów nazywany jest kluczem złożonym. Wszystkie atrybuty będące częścią klucza głównego muszą mieć wartość w każdym rekordzie (który nie może być pusty), a kombinacja wartości w tych atrybutach musi być unikalna w tabeli.
W przykładzie jest kilku oczywistych kandydatów do klucza głównego. Klienci wszyscy mają numer klienta, produkty wszystkie mają unikalny numer produktu i sprzedaży mają numer sprzedaży. Każda z tych danych jest unikalna i każdy rekord będzie zawierał wartość, więc te atrybuty mogą być kluczem głównym. Często kolumna liczb całkowitych jest używana jako klucz główny, więc rekord może być łatwo znaleziony poprzez jego numer.
Podmioty linkujące zazwyczaj odnoszą się do atrybutów klucza głównego podmiotów, które łączą. Klucz główny powiązanej encji jest zazwyczaj zbiorem tych atrybutów odniesienia. Na przykład w encji Sales_details moglibyśmy użyć kombinacji PK encji sales i products jako PK Sales_details. W ten sposób wymuszamy, że ten sam produkt (typ) może być użyty tylko raz w tej samej sprzedaży. Wiele pozycji tego samego typu produktu w sprzedaży musi być wskazanych przez ilość.
W ERD atrybuty klucza głównego są oznaczone tekstem 'PK’ za nazwą atrybutu. W przykładzie tylko encja „sklep” nie ma oczywistego kandydata na PK, więc wprowadzimy nowy atrybut dla tej encji: shopnr.
Klucze obce
Klucz obcy (FK) w encji jest odniesieniem do klucza głównego innej encji. W ERD atrybut ten będzie oznaczony jako „FK” za jego nazwą. Klucz obcy encji może być również częścią klucza głównego, w takim przypadku atrybut będzie oznaczony jako 'PF’ za jego nazwą. Zwykle ma to miejsce w przypadku encji typu link, ponieważ zazwyczaj łączymy dwie instancje tylko raz razem (przy 1 sprzedaży tylko 1 typ produktu jest sprzedawany 1 raz).
Jeśli umieścimy wszystkie encje typu link, PK i FK w ERD, otrzymamy model jak pokazano poniżej. Proszę zauważyć, że atrybut „produkty” nie jest już potrzebny w „Sprzedaż”, ponieważ „sprzedane produkty” są teraz zawarte w tabeli odnośników. W tabeli łączącej dodano kolejne pole, „ilość”, które wskazuje, ile produktów zostało sprzedanych. Pole „ilość” zostało również dodane w tabeli zapasów, aby wskazać, ile produktów znajduje się jeszcze w magazynie.
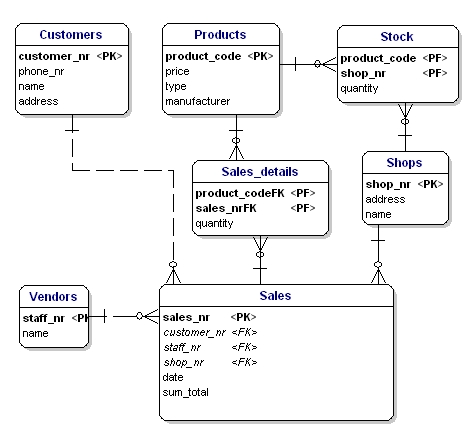
Rysunek 11: Klucze podstawowe i klucze obce.
Definiowanie typu danych atrybutu
Teraz nadszedł czas, aby ustalić, jakie typy danych muszą być użyte w atrybutach. Istnieje wiele różnych typów danych. Kilka z nich jest standaryzowanych, ale wiele baz danych posiada własne typy danych, które mają swoje zalety. Niektóre bazy danych oferują możliwość definiowania własnych typów danych, w przypadku, gdy standardowe typy nie mogą wykonać tego, czego potrzebujesz.
Standardowe typy danych, które zna każda baza danych i które są najczęściej używane, to: CHAR, VARCHAR, TEXT, FLOAT, DOUBLE oraz INT.
Text:
- CHAR(length) – zawiera tekst (znaki, liczby, znaki interpunkcyjne…). CHAR ma tę właściwość, że zawsze zapisuje stałą ilość pozycji. Jeżeli zdefiniujemy CHAR(10) to możemy zapisać maksymalnie do dziesięciu pozycji, ale jeżeli użyjemy tylko dwóch pozycji to baza danych i tak zapisze 10 pozycji. Pozostałe osiem pozycji zostanie wypełnione spacjami.
- VARCHAR(length) – zawiera tekst (znaki, liczby, interpunkcję…). VARCHAR jest taki sam jak CHAR, różnica polega na tym, że VARCHAR zajmuje tylko tyle miejsca, ile potrzeba.
- TEXT – może zawierać duże ilości tekstu. W zależności od typu bazy danych może to być nawet do gigabajtów.
Liczby:
- INT – zawiera dodatnią lub ujemną liczbę całkowitą. Wiele baz danych posiada odmiany INT, takie jak: TINYINT, SMALLINT, MEDIUMINT, BIGINT, INT2, INT4, INT8. Odmiany te różnią się od INT tylko wielkością liczby, która się w nich mieści. Zwykły INT ma wielkość 4 bajtów (INT4) i mieści liczby od -2147483647 do +2147483646, lub jeśli określisz go jako UNSIGNED od 0 do 4294967296. INT8, czyli BIGINT, może mieć jeszcze większy rozmiar, od 0 do 18446744073709551616, ale zajmuje do 8 bajtów przestrzeni dyskowej, nawet jeśli jest w nim tylko mała liczba.
- FLOAT, DOUBLE – Ta sama idea co INT, ale może również przechowywać liczby zmiennoprzecinkowe. . Należy pamiętać, że nie zawsze działa to idealnie. Na przykład w MySQL obliczanie za pomocą tych liczb zmiennoprzecinkowych nie jest idealne, (1/3)*3 da wynik 0.9999999, a nie 1.
Inne typy:
- BLOB – dla danych binarnych, takich jak pliki.
- INET – dla adresów IP. Używany również dla netmasek.
Dla naszego przykładu typy danych są następujące:
Rysunek 12: Model danych wyświetlający typy danych.
Normalizacja
Normalizacja sprawia, że Twój model danych jest elastyczny i niezawodny. Generuje to pewien narzut, ponieważ zazwyczaj otrzymujemy więcej tabel, ale umożliwia robienie wielu rzeczy z modelem danych bez konieczności jego dostosowywania. Możesz przeczytać więcej o normalizacji bazy danych w tym artykule.
Normalizacja, pierwsza forma
Pierwsza forma normalizacji mówi, że nie może być powtarzających się grup kolumn w encji. Moglibyśmy utworzyć encję „sprzedaż” z atrybutami dla każdego z produktów, które zostały zakupione. Wyglądałoby to tak:

Rysunek 13: Nie w pierwszej postaci normalnej.
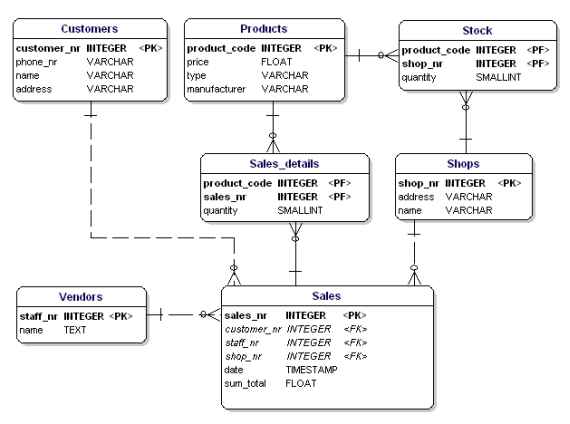
Co jest w tym złego, to fakt, że teraz można sprzedać tylko 3 produkty. Jeśli musiałbyś sprzedawać 4 produkty, musiałbyś rozpocząć drugą sprzedaż lub dostosować swój model danych poprzez dodanie atrybutów 'product4′. Oba rozwiązania są niepożądane. W takich przypadkach zawsze powinieneś stworzyć nową encję, którą połączysz ze starą poprzez relację jeden do wielu.
Rysunek 14: Zgodnie z 1. postacią normalną.
Normalizacja, druga forma
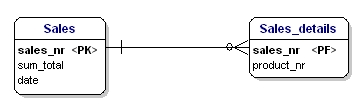
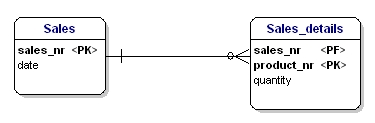
Druga forma normalizacji stwierdza, że wszystkie atrybuty encji powinny być w pełni zależne od całego klucza głównego. Oznacza to, że każdy atrybut encji może być zidentyfikowany tylko poprzez cały klucz główny. Załóżmy, że w encji Sales_details mamy datę:

Rysunek 15: Nie w drugiej postaci normalnej.
Ta encja nie jest zgodna z drugą postacią normalizacyjną, ponieważ aby móc sprawdzić datę sprzedaży, nie muszę wiedzieć co zostało sprzedane (productnr), jedyne co muszę wiedzieć to numer sprzedaży. Rozwiązano to poprzez rozdzielenie tabel na tabelę sprzedaż i tabelę sprzedaż_details:
Rysunek 16: Zgodnie z 2. postacią normalną.
Teraz każdy atrybut encji jest zależny od całego PK encji. Data jest zależna od numeru sprzedaży, a ilość jest zależna od numeru sprzedaży i sprzedanego produktu.
Normalizacja, trzecia forma
Trzecia forma normalizacji mówi, że wszystkie atrybuty muszą być bezpośrednio zależne od klucza głównego, a nie od innych atrybutów. Wydaje się, że jest to to, co stwierdza druga forma normalizacji, ale w drugiej formie jest w rzeczywistości podane odwrotnie. W drugiej formie normalizacji wskazujesz na atrybuty poprzez PK, w trzeciej formie normalizacji każdy atrybut musi być zależny od PK i nic więcej.

Rysunek 17: Nie w trzeciej formie normalnej.
W tym przypadku cena produktu luzem jest zależna od numeru zamówienia, a numer zamówienia jest zależny od numeru produktu i numeru sprzedaży. Nie jest to zgodne z trzecią postacią normalizacji. Ponownie podział na tablice rozwiązuje ten problem.
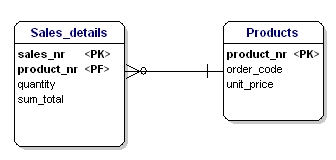
Rysunek 18: Zgodnie z trzecią postacią normalną.
Normalizacja, więcej form
Istnieje więcej form normalizacji niż trzy formy wymienione powyżej, ale te nie są zbyt interesujące dla przeciętnego użytkownika. Te inne formularze są wysoce wyspecjalizowane dla pewnych zastosowań. Jeśli będziesz trzymał się zasad projektowania i normalizacji wspomnianych w tym artykule, stworzysz projekt, który będzie działał świetnie dla większości aplikacji.
Normalizowany model danych
Jeśli zastosujesz zasady normalizacji, przekonasz się, że „producent” w tabeli produktów również powinien być osobną tabelą:
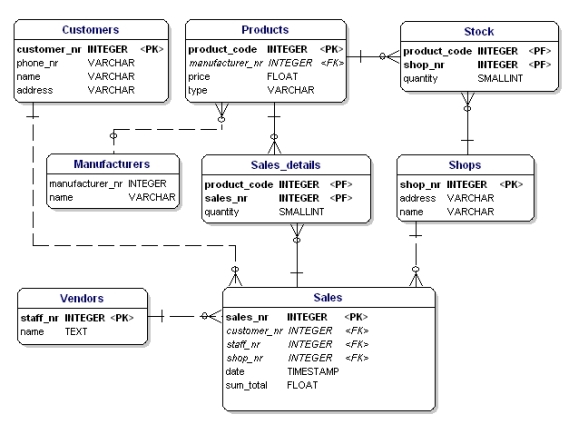
Rysunek 19: Model danych zgodny z 1, 2 i 3 formą normalną.