




Introduction to Database Design
Identificando Atributos
Os elementos de dados que você quer salvar para cada entidade são chamados de ‘atributos’.
Sobre os produtos que você vende, você quer saber, por exemplo, qual é o preço, qual é o nome do fabricante, e qual é o número do tipo. Sobre os clientes você sabe seu número de cliente, seu nome, e endereço. Sobre as lojas, você sabe o código de localização, o nome, o endereço. Das vendas que você sabe quando aconteceram, em que loja, que produtos foram vendidos e a soma total da venda. Do vendedor você sabe o número de pessoal, nome e endereço dele. O que será incluído com precisão ainda não é importante; ainda é apenas sobre o que você quer salvar.
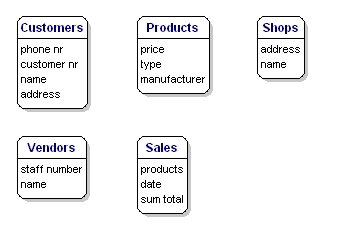
Figura 6: Entidades com atributos.
Dados derivados
Dados derivados são dados que são derivados de outros dados que você já salvou. Neste caso, a ‘soma total’ é um caso clássico de dados derivados. Você sabe exatamente o que foi vendido e o que cada produto custa, então você pode sempre calcular o quanto é a soma total das vendas. Portanto, realmente não é necessário gravar a soma total.
Então porque é que é guardado aqui? Bem, porque é uma venda, e o preço do produto pode variar ao longo do tempo. Um produto pode ter um preço de 10 euros hoje e de 8 euros no próximo mês, e para a sua administração você precisa saber quanto custa no momento da venda, e a maneira mais fácil de fazer isso é guardá-lo aqui. Há muitas maneiras mais elegantes, mas são demasiado profundas para este artigo.
Apresentando Entidades e Relacionamentos: Diagrama de Relacionamento de Entidades (ERD)
O Diagrama de Relacionamento de Entidades (ERD) dá uma visão gráfica da base de dados. Existem vários estilos e tipos de Diagramas ER. Uma notação muito utilizada é a notação ‘crowfeet’, onde as entidades são representadas como rectângulos e as relações entre as entidades são representadas como linhas entre as entidades. Os sinais no final das linhas indicam o tipo de relação. O lado da relação que é obrigatório para que a outra exista será indicado através de um traço na linha. As entidades não obrigatórias são indicadas através de um círculo. “Muitas” é indicado através de um ‘crowfeet’; a linha de relação se divide em três linhas.
Neste artigo utilizamos o DeZign for Databases para desenhar e apresentar nossa base de dados.
A relação obrigatória 1:1 é representada da seguinte forma:
Figura 7: Relação obrigatória uma para uma.
A 1:N relação obrigatória:
Figura 8: Obrigatória uma para muitas relações.
Uma relação M:N é:
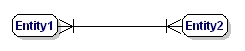
Figura 9: Obrigatória uma a muitas relações.
O modelo do nosso exemplo parecerá assim:
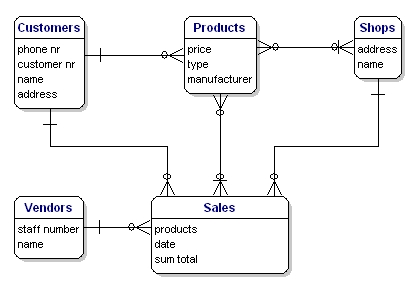
Figura 10: Modelo com relacionamentos.
Atribuição de chaves
Primary Keys
Uma chave primária (PK) é um ou mais atributos de dados que identificam de forma única uma entidade. Uma chave que consiste em dois ou mais atributos é chamada de chave composta. Todos os atributos parte de uma chave primária devem ter um valor em cada registro (que não pode ser deixado vazio) e a combinação dos valores dentro desses atributos deve ser única na tabela.
No exemplo, há alguns candidatos óbvios para a chave primária. Todos os clientes têm um número de cliente, todos os produtos têm um número de produto único e as vendas têm um número de venda. Cada um desses dados é único e cada registro conterá um valor, portanto esses atributos podem ser uma chave primária. Muitas vezes uma coluna inteira é usada para a chave primária para que um registro possa ser facilmente encontrado através de seu número.
Link-entities geralmente se referem aos atributos da chave primária das entidades que eles ligam. A chave primária de uma link-entidade é normalmente uma coleção desses atributos de referência. Por exemplo, na entidade Sales_details, poderíamos usar a combinação dos PK’s das entidades de vendas e produtos como o PK of Sales_details. Desta forma, é possível impor que o mesmo produto (tipo) só possa ser usado uma vez na mesma venda. Vários itens do mesmo tipo de produto em uma venda devem ser indicados pela quantidade.
Na ERD os principais atributos-chave são indicados pelo texto ‘PK’ por trás do nome do atributo. No exemplo só a entidade ‘shop’ não tem um candidato óbvio para o PK, portanto vamos introduzir um novo atributo para essa entidade: shopnr.
Foreign Keys
A Foreign Key (FK) em uma entidade é a referência para a chave primária de outra entidade. Na ERD esse atributo será indicado com ‘FK’ atrás de seu nome. A chave estrangeira de uma entidade também pode fazer parte da chave primária, neste caso o atributo será indicado com ‘PF’ atrás do seu nome. Este é normalmente o caso com as link-entities, pois você normalmente liga duas instâncias apenas uma vez (com 1 venda apenas 1 tipo de produto é vendido 1 vez).
Se colocarmos todas as link-entities, PK’s e FK’s na ERD, obtemos o modelo como mostrado abaixo. Por favor note que o atributo ‘produtos’ não é mais necessário em ‘Vendas’, porque ‘produtos vendidos’ está agora incluído no link-table. No link-table foi adicionado outro campo, ‘quantidade’, que indica quantos produtos foram vendidos. O campo quantidade também foi adicionado na tabela de estoque, para indicar quantos produtos ainda estão na loja.
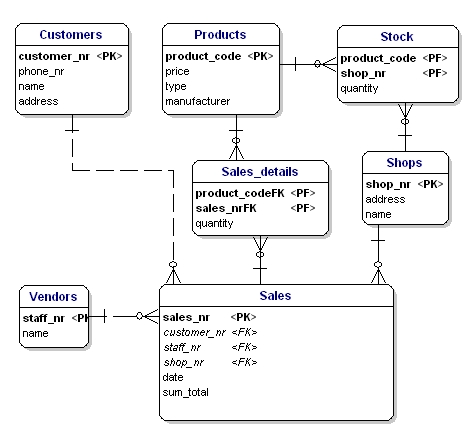
Figura 11: Chaves primárias e chaves estrangeiras.
Definindo o Tipo de Dados do Atributo
Agora é hora de descobrir quais tipos de dados precisam ser usados para os atributos. Existem muitos tipos de dados diferentes. Alguns são padronizados, mas muitos bancos de dados têm seus próprios tipos de dados, todos com suas próprias vantagens. Alguns bancos de dados oferecem a possibilidade de definir seus próprios tipos de dados, caso os tipos padrão não possam fazer as coisas que você precisa.
Os tipos de dados padrão que todos os bancos de dados conhecem, e são mais utilizados, são: CHAR, VARCHAR, TEXT, FLOAT, DOUBLE, e INT.
Texto:
- CHAR(comprimento) – inclui texto (caracteres, números, pontuações…). CHAR tem como característica que sempre guarda uma quantidade fixa de posições. Se você definir um CHAR(10) você pode gravar até dez posições no máximo, mas se você usar apenas duas posições o banco de dados ainda irá gravar 10 posições. As oito posições restantes serão preenchidas por espaços.
- VARCHAR(comprimento) – inclui texto (caracteres, números, pontuação…). VARCHAR é o mesmo que CHAR, a diferença é que VARCHAR só ocupa o espaço necessário.
- TEXT – pode conter grandes quantidades de texto. Dependendo do tipo de base de dados, isto pode somar até gigabytes.
Números:
- INT – contém um número inteiro positivo ou negativo. Muitas bases de dados têm variações da INT, tais como TINYINT, SMALLINT, MEDIUMINT, BIGINT, INT2, INT4, INT8. Estas variações diferem da INT apenas no tamanho da figura que lhe cabe. Uma INT regular é de 4 bytes (INT4) e cabe figuras de -2147483647 a +2147483646, ou se você defini-la como UNSIGNED de 0 a 4294967296. A INT8, ou BIGINT, pode ficar ainda maior em tamanho, de 0 a 18446744073709551616, mas ocupa até 8 bytes de espaço em disco, mesmo que haja apenas um pequeno número nela.
- FLOAT, DOUBLE – A mesma idéia da INT, mas também pode armazenar números de ponto flutuante. . Note que isto nem sempre funciona perfeitamente. Por exemplo, no MySQL calcular com estes números de ponto flutuante não é perfeito, (1/3)*3 resultará com as flutuações do MySQL em 0.9999999, não 1.
Outros tipos:
- BLOB – para dados binários como arquivos.
- INET – para endereços IP. Também pode ser usado para máscaras de rede.
Para nosso exemplo os tipos de dados são os seguintes:
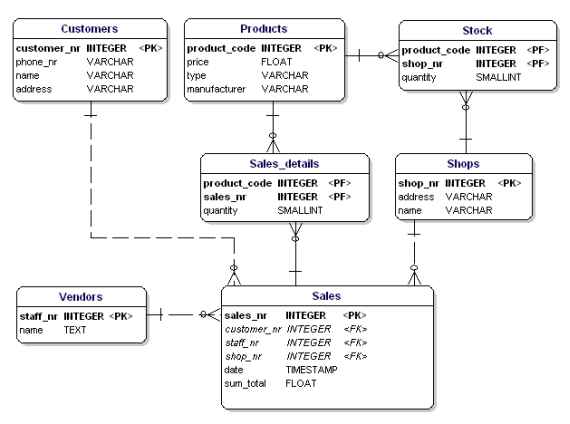
Figura 12: Modelo de dados exibindo os tipos de dados.
Normalização
Normalização torna o seu modelo de dados flexível e confiável. Ela gera alguma sobrecarga porque você normalmente recebe mais tabelas, mas permite que você faça muitas coisas com o seu modelo de dados sem ter que ajustá-lo. Você pode ler mais sobre normalização de banco de dados neste artigo.
Normalização, o Primeiro Formulário
A primeira forma de normalização afirma que pode não haver grupos de colunas repetidas em uma entidade. Poderíamos ter criado uma entidade ‘vendas’ com atributos para cada um dos produtos que foram comprados. Isto pareceria assim:

Figura 13: Não na 1ª forma normal.
O que há de errado nisto é que agora apenas 3 produtos podem ser vendidos. Se você tivesse que vender 4 produtos, então você teria que iniciar uma segunda venda ou ajustar seu modelo de dados adicionando atributos de ‘produto4’. Ambas as soluções são indesejadas. Nesses casos, você deve sempre criar uma nova entidade que você conecte com a antiga através de uma relação de um-para-muitos.
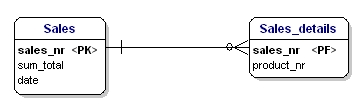
Figura 14: De acordo com a 1ª forma normal.
Normalização, a Segunda forma
A segunda forma de normalização indica que todos os atributos de uma entidade devem ser totalmente dependentes da chave primária inteira. Isto significa que cada atributo de uma entidade só pode ser identificado através de toda a chave primária. Suponha que tivéssemos a data na entidade Sales_details:

Figura 15: Não na 2ª forma normal.
Esta entidade não está de acordo com a segunda forma de normalização, pois para poder consultar a data de uma venda, não preciso saber o que é vendido (produto), a única coisa que preciso saber é o número de venda. Isto foi resolvido através da divisão das tabelas na tabela de vendas e na tabela de detalhes de Vendas_detail:
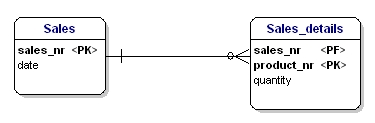
Figura 16: De acordo com a 2ª forma normal.
Agora cada atributo das entidades é dependente do PK inteiro da entidade. A data depende do número de vendas, e a quantidade depende do número de vendas e do produto vendido.
Normalização, o terceiro formulário
O terceiro formulário de normalização indica que todos os atributos precisam ser diretamente dependentes da chave primária, e não de outros atributos. Isto parece ser o que a segunda forma de normalização afirma, mas na segunda forma é na verdade o oposto. Na segunda forma de normalização você aponta atributos através do PK, na terceira forma de normalização todo atributo precisa ser dependente do PK, e nada mais.

Figura 17: Não na terceira forma normal.
Neste caso o preço de um produto solto depende do número do pedido, e o número do pedido depende do número do produto e do número de venda. Isto não está de acordo com a terceira forma de normalização. Mais uma vez, a divisão das tabelas resolve isto.
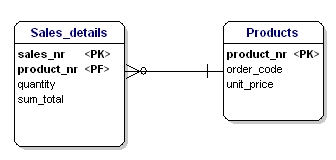
Figura 18: De acordo com a 3ª forma de normalização.
Normalização, Mais Formulários
Existem mais formas de normalização do que as três formas acima mencionadas, mas estas não são de grande interesse para o utilizador médio. Estes outros formulários são altamente especializados para determinadas aplicações. Se você se ater às regras de design e à normalização mencionada neste artigo, você criará um design que funciona muito bem para a maioria das aplicações.
Normalized Data Model
Se você aplicar as regras de normalização, você verá que o ‘fabricante’ na tabela de produtos também deve ser uma tabela separada:
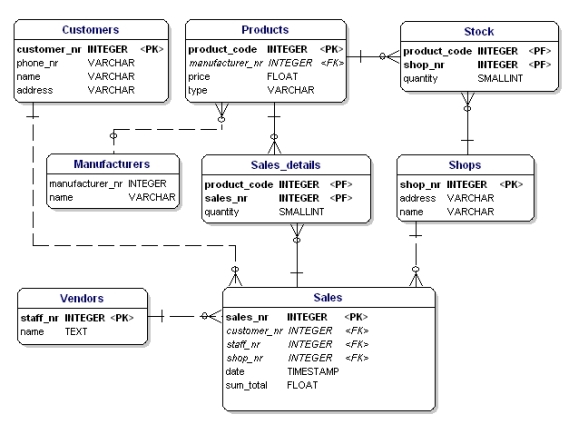
Figura 19: Modelo de dados de acordo com a 1ª, 2ª e 3ª forma normal.