




Quão bons são os pesquisadores de opinião pública? Analisando o conjunto de dados de Cinco- Trinta e Oito
Analisamos o conjunto de dados do venerável site de previsão política Cinco- Trinta e Oito.

Este é um Ano Eleitoral e o cenário de votação em torno das eleições (tanto Presidencial Geral como Casa/Senado) está aquecendo. Isso vai se tornar cada vez mais emocionante nos próximos dias, com tweets, contra-tweets, brigas nas mídias sociais e uma infinidade de punditries na televisão.
Sabemos que nem todas as enquetes são da mesma qualidade. Então, como fazer sentido de tudo isso? Como identificar sondagens de confiança usando dados e análises?

No mundo da análise preditiva política (e alguns outros assuntos como esportes, fenômenos sociais, economia, etc.), Five-Thirty-Eight é um nome formidável.
Desde o início de 2008, o site tem publicado artigos – tipicamente criando ou analisando informações estatísticas – sobre uma grande variedade de tópicos da política atual e notícias políticas. O site, dirigido pelo cientista de dados rockstar e estatístico Nate Silver, alcançou particular destaque e fama generalizada em torno da eleição presidencial de 2012, quando seu modelo previu corretamente o vencedor de todos os 50 estados e o Distrito de Columbia.
E antes de zombar e dizer “Mas e a eleição de 2016?”, você pode ser bem aconselhado a ler este artigo sobre como a eleição de Donald Trump foi dentro da margem de erro normal da modelagem estatística.
Para os leitores mais politicamente curiosos, eles têm um saco inteiro de artigos sobre a eleição de 2016 aqui.
Os profissionais da ciência dos dados deveriam gostar de Cinco- Trinta e Oito porque não se esquiva de explicar seus modelos de previsão em termos altamente técnicos (pelo menos complexos o suficiente para os leigos).

Aqui, eles estão falando em adotar a famosa distribuição t, enquanto a maioria dos outros agregadores de pesquisa pode estar apenas feliz com a distribuição Normal onipresente.
No entanto, indo além do uso de técnicas sofisticadas de modelagem estatística, a equipe sob Silver se orgulha de uma metodologia única – a classificação dos pesquisadores – para ajudar seus modelos a permanecerem altamente precisos e confiáveis.
Neste artigo, analisamos os seus dados sobre estes métodos de classificação.
Cinco-trinta e oito não se esquiva de explicar os seus modelos de previsão em termos altamente técnicos (pelo menos suficientemente complexos para o leigo).
Pollster rating e ranking
Existe uma multidão de sondadores a operar neste país. Ler e medir a qualidade deles pode ser altamente tributário e fraccionário. De acordo com o site, “As sondagens de leitura podem ser perigosas para a sua saúde. Os sintomas incluem a apanha da cereja, o excesso de confiança, a queda por números de junky e a precipitação para o julgamento. Felizmente, nós temos uma cura.” (fonte)
Existem sondagens. Depois, há sondagens de sondagem. Depois, há sondagens ponderadas. Acima de tudo, há uma sondagem com pesos que são modelados estatisticamente e mudam os pesos dinamicamente.
Sons familiares a outra famosa metodologia de ranking que você já ouviu falar como cientista de dados? O ranking de produtos da Amazon ou o ranking de filmes da Netflix? Provavelmente, sim.
Essencialmente, Cinco- Trinta e oito usa este sistema de classificação/classificação para ponderar os resultados das sondagens (os resultados das sondagens altamente classificadas são dados maior importância e assim por diante). Eles também rastreiam ativamente a precisão e as metodologias por trás do resultado de cada pesquisador e ajustam sua classificação ao longo do ano.
Existem pesquisas. Depois, há sondagens de opinião pública. Depois, há sondagens ponderadas. Acima de tudo, há uma sondagem com pesos que são modelados estatisticamente e mudam os pesos dinamicamente.
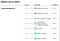
É interessante notar que a sua metodologia de classificação não classifica necessariamente uma sondagem com um tamanho de amostra maior como uma melhor. A seguinte captura de tela do site deles demonstra isso claramente. Enquanto os pesquisadores como Rasmussen Reports e HarrisX têm amostras maiores, é, de fato, o Marist College, que recebe a classificação A+ com um tamanho de amostra modesto.
Felizmente, eles também abrem a fonte dos seus dados de ranking (juntamente com quase todos os seus outros conjuntos de dados) aqui no Github. E se você só está interessado em uma tabela bonita, aqui está ela.
Naturalmente, como um cientista de dados, você pode querer olhar mais profundamente para os dados brutos e entender coisas como,
- como a classificação numérica deles se correlaciona com a exatidão dos pesquisadores
- se eles têm uma tendência partidária para selecionar determinados pesquisadores (na maioria dos casos, eles podem ser categorizados como de limpeza democrática ou republicana)
- quem são os pesquisadores mais bem classificados? Eles realizam muitas pesquisas ou são seletivos?
Tentamos analisar o conjunto de dados para adquirir tais conhecimentos. Vamos escavar o código e os resultados, devemos?
A análise
Pode encontrar o caderno Jupyter aqui na minha repo Github.
A fonte
Para começar, você pode puxar os dados diretamente do seu Github, para uma DataFrame Pandas, como segue,

Existem 23 colunas neste conjunto de dados. Aqui está como elas são,

>
>
Soma transformação e limpeza
Notemos que uma coluna tem algum espaço extra. Alguns outros podem precisar de alguma extracção e conversão do tipo de dados.



Após a aplicação desta extracção, o novo DataFrame tem colunas adicionais, o que o torna mais adequado para filtragem e modelagem estatística.

Examinar e quantificar a coluna “538 Grades”
As colunas “538 Grades” contêm o núcleo do conjunto de dados – a letra grade para a sondagem. Tal como um exame regular, A+ é melhor que A, e A é melhor que B+. Se plotarmos as contagens das notas das letras, observamos 15 gradações, no total, de A+ a F.

Em vez de trabalharmos com tantas gradações categóricas, podemos querer combiná-las em um pequeno número de notas numéricas – 4 para A+/A/A-, 3 para os B’s, etc.

Boxplots
Antra a análise visual, podemos começar com boxplots.
Suponhamos que queremos verificar qual o método de sondagem que tem melhor desempenho em termos de erro de previsão. O conjunto de dados tem uma coluna chamada “Simple Average Error”, que é definida como “O erro médio da empresa, calculado como a diferença entre o resultado da sondagem e o resultado real da margem que separa os dois primeiros colocados na corrida”.”

Então, podemos estar interessados em verificar se os inquiridores com um certo preconceito partidário são mais bem sucedidos na convocação correcta das eleições do que outros.
Nota algo interessante acima? Se você é um pensador progressista e liberal, com toda a probabilidade, você pode ser partidário do partido Democrata. Mas, na média, os pesquisadores de opinião com limpeza republicana, chamam as eleições de forma mais precisa e com menos variabilidade. É melhor ter cuidado com essas pesquisas!
Outra coluna interessante no conjunto de dados se chama “NCPP/AAPOR/Roper”. Ela “indica se a firma de pesquisa foi membro do Conselho Nacional de Pesquisas Públicas, signatária da iniciativa de transparência da Associação Americana para Pesquisa de Opinião Pública ou contribuinte do arquivo de dados do Roper Center for Public Opinion Research”. Efetivamente, uma filiação indica adesão a uma metodologia de votação mais robusta” (fonte).
Como julgar a validade da afirmação acima mencionada? O conjunto de dados tem uma coluna chamada “Advanced Plus-Minus”, que é “uma pontuação que compara o resultado de uma sondagem com outras empresas de sondagem que pesquisam as mesmas raças e que pesa mais os resultados recentes”. As pontuações negativas são favoráveis e indicam uma qualidade acima da média” (fonte).
Aqui está um boxplot entre estes dois parâmetros. Não só os pesquisadores, associados com NCCP/AAPOR/Roper, exibem uma pontuação de erro mais baixa, mas também apresentam uma variabilidade consideravelmente baixa. Suas previsões parecem ser estáveis e robustas.

Se você é um pensador progressista e liberal, com toda a probabilidade, você pode ser partidário do partido Democrata. Mas, na média, os pesquisadores de opinião com viés de limpeza republicano, chamam as eleições de forma mais precisa e com menor variabilidade.
Gráficos de dispersão e regressão
Para entender a correlação entre os parâmetros, podemos olhar para os gráficos de dispersão com ajuste de regressão. Usamos as bibliotecas Seaborn e Scipy Python e uma função personalizada para gerar esses gráficos.
Por exemplo, podemos relacionar as “Raças Chamadas Corretamente” com as “Predictive Plus-Minus”. Como em Five-Thirty-Eight, “Predictive Plus-Minus” é “uma projeção de quão exato será o eleitor nas futuras eleições”. É calculado revertendo a pontuação avançada Plus-Minus de um inquiridor para uma média baseada nos nossos procuradores para qualidade metodológica”. (fonte)

Or, podemos verificar como o “Grau Numérico” que definimos, correlaciona com a média de erros de sondagem. Uma tendência negativa indica que um maior grau numérico está associado a um menor erro de sondagem.

Podemos também verificar se o “# de Sondagens para Análise de Polarização” ajuda a reduzir o “Grau de Polarização Partidária” que é atribuído a cada sondagem. Podemos observar uma relação descendente, indicando que a disponibilidade de um elevado número de sondagens ajuda a reduzir o grau de enviesamento partidário. No entanto, a relação parece altamente não linear e uma escala logarítmica teria sido melhor para ajustar a curva.

É mais confiável para os pesquisadores? Traçamos o histograma do número de sondagens e vemos que segue uma lei de poder negativa. Podemos filtrar os pesquisadores com números muito baixos e muito altos de pesquisas e criar um gráfico de dispersão personalizado. No entanto, observamos uma correlação quase inexistente entre o número de sondagens e a pontuação do Predictive Plus-Minus. Portanto, um grande número de sondagens não conduz necessariamente a uma elevada qualidade de sondagem e poder preditivo.