




Învățați Regex: A Beginner's Guide
În acest ghid, veți învăța regex, sau sintaxa expresiilor regulate. Până la final, veți fi capabil să aplicați soluții regex în majoritatea scenariilor care o solicită în activitatea dumneavoastră de dezvoltare web.
Expresiile regulate au multe cazuri de utilizare, care includ:
- validarea intrărilor în formulare
- raping web
- cercetare și înlocuire
- filtrare pentru informații în fișiere text masive, cum ar fi jurnalele
Expresiile regulate, sau regex, așa cum sunt numite în mod obișnuit, par complicate și intimidante pentru noii utilizatori. Uitați-vă la acest exemplu:
/^+@+(?:\.+)*$/Apare doar ca un text confuz. Dar nu disperați, există o metodă în spatele acestei nebunii.

Credit: xkcd
Vă voi arăta cum să stăpâniți expresiile regulate în cel mai scurt timp. Mai întâi, să clarificăm terminologia folosită în acest ghid:
- model: model de expresie regulată
- șir: șir de testare folosit pentru a se potrivi cu modelul
- cifră: 0-9
- literă: a-z, A-Z
- simbol: !$%^&*()_+|~-=`{}:”;'<>?,./
- spațiu: un singur spațiu alb, tabulație
- caracter: se referă la o literă, cifră sau simbol
Bazele
Pentru a învăța rapid regex cu ajutorul acestui ghid, vizitați Regex101, unde puteți construi tipare regex și le puteți testa în raport cu șiruri (text) pe care le furnizați.
Când deschideți site-ul, va trebui să selectați aroma JavaScript, deoarece aceasta este cea pe care o vom folosi pentru acest ghid. (Sintaxa Regex este în mare parte aceeași pentru toate limbile, dar există câteva diferențe minore.)
În continuare, trebuie să dezactivați stegulețele global și multi line din Regex101. Le vom aborda în secțiunea următoare. Pentru moment, ne vom uita la cea mai simplă formă de expresie regulată pe care o putem construi. Introduceți următoarele:
- câmpul de intrare regex: cat
- șirul de test: rat bat cat sat fat cats eat tat cat mat CAT
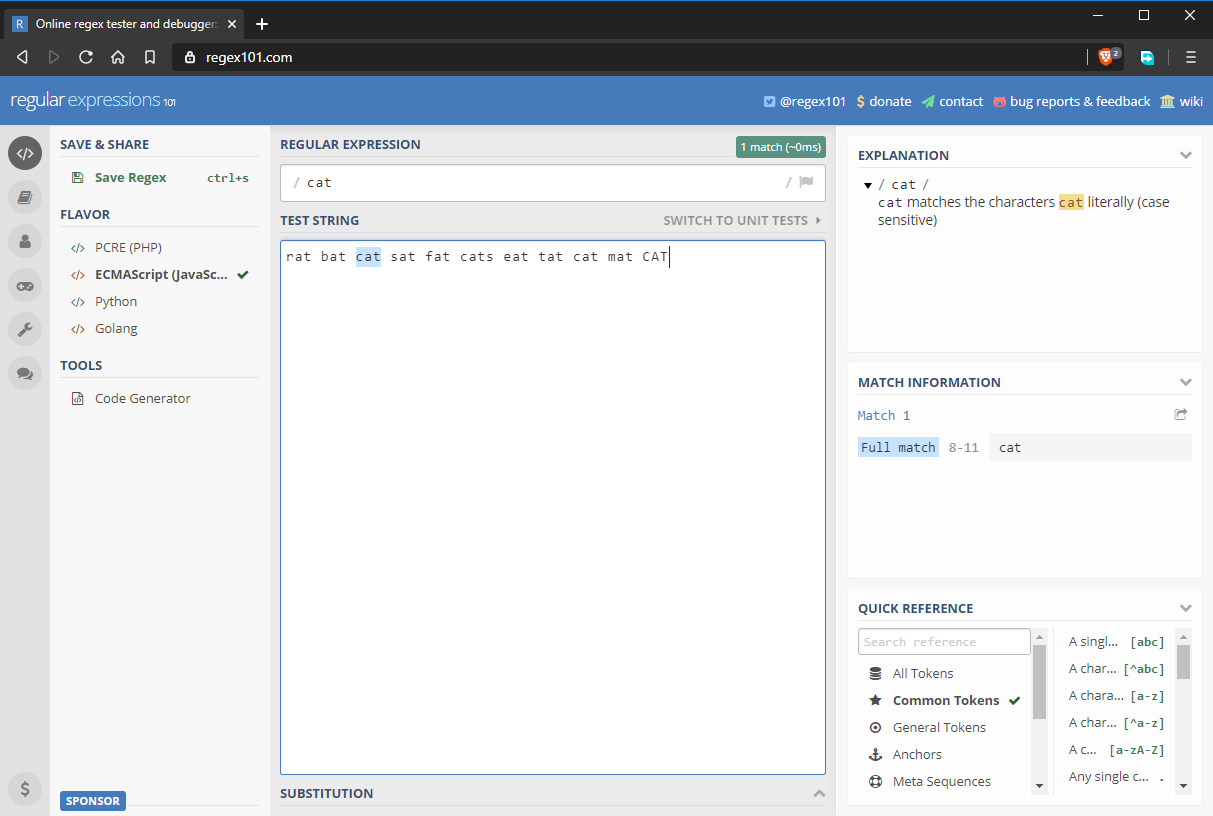
Rețineți că expresiile regulate în JavaScript încep și se termină cu /. Dacă ar fi să scrieți o expresie regulată în codul JavaScript, aceasta ar arăta astfel: /cat/ fără ghilimele. În starea de mai sus, expresia regulată se potrivește cu șirul „cat”. Cu toate acestea, după cum puteți vedea în imaginea de mai sus, există mai multe șiruri „cat” care nu se potrivesc. În secțiunea următoare, vom vedea de ce.
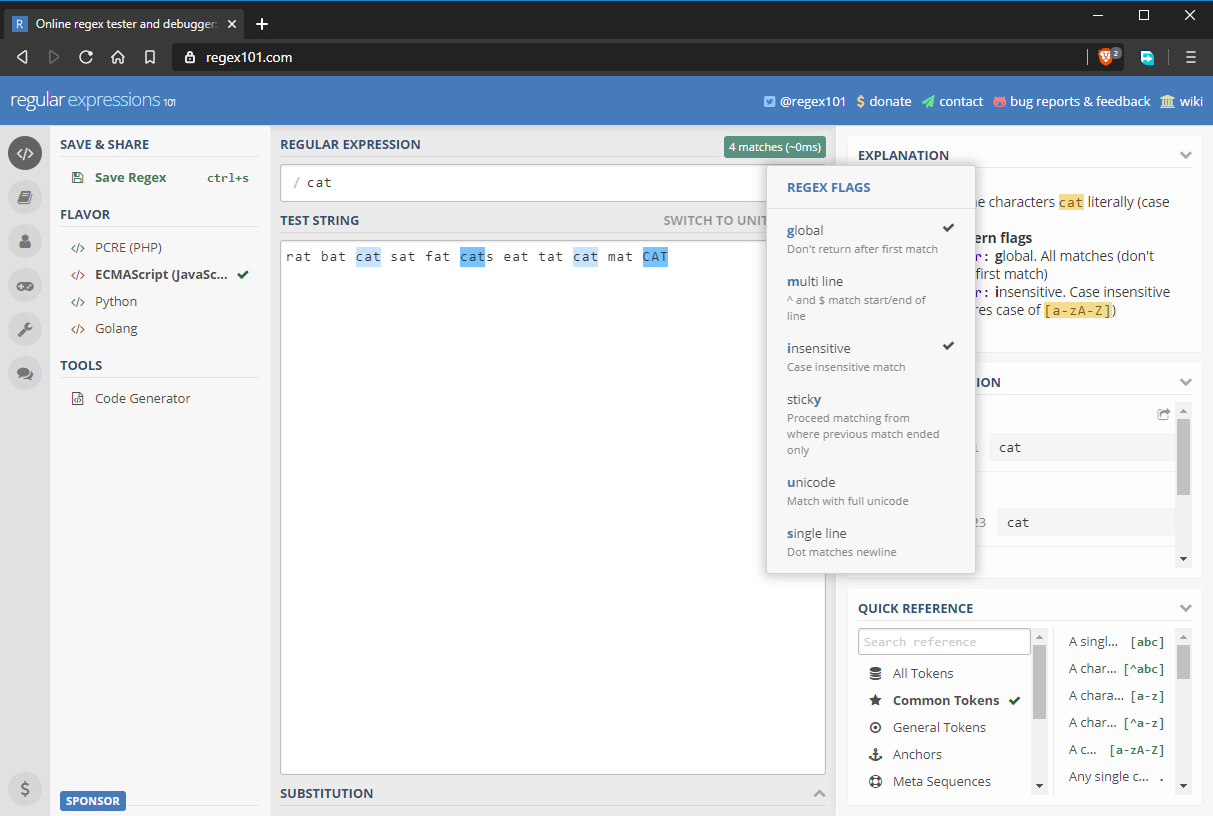
Flags Regex globale și insensibile la majuscule și minuscule
În mod implicit, un model regex va returna doar prima potrivire pe care o găsește. Dacă doriți să returnați potriviri suplimentare, trebuie să activați indicatorul global, notat cu g. Modelele regex sunt, de asemenea, sensibile la majuscule și minuscule în mod implicit. Puteți anula acest comportament prin activarea indicatorului insensibil, notat cu i. Modelul regex actualizat este acum exprimat complet ca /cat/gi. După cum puteți vedea mai jos, toate șirurile de caractere „cat” au fost potrivite, inclusiv cea cu majuscule și minuscule diferite.
Seturi de caractere
În exemplul anterior, am învățat cum să efectuăm potriviri exacte în funcție de majuscule și minuscule. Ce s-ar întâmpla dacă am dori să potrivim „bat”, „cat” și „fat”. Putem face acest lucru utilizând seturi de caractere, notate cu . Practic, introduceți mai multe caractere pe care doriți să le potriviți. De exemplu, at se va potrivi cu mai multe șiruri de caractere după cum urmează:
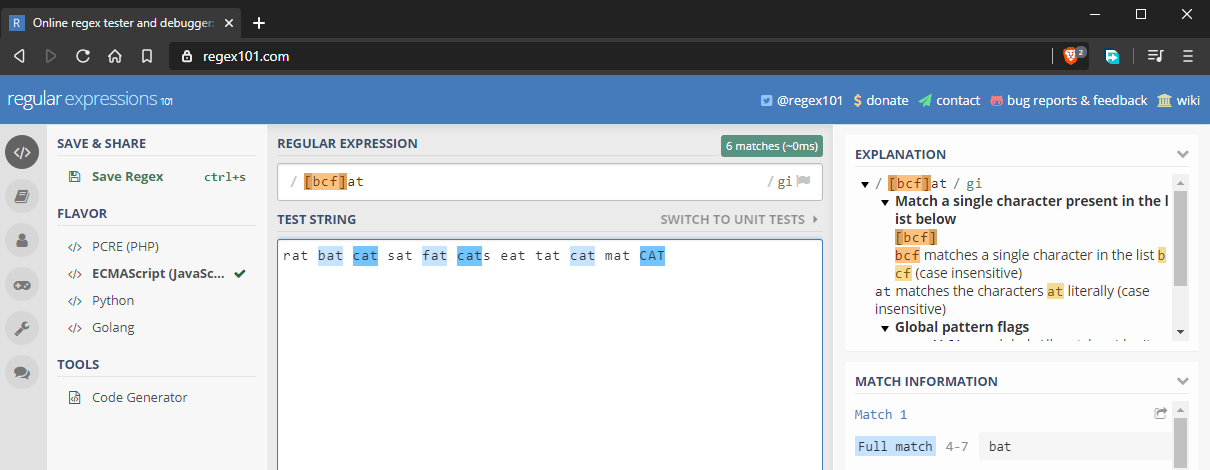
Seturile de caractere funcționează și cu cifre.
Range
Să presupunem că vrem să potrivim toate cuvintele care se termină cu at. Am putea furniza întregul alfabet în interiorul setului de caractere, dar acest lucru ar fi plictisitor. Soluția este să folosim intervale de genul acesta at:
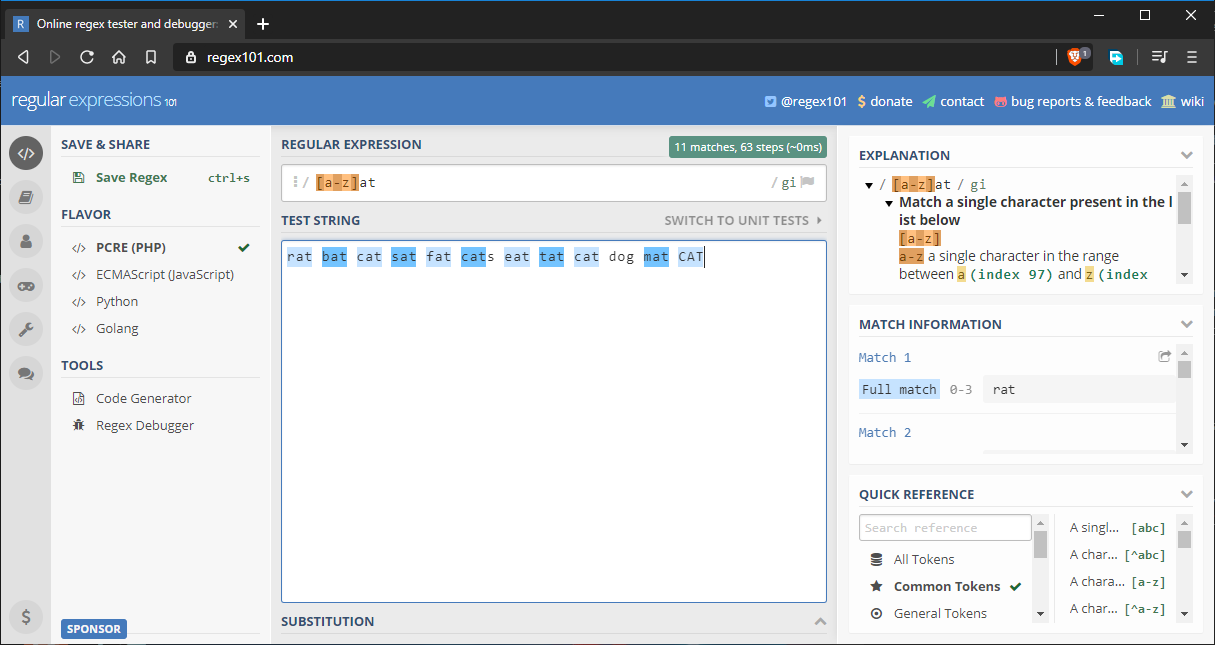
Iată șirul complet care este testat: rat bat cat sat fat cats eat tat cat dog mat CAT.
După cum puteți vedea, toate cuvintele se potrivesc așa cum era de așteptat. Am adăugat cuvântul dog doar pentru a adăuga o potrivire invalidă. Iată și alte moduri în care puteți folosi intervale:
-
Intervalul parțial: selecții cum ar fi
sau. -
Intervalul cu majuscule:
. -
Intervalul de cifre:
. -
Faza de simboluri: de exemplu,
. -
Faza mixtă: de exemplu,
include toate cifrele, literele mici și majuscule. Rețineți că un interval specifică doar mai multe alternative pentru un singur caracter dintr-un model.Pentru a înțelege mai bine cum se definește un interval, cel mai bine este să vă uitați la tabelul ASCII complet pentru a vedea cum sunt ordonate caracterele.

Caractere care se repetă
Să spunem că doriți să potriviți toate cuvintele de trei litere. Probabil că ați proceda astfel:
Aceasta ar corespunde tuturor cuvintelor din trei litere. Dar ce se întâmplă dacă doriți să potriviți un cuvânt de cinci sau opt caractere. Metoda de mai sus este anevoioasă. Există o modalitate mai bună de a exprima un astfel de tipar folosind notația {} cu paranteze curbe {}. Tot ce trebuie să faceți este să specificați numărul de caractere care se repetă. Iată câteva exemple:
-
a{5}se va potrivi cu „aaaaa”. -
n{3}se va potrivi cu „nnn”. -
{4}se va potrivi cu orice cuvânt din patru litere, cum ar fi „ușă”, „cameră” sau „carte”. -
{6,}se va potrivi cu orice cuvânt cu șase sau mai multe litere. -
{8,11}se va potrivi cu orice cuvânt între opt și 11 litere. Validarea de bază a parolei se poate face în acest fel. -
{11}se va potrivi cu un număr de 11 cifre. Validarea de bază a telefoanelor internaționale se poate face în acest fel.
Metacaracterele
Metacaracterele vă permit să scrieți modele de expresii regulate care sunt și mai compacte. Să le trecem în revistă unul câte unul:
-
\dse potrivește cu orice cifră care este identică cu -
\wse potrivește cu orice literă, cifră și caracter de subliniere -
\sse potrivește cu un caracter de spațiu alb – adică, un spațiu sau o tabulație -
\tse potrivește numai cu un caracter de tabulație
Din ceea ce am învățat până acum, putem scrie expresii regulate ca acestea:
-
\w{5}se potrivește cu orice cuvânt din cinci litere sau cu un număr din cinci cifre -
\d{11}se potrivește cu un număr din 11 cifre, cum ar fi un număr de telefon
Caractere speciale
Caracterele speciale ne duc cu un pas mai departe în scrierea unor expresii de tipare mai avansate:
-
+: Unul sau mai mulți cuantificatori (caracterul precedent trebuie să existe și poate fi duplicat opțional). De exemplu, expresiac+atse va potrivi cu „cat”, „ccat” și „ccccccccccat”. Puteți repeta caracterul precedent de câte ori doriți și tot veți obține o potrivire. -
?: Zero sau un cuantificator (caracterul precedent este opțional). De exemplu, expresiac?atse va potrivi numai cu „cat” sau „at”. -
*: Zero sau mai mulți cuantificatori (caracterul anterior este opțional și poate fi duplicat în mod opțional). De exemplu, expresiac*atse va potrivi cu „at”, „cat” și „ccccccat”. Este ca și combinația dintre+și?. -
\: acest „caracter de evadare” este utilizat atunci când dorim să folosim un caracter special la propriu. De exemplu,c\*se va potrivi exact cu „c*” și nu cu „ccccccccc”. -
: această notație de „negație” este utilizată pentru a indica un caracter care nu trebuie să se potrivească în cadrul unui interval. De exemplu, expresiabldnu se va potrivi cu „bald” sau „bbld” deoarece a doua literă de la a la c este negativă. Cu toate acestea, modelul se va potrivi cu „beld”, „bild”, „bold” și așa mai departe. -
.: această notație „do” se va potrivi cu orice cifră, literă sau simbol, cu excepția liniei noi. De exemplu,.{8}se va potrivi cu o parolă de opt caractere formată din litere, cifre și simboluri. de exemplu, „password” și „P@ssw0rd” se vor potrivi amândouă.
Din ceea ce am învățat până acum, putem crea o varietate interesantă de expresii regulate compacte, dar puternice. De exemplu:
-
.+se potrivește cu unul sau cu un număr nelimitat de caractere. De exemplu, „c” , „cc” și „bcd#.670” se vor potrivi toate. -
+se va potrivi cu toate cuvintele cu litere minuscule, indiferent de lungime, atâta timp cât acestea conțin cel puțin o literă. De exemplu, „book” și „boardroom” se vor potrivi amândouă.
Grupuri
Toate caracterele speciale pe care tocmai le-am menționat afectează doar un singur caracter sau un set de intervale. Dar dacă am dori ca efectul să se aplice unei secțiuni a expresiei? Putem face acest lucru prin crearea de grupuri folosind paranteze rotunde – (). De exemplu, modelul book(.com)? se va potrivi atât cu „book”, cât și cu „book.com”, deoarece am făcut partea „.com” opțională.
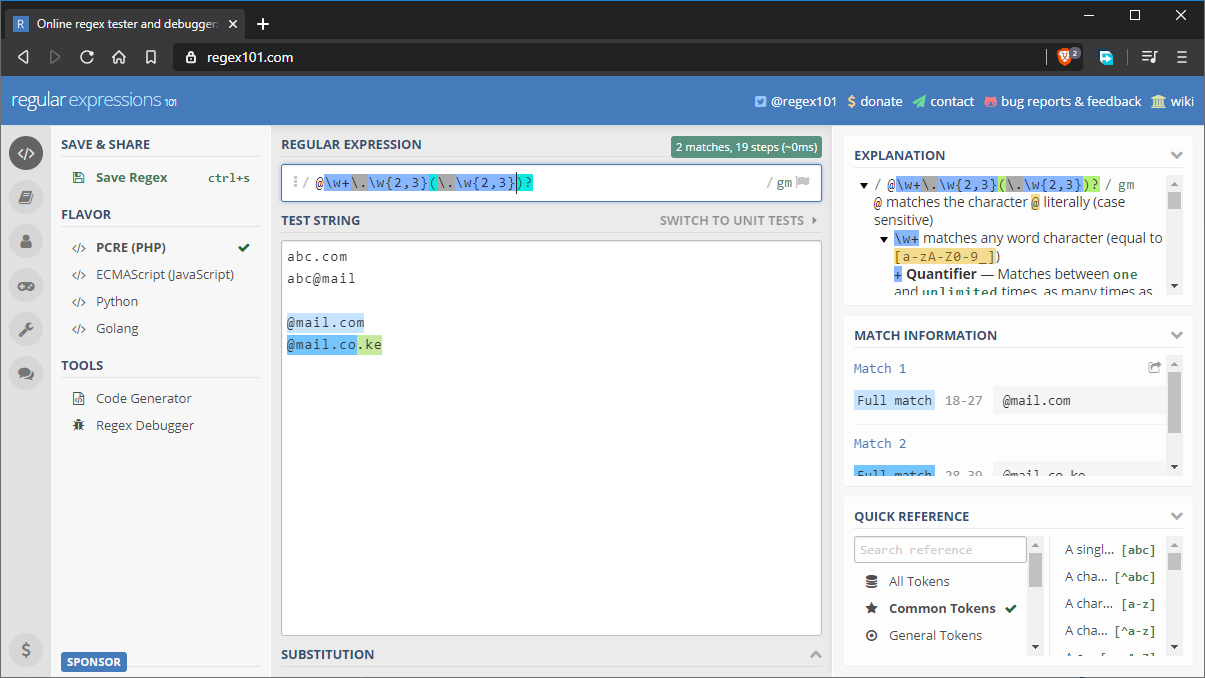
Iată un exemplu mai complex, care ar fi folosit într-un scenariu realist, cum ar fi validarea e-mailurilor:
- pattern:
@\w+\.\w{2,3}(\.\w{2,3})? - șir de test:
abc.com abc@mail @mail.com @mail.co.ke
Caractere alternative
În regex, putem specifica caractere alternative folosind simbolul „pipe” – |. Acesta este diferit de caracterele speciale pe care le-am arătat mai devreme, deoarece afectează toate caracterele de pe fiecare parte a simbolului „pipe”. De exemplu, modelul sat|sit se va potrivi atât cu șirurile „sat”, cât și cu „sit”. Putem rescrie modelul ca s(a|i)t pentru a se potrivi cu aceleași șiruri de caractere.
Planul de mai sus poate fi exprimat ca s(a|i)t prin utilizarea parantezelor ().
Planuri de început și de sfârșit
Ați observat probabil că unele potriviri pozitive sunt rezultatul unei potriviri parțiale. De exemplu, dacă am scris un model care să se potrivească cu șirul „boo”, șirul „book” va primi și el o potrivire pozitivă, în ciuda faptului că nu este o potrivire exactă. Pentru a remedia acest lucru, vom folosi următoarele notații:
-
^: plasat la început, acest caracter se potrivește cu un model la începutul șirului. -
$: plasat la sfârșit, acest caracter se potrivește cu un model la sfârșitul șirului.
Pentru a rezolva situația de mai sus, putem scrie modelul nostru ca boo$. Acest lucru va asigura că ultimele trei caractere se potrivesc cu modelul. Cu toate acestea, există o problemă pe care nu am luat-o încă în considerare, după cum arată imaginea următoare:
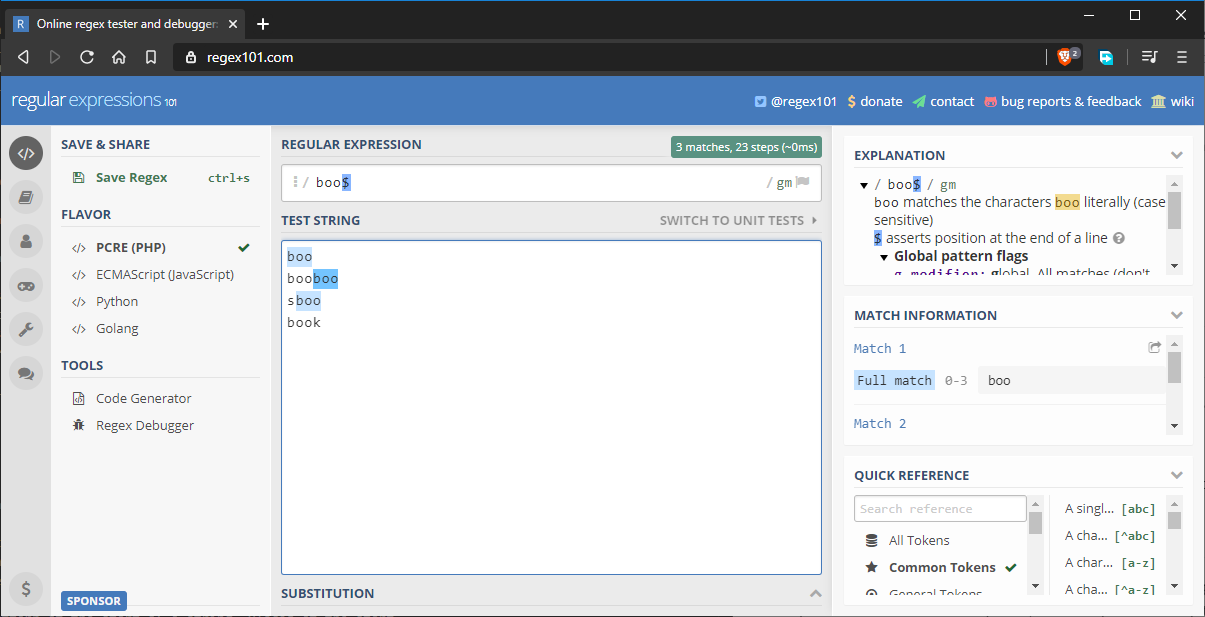
Șirul „sboo” primește o potrivire, deoarece încă îndeplinește cerințele actuale de potrivire a modelului. Pentru a remedia acest lucru, putem actualiza modelul după cum urmează: ^boo$. Acest lucru se va potrivi strict cu cuvântul „boo”. Dacă le folosiți pe amândouă, ambele reguli sunt puse în aplicare. De exemplu, ^{5}$ se potrivește strict cu un cuvânt din cinci litere. Dacă șirul are mai mult de cinci litere, tiparul nu se potrivește.
Regex în JavaScript
// Example 1const regex1=/a-z/ig//Example 2const regex2= new RegExp(//, 'ig')Dacă aveți Node.js instalat pe calculatorul dumneavoastră, deschideți un terminal și executați comanda node pentru a lansa interpretorul de shell Node.js. Apoi, executați după cum urmează:
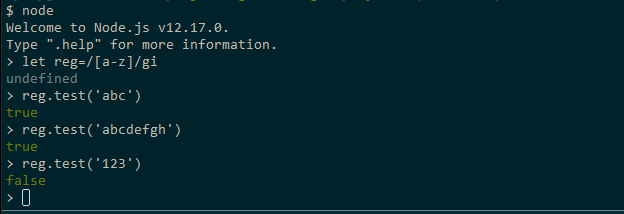
Simțiți-vă liber să vă jucați cu mai multe modele regex. Când ați terminat, utilizați comanda .exit pentru a ieși din shell.
Exemplu din lumea reală: Validarea e-mailurilor
Pentru a încheia acest ghid, să ne uităm la o utilizare populară a regex-ului, validarea e-mailurilor. (De exemplu, am putea dori să verificăm dacă o adresă de e-mail pe care un utilizator a introdus-o într-un formular este o adresă de e-mail validă.)
Acest subiect este mai complicat decât ați putea crede. Sintaxa adresei de e-mail este destul de simplă: {name}@{domain}. În teorie, o adresă de e-mail poate conține un număr limitat de simboluri, cum ar fi #-@&%. etc. Cu toate acestea, plasarea acestor simboluri contează. Serverele de poștă electronică au, de asemenea, reguli diferite privind utilizarea simbolurilor. De exemplu, unele servere tratează simbolul + ca fiind invalid. În alte servere de poștă electronică, simbolul este utilizat pentru subadresarea e-mailurilor.
Ca o provocare pentru a vă testa cunoștințele, încercați să construiți un model de expresie regulată care să se potrivească numai cu adresele de e-mail valide marcate mai jos:
# invalid emailabcabc.com# valid email [email protected]@[email protected]@[email protected]# invalid email [email protected]@[email protected]#[email protected]# valid email [email protected]@[email protected][email protected]# invalid domain [email protected]@mail#[email protected]@mail..com# valid domain [email protected]@[email protected]@[email protected]Rețineți că unele adrese de e-mail marcate ca fiind valide pot fi invalide pentru anumite organizații, în timp ce unele care sunt marcate ca fiind invalide pot fi de fapt permise în alte organizații. Oricum ar fi, este esențial să învățați să construiți expresii regulate personalizate pentru organizațiile pentru care lucrați, pentru a răspunde nevoilor acestora. În cazul în care vă împotmoliți, vă puteți uita la următoarele soluții posibile. Rețineți că niciuna dintre ele nu vă va oferi o potrivire de 100% pentru șirurile de test de e-mail valide de mai sus.
- Soluția posibilă 1:
^\w*(\-\w)?(\.\w*)?@\w*(-\w*)?\.\w{2,3}(\.\w{2,3})?$- Soluția posibilă 2:
^((\.,;:\s@"]+(\.\.,;:\s@"]+)*)|(".+"))@((\{1,3}\.{1,3}\.{1,3}\.{1,3}])|((+\.)+{2,}))$Summary
Sperăm că acum ați învățat elementele de bază ale expresiilor regulate. Nu am acoperit toate caracteristicile regex în acest ghid rapid pentru începători, dar ar trebui să aveți suficiente informații pentru a aborda majoritatea problemelor care necesită o soluție regex. Pentru a afla mai multe, citiți ghidul nostru privind cele mai bune practici pentru aplicarea practică a regex-ului în scenarii din lumea reală.
.