




Cât de buni sunt cei care fac sondajele? Analizând setul de date Five-Thirty-Eight
Analizăm setul de date privind clasamentul sondatorilor de pe venerabilul site de predicții politice Five-Thirty-Eight.

Acesta este un an electoral, iar scena sondajelor în jurul alegerilor (atât cele prezidențiale generale, cât și cele pentru Camera Deputaților/Senat) se încălzește. Aceasta va deveni din ce în ce mai palpitantă în zilele următoare, cu tweet-uri, contra-tweet-uri, lupte pe rețelele de socializare și o polemică nesfârșită la televizor.
Știm că nu toate sondajele sunt de aceeași calitate. Așadar, cum să dăm sens la toate acestea? Cum să identificăm institutele de sondare demne de încredere folosind date și analize?

În lumea analizei predictive politice (și a unor alte chestiuni precum sportul, fenomenele sociale, economia etc.), Five-Thirty-Eight este un nume formidabil.
De la începutul anului 2008, site-ul a publicat articole – de obicei creând sau analizând informații statistice – pe o mare varietate de subiecte din politica actuală și știri politice. Site-ul, condus de rockstarul om de știință de date și statistician Nate Silver, a atins o proeminență deosebită și o faimă larg răspândită în jurul alegerilor prezidențiale din 2012, când modelul său a prezis corect câștigătorul tuturor celor 50 de state și al Districtului Columbia.
Și înainte de a vă batjocori și a spune „Dar cum rămâne cu alegerile din 2016?”, ar fi bine să citiți acest articol despre cum alegerea lui Donald Trump s-a încadrat în marja de eroare normală a modelării statistice.
Pentru cititorii mai curioși din punct de vedere politic, au o pungă întreagă de articole despre alegerile din 2016 aici.
Practicienii din domeniul științei datelor ar trebui să simpatizeze cu Five-Thirty-Eight pentru că nu se feresc să explice modelele lor predictive în termeni foarte tehnici (cel puțin suficient de complecși pentru profani).

Aici, ei vorbesc despre adoptarea faimoasei distribuții t, în timp ce majoritatea celorlalți agregatori de sondaje s-ar putea să se mulțumească doar cu omniprezenta distribuție normală.
Cu toate acestea, mergând dincolo de utilizarea unor tehnici sofisticate de modelare statistică, echipa de sub conducerea lui Silver se mândrește cu o metodologie unică – ratingul sondajelor – pentru a-și ajuta modelele să rămână foarte precise și de încredere.
În acest articol, analizăm datele lor cu privire la aceste metode de rating.
Five-Thirty-Eight nu se sfiește să explice modelele lor predictive în termeni foarte tehnici (cel puțin suficient de complecși pentru profani).
Pollster rating and ranking
Există o multitudine de institute de sondare care operează în această țară. Citirea și aprecierea calității acestora poate fi extrem de obositoare și fracționată. Conform site-ului, „Citirea sondajelor poate fi periculoasă pentru sănătate. Simptomele includ selecția de cireșe, excesul de încredere, căderea în mrejele unor cifre de doi lei și judecata pripită. Din fericire, avem un leac”. (sursa)
Există sondaje. Apoi, există sondaje de sondaje. Apoi, există sondaje ponderate ale sondajelor. Mai presus de toate, există un sondaj de sondaje cu ponderi modelate statistic și cu ponderi care se schimbă în mod dinamic.
Vă sună familiar cu alte metodologii celebre de clasificare despre care ați auzit în calitate de cercetător de date? Clasamentul produselor de la Amazon sau clasamentul filmelor de la Netflix? Probabil că da.
În esență, Five-Thirty-Eight folosește acest sistem de rating/clasare pentru a pondera rezultatele sondajelor (rezultatele sondajelor cu clasament ridicat primesc o importanță mai mare și așa mai departe). De asemenea, ei urmăresc în mod activ acuratețea și metodologiile din spatele rezultatului fiecărui sondaj și își ajustează clasamentul pe parcursul anului.
Există sondaje. Apoi, există sondaje de sondaje. Apoi, există sondaje ponderate ale sondajelor. Mai presus de toate, există un sondaj de sondaje cu ponderi care sunt modelate statistic și cu ponderi care se schimbă în mod dinamic.
Este interesant de observat că metodologia lor de clasificare nu clasifică neapărat un sondaj cu o dimensiune mai mare a eșantionului ca fiind unul mai bun. Următoarea captură de ecran de pe site-ul lor demonstrează clar acest lucru. În timp ce institute de sondare precum Rasmussen Reports și HarrisX au eșantioane de dimensiuni mai mari, este, de fapt, Marist College, care primește ratingul A+ cu o dimensiune modestă a eșantionului.
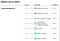
Din fericire, ei au, de asemenea, sursă deschisă a datelor lor de clasificare a sondajelor (împreună cu aproape toate celelalte seturi de date) aici, pe Github. Iar dacă sunteți interesați doar de un tabel arătos, iată-l aici.
Natural, ca om de știință de date, este posibil să doriți să vă uitați mai adânc în datele brute și să înțelegeți lucruri cum ar fi,
- cum se corelează clasamentul lor numeric cu acuratețea sondatorilor
- dacă au o prejudecată partizană în ceea ce privește selectarea anumitor sondatori (în cele mai multe cazuri, aceștia pot fi clasificați ca fiind fie cu înclinații democrate, fie cu înclinații republicane)
- cine sunt cei mai bine cotați sondatori? Realizează ei multe sondaje sau sunt selectivi?
Am încercat să analizăm setul de date pentru a dobândi astfel de informații. Să ne adâncim în cod și în constatări, da?
Analiza
Puteți găsi caietul Jupyter Notebook aici pe repo-ul meu Github.
Sursa
Pentru a începe, puteți extrage datele direct din Github-ul lor, într-un Pandas DataFrame, după cum urmează,

Există 23 de coloane în acest set de date. Iată cum arată acestea,

Câteva transformări și curățări
Observăm că o coloană are ceva spațiu în plus. Alte câteva ar putea avea nevoie de unele extrageri și conversii de tip de date.



După aplicarea acestei extrageri, noul DataFrame are coloane suplimentare, ceea ce îl face mai potrivit pentru filtrare și modelare statistică.

Examinarea și cuantificarea coloanei „538 Grade”
Colonelul „538 Grades” conține punctul nevralgic al setului de date – nota literară pentru sondaj. La fel ca la un examen obișnuit, A+ este mai bun decât A, iar A este mai bun decât B+. Dacă reprezentăm grafic numărătorile notelor literare, observăm 15 gradații, în total, de la A+ la F.

În loc să lucrăm cu atât de multe gradații categorice, am putea dori să le combinăm într-un număr mic de note numerice – 4 pentru A+/A/A-, 3 pentru B-uri, etc.

Boxplots
Plecând la analiza vizuală, putem începe cu boxplots.
Să presupunem că vrem să verificăm ce metodă de sondaj se comportă mai bine în ceea ce privește eroarea de predicție. Setul de date are o coloană numită „Eroare medie simplă”, care este definită ca fiind „Eroarea medie a firmei, calculată ca diferență între rezultatul sondat și rezultatul real pentru marja care separă primii doi clasați în cursă”.”

Atunci, am putea fi interesați să verificăm dacă sondajele de opinie cu o anumită prejudecată partizană au mai mult succes în a anunța corect alegerile decât altele.

Observați ceva interesant mai sus? Dacă sunteți un gânditor progresist, liberal, după toate probabilitățile, este posibil să fiți partizan al Partidului Democrat. Dar, în medie, sondajele cu înclinație republicană, anunță alegerile cu mai multă acuratețe și cu mai puțină variabilitate. Ar fi bine să aveți grijă la aceste sondaje!
O altă coloană interesantă din setul de date se numește „NCPP/AAPOR/Roper”. Aceasta „indică dacă firma de sondare a fost membră a Consiliului Național pentru Sondaje Publice, semnatară a inițiativei de transparență a Asociației Americane pentru Cercetarea Opiniei Publice sau contribuitor la arhiva de date a Centrului Roper pentru Cercetarea Opiniei Publice. Efectiv, o apartenență indică aderarea la o metodologie de sondaj mai robustă” (sursa).
Cum să judecăm validitatea afirmației menționate mai sus? Setul de date are o coloană numită „Advanced Plus-Minus”, care este „un scor care compară rezultatul unei firme de sondaje cu alte firme de sondaje care anchetează aceleași curse și care ponderează mai mult rezultatele recente. Scorurile negative sunt favorabile și indică o calitate peste medie” (sursa).
Iată un boxplot între acești doi parametri. Nu numai că firmele de sondaje, asociate cu NCCP/AAPOR/Roper, prezintă un scor de eroare mai mic, dar și o variabilitate considerabil de scăzută. Predicțiile lor par a fi constante și robuste.

Dacă sunteți un gânditor progresist, liberal, după toate probabilitățile, este posibil să fiți partizan al Partidului Democrat. Dar, în medie, sondajele de opinie cu înclinații republicane, anunță alegerile cu mai multă acuratețe și cu mai puțină variabilitate.
Ploci de dispersie și de regresie
Pentru a înțelege corelația dintre parametri, ne putem uita la diagramele de dispersie cu ajustare prin regresie. Folosim bibliotecile Seaborn și Scipy Python și o funcție personalizată pentru a genera aceste diagrame.
De exemplu, putem corela „Cursele apelate corect” cu „Plus-minus predictiv”. Conform Five-Thirty-Eight, „Predictive Plus-Minus” este „o proiecție a cât de precis va fi sondajul în alegerile viitoare. Acesta este calculat prin revenirea scorului Plus-Minus avansat al unui sondaj la o medie bazată pe indicatorii noștri de calitate metodologică”. (sursa)

Or, putem verifica modul în care „Nota numerică” pe care am definit-o, se corelează cu media erorilor din sondaje. O tendință negativă indică faptul că un grad numeric mai mare este asociat cu o eroare de sondaj mai mică.

De asemenea, putem verifica dacă „Numărul de sondaje pentru analiza de părtinire” ajută la reducerea „Gradului de părtinire partizană” care este atribuit fiecărui sondaj. Putem observa o relație descendentă, ceea ce indică faptul că disponibilitatea unui număr mare de sondaje ajută într-adevăr la reducerea gradului de părtinire partizană. Cu toate acestea, relația pare foarte neliniară și o scalare logaritmică ar fi fost mai bună pentru a se potrivi curbei.

Este posibil să se aibă mai multă încredere în sondajele mai active? Trasăm histograma numărului de sondaje și vedem că aceasta urmează o lege de putere negativă. Putem filtra sondatorii cu un număr foarte mic și foarte mare de sondaje și putem crea un grafic de dispersie personalizat. Cu toate acestea, observăm o corelație aproape inexistentă între numărul de sondaje și scorul Predictive Plus-Minus. Prin urmare, un număr mare de sondaje nu duce neapărat la o calitate ridicată a sondajelor și la o putere predictivă mare.
.