




SQL Magazine 7 artikel – SQL Server: Verfijn uw query’s met geïndexeerde views
Neem uw vraag op Markeer als voltooid Annoteer
Het doel van dit artikel is om het concept van SQL Server geïndexeerde views te introduceren en te laten zien hoe dit type view kan worden geïmplementeerd en gebruikt om query’s te optimaliseren.
View concept
Views zijn ook bekend als “virtuele tabellen”, omdat ze een alternatief bieden voor het gebruik van tabellen om toegang te krijgen tot gegevens. Een view is niets meer dan een SELECT verklaring ingekapseld in een object. De syntaxis voor het maken van een view is zoals weergegeven in Listing 1.
CREATE VIEW nome_da_visão ...) ] AS subconsulta;Zie een voorbeeld van het maken en gebruiken van een view in Listing 1.
Use NorthWind go create view vi_vendas_mes As Select ano = datepart(yyyy,OrderDate), mes = datepart(mm,OrderDate), qtde_total = sum(Quantity) from Orders o inner join od on o.OrderId = od.OrderId group by datepart(yyyy,o.OrderDate), datepart(mm,o.OrderDate) go select * from vi_vendas_mês go ano mes qtde_total contador ----------- ----------- ----------- -------------------- 1996 7 1462 59 1996 8 1322 69 1996 9 1124 57 1996 10 1738 73 1996 11 1735 66Van de voordelen van het gebruik van views kunnen we noemen :
- Vereenvoudiging van code: je kunt complexe SELECTs één keer schrijven, ze inkapselen in de view en ze van daaruit triggeren, alsof het een willekeurige tabel is;
- Veiligheidskwesties: stel dat je vertrouwelijke informatie in sommige tabellen hebt en dat je daarom wilt dat slechts enkele gebruikers toegang tot die tabellen hebben. Sommige kolommen in deze tabellen moeten echter voor alle gebruikers toegankelijk zijn. Een effectieve manier om dit probleem op te lossen is een view te maken en de gevoelige kolommen te verbergen. Op deze manier kan men de toegangsrechten tot de oorspronkelijke tabel opheffen en de toegang tot de view vrijgeven;
- Mogelijkheid van query-optimalisatie door geïndexeerde views te implementeren.
Geïndexeerde views in de praktijk
Views kapselen SELECT statements in, wat betekent dat telkens wanneer zij worden getriggerd, de bijbehorende SELECT statements worden uitgevoerd. Views maken geen bewaarplaatsen voor de gegevens die ze teruggeven (zoals de tabel dat doet). Welnu, het zou geweldig zijn als we het resultaat van de SELECT-opdracht die we in de view vinden, in een tabel zouden kunnen “materialiseren”, door indexen aan te maken om de toegang ertoe te vergemakkelijken. Nou, de geïndexeerde views doen precies dat. Het uitvoeren van een SELECT in een geïndexeerde view heeft hetzelfde effect als het uitvoeren van een select in een conventionele tabel.
Het belangrijkste doel van geïndexeerde views is het verhogen van de prestaties, en het voordeel van SQL Server is om uitvoeringsplannen toe te staan de geïndexeerde view te beschouwen als een middel om gegevens te benaderen, zelfs als de view naam niet expliciet in de query was. Dit is mogelijk in de Enterprise-editie van SQL Server 2000, waar de opdracht-optimalisator gegevens rechtstreeks in de geïndexeerde weergave kan selecteren (in plaats van de ruwe gegevens die in de tabel bestaan te selecteren), zoals we hierna zullen zien.
Stapsgewijs een geïndexeerde view maken
- De omgeving configureren, de eerste stap is het instellen van de status van enkele parameters in de sessie waar je de view wilt maken en gebruiken, want omdat de geïndexeerde view “gematerialiseerd” is in een tabel, kan niets het resultaat ervan verstoren. Stel u bijvoorbeeld het volgende scenario voor:
- Een bepaalde instelling, die van invloed is op het resultaat van een SELECT (b.v. concat_null_yelds_null), wordt ingesteld voordat de geïndexeerde weergave wordt gemaakt;
- De geïndexeerde weergave wordt gemaakt; merk op dat het resultaat van de weergave op schijf wordt “gematerialiseerd” volgens de instelling die in de vorige stap is ingesteld;
- Dan wordt de instelling uitgeschakeld en de geïndexeerde weergave door de gebruiker uitgevoerd. Aangezien de view gematerialiseerd is, zullen we een resultaat krijgen dat niet consistent is met de huidige configuratie.
In Listing 2 is bijvoorbeeld het verschil te zien in het resultaat van een commando wanneer de eigenschap concat_null_yields_null wordt gewijzigd.
set concat_null_yields_null ON print null + 'abc' -------------------------------------- Set concat_null_yields_null OFF print null + 'abc' -------------------------------------- abcStelt u zich eens voor wat er zou gebeuren als de geïndexeerde view was gemaakt met de eigenschap concat_null_yields_null ingeschakeld, maar in de huidige sessie was die eigenschap uitgeschakeld – dezelfde SELECT zou tot verschillende resultaten leiden!
Dit probleem is op een eenvoudige manier opgelost – om geïndexeerde views te maken en te gebruiken, is het verplicht om de omgeving te configureren volgens een lijst van standaard waarden. Op die manier is het onmogelijk om andere resultaten te krijgen, omdat de view eenvoudigweg niet zal werken als een van de instellingen is ingesteld op een waarde buiten de standaard.
Tabel 1 toont deze instellingen en hun respectievelijke standaardwaarden.
| Instelling | Id (*) | Verplichte status voor geïndexeerde weergaven | SQL Server 2000 standaard | Standaard bij OLE DB (=ADO) of ODBC-verbindingen | Standaard bij verbindingen die DB-bibliotheek gebruiken |
|---|---|---|---|---|---|
| ANSI_NULLS | 32 | ON | OFF | ON | OFF |
| ANSI_PADDING | 16 | ON | ON | ON | OFF |
| ANSI_WARNING | 8 | ON | OFF | ON | OFF |
| ARITHABORT | 64 | ON | OFF | OFF | UIT |
| CONCAT_NULL_YIELDS_NULL | 4096 | ON | OFF | ON | OFF |
| QUOTED_IDENTIFIER | 256 | ON | OFF | ON | OFF |
| NUMERIC_ROUNDABORT | 8192 | OFF | OFF | OFF | OFF |
(*) De id wordt gebruikt in het sp_configure commando. Om na te gaan wat elke instelling doet, lees de sectie “Vereiste instellingen voor geïndexeerde weergaven”. Er zijn twee manieren om de waarde van een configuratie te veranderen:
- Direct in de sessie: voer het commando set ON | OFF uit
- Veranderen van de bestaande standaard server: voer sp_Configure ‘user options’, . Het id-nummer van elke configuratie is te vinden in tabel 1.
Opmerking: AritHabort heeft id 64 en Quoted_Identifier heeft id 256. Om bijvoorbeeld Quoted_Identifier + AritHabort te koppelen, zouden we sp_cofigure uitvoeren, waarbij als parameter het resultaat van 64+256 (=320) wordt meegegeven: sp_configure ‘user options’, 320. Voor een volledige lijst van de ids die aan elke configuratie zijn toegewezen, gaat u naar http://msdn.microsoft.com/library/default.asp?url=/library/en-us/adminsql/ad_config_9b1q.asp.
Om de status van elk van de parameters in tabel 1 te bevestigen, gebruikt u de functie SessionProperty(‘parameter name’) of het commando DBCC UserOptions.
Zo stelt u alle parameters in volgens de kolom ‘vereiste status voor geïndexeerde weergaven’ in tabel 1 – als u dit niet doet, staat SQL Server niet toe dat u de geïndexeerde weergave maakt/uitvoert.
De geïndexeerde weergave maken
We zullen een weergave maken om het totaal van het dagelijks verkochte bedrag in de tabel Bestellingsdetails, die zich in de NorthWind-database bevindt. Zie Listing 3.
use NorthWind go create view vi_vendas_mes with SchemaBinding as select ano = datepart(yyyy,OrderDate), mes = datepart(mm,OrderDate), qtde_total = sum(Quantity), contador = count_big(*) from dbo.Orders o inner join dbo. od on o.OrderId = od.OrderId group by datepart(yyyy,o.OrderDate),datepart(mm,o.OrderDate) goWe moeten enkele bijzonderheden in acht nemen bij het maken van geïndexeerde views:
- De view dient deterministisch te zijn. Een view zal deterministisch zijn als we alleen deterministische functies in zijn code gebruiken. Hetzelfde SELECT-commando dat herhaaldelijk wordt uitgevoerd op een geïndexeerd overzicht (met een statische basis) kan geen verschillende resultaten opleveren. Deterministische functies zorgen ervoor dat het resultaat van een functie onveranderd blijft, ongeacht het aantal keren dat de functie wordt uitgevoerd. De functie DatePart, bijvoorbeeld, is deterministisch, aangezien zij altijd hetzelfde resultaat voor een specifieke datum teruggeeft. De functie getdate() geeft elke keer dat hij wordt uitgevoerd een andere waarde terug. Voor de volledige lijst van SQL Server 2000 deterministische functies, ga naar http://msdn.microsoft.com/library/default.asp?url=/library/en-us/createdb/cm_8_des_08_95v7.asp
- Controleer of er geen syntax beperkingen zijn. De hieronder vermelde clausules, functies en querytypes kunnen het schema van een geïndexeerde view niet integreren:
- MIN, MAX,TOP
- VARIANCE,STDEV,AVG
- COUNT(*)
- SUM op kolommen die null-waarden toelaten
- DISTINCT
- ROWSET-functie
- Derived tables, self joins, subqueries, outer joins
- DISTINCT
- UNION
- Float, text, ntext en image
- COMPUTE en COMPUTE BY
- HAVING, CUBE en ROLLUP
Het is nodig om de geïndexeerde views met SchemaBinding te maken. Om de inhoud van het overzicht consistent te houden, kunt u de structuur van de tabellen die aan het overzicht ten grondslag liggen niet wijzigen. Om dit soort problemen te voorkomen, is het verplicht om SchemaBinding te gebruiken bij het maken van geïndexeerde views, omdat deze optie niet toestaat dat je de tabelstructuur wijzigt zonder eerst de view te verwijderen.
Om de GROUP BY-clausule te gebruiken, is het verplicht om de COUNT_BIG(*) functie op te nemen. De count_big(*) functie doet hetzelfde als count(*), maar retourneert een waarde van het type bigint (8 bytes).
Informeer altijd de eigenaar van de objecten waarnaar verwezen wordt in de geïndexeerde view. Gebruik select * from dbo.Orders in plaats van select * from Orders, aangezien het mogelijk is om tabellen te hebben met dezelfde naam maar verschillende eigenaars. Aangezien de schemabinding optie verplicht is, heeft SQL Server de exacte object specificatie nodig om schema wijziging te beteugelen.
Creëren van een cluster index in de view (materialisatie)
De view gemaakt in punt 2 gedraagt zich nog niet als een geïndexeerde view, omdat het resultaat van het select commando nog niet gematerialiseerd is in een tabel. U kunt deze bewering bevestigen door het commando sp_spaceused uit te voeren in Query Analyzer, dat het aantal rijen en de door de tabellen gebruikte ruimte teruggeeft (Listing 4).
sp_SpaceUsed vi_vendas_mes -------------------------------------------------------------------------------------- Server: Msg 15235, Level 16, State 1, Procedure sp_spaceused, Line 91 Views do not have space allocated.Observeer in Listing 5 dat de verwerking van de view zuiver logisch is, zozeer zelfs dat de waarde van Physical Reads nul is. Let op de waarden die zijn geregistreerd in Logical Reads en Physical Reads (1672+0+4+0=1676) – we zullen deze waarden gebruiken in onze toekomstige vergelijkingen.
Set statistics io ON Select * from vi_vendas_mesgo---------------------------------------------------------ano mes qtde_total contador ----------- ----------- ------------- -------------------- 1996 7 1462 591996 8 1322 691996 9 1124 57.....(23 row(s) affected)Table 'Order Details'. Scan count 830, logical reads 1672, physical reads 0, read-ahead reads 0.Table 'Orders'. Scan count 1, logical reads 4, physical reads 0, read-ahead reads 0.Om te controleren of de view kan worden geïndexeerd (gematerialiseerd), dat wil zeggen, of deze is gemaakt binnen de normen en instellingen die vereist zijn voor geïndexeerde views, moet het resultaat van de volgende SELECT gelijk zijn aan 1.
select ObjectProperty(object_id('vi_vendas_mes'),'IsIndexable')Als we bevestigen dat aan de voorwaarden is voldaan, kunnen we nu de index maken. De syntaxis heeft hetzelfde formaat als bij het maken van indexen in conventionele tabellen:
create unique clustered index pk_ano_mes on vi_vendas_mes (ano,mes)Merk op dat de clusterindex nodig is omdat deze pagina’s met gegevens genereert. Je kunt niet-cluster indexen in geïndexeerde views pas maken nadat je de cluster index hebt gemaakt.
Nu de SELECT gevonden in de view is gematerialiseerd. wat kan worden bewezen met het sp_spaceused commando in Query Analyzer (Listing 6).
sp_SpaceUsed vi_vendas_mêsgo-----------------------------------------------------Name Rows Reserved data index_size Unusedvi_vendas_mes 23 24 KB 8 KB 16 KB 0 KBGebruik van geïndexeerde views
Een manier om toegang te krijgen tot een geïndexeerde view (evenals een conventionele view) is door naar de naam ervan te verwijzen in het SELECT commando:
select * from vi_vendas_mesVergelijk de hoeveelheid verplaatste pagina’s in lijst 5 (1672+4=1676) met die in lijst 7 (2+0=2). Het verschil is aanzienlijk – het creëren van de geïndexeerde view verminderde de totale benodigde I/O met 1674 pagina’s.
Set statistics io ON select * from vi_vendas_mes go --------------------------------------------------------- ano mes qtde_total contador ----------- ----------- ------------- -------------------- 1996 7 1462 59 1996 9 1124 57 ..... (23 row(s) affected) Table 'vi_vendas_mes'. Scan count 1, logical reads 2, physical reads 0, read-ahead reads 0.Laten we eens kijken naar een ander voorbeeld. Figuur 1 toont het uitvoeringsplan van een query. Bevestig dat het uitzicht werd geselecteerd, ook al was het niet aanwezig in de SELECT-rij.
Tijdens het opstellen van het uitvoeringsplan voor de query ontdekte de optimizer dat er al vooraf samengevatte gegevens voor de query in vi_sales_mes stonden en koos hij ervoor de gegevens rechtstreeks in de geïndexeerde weergave te selecteren.
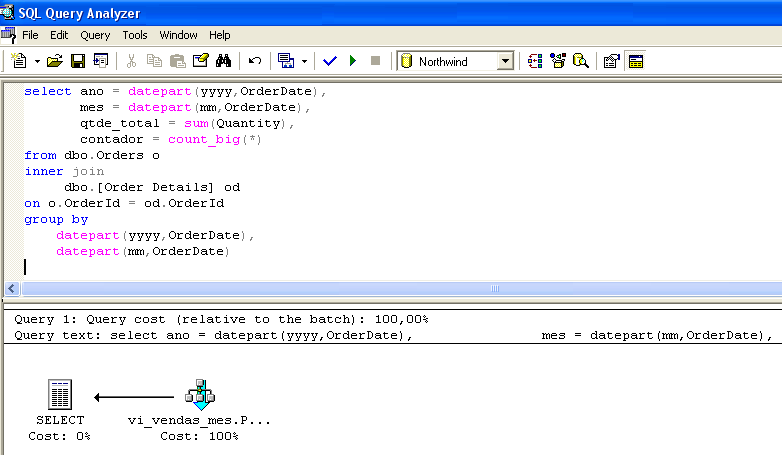
Merk op dat de query die in afbeelding 1 wordt uitgevoerd, identiek is aan de query die in de weergave vi_sales_mes wordt gevonden. De toegang tot de view door de optimizer is echter onafhankelijk van de gelijkenis tussen de uitgevoerde query en de view query. Bij de selectie van de geïndexeerde view door de queryprocessor wordt alleen rekening gehouden met de kosten/batenverhouding. Op deze manier hoeven de uitgevoerde queries niet identiek te zijn aan de view (zie figuur 3).
Het is echter noodzakelijk enkele regels te volgen opdat de geïndexeerde view door de query optimizer in aanmerking kan worden genomen:
- De in de view aanwezige join moet “vervat” zijn in de query: indien de query een join uitvoert tussen de tabellen A en B, en de view voert een join uit tussen A en C, dan zal de view niet in het uitvoeringsplan worden getriggerd. Als de query echter een join tussen A,B en C uitvoert, kan de view worden getriggerd.
- De in de query gestelde voorwaarden moeten overeenkomen met de voorwaarden in de view: in de SELECT in figuur 2 wordt de geïndexeerde view vi_sales_mes niet in aanmerking genomen omdat de where-clausule niet in de view-code aanwezig was, waardoor rijen met Quantity <= 5 in de join werden berekend.
Anderzijds, als de query de where conditie where sum(Quantity) > 5 heeft, zal de view vi_sales_mes in het uitvoeringsplan in aanmerking worden genomen, omdat de query conditie een subset is van de SELECT die in de view aanwezig is.
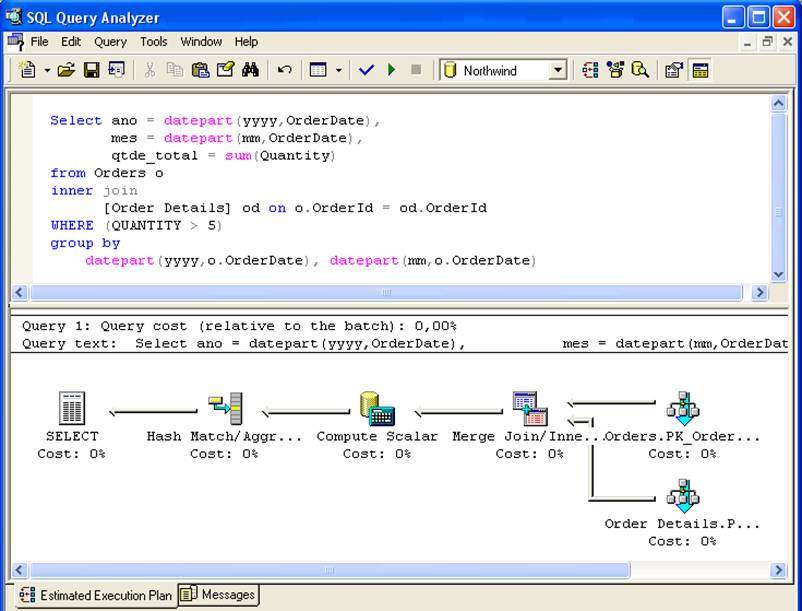
Kolommen met aggregatiefuncties in de query moeten “vervat” zijn in de view-definitie: indien de view de kolom qtde=sum(Quantity) retourneert en de query een kolom vlr_unit=sum(UnitPrice) heeft, zal de view niet in aanmerking worden genomen.
Figuur 3 toont een SELECT commando dat toelaat de intelligentie van de commando optimizer aan te tonen – de AVG(Quantity) berekening is vervangen door de deling tussen SUM(Quantity) / Count_Big(*), voorgesteld door het Compute Scalar icoon. Het predicaat where sum(Quantity) > 1500 (weergegeven door het Filter-pictogram) wordt ook overwogen.
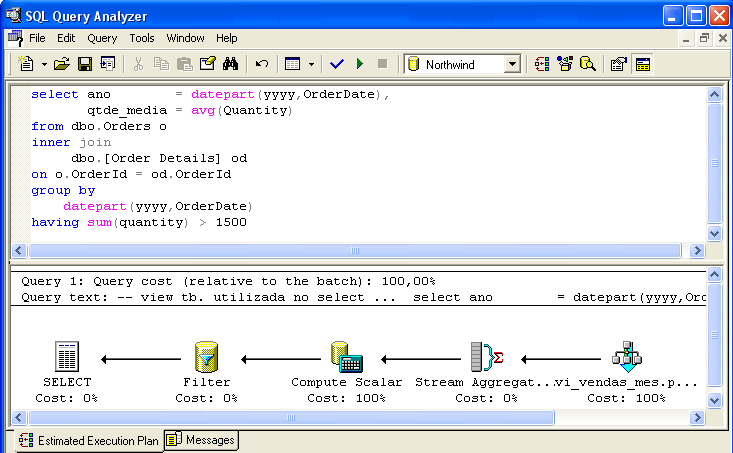
Algemene overwegingen over het gebruik van geïndexeerde weergaven:
- Geïndexeerde weergaven kunnen in elke versie van SQL Server 2000 worden gemaakt. Echter, alleen in de Enterprise Edition versie zullen ze automatisch worden geselecteerd door de query optimizer.
- In andere versies dan Enterprise, moet u de NoExpand hint gebruiken om de geïndexeerde view te benaderen als een conventionele tabel. Als NoExpand niet wordt gebruikt, zal het geïndexeerde overzicht als een “normaal” overzicht worden beschouwd.
Opmerking: De Expand hint doet het omgekeerde van NoExpand: het behandelt de geïndexeerde view als een “normale” view, waardoor SQL Server gedwongen wordt de SELECT statement uit te voeren tijdens de run-time fase.
- Het onderhoud van een geïndexeerde view is automatisch (zoals bij indexen); er is geen extra synchronisatie voor nodig. Door zijn eigen karakteristiek (het slaat gewoonlijk vooraf samengevatte gegevens op), neigt de update ervan ertoe iets langzamer te zijn dan die van conventionele indexen.
- Het gebruik van geïndexeerde views in OLTP-bases vereist voorzichtigheid, want hoewel zij goede prestaties leveren bij queries, veroorzaken zij overhead bij de processen die de in de view gerelateerde tabellen wijzigen. In situaties waar hoge schrijfprestaties vereist zijn, met frequente updates, wordt het maken van geïndexeerde views niet aanbevolen.
- Net als bij indexen, zal de optimizer de view code in Enterprise versies analyseren als onderdeel van het proces om het beste uitvoeringsplan voor een query te kiezen. Als er echter veel geïndexeerde views voor dezelfde query kunnen worden uitgevoerd, kan deze keuzetijd aanzienlijk toenemen omdat alle views zullen worden geanalyseerd. Gebruik daarom gezond verstand bij het implementeren van de weergaven.
Verplichte instellingen voor geïndexeerde weergaven
ANSI_NULLS
Definieert hoe vergelijkingen met null-waarden worden uitgevoerd (Listing 8).
set ANSI_NULLS ON declare @var char(10) set @var = null if @var = null print 'VERDADEIRO' else print 'FALSO' ------------------------------------- FALSO set ANSI_NULLS OFF declare @var char(10) set @var = null if @var = null print 'VERDADEIRO' else print 'FALSO' -------------------------------------- VERDADEIROANSI_PADDING
Bepaalt hoe char, varchar, binary, en varbinary kolommen moeten worden opgeslagen wanneer hun inhoud kleiner is dan de grootte die in de tabelstructuur is gedefinieerd. SQL Server 2000 is standaard om ansi_padding aan te houden (=ON); in deze conditie zijn de volgende regels van toepassing:
- Bij het updaten van char kolommen zal whitespace worden toegevoegd aan het eind van de string indien deze kleiner is dan de grootte zoals gedefinieerd in de kolom structuur. Dezelfde regel geldt voor binaire kolommen (in dat geval wordt de ruimte opgevuld door een reeks nullen)
- Varchar of varbinary kolommen volgen de bovenstaande regel niet: zij behouden altijd hun oorspronkelijke grootte.
ARITHABORT
Ingeschakeld, beëindigt uitvoering query na deling door nul of een overflow.
QUOTED_IDENTIFIER
Ingeschakeld, staat het gebruik van dubbele aanhalingstekens toe om namen van tabellen, kolommen enz. te specificeren. – Zo kunnen die namen spaties en of speciale tekens bevatten.
CONCAT_NULL_YELDS_NULL
Regelt het resultaat van het aaneenschakelen van strings met null waarden. Bepaalt, indien ingeschakeld, dat deze join een nulwaarde moet retourneren; anders wordt de string zelf geretourneerd.
ANSI_WARNINGS
Bepaalt, indien ingeschakeld, het genereren van foutmeldingen wanneer:
- u samenvattingsfuncties gebruikt en er nulwaarden in het querybereik worden aangetroffen;
- er een verdeling door nul of een rekenkundige overflow wordt aangetroffen.
NUMERIC_ROUNDABORT
Bepaalt hoe SQL Server moet handelen bij verlies van numerieke precisie bij rekenkundige bewerkingen. Indien de parameter is ingeschakeld en een variabele met een precisie van twee decimalen een waarde met drie decimalen ontvangt, wordt de bewerking afgebroken. Als de parameter is uitgeschakeld, zal de waarde worden afgekapt tot twee cijfers achter de komma.
Conclusie
Wanneer het aankomt op query optimalisatie, zijn geïndexeerde views een goede keuze voor het benutten van prestaties. Evalueer daarom grondig de query’s die te maken hebben met samenvattingen en die met een zekere frequentie worden uitgevoerd, en ga voor het maken van geïndexeerde weergaven. Het resultaat is het waard!