




Statistische analyse: Significantie en Betrouwbaarheidsintervallen
In elke statistische analyse werkt u waarschijnlijk met een steekproef, en niet met gegevens van de hele populatie. Uw resultaat is dus mogelijk niet representatief voor de gehele populatie – en kan zelfs zeer onnauwkeurig zijn als uw steekproef niet erg goed was.
U hebt dus een manier nodig om te meten hoe zeker u bent dat uw resultaat nauwkeurig is, en niet gewoon door toeval is ontstaan. Statistici gebruiken hiervoor twee met elkaar verbonden begrippen: betrouwbaarheid en significantie.
Op deze pagina worden deze begrippen uitgelegd.
Statistische significantie
De term significantie heeft in de statistiek een heel bijzondere betekenis. Het vertelt u hoe waarschijnlijk het is dat uw resultaat niet door toeval is ontstaan.

In het diagram stelt de blauwe cirkel de hele populatie voor. Wanneer u een steekproef neemt, kan uw steekproef uit de hele populatie afkomstig zijn. Het is echter waarschijnlijker dat hij kleiner is. Als alles uit de gele cirkel komt, zou u een groot deel van de populatie hebben bestreken. U kunt echter ook pech hebben (of uw steekproefprocedure slecht hebben opgezet) en alleen monsters nemen uit de kleine rode cirkel. Dit zou ernstige gevolgen hebben voor de vraag of uw steekproef representatief is voor de gehele populatie.
Een van de beste manieren om ervoor te zorgen dat u een groter deel van de populatie bestrijkt, is door een grotere steekproef te gebruiken. De omvang van uw steekproef is van grote invloed op de nauwkeurigheid van uw resultaten (meer hierover op onze pagina over Steekproeven en steekproefontwerp).
Echter is ook een ander element van invloed op de nauwkeurigheid: variatie binnen de populatie zelf. U kunt dit beoordelen door te kijken naar metingen van de spreiding van uw gegevens (en voor meer hierover, zie onze pagina over Eenvoudige statistische analyse). Waar meer variatie is, is er meer kans dat u een steekproef neemt die niet typisch is.
Het begrip significantie brengt eenvoudigweg steekproefgrootte en populatievariatie samen, en maakt een numerieke beoordeling van de kans dat u een steekproeffout hebt gemaakt: dat wil zeggen dat uw steekproef niet representatief is voor uw populatie.
Significantie wordt uitgedrukt als een waarschijnlijkheid dat uw resultaten door toeval zijn ontstaan, algemeen bekend als een p-waarde. Over het algemeen zoekt u naar een p-waarde die lager is dan een bepaalde waarde, meestal 0,05 (5%) of 0,01 (1%), hoewel sommige resultaten ook 0,10 (10%) vermelden.
Nulle en alternatieve hypothese
Wanneer u een experiment of een stuk marktonderzoek uitvoert, wilt u over het algemeen weten of wat u doet een effect heeft. Je kunt het daarom uitdrukken als een hypothese:
-x zal een effect hebben op y.
Dit staat in de statistiek bekend als de ‘alternatieve hypothese’, vaak H1 genoemd.
De ‘nulhypothese’, of H0, is dat x geen effect heeft op y.
Statistisch gezien is het doel van significantietests om te zien of uw resultaten suggereren dat u de nulhypothese moet verwerpen – in dat geval is het waarschijnlijker dat de alternatieve hypothese waar is.
Als uw resultaten niet significant zijn, kunt u de nulhypothese niet verwerpen en moet u concluderen dat er geen effect is.
De p-waarde is de waarschijnlijkheid dat u de resultaten zou hebben gekregen die u hebt gekregen als uw nulhypothese waar is.
Berekening van significantie
Een manier om significantie te berekenen is het gebruik van een z-score. Deze beschrijft de afstand van een gegevenspunt tot het gemiddelde, in termen van het aantal standaardafwijkingen (voor meer over gemiddelde en standaardafwijking, zie onze pagina over eenvoudige statistische analyse).
Voor een eenvoudige vergelijking wordt de z-score berekend met de formule:
$$z={x – \mu}{sigma}$$
waarbij \(x) het gegevenspunt is, \(\mu) het gemiddelde van de populatie of verdeling, en \(\sigma) de standaardafwijking.
Voorbeeld, stel dat we willen testen of een spel-app populairder is dan andere spellen. Laten we zeggen dat de gemiddelde game-app 1000 keer is gedownload, met een standaardafwijking van 110. Ons spel is 1200 keer gedownload. De z-score is:
$$z=\frac{1200-1000}{110}=1.81$$
Een hogere z-score geeft aan dat het resultaat minder waarschijnlijk door toeval is ontstaan.
U kunt een standaard statistische z-tabel gebruiken om uw z-score om te zetten in een p-waarde. Als je p-waarde lager is dan je gewenste significantieniveau, dan zijn je resultaten significant.
Met behulp van de z-tabel converteert de z-score voor onze game-app (1,81) naar een p-waarde van 0,9649. Dit is beter dan ons gewenste niveau van 5% (0,05) (want 1-0,9649 = 0,0351, of 3,5%), dus we kunnen zeggen dat dit resultaat significant is.
Merk op dat er een klein verschil is voor een steekproef uit een populatie, waar de z-score wordt berekend met de formule:
$$z={(x-kmu)}{(√sigma/qrt n)}$
waarbij x het gegevenspunt is (meestal je steekproefgemiddelde), µ het gemiddelde van de populatie of verdeling, σ de standaardafwijking, en √n de vierkantswortel van de steekproefgrootte.
Een voorbeeld zal dit duidelijker maken.
Voorstel dat u nagaat of biologiestudenten de neiging hebben betere cijfers te halen dan hun medestudenten die andere vakken studeren. U zou kunnen vaststellen dat het gemiddelde cijfer van een steekproef van 40 biologen 80 is, met een standaardafwijking van 5, vergeleken met 78 voor alle studenten aan die universiteit of school.
$$z={(80-78)}{(5/\sqrt 40)}=2.53$$
Uit de z-tabel komt 2.53 overeen met een p-waarde van 0.9943. Je kunt dit van 1 aftrekken om 0.0054 te krijgen. Dit is lager dan 1%, zodat we kunnen zeggen dat dit resultaat significant is op het 1%-niveau, en dat biologen betere resultaten halen voor toetsen dan de gemiddelde student aan deze universiteit.
Merk op dat dit niet noodzakelijkerwijs betekent dat biologen slimmer zijn of beter slagen voor toetsen dan degenen die andere vakken studeren. Het zou in feite kunnen betekenen dat de toetsen in de biologie gemakkelijker zijn dan die in andere vakken. Het vinden van een significant resultaat is GEEN bewijs van een oorzakelijk verband, maar het vertelt je wel dat er misschien een kwestie is die je wilt onderzoeken.
Er is meer over het testen op significantie van steekproefgemiddelden, en het testen van verschillen tussen groepen, op onze pagina over Hypotheseontwikkeling en testen.
Betrouwbaarheidsintervallen
Een betrouwbaarheidsinterval (of betrouwbaarheidsniveau) is een bereik van waarden die een bepaalde waarschijnlijkheid hebben dat de werkelijke waarde erin ligt.
In feite meet het hoe zeker u bent dat het gemiddelde van uw steekproef (het steekproefgemiddelde) hetzelfde is als het gemiddelde van de totale populatie waaruit uw steekproef is getrokken (het populatiegemiddelde).
Bij voorbeeld, als uw gemiddelde 12,4 is, en uw 95%-betrouwbaarheidsinterval is 10,3-15,6, betekent dit dat u 95% zeker bent dat de werkelijke waarde van uw populatiegemiddelde tussen 10,3 en 15,6 ligt. Met andere woorden, het is misschien niet 12,4, maar je bent er redelijk zeker van dat het niet veel verschilt.
Het diagram hieronder laat dit in de praktijk zien voor een variabele die een normale verdeling volgt (voor meer hierover, zie onze pagina over statistische verdelingen).

De precieze betekenis van een betrouwbaarheidsinterval is dat als je je experiment vele, vele malen zou doen, 95% van de intervallen die je op basis van deze experimenten construeert, de ware waarde zou bevatten. Met andere woorden, in 5% van uw experimenten zou uw interval NIET de werkelijke waarde bevatten.
U kunt in het diagram zien dat er een kans van 5% is dat het betrouwbaarheidsinterval het populatiegemiddelde niet bevat (de twee ‘staarten’ van 2,5% aan weerszijden). Met andere woorden, in één op de 20 steekproeven of experimenten zal de waarde die we voor het betrouwbaarheidsinterval krijgen, niet het ware gemiddelde bevatten: het populatiegemiddelde zal in feite buiten het betrouwbaarheidsinterval vallen.
Berekenen van het betrouwbaarheidsinterval
Berekenen van een betrouwbaarheidsinterval maakt gebruik van uw steekproefwaarden, en enkele standaardmaten (gemiddelde en standaardafwijking) (en voor meer over hoe deze te berekenen, zie onze pagina over Eenvoudige statistische analyse).
Het is het gemakkelijkst te begrijpen met een voorbeeld.
Stel dat we de lengte van een groep van 40 mensen hebben bemonsterd en hebben vastgesteld dat het gemiddelde 159,1 cm was, en de standaardafwijking 25,4.
Standaardafwijking voor betrouwbaarheidsintervallen
Normaal gesproken zou u de standaardafwijking van de populatie gebruiken om het betrouwbaarheidsinterval te berekenen. Het is echter zeer onwaarschijnlijk dat u zou weten wat dit was.
Gelukkig genoeg kunt u de standaardafwijking van de steekproef gebruiken, mits u een steekproef hebt die groot genoeg is. Over het algemeen wordt een steekproefgrootte van 30 of meer als uitgangspunt genomen, maar hoe groter, hoe beter.
We moeten nagaan of ons gemiddelde een redelijke schatting is van de lengte van alle mensen, of dat we een bijzonder lange (of korte) steekproef hebben genomen.
We gebruiken een formule voor het berekenen van een betrouwbaarheidsinterval. Dit is:
$$mean \pm z \frac{(SD)}{\sqrt n}$$
Waarbij SD = standaardafwijking, en n het aantal waarnemingen of de steekproefgrootte.
De z-waarde wordt gehaald uit statistische tabellen voor de door ons gekozen referentieverdeling. Deze tabellen geven de z-waarde voor een bepaald betrouwbaarheidsinterval (zeg 95% of 99%).
In dit geval meten we de lichaamslengte van mensen, en we weten dat de lichaamslengte van de bevolking een (globaal) normale verdeling volgt (voor meer hierover, zie onze pagina over statistische verdelingen).We kunnen dus de waarden voor een normale verdeling gebruiken.
De z-waarde voor een 95%-betrouwbaarheidsinterval is 1,96 voor de normale verdeling (ontleend aan standaard statistische tabellen).
Gebruik makend van bovenstaande formule is het 95%-betrouwbaarheidsinterval dus:
$$159,1 \pm 1,96 \frac{(25,4)}{\sqrt 40}$$$
Als we deze berekening uitvoeren, vinden we dat het betrouwbaarheidsinterval 151,23-166,97 cm is. Het is dus redelijk om te zeggen dat we er dus 95% zeker van zijn dat het populatiegemiddelde binnen dit bereik valt.
Uitleg over z-score of z-waarde
De z-score is een maat voor de standaardafwijkingen van het gemiddelde. In ons voorbeeld weten we dus dat 95% van de waarden binnen ± 1,96 standaardafwijkingen van het gemiddelde zal vallen:
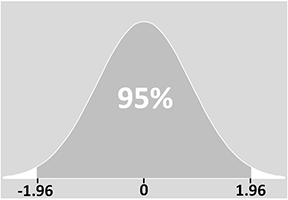
Bepaling van uw betrouwbaarheidsinterval
Als algemene vuistregel geldt dat een klein betrouwbaarheidsinterval beter is. Het betrouwbaarheidsinterval wordt kleiner naarmate de steekproefgrootte toeneemt, en daarom wordt altijd de voorkeur gegeven aan een grotere steekproef. Zoals onze pagina over steekproeftrekking en steekproefontwerp uitlegt, zou uw ideale experiment de hele populatie omvatten, maar dit is meestal niet mogelijk.
Conclusie
Betrouwbaarheidsintervallen en significantie zijn standaardmanieren om de kwaliteit van uw statistische resultaten aan te tonen. Van u wordt verwacht dat u ze routinematig rapporteert wanneer u een statistische analyse uitvoert, en over het algemeen moet u precieze cijfers rapporteren. Dit zal ervoor zorgen dat uw onderzoek geldig en betrouwbaar is.