




Hvor gode er meningsmålingerne? Analyse af Five-Thirty-Eights datasæt
Vi analyserer datasættet for meningsmåleres rangordning fra det ærværdige politiske forudsigelseswebsted Five-Thirty-Eight.

Dette er et valgår, og meningsmålingerne omkring valgene (både præsidentvalget og valget til Repræsentanternes Hus/Senatet) er ved at blive ophedet. Det bliver mere og mere spændende i de kommende dage med tweets, mod-tweets, slagsmål på de sociale medier og endeløse punditry på tv.
Vi ved, at ikke alle meningsmålinger er af samme kvalitet. Så hvordan kan man få mening ud af det hele? Hvordan identificerer man troværdige meningsmålingsinstitutter ved hjælp af data og analyser?

I en verden af politiske (og nogle andre emner som sport, sociale fænomener, økonomi osv.) forudsigelsesanalyser er Five-Thirty-Eight et formidabelt navn.
Siden har siden begyndelsen af 2008 offentliggjort artikler – typisk med oprettelse eller analyse af statistiske oplysninger – om en lang række emner inden for aktuel politik og politiske nyheder. Hjemmesiden, der drives af rockstjernen datalog og statistiker Nate Silver, opnåede særlig prominens og udbredt berømmelse omkring præsidentvalget i 2012, da dens model korrekt forudsagde vinderen i alle 50 stater og District of Columbia.
Og før du spottes og siger “Men hvad med valget i 2016?”, kan du med fordel læse denne artikel om, hvordan valget af Donald Trump lå inden for den normale fejlmargin i den statistiske modellering.
For de mere politisk nysgerrige læsere har de en hel pose artikler om valget i 2016 her.
Data science-praktikere burde kunne lide Five-Thirty-Eight, fordi de ikke viger tilbage for at forklare deres forudsigelsesmodeller i meget tekniske termer (i hvert fald komplekse nok til at være komplicerede for lægmænd).

Men ud over brugen af sofistikerede statistiske modelleringsteknikker er holdet under Silver stolt af en unik metode – pollster rating – for at hjælpe deres modeller med at forblive meget præcise og troværdige.
I denne artikel analyserer vi deres data om disse ratingmetoder.
Five-Thirty-Eight viger ikke tilbage for at forklare deres forudsigelsesmodeller i form af meget tekniske termer (i hvert fald komplekse nok til, at lægmanden kan forstå dem).
Pollster rating og ranking
Der er et væld af meningsmålingsinstitutter, der opererer i dette land. At læse og bedømme kvaliteten af dem kan være meget anstrengende og opsigtsvækkende. Som det fremgår af hjemmesiden: “At læse meningsmålinger kan være farligt for dit helbred. Symptomerne omfatter kirsebærplukning, overdreven selvtillid, at falde for usikre tal og forhaste sig med at dømme. Heldigvis har vi en kur.” (kilde)
Der findes meningsmålinger. Og så er der meningsmålinger af meningsmålinger. Og så er der vægtede meningsmålinger af meningsmålinger. Frem for alt er der en meningsmåling af meningsmålinger med vægte, der er statistisk modellerede og dynamisk skiftende vægte.
Klanger det bekendt med andre berømte rankingmetoder, du har hørt om som datalog? Amazons produktrangering eller Netflix’ filmrangering? Sandsynligvis, ja.
Helt grundlæggende bruger Five-Thirty-Eight dette rating/ranking-system til at vægte meningsmålingernes resultater (højt rangerede meningsmåleresultater tillægges større betydning og så videre og så videre). De følger også aktivt nøjagtigheden og metoderne bag de enkelte meningsmåleresultater og justerer deres rangordning i løbet af året.
Der er meningsmålinger. Og så er der meningsmålinger af meningsmålinger. Og så er der vægtede meningsmålinger af meningsmålinger. Frem for alt er der meningsmålinger af meningsmålinger med vægte, der er statistisk modellerede og dynamisk skiftende vægte.
Det er interessant at bemærke, at deres rankingmetode ikke nødvendigvis vurderer et meningsmålingsinstitut med en større stikprøvestørrelse som et bedre institut. Følgende skærmbillede fra deres hjemmeside demonstrerer det tydeligt. Mens meningsmålingsinstitutter som Rasmussen Reports og HarrisX har større stikprøvestørrelser, er det faktisk Marist College, der får A+-rating med en beskeden stikprøvestørrelse.
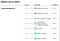
Godt nok åbner de også deres pollster ranking data (sammen med næsten alle deres andre datasæt) her på Github. Og hvis du kun er interesseret i en flot tabel, så er den her.
Naturligvis vil du som datalog måske gerne kigge dybere ind i de rå data og forstå ting som,
- hvordan deres numeriske rangordning korrelerer med nøjagtigheden af meningsmålingerne
- hvis de har en partisk bias i forhold til at vælge bestemte meningsmålere (i de fleste tilfælde kan de kategoriseres som enten demokratisk-orienterede eller republikansk-orienterede)
- hvem er de bedst rangerede meningsmålere? Foretager de mange meningsmålinger, eller er de selektive?
Vi har forsøgt at analysere datasættet for at opnå en sådan indsigt. Lad os grave i koden og resultaterne, skal vi?
Analysen
Du kan finde Jupyter Notebook her på min Github repo.
Kilden
For at starte kan du trække dataene direkte fra deres Github, ind i et Pandas DataFrame, som følger,

Der er 23 kolonner i dette datasæt. Sådan ser de ud,

En del transformation og oprydning
Vi bemærker, at en kolonne har lidt ekstra plads. Et par andre kan have brug for noget udtrækning og konvertering af datatype.



Efter anvendelse af denne udtrækning, har det nye DataFrame yderligere kolonner, hvilket gør det mere velegnet til filtrering og statistisk modellering.

Undersøgelse og kvantificering af kolonnen “538 Grade”
Kolonnerne “538 Grades” indeholder datasættets kerne, nemlig brevkarakteren for meningsmåleren. Ligesom ved en almindelig eksamen er A+ bedre end A, og A er bedre end B+. Hvis vi plotter tællingerne af bogstavkaraktererne, observerer vi i alt 15 gradueringer fra A+ til F.

I stedet for at arbejde med så mange kategoriske gradueringer, kan vi måske kombinere dem til et lille antal numeriske karakterer – 4 for A+/A/A/A-, 3 for B’erne osv.

Boxplots
Går vi ind i visuel analyse, kan vi starte med boxplots.
Lad os antage, at vi ønsker at kontrollere, hvilken afstemningsmetode der klarer sig bedst med hensyn til forudsigelsesfejl. Datasættet har en kolonne kaldet “Simple Average Error”, som er defineret som “The firm’s average error, calculated as the difference between the polled result and the actual result for the margin separating the top two finishers in the race”.”

Så kan vi være interesseret i at kontrollere, om meningsmålingsinstitutter med en vis partiskhed har større succes med at udråbe valgene korrekt end andre.

Mærker du noget interessant ovenfor? Hvis du er en progressiv, liberal tænkende person, kan du efter al sandsynlighed være partisk tilhænger af det demokratiske parti. Men i gennemsnit kalder meningsmålingerne med republikansk orientering, valgene mere præcist og med mindre variabilitet. Man må hellere holde øje med disse meningsmålinger!
En anden interessant kolonne i datasættet hedder “NCPP/AAPOR/Roper”. Den “angiver, om meningsmålingsfirmaet var medlem af National Council on Public Polls, underskriver af American Association for Public Opinion Research’s gennemsigtighedsinitiativ eller bidrager til Roper Center for Public Opinion Research’s dataarkiv”. Et medlemskab indikerer i realiteten, at man overholder en mere robust meningsmålingsmetodologi” (kilde).
Hvordan kan man vurdere gyldigheden af ovennævnte påstand? Datasættet har en kolonne kaldet “Advanced Plus-Minus”, som er “en score, der sammenligner et meningsmålingskontors resultat med andre meningsmålingskontorer, der undersøger de samme løb, og som vægter de seneste resultater tungere. Negative scorer er gunstige og indikerer en kvalitet over gennemsnittet” (kilde).
Her er en boxplot mellem disse to parametre. Ikke alene udviser de meningsmålingsinstitutter, der er tilknyttet NCCP/AAPOR/Roper, en lavere fejlscore, men de udviser også en betydelig lav variabilitet. Deres forudsigelser synes at være stabile og robuste.

Hvis du er en progressiv, liberalt tænkende person, kan du efter al sandsynlighed være partisk tilhænger af det demokratiske parti. Men i gennemsnit kalder meningsmålingsinstitutterne med republikansk orienteret partiskhed valgene mere præcist og med mindre variabilitet.
Scatter- og regressionsplots
For at forstå sammenhængen mellem parametre kan vi se på scatterplots med regression fit. Vi bruger Seaborn- og Scipy Python-bibliotekerne og en tilpasset funktion til at generere disse plots.
For eksempel kan vi relatere “Races Called Correctly” til “Predictive Plus-Minus”. Ifølge Five-Thirty-Eight er “Predictive Plus-Minus” “en fremskrivning af, hvor nøjagtig meningsmåleren vil være i fremtidige valg. Det beregnes ved at tilbageføre en meningsmåleres Advanced Plus-Minus-score til et gennemsnit baseret på vores proxies for metodologisk kvalitet.” (kilde)

Og vi kan tjekke, hvordan den “Numeric Grade” vi definerede, korrelerer med gennemsnittet af meningsmålingsfejl. En negativ tendens indikerer, at en højere numerisk karakter er forbundet med en lavere meningsmålingsfejl.

Vi kan også kontrollere, om “Antal meningsmålinger til biasanalyse” er med til at reducere den “Partisan Bias Degree”, der er tildelt hvert meningsmålingsinstitut. Vi kan observere en nedadgående sammenhæng, hvilket indikerer, at tilgængeligheden af et stort antal meningsmålinger bidrager til at reducere graden af partisk skævhed. Forholdet ser dog meget ulineært ud, og en logaritmisk skalering ville have været bedre til at tilpasse kurven.

Er mere aktive meningsmålere at stole mere på? Vi tegner histogrammet over antallet af meningsmålinger og ser, at det følger en negativ potenslov. Vi kan filtrere meningsmålingerne med både et meget lavt og et meget højt antal meningsmålinger fra og oprette et brugerdefineret spredningsdiagram. Vi observerer imidlertid en næsten ikke-eksisterende korrelation mellem antallet af meningsmålinger og den prædiktive Plus-Minus-score. Derfor fører et stort antal meningsmålinger ikke nødvendigvis til en høj meningsmålingskvalitet og forudsigelseskraft.