




Indledning til databasedesign
Identificering af attributter
De dataelementer, som du ønsker at gemme for hver enhed, kaldes ‘attributter’.
Om de produkter, du sælger, vil du f.eks. gerne vide, hvad prisen er, hvad navnet på producenten er, og hvad typenummeret er. Om kunderne kender du deres kundenummer, deres navn og deres adresse. Om butikkerne kender du beliggenhedskoden, navnet og adressen. Om salgene ved du, hvornår de fandt sted, i hvilken butik, hvilke produkter der blev solgt, og hvor meget salget beløb sig i alt. Om sælgeren kender du hans medarbejdernummer, navn og adresse. Hvad der præcist skal medtages, er ikke af betydning endnu; det handler stadig kun om, hvad du ønsker at gemme.
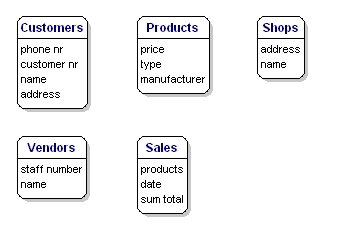
Figur 6: Entiteter med attributter.
Afledte data
Afledte data er data, der er afledt af de andre data, som du allerede har gemt. I dette tilfælde er “summen af data” et klassisk tilfælde af afledte data. Du ved præcis, hvad der er blevet solgt, og hvad hvert produkt koster, så du kan altid beregne, hvor meget den samlede sum af salget er. Så egentlig er det ikke nødvendigt at gemme den samlede sum.
Så hvorfor bliver den gemt her? Jo, fordi det er et salg, og fordi prisen på produktet kan variere over tid. Et produkt kan have en pris på 10 euro i dag og 8 euro i næste måned, og til din administration skal du vide, hvad det kostede på salgstidspunktet, og den nemmeste måde at gøre det på er ved at gemme det her. Der findes en masse mere elegante måder, men de er for dybsindige til denne artikel.
Præsentation af enheder og relationer: Entity Relationship Diagram (ERD)
Entity Relationship Diagram (ERD) giver et grafisk overblik over databasen. Der findes flere forskellige stilarter og typer af ER-diagrammer. En meget anvendt notation er “crowfeet”-notationen, hvor enheder repræsenteres som rektangler, og relationerne mellem enhederne repræsenteres som linjer mellem enhederne. Tegnene i slutningen af linjerne angiver typen af relation. Den side af relationen, der er obligatorisk for at den anden kan eksistere, angives med en streg på linjen. Enheder, der ikke er obligatoriske, angives med en cirkel. “Mange” angives gennem en “kragefod”; relationslinjen deler sig op i tre linjer.
I denne artikel gør vi brug af DeZign for Databases til at designe og præsentere vores database.
En 1:1 obligatorisk relation er repræsenteret således:
Figur 7: Obligatorisk en til en-relation.
En obligatorisk 1:N-relation:
Figur 8: Obligatorisk en til mange-relation.
Et M:N-forhold er:
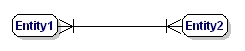
Figur 9: Obligatorisk mange til mange-forhold.
Modellen i vores eksempel vil se således ud:
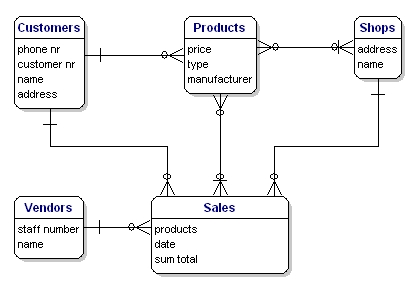
Figur 10: Model med relationer.
Tildeling af nøgler
Primærnøgler
En primærnøgle (PK) er en eller flere dataattributter, der entydigt identificerer en enhed. En nøgle, der består af to eller flere attributter, kaldes en sammensat nøgle. Alle attributter, der indgår i en primær nøgle, skal have en værdi i hver post (som ikke kan være tom), og kombinationen af værdierne i disse attributter skal være unik i tabellen.
I eksemplet er der et par oplagte kandidater til den primære nøgle. Kunderne har alle et kundenummer, produkterne har alle et unikt produktnummer og salget har et salgsnummer. Hver af disse data er unikke, og hver record vil indeholde en værdi, så disse attributter kan være en primærnøgle. Ofte anvendes en heltalskolonne som primærnøgle, så en post let kan findes via dens nummer.
Link-entiteter henviser normalt til primærnøgleattributterne for de enheder, som de linker. Den primære nøgle for en link-entitet er normalt en samling af disse reference-attributter. I enheden Sales_details kunne vi f.eks. bruge kombinationen af PK’erne for enhederne sales og products som PK for Sales_details. På denne måde håndhæver vi, at det samme produkt (type) kun kan anvendes én gang i det samme salg. Flere varer af samme produkttype i et salg skal angives ved mængden.
I ERD’et er primærnøgleattributterne angivet ved teksten “PK” bag attributtens navn. I eksemplet har kun entiteten “shop” ikke en indlysende kandidat til PK, så vi vil indføre en ny attribut for denne entitet: shopnr.
Fremdnøgler
Fremdnøglen (FK) i en entitet er referencen til en anden entitets primærnøgle. I ERD’et vil denne attribut blive angivet med “FK” bag sit navn. Den fremmede nøgle i en enhed kan også være en del af den primære nøgle, i så fald vil attributten blive angivet med “PF” bag sit navn. Dette er normalt tilfældet med link-entiteterne, fordi man normalt kun forbinder to instanser én gang sammen (med 1 salg sælges kun 1 produkttype én gang).
Hvis vi sætter alle link-entiteter, PK’er og FK’er ind i ERD’et, får vi modellen som vist nedenfor. Bemærk, at attributten “products” ikke længere er nødvendig i “Sales”, fordi “solgte produkter” nu er med i link-tabellen. I link-tabellen blev der tilføjet et andet felt, “quantity”, der angiver, hvor mange produkter der er solgt. Feltet “mængde” blev også tilføjet i lagertabellen for at angive, hvor mange produkter der stadig er på lager.
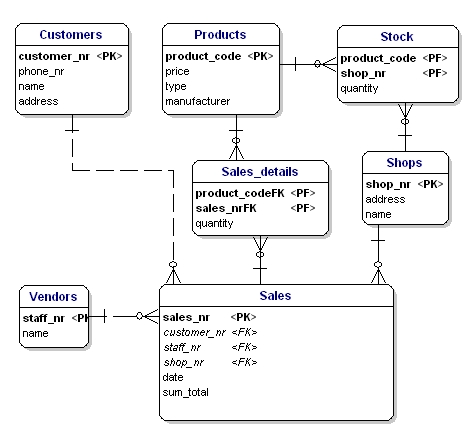
Figur 11: Primærnøgler og fremmednøgler.
Definering af attributtets datatype
Nu er det tid til at finde ud af, hvilke datatyper der skal bruges til attributterne. Der findes en masse forskellige datatyper. Nogle få er standardiserede, men mange databaser har deres egne datatyper, som alle har deres egne fordele. Nogle databaser giver mulighed for at definere egne datatyper, hvis standardtyperne ikke kan gøre de ting, du har brug for.
De standard datatyper, som alle databaser kender, og som er mest anvendte, er: CHAR, VARCHAR, TEXT, FLOAT, DOUBLE og INT.
Tekst:
- CHAR(længde) – omfatter tekst (tegn, tal, tegnsætninger…). CHAR har som egenskab, at den altid gemmer et fast antal positioner. Hvis du definerer en CHAR(10), kan du maksimalt gemme op til ti positioner, men hvis du kun bruger to positioner, vil databasen stadig gemme 10 positioner. De resterende otte positioner vil blive udfyldt af mellemrum.
- VARCHAR(længde) – omfatter tekst (tegn, tal, tegnsætning…). VARCHAR er det samme som CHAR, forskellen er, at VARCHAR kun tager så meget plads som nødvendigt.
- TEXT – kan indeholde store mængder tekst. Afhængigt af databasetypen kan det løbe op i gigabytes.
Numbers:
- INT – indeholder et positivt eller negativt helt tal. Mange databaser har variationer af INT, f.eks. TINYINT, SMALLINT, MEDIUMINT, BIGINT, INT2, INT4, INT8. Disse variationer adskiller sig kun fra INT ved størrelsen af det tal, der passer ind i det. En almindelig INT er på 4 bytes (INT4) og passer til tal fra -2147483647 til +2147483646 eller, hvis du definerer den som UNSIGNED, fra 0 til 4294967296. INT8, eller BIGINT, kan blive endnu større i størrelse, fra 0 til 184467440407370955161616, men tager op til 8 bytes diskplads, selv om der kun er et lille tal i det.
- FLOAT, DOUBLE – Samme idé som INT, men kan også lagre floating point-tal. . Bemærk dog, at dette ikke altid fungerer perfekt. For eksempel i MySQL er beregning med disse floating point tal ikke perfekt, (1/3)*3 vil resultere med MySQL’s floats i 0,999999999, ikke 1.
Andre typer:
- BLOB – til binære data som f.eks. filer.
- INET – til IP-adresser. Kan også bruges til netmasker.
For vores eksempel er datatyperne som følger:
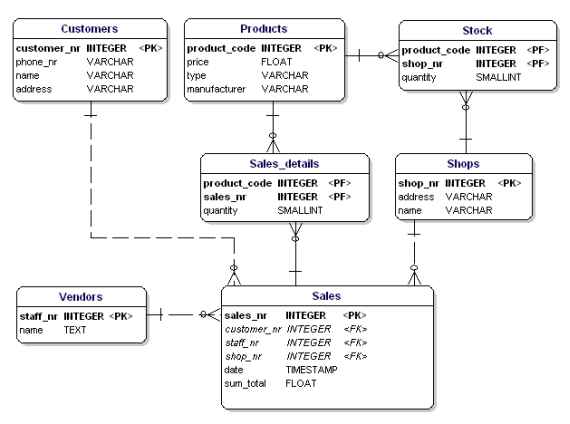
Figur 12: Datamodel, der viser datatyper.
Normalisering
Normalisering gør din datamodel fleksibel og pålidelig. Det genererer en del overhead, fordi du normalt får flere tabeller, men det giver dig mulighed for at gøre mange ting med din datamodel uden at skulle justere den. Du kan læse mere om databasernormalisering i denne artikel.
Normalisering, den første form
Den første form for normalisering fastslår, at der ikke må være nogen gentagende grupper af kolonner i en enhed. Vi kunne have oprettet en entitet “salg” med attributter for hver af de produkter, der blev købt. Dette ville se således ud:

Figur 13: Ikke i 1. normalform.
Det, der er forkert ved dette, er, at der nu kun kan sælges 3 produkter. Hvis du skulle sælge 4 produkter, så skal du starte et andet salg eller justere din datamodel ved at tilføje “product4”-attributter. Begge løsninger er uønskede. I disse tilfælde bør du altid oprette en ny enhed, som du linker til den gamle enhed via en one-to-many-relation.
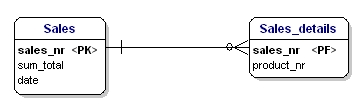
Figur 14: I overensstemmelse med 1. normalform.
Normalisering, den anden form
Den anden form for normalisering fastslår, at alle attributter for en entitet skal være fuldt afhængige af hele primærnøglen. Det betyder, at hver attribut af en entitet kun kan identificeres gennem hele primærnøglen. Lad os antage, at vi havde datoen i entiteten Sales_details:

Figur 15: Ikke i 2. normalform.
Denne entitet er ikke i overensstemmelse med 2. normaliseringsform, for for at kunne slå datoen for et salg op, behøver jeg ikke at vide, hvad der er solgt (produktnr), det eneste, jeg behøver at vide, er salgsnummeret. Dette blev løst ved at dele tabellerne op i tabellen Salg og tabellen Salg_detaljer:
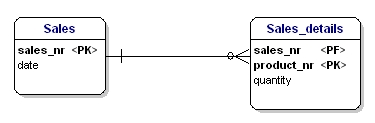
Figur 16: I overensstemmelse med 2. normalform.
Nu er hver attribut i entiteterne afhængig af hele PK for entiteten. Datoen er afhængig af salgsnummeret, og mængden er afhængig af salgsnummeret og det solgte produkt.
Normalisering, den tredje form
Den tredje form for normalisering siger, at alle attributter skal være direkte afhængige af primærnøglen, og ikke af andre attributter. Dette synes at være det samme som i den anden form for normalisering, men i den anden form står der faktisk det modsatte. I den anden form for normalisering peger man på attributter gennem PK’en, i den tredje form for normalisering skal alle attributter være afhængige af PK’en og intet andet.

Figur 17: Ikke i 3. normalform.
I dette tilfælde er prisen på et løst produkt afhængig af bestillingsnummeret, og bestillingsnummeret er afhængig af produktnummeret og salgsnummeret. Dette er ikke i overensstemmelse med den tredje normaliseringsform. Igen løser en opsplitning af tabellerne dette.
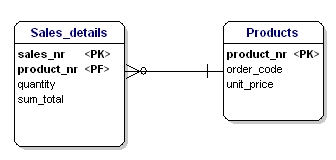
Figur 18: I overensstemmelse med 3. normalform.
Normalisering, flere former
Der findes flere normaliseringsformer end de tre ovennævnte tre former, men disse er ikke af stor interesse for den gennemsnitlige bruger. Disse andre former er meget specialiserede til visse anvendelser. Hvis du holder dig til de designregler og den normalisering, der er nævnt i denne artikel, vil du skabe et design, der fungerer godt til de fleste applikationer.
Normaliseret datamodel
Hvis du anvender normaliseringsreglerne, vil du opdage, at ‘producenten’ i produkttabellen også bør være en separat tabel:
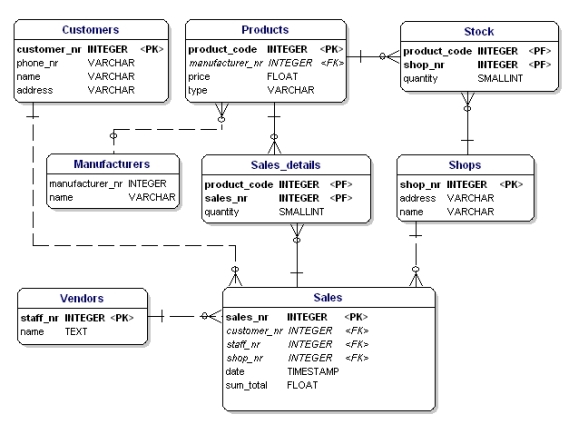
Figur 19: Datamodel i overensstemmelse med 1., 2. og 3. normalform.