




Einführung in den Datenbankentwurf
Attribute identifizieren
Die Datenelemente, die Sie für jede Entität speichern wollen, werden „Attribute“ genannt.
Über die Produkte, die Sie verkaufen, wollen Sie zum Beispiel wissen, wie hoch der Preis ist, wie der Name des Herstellers lautet und wie die Typennummer lautet. Über die Kunden wissen Sie die Kundennummer, den Namen und die Adresse. Von den Geschäften kennen Sie den Standortcode, den Namen und die Adresse. Von den Verkäufen wissen Sie, wann sie stattgefunden haben, in welchem Geschäft, welche Produkte verkauft wurden und wie hoch die Verkaufssumme war. Vom Verkäufer kennen Sie seine Personalnummer, seinen Namen und seine Adresse. Was genau erfasst wird, ist noch nicht von Bedeutung; es geht nur darum, was Sie speichern wollen.
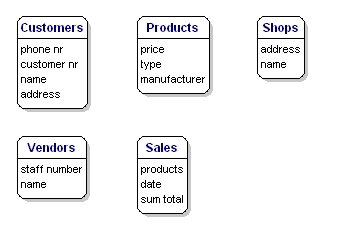
Abbildung 6: Entitäten mit Attributen.
Abgeleitete Daten
Abgeleitete Daten sind Daten, die von anderen Daten, die Sie bereits gespeichert haben, abgeleitet sind. In diesem Fall ist die „Gesamtsumme“ ein klassischer Fall von abgeleiteten Daten. Da Sie genau wissen, was verkauft wurde und was die einzelnen Produkte kosten, können Sie jederzeit berechnen, wie hoch die Gesamtsumme der Verkäufe ist. Es ist also wirklich nicht notwendig, die Gesamtsumme zu speichern.
Warum wird sie dann hier gespeichert? Nun, weil es sich um einen Verkauf handelt, und der Preis des Produkts kann im Laufe der Zeit variieren. Ein Produkt kann heute 10 Euro kosten und nächsten Monat 8 Euro, und für Ihre Verwaltung müssen Sie wissen, was es zum Zeitpunkt des Verkaufs gekostet hat, und das geht am einfachsten, wenn Sie es hier speichern. Es gibt noch viele elegantere Möglichkeiten, aber sie sind zu tiefgründig für diesen Artikel.
Darstellung von Entitäten und Beziehungen: Entity Relationship Diagram (ERD)
Das Entity Relationship Diagram (ERD) gibt einen grafischen Überblick über die Datenbank. Es gibt verschiedene Stile und Typen von ER-Diagrammen. Eine weit verbreitete Notation ist die „Crowfeet“-Notation, bei der Entitäten als Rechtecke und die Beziehungen zwischen den Entitäten als Linien zwischen den Entitäten dargestellt werden. Die Zeichen am Ende der Linien geben die Art der Beziehung an. Die Seite der Beziehung, die für die Existenz der anderen zwingend erforderlich ist, wird durch einen Strich auf der Linie angezeigt. Nicht obligatorische Entitäten sind durch einen Kreis gekennzeichnet. „Viele“ werden durch ein „Krähenfüßchen“ angezeigt; die Beziehungslinie teilt sich in drei Linien auf.
In diesem Artikel verwenden wir DeZign for Databases, um unsere Datenbank zu entwerfen und darzustellen.
Eine obligatorische 1:1-Beziehung wird wie folgt dargestellt:
Abbildung 7: Obligatorische Eins-zu-eins-Beziehung.
Eine obligatorische 1:N-Beziehung:
Abbildung 8: Obligatorische eins-zu-viele-Beziehung.
Eine M:N-Beziehung ist:
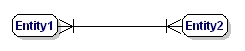
Abbildung 9: Obligatorische Many-to-Many-Beziehung.
Das Modell unseres Beispiels wird wie folgt aussehen:
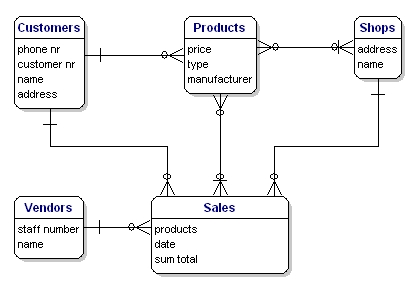
Abbildung 10: Modell mit Beziehungen.
Schlüssel zuordnen
Primärschlüssel
Ein Primärschlüssel (PK) ist ein oder mehrere Datenattribute, die eine Entität eindeutig identifizieren. Ein Schlüssel, der aus zwei oder mehr Attributen besteht, wird als zusammengesetzter Schlüssel bezeichnet. Alle Attribute, die Teil eines Primärschlüssels sind, müssen in jedem Datensatz einen Wert haben (der nicht leer bleiben darf), und die Kombination der Werte innerhalb dieser Attribute muss in der Tabelle eindeutig sein.
Im Beispiel gibt es einige offensichtliche Kandidaten für den Primärschlüssel. Kunden haben alle eine Kundennummer, Produkte haben alle eine eindeutige Produktnummer und die Verkäufe haben eine Verkaufsnummer. Jede dieser Daten ist eindeutig, und jeder Datensatz enthält einen Wert, so dass diese Attribute als Primärschlüssel dienen können. Oft wird eine Integer-Spalte für den Primärschlüssel verwendet, so dass ein Datensatz anhand seiner Nummer leicht gefunden werden kann.
Verknüpfte Entitäten beziehen sich normalerweise auf die Primärschlüsselattribute der Entitäten, die sie verknüpfen. Der Primärschlüssel einer Link-Entität ist in der Regel eine Sammlung dieser Referenzattribute. In der Entität „Sales_details“ könnten wir zum Beispiel die Kombination der PKs der Entitäten „Sales“ und „Products“ als PK von „Sales_details“ verwenden. Auf diese Weise erzwingen wir, dass dasselbe Produkt (Typ) nur einmal in demselben Verkauf verwendet werden kann. Mehrere Artikel desselben Produkttyps in einem Verkauf müssen durch die Menge angegeben werden.
In der ERD sind die Primärschlüsselattribute durch den Text ‚PK‘ hinter dem Namen des Attributs gekennzeichnet. Im Beispiel hat nur die Entität ’shop‘ keinen offensichtlichen Kandidaten für den PK, also werden wir ein neues Attribut für diese Entität einführen: shopnr.
Fremdschlüssel
Der Fremdschlüssel (FK) in einer Entität ist der Verweis auf den Primärschlüssel einer anderen Entität. In der ERD wird dieses Attribut mit „FK“ hinter seinem Namen angegeben. Der Fremdschlüssel einer Entität kann auch Teil des Primärschlüssels sein. In diesem Fall wird das Attribut mit „PF“ hinter seinem Namen angegeben. Dies ist in der Regel bei den Link-Entitäten der Fall, da man in der Regel zwei Instanzen nur einmal miteinander verknüpft (bei 1 Verkauf wird nur 1 Produkttyp 1 Mal verkauft).
Wenn wir alle Link-Entitäten, PK’s und FK’s in die ERD einfügen, erhalten wir das unten gezeigte Modell. Bitte beachten Sie, dass das Attribut „products“ in „Sales“ nicht mehr notwendig ist, da „sold products“ nun in der Link-Tabelle enthalten ist. In der Verknüpfungstabelle wurde ein weiteres Feld, „Menge“, hinzugefügt, das angibt, wie viele Produkte verkauft wurden. Das Feld „Menge“ wurde auch in der Bestandstabelle hinzugefügt, um anzugeben, wie viele Produkte noch auf Lager sind.
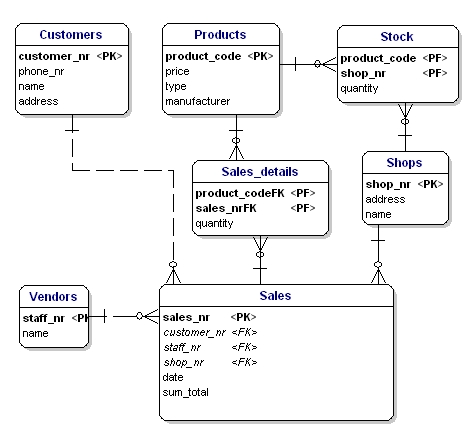
Abbildung 11: Primärschlüssel und Fremdschlüssel.
Definieren des Datentyps der Attribute
Jetzt ist es an der Zeit, herauszufinden, welche Datentypen für die Attribute verwendet werden müssen. Es gibt eine Menge verschiedener Datentypen. Einige sind standardisiert, aber viele Datenbanken haben ihre eigenen Datentypen, die alle ihre eigenen Vorteile haben. Einige Datenbanken bieten die Möglichkeit, eigene Datentypen zu definieren, falls die Standardtypen nicht das tun können, was man braucht.
Die Standard-Datentypen, die jede Datenbank kennt und die am häufigsten verwendet werden, sind: CHAR, VARCHAR, TEXT, FLOAT, DOUBLE und INT.
Text:
- CHAR(length) – umfasst Text (Zeichen, Zahlen, Interpunktionen…). CHAR hat die Eigenschaft, dass es immer eine feste Anzahl von Positionen speichert. Wenn Sie einen CHAR(10) definieren, können Sie maximal zehn Positionen speichern, aber wenn Sie nur zwei Positionen verwenden, speichert die Datenbank trotzdem 10 Positionen. Die restlichen acht Positionen werden durch Leerzeichen aufgefüllt.
- VARCHAR(length) – umfasst Text (Zeichen, Zahlen, Satzzeichen…). VARCHAR ist dasselbe wie CHAR, mit dem Unterschied, dass VARCHAR nur so viel Platz wie nötig einnimmt.
- TEXT – kann große Textmengen enthalten. Je nach Art der Datenbank kann dies bis zu Gigabytes betragen.
Zahlen:
- INT – enthält eine positive oder negative ganze Zahl. In vielen Datenbanken gibt es Variationen des INT, wie z.B. TINYINT, SMALLINT, MEDIUMINT, BIGINT, INT2, INT4, INT8. Diese Variationen unterscheiden sich vom INT nur durch die Größe der Zahl, die in ihn passt. Ein normaler INT ist 4 Byte groß (INT4) und passt für Zahlen von -2147483647 bis +2147483646, oder, wenn Sie ihn als UNSIGNED definieren, von 0 bis 4294967296. Der INT8, oder BIGINT, kann sogar noch größer werden, von 0 bis 18446744073709551616, nimmt aber bis zu 8 Byte Speicherplatz ein, auch wenn nur eine kleine Zahl darin steht.
- FLOAT, DOUBLE – Die gleiche Idee wie INT, kann aber auch Fließkommazahlen speichern. . Bitte beachten Sie, dass dies nicht immer perfekt funktioniert. Zum Beispiel in MySQL ist das Rechnen mit diesen Fließkommazahlen nicht perfekt, (1/3)*3 ergibt mit MySQL’s Fließkommazahlen 0.9999999, nicht 1.
Andere Typen:
- BLOB – für binäre Daten wie Dateien.
- INET – für IP-Adressen. Auch für Netzmasken verwendbar.
Für unser Beispiel lauten die Datentypen wie folgt:
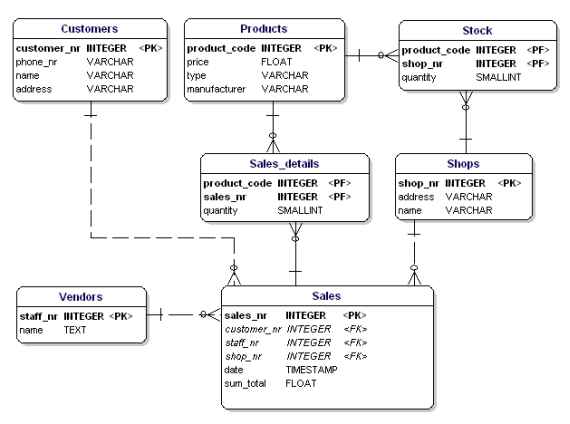
Abbildung 12: Datenmodell mit Darstellung der Datentypen.
Normalisierung
Normalisierung macht Ihr Datenmodell flexibel und zuverlässig. Sie verursacht zwar einen gewissen Overhead, weil Sie in der Regel mehr Tabellen erhalten, aber sie ermöglicht es Ihnen, viele Dinge mit Ihrem Datenmodell zu tun, ohne es anpassen zu müssen. Mehr über Datenbanknormalisierung erfahren Sie in diesem Artikel.
Normalisierung, die erste Form
Die erste Form der Normalisierung besagt, dass es keine sich wiederholenden Spaltengruppen in einer Entität geben darf. Wir hätten eine Entität „Verkäufe“ mit Attributen für jedes der gekauften Produkte erstellen können. Dies würde wie folgt aussehen:

Abbildung 13: Nicht in der ersten Normalform.
Falsch daran ist, dass jetzt nur 3 Produkte verkauft werden können. Wenn Sie 4 Produkte verkaufen wollen, müssen Sie einen zweiten Verkauf starten oder Ihr Datenmodell anpassen, indem Sie die Attribute „product4“ hinzufügen. Beide Lösungen sind unerwünscht. In diesen Fällen sollten Sie immer eine neue Entität erstellen, die Sie über eine Eins-zu-Viel-Beziehung mit der alten Entität verknüpfen.
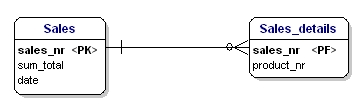
Abbildung 14: Gemäß der 1. Normalform.
Normalisierung, die zweite Form
Die zweite Form der Normalisierung besagt, dass alle Attribute einer Entität vollständig von dem gesamten Primärschlüssel abhängig sein sollten. Das bedeutet, dass jedes Attribut einer Entität nur durch den gesamten Primärschlüssel identifiziert werden kann. Angenommen, wir hätten das Datum in der Entität Sales_details:

Abbildung 15: Nicht in der zweiten Normalform.
Diese Entität entspricht nicht der zweiten Normalform, denn um das Datum eines Verkaufs nachschlagen zu können, muss ich nicht wissen, was verkauft wurde (productnr), ich muss nur die Verkaufsnummer kennen. Das Problem wurde gelöst, indem die Tabellen in die Tabelle „Verkäufe“ und die Tabelle „Verkaufsdetails“ aufgeteilt wurden:
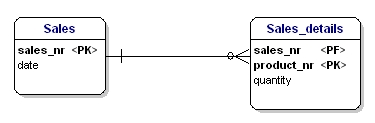
Abbildung 16: In Übereinstimmung mit der zweiten Normalform.
Jetzt ist jedes Attribut der Entitäten abhängig von der gesamten PK der Entität. Das Datum ist abhängig von der Verkaufsnummer, und die Menge ist abhängig von der Verkaufsnummer und dem verkauften Produkt.
Normalisierung, die dritte Form
Die dritte Form der Normalisierung besagt, dass alle Attribute direkt vom Primärschlüssel abhängig sein müssen und nicht von anderen Attributen. Dies scheint der zweiten Form der Normalisierung zu entsprechen, aber in der zweiten Form ist das Gegenteil der Fall. In der zweiten Form der Normalisierung werden die Attribute durch den PK hervorgehoben, in der dritten Form der Normalisierung muss jedes Attribut vom PK abhängig sein, und sonst nichts.

Abbildung 17: Nicht in der dritten Normalform.
In diesem Fall ist der Preis eines losen Produkts abhängig von der Bestellnummer, und die Bestellnummer ist abhängig von der Produktnummer und der Verkaufsnummer. Dies entspricht nicht der dritten Form der Normalisierung. Auch hier ist die Aufteilung der Tabellen die Lösung.
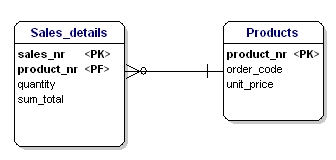
Abbildung 18: In Übereinstimmung mit der dritten Normalform.
Normalisierung, weitere Formen
Es gibt noch mehr Normalisierungsformen als die drei oben erwähnten, aber diese sind für den durchschnittlichen Benutzer nicht von großem Interesse. Diese anderen Formulare sind für bestimmte Anwendungen hoch spezialisiert. Wenn Sie sich an die Gestaltungsregeln und die in diesem Artikel erwähnte Normalisierung halten, werden Sie ein Design erstellen, das für die meisten Anwendungen gut funktioniert.
Normalisiertes Datenmodell
Wenn Sie die Normalisierungsregeln anwenden, werden Sie feststellen, dass der „Hersteller“ in der Produkttabelle auch eine separate Tabelle sein sollte:
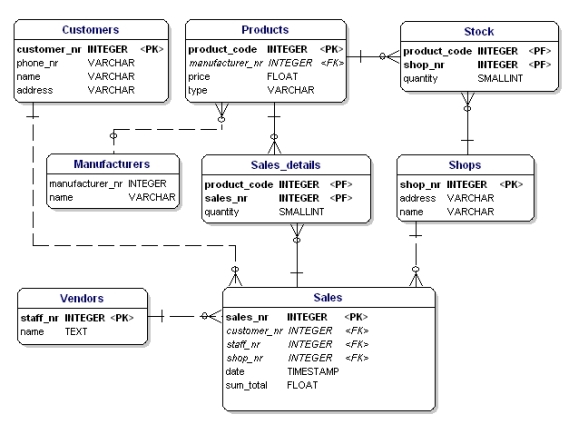
Abbildung 19: Datenmodell nach der 1., 2. und 3. Normalform.