




Enterprise Data Warehouse: Konzepte, Architektur und Komponenten
Lesezeit: 12 Minuten
Im Laufe des Tages treffen wir viele Entscheidungen auf der Grundlage früherer Erfahrungen. Unser Gehirn speichert Billionen von Daten über vergangene Ereignisse und greift jedes Mal auf diese Erinnerungen zurück, wenn wir eine Entscheidung treffen müssen. Genau wie die Menschen erzeugen und sammeln auch Unternehmen Unmengen von Daten über die Vergangenheit. Und diese Daten können genutzt werden, um bessere Entscheidungen zu treffen.
Während unser Gehirn sowohl zur Verarbeitung als auch zur Speicherung dient, benötigen Unternehmen mehrere Werkzeuge, um mit Daten zu arbeiten. Eines der wichtigsten ist ein Data Warehouse.
In diesem Artikel werden wir erörtern, was ein Enterprise Data Warehouse ist, welche Arten und Funktionen es hat und wie es in der Datenverarbeitung eingesetzt wird. Wir werden definieren, wie sich Enterprise Warehouses von den üblichen unterscheiden, welche Arten von Data Warehouses es gibt und wie sie funktionieren. Der Schwerpunkt liegt darauf, Informationen über den geschäftlichen Wert jedes architektonischen und konzeptionellen Ansatzes für den Aufbau eines Warehouses zu liefern.
Was ist ein Enterprise Data Warehouse?
Wenn Sie wissen, was ein Terabyte ist, wird Sie wahrscheinlich die Tatsache beeindrucken, dass Netflix im Jahr 2016 etwa 44 Terabyte Daten in seinem Warehouse hatte. Allein die Größe verdeutlicht, warum wir von einem Warehouse und nicht nur von einer Datenbank sprechen. Beginnen wir also mit den Grundlagen.
Ein Enterprise Data Warehouse (EDW) ist eine Art Unternehmensrepository, das alle historischen Geschäftsdaten eines Unternehmens speichert und verwaltet. Die Informationen stammen in der Regel aus verschiedenen Systemen wie ERPs, CRMs, physischen Aufzeichnungen und anderen flachen Dateien. Um die Daten für die weitere Analyse vorzubereiten, müssen sie in einem einzigen Speicher abgelegt werden. Auf diese Weise können verschiedene Geschäftsbereiche sie abfragen und Informationen aus verschiedenen Blickwinkeln analysieren.
Mit einem Data Warehouse kann ein Unternehmen riesige Datenmengen verwalten, ohne mehrere Datenbanken zu verwalten. Eine solche Praxis ist eine zukunftssichere Art der Datenspeicherung für Business Intelligence (BI), die eine Reihe von Methoden/Technologien zur Umwandlung von Rohdaten in verwertbare Erkenntnisse darstellt. Mit dem EDW als wichtigem Teil davon ist das System vergleichbar mit einem menschlichen Gehirn, das Informationen speichert, aber auf Steroiden.
Enterprise Data Warehouse vs. gewöhnliches Data Warehouse: was ist der Unterschied?
Jedes Data Warehouse ist eine Datenbank, die immer mit Rohdatenquellen über Datenintegrations-Tools auf der einen Seite und analytischen Schnittstellen auf der anderen Seite verbunden ist. Wenn das so ist, warum isolieren wir dann die Unternehmensform für die Diskussion?
Jedes Data Warehouse bietet einen Speicher, der über Mechanismen verfügt, um Daten zu transformieren, zu verschieben und dem Endbenutzer zu präsentieren. Der Unterschied zwischen einem gewöhnlichen Data Warehouse und einem Enterprise Warehouse liegt in der viel größeren architektonischen Vielfalt und Funktionalität. Aufgrund der komplexen Struktur und Größe werden EDWs oft in kleinere Datenbanken unterteilt, so dass die Endbenutzer diese kleineren Datenbanken leichter abfragen können. In Anbetracht dessen konzentrieren wir uns auf ein Enterprise Warehouse, um das gesamte Spektrum der Funktionalität abzudecken.
Die Größe eines Warehouses sagt jedoch nichts über seine technische Komplexität, die Anforderungen an Analyse- und Berichtsfunktionen, die Anzahl der Datenmodelle und die Daten selbst aus. Um also zu verstehen, was ein Warehouse zu einem Warehouse macht, sollten wir uns mit seinen Kernkonzepten und -funktionen befassen.
Enterprise Data Warehouse-Konzepte und -Funktionen
Bei allem Schnickschnack liegen im Herzen eines jeden Warehouses grundlegende Konzepte und Funktionen. Diese Säulen definieren ein Warehouse als technologisches Phänomen:
Es dient als ultimativer Speicher. Ein Enterprise Data Warehouse ist ein einheitliches Repository für alle Geschäftsdaten, die jemals in einem Unternehmen anfallen.
Spiegelt die Quelldaten wider. EDW bezieht Daten aus ihren ursprünglichen Speicherorten wie Google Analytics, CRMs, IoT-Geräten usw. Wenn die Daten über mehrere Systeme verstreut sind, sind sie nicht mehr zu verwalten. Der Zweck von EDW besteht also darin, das Gleiche wie die ursprünglichen Quelldaten in einem einzigen Repository bereitzustellen. Da sowohl innerhalb als auch außerhalb des Unternehmens ständig neue, relevante Daten erzeugt werden, erfordert der Datenfluss eine spezielle Infrastruktur, um die Daten zu verwalten, bevor sie in ein Lagerhaus gelangen.
Speichert strukturierte Daten. Die in einem EDW gespeicherten Daten sind immer standardisiert und strukturiert. Dies ermöglicht es den Endbenutzern, sie über BI-Schnittstellen abzufragen und Berichte zu erstellen. Und genau das unterscheidet ein Data Warehouse von einem Data Lake. Data Lakes dienen der Speicherung unstrukturierter Daten für Analysezwecke. Im Gegensatz zu Warehouses werden Data Lakes jedoch eher von Dateningenieuren/-wissenschaftlern verwendet, um mit großen Mengen an Rohdaten zu arbeiten.
Themenorientierte Daten. Das Hauptaugenmerk eines Warehouses liegt auf Geschäftsdaten, die sich auf verschiedene Bereiche beziehen können. Um zu verstehen, worauf sich die Daten beziehen, werden sie immer um ein bestimmtes Thema herum strukturiert, das als Datenmodell bezeichnet wird. Ein Beispiel für ein Thema kann eine Verkaufsregion oder der Gesamtumsatz eines bestimmten Artikels sein. Zusätzlich werden Metadaten hinzugefügt, um detailliert zu erklären, woher die einzelnen Informationen stammen.
Zeitabhängig. Bei den erfassten Daten handelt es sich in der Regel um historische Daten, da sie vergangene Ereignisse beschreiben. Um zu verstehen, wann und wie lange eine bestimmte Tendenz stattgefunden hat, werden die meisten gespeicherten Daten in Zeiträume unterteilt.
Nicht flüchtig. Einmal in einem Lager abgelegt, werden die Daten nie wieder daraus gelöscht. Die Daten können manipuliert, modifiziert oder aufgrund von Quellenänderungen aktualisiert werden, aber sie sind nie dazu bestimmt, gelöscht zu werden, zumindest nicht von den Endnutzern. Da es sich um historische Daten handelt, sind Löschungen für analytische Zwecke kontraproduktiv. Dennoch kann es alle paar Jahre zu einer generellen Überarbeitung kommen, um irrelevante Daten loszuwerden.
Unter Berücksichtigung der Grundprinzipien werden wir uns die Implementierungsarten von DWs ansehen.
Data-Warehouse-Typen
Unter Berücksichtigung der EDW-Funktionen gibt es immer Raum für Diskussionen, wie es technisch zu gestalten ist. Im Fall der Datenspeicherung und -verarbeitung sind sie spezifisch und unterschiedlich für verschiedene Arten von Unternehmen. Je nach Datenmenge, analytischer Komplexität, Sicherheitsaspekten und Budget gibt es natürlich immer eine Option, wie man sein System aufbaut.
Klassisches Data Warehouse
Als klassische Variante für ein EDW gilt eine einheitliche Speicherung mit eigener Hardware und Software. Bei der physischen Speicherung müssen Sie keine Datenintegrations-Tools zwischen mehreren Datenbanken einrichten. Stattdessen kann das EDW über APIs mit Datenquellen verbunden werden, um Informationen ständig zu beziehen und sie dabei umzuwandeln. Die gesamte Arbeit wird also entweder im Staging-Bereich (dem Ort, an dem die Daten vor dem Laden in das DW umgewandelt werden) oder im Warehouse selbst erledigt.
Ein klassisches Data Warehouse ist einem virtuellen (das wir weiter unten besprechen) überlegen, da es keine zusätzliche Abstraktionsschicht gibt. Es vereinfacht die Arbeit für Dateningenieure und erleichtert die Verwaltung des Datenflusses auf der Vorverarbeitungsseite sowie das eigentliche Reporting. Die Nachteile des klassischen Warehouse hängen von der tatsächlichen Implementierung ab, aber für die meisten Unternehmen sind diese:
- Kostenintensive technologische Infrastruktur, sowohl Hardware als auch Software;
- Ein Team von Dateningenieuren und DevOps-Spezialisten einstellen, um die gesamte Datenplattform einzurichten und zu pflegen.
Wann verwenden: geeignet für Unternehmen jeder Größe, die ihre Daten verarbeiten und nutzen wollen. Klassische Warehouses ermöglichen die Anpassung an verschiedene Architekturen der Datenplattform sowie eine gezielte Auf- und Abwärtsskalierung.
Virtuelles Data Warehouse
Ein virtuelles Data Warehouse ist eine Art von EDW, das als Alternative zu einem klassischen Warehouse verwendet wird. Im Wesentlichen handelt es sich dabei um mehrere Datenbanken, die virtuell miteinander verbunden sind, so dass sie wie ein einziges System abgefragt werden können.
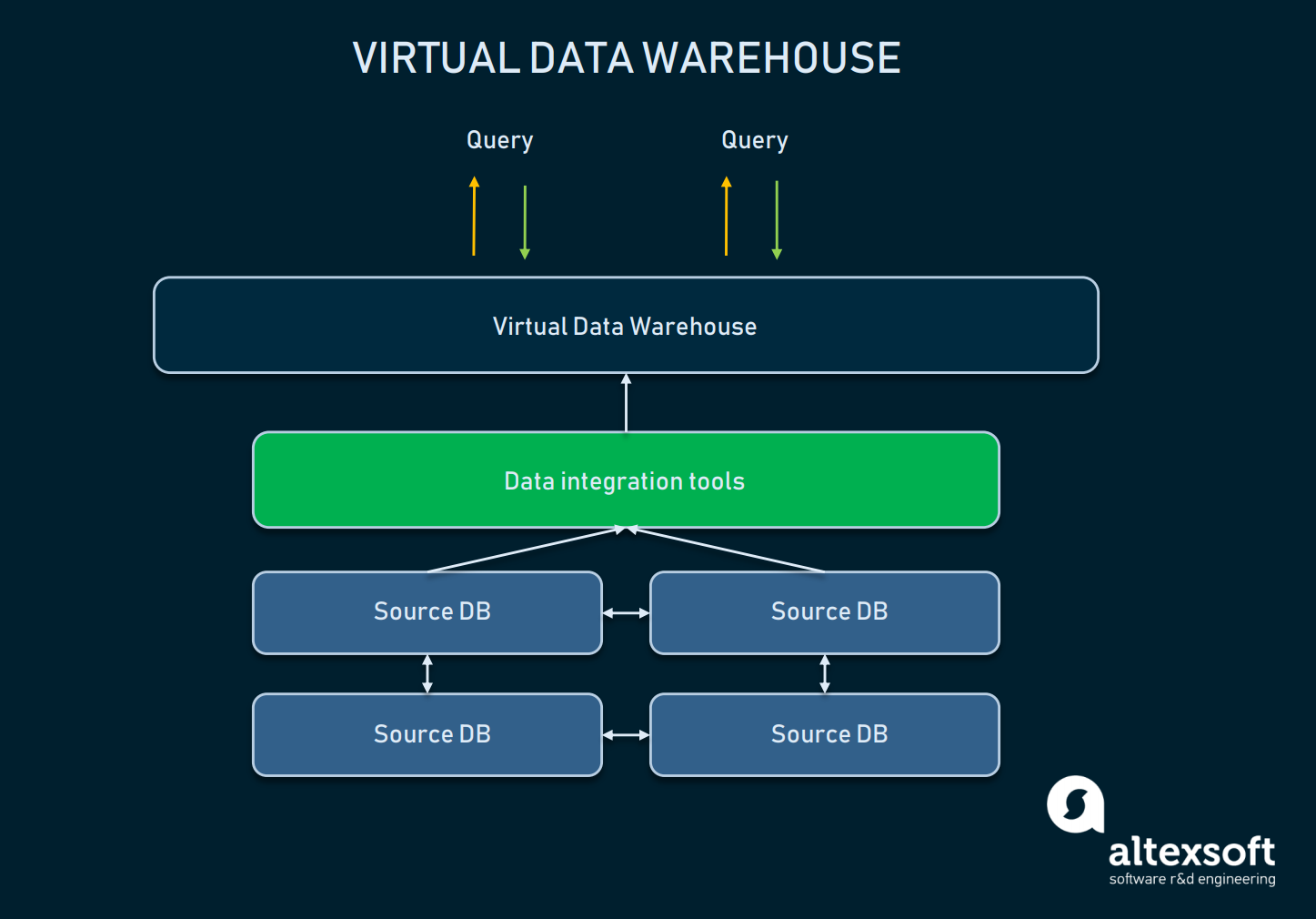
Ein Beziehungsschema zwischen der Abstraktion des virtuellen DW und den Quelldatenbanken
Ein solcher Ansatz ermöglicht es Unternehmen, es einfach zu halten: Die Daten können in ihren Quellen verbleiben, können aber dennoch mit Hilfe von Analysetools abgerufen werden. Virtuelle Lager können verwendet werden, wenn man sich nicht mit der gesamten zugrundeliegenden Infrastruktur herumschlagen möchte oder die vorhandenen Daten ohnehin leicht zu verwalten sind. Ein solcher Ansatz hat jedoch viele Nachteile:
- Mehrere Datenbanken erfordern ständige Software- und Hardware-Wartung und -kosten.
- Die in einem virtuellen DW gespeicherten Daten erfordern immer noch eine Transformationssoftware, um sie für die Endbenutzer und die Berichtstools verdaulich zu machen.
- Komplexe Datenabfragen können zu viel Zeit in Anspruch nehmen, da die benötigten Daten möglicherweise in zwei verschiedenen Datenbanken gespeichert sind.
Wann ist es sinnvoll: Geeignet für Unternehmen, die über Rohdaten in standardisierter Form verfügen, die keine komplexen Analysen erfordern. Es eignet sich auch für Unternehmen, die BI nicht systematisch nutzen oder damit beginnen wollen.
Cloud Data Warehouse
Seit einem Jahrzehnt sind Cloud/Cloudless-Technologien zum Standard für die Einrichtung von Technologien auf Unternehmensebene geworden. Es gibt unzählige Anbieter auf dem Markt, die Warehousing-as-a-Service anbieten. Um ein paar zu nennen:
- Amazon Redshift/ Preisseite
- IBM Db2/ Preisseite
- Google BigQuery/ Preisseite
- Snowflake/ Preisseite
- Microsoft SQL Data Warehouse/ Preisseite
Alle genannten Anbieter bieten voll gemanagte, skalierbares Warehousing als Teil ihrer BI-Tools an oder konzentrieren sich auf EDW als eigenständigen Service, wie es Snowflake tut. In diesem Fall hat die Cloud-Warehouse-Architektur die gleichen Vorteile wie jeder andere Cloud-Service. Die Infrastruktur wird für Sie gewartet, d. h. Sie müssen keine eigenen Server, Datenbanken und Tools für die Verwaltung einrichten. Der Preis für einen solchen Dienst hängt von der benötigten Speichermenge und den Rechenkapazitäten für Abfragen ab.
Der einzige Aspekt, der Ihnen bei einer Cloud-Warehouse-Plattform Sorgen bereiten könnte, ist die Datensicherheit. Ihre Geschäftsdaten sind eine sensible Sache. Daher sollten Sie prüfen, ob der Anbieter, den Sie ausgewählt haben, vertrauenswürdig ist und Verstöße vermeiden kann. Das bedeutet nicht unbedingt, dass ein On-Premise-Lager sicherer ist, aber in diesem Fall liegt die Sicherheit Ihrer Daten in Ihren Händen.
Wann nutzen: Cloud-Plattformen sind eine gute Wahl für Unternehmen jeder Größe. Wenn Sie alles für sich einrichten lassen möchten, einschließlich verwalteter Datenintegration, DW-Wartung und BI-Support.
Enterprise Data Warehouse Architecture
Es gibt zwar viele architektonische Ansätze, die die Warehouse-Funktionen auf die eine oder andere Weise erweitern, aber wir werden uns auf die wichtigsten konzentrieren. Ohne zu sehr ins technische Detail zu gehen, kann die gesamte Datenpipeline in drei Schichten unterteilt werden:
- Rohdatenschicht (Datenquellen)
- Warehouse und sein Ökosystem
- Benutzerschnittstelle (Analysewerkzeuge)
Die Werkzeuge, die sich mit der Extraktion, Transformation und dem Laden von Daten in ein Warehouse befassen, sind eine eigene Kategorie von Werkzeugen, die als ETL bekannt sind. Unter dem Dach von ETL führen Datenintegrations-Tools auch Manipulationen mit Daten durch, bevor sie in ein Warehouse gestellt werden. Diese Tools arbeiten zwischen einer Rohdatenebene und einem Warehouse.
Wenn die Daten in ein Warehouse geladen werden, können sie auch transformiert werden. Das Warehouse benötigt also bestimmte Funktionen zur Bereinigung/Standardisierung/Dimensionalisierung. Diese und andere Faktoren werden die Komplexität der Architektur bestimmen. Wir werden die EDW-Architektur unter dem Gesichtspunkt der wachsenden organisatorischen Anforderungen betrachten.
Einschichtige Architektur
Wenn die Datenintegration gut konfiguriert ist, können wir unser Data Warehouse wählen. In den meisten Fällen handelt es sich bei einem Data Warehouse um eine relationale Datenbank mit Modulen, die multidimensionale Daten ermöglichen, oder um eine Datenbank, die einige bereichsspezifische Informationen für einen leichteren Zugriff abtrennen kann. In seiner primitivsten Form kann ein Data Warehouse nur eine einstufige Architektur haben.
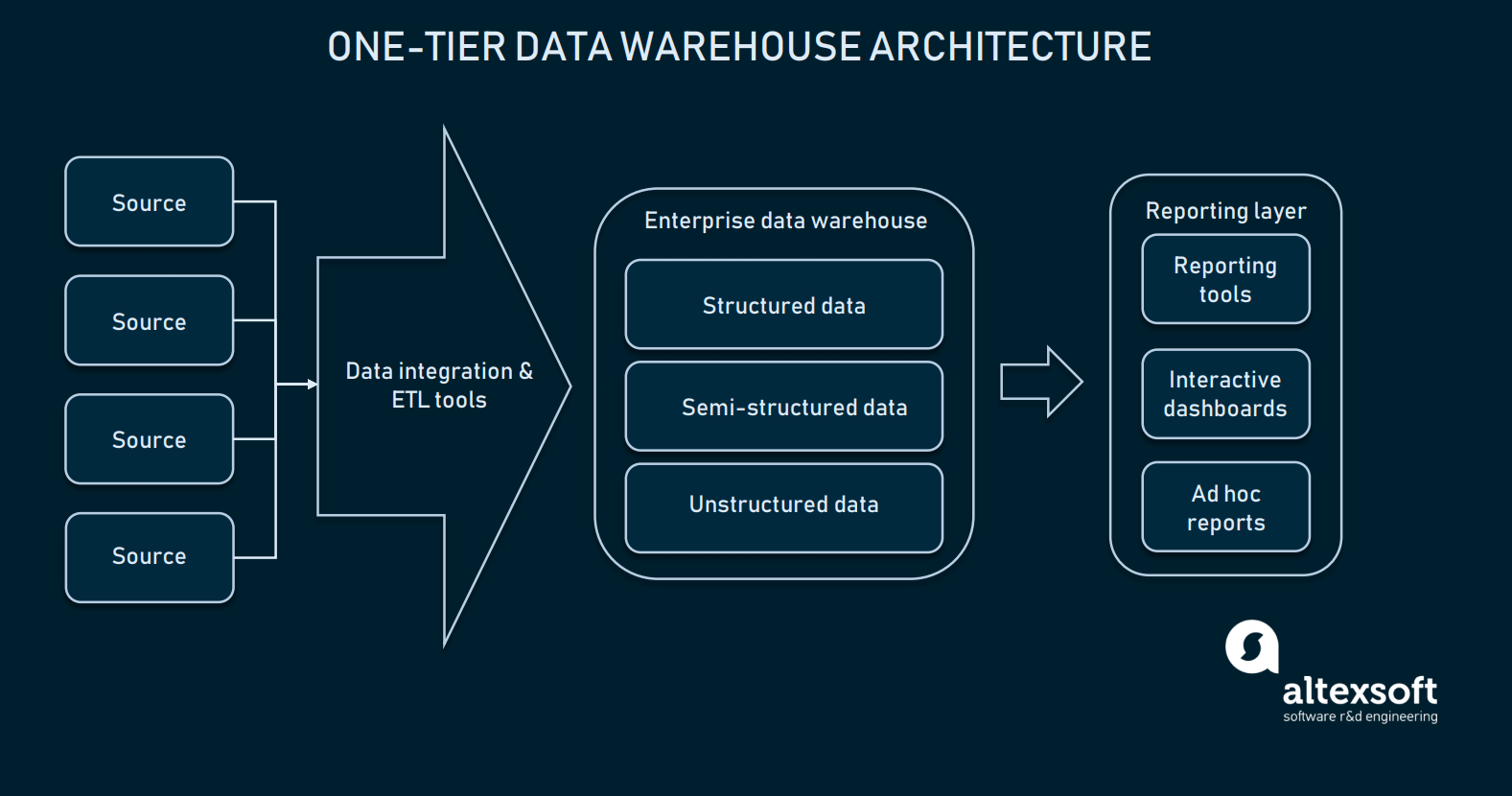
Die Berichterstattungsschicht ist direkt mit der gesamten Datenbank des EDW verbunden
Einstufige Architektur für EDW bedeutet, dass eine Datenbank direkt mit den analytischen Schnittstellen verbunden ist, über die der Endbenutzer Abfragen durchführen kann. Die direkte Verbindung zwischen einem EDW und Analysetools bringt mehrere Herausforderungen mit sich:
- Traditionell kann man seinen Speicher ab 100 GB Daten als Warehouse betrachten. Die direkte Arbeit damit kann zu unübersichtlichen Abfrageergebnissen sowie zu einer geringen Verarbeitungsgeschwindigkeit führen.
- Die Abfrage von Daten direkt aus dem DW kann eine präzise Eingabe erfordern, damit das System in der Lage ist, nicht benötigte Daten herauszufiltern. Das macht den Umgang mit Präsentationstools etwas schwierig.
- Eine begrenzte Flexibilität/Analysefähigkeit ist vorhanden.
Außerdem setzt die einstufige Architektur der Komplexität des Berichtswesens gewisse Grenzen. Ein solcher Ansatz wird wegen seiner Langsamkeit und Unvorhersehbarkeit selten für große Datenplattformen verwendet. Um fortgeschrittene Datenabfragen durchzuführen, kann ein Warehouse mit Low-Level-Instanzen erweitert werden, die den Zugriff auf die Daten erleichtern.
Zweischichtige Architektur (Data-Mart-Schicht)
In der zweischichtigen Architektur wird eine Data-Mart-Ebene zwischen der Benutzeroberfläche und dem EDW hinzugefügt. Ein Data Mart ist ein Low-Level-Repository, das bereichsspezifische Informationen enthält. Einfach ausgedrückt, handelt es sich um eine weitere, kleinere Datenbank, die das EDW um spezielle Informationen für Ihre Vertriebs-/Betriebsabteilungen, Marketing usw. erweitert.
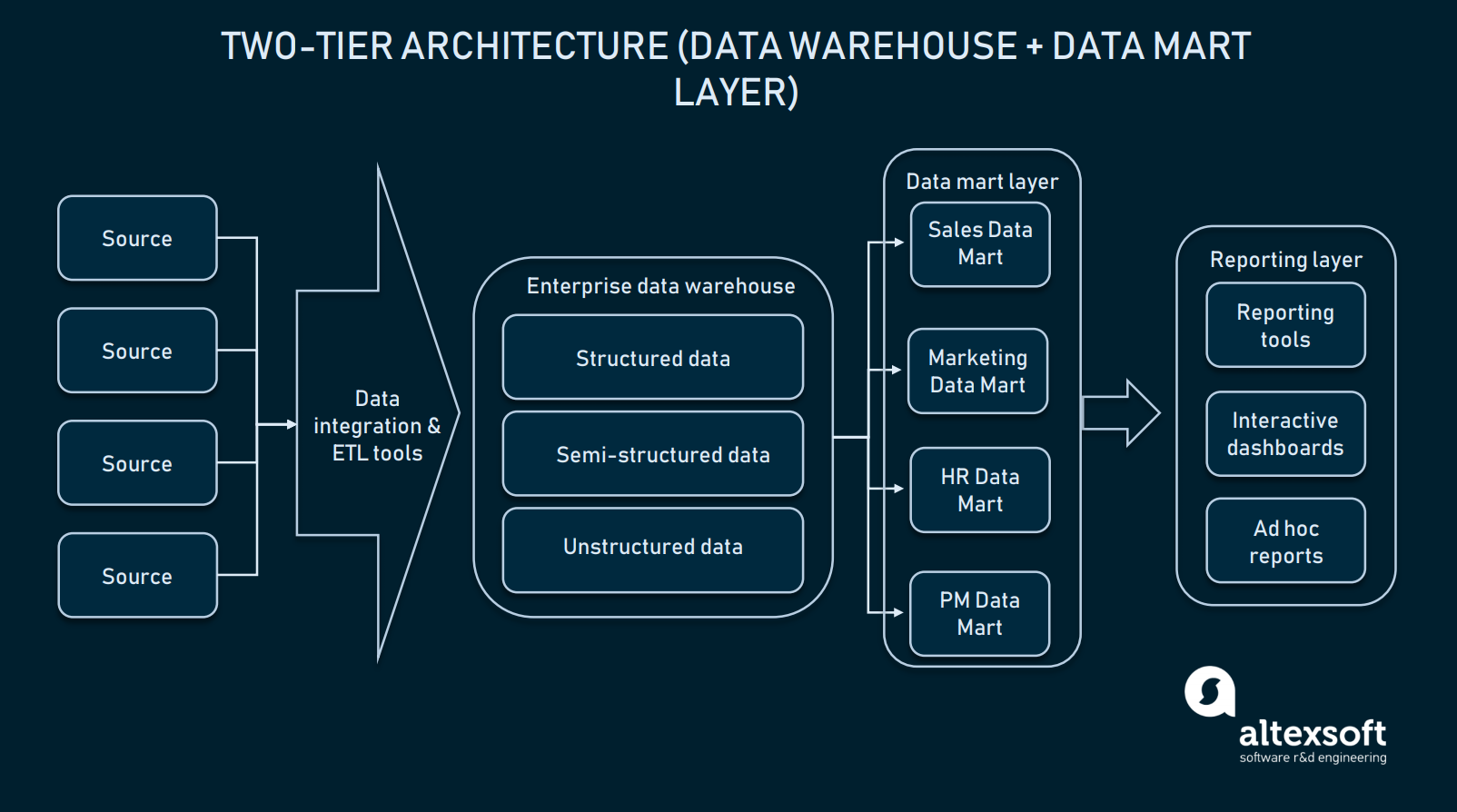
In der zweistufigen Architektur wird ein EDW durch Data Marts erweitert, um bereichsspezifische Daten bereitzustellen
Die Schaffung einer Data-Mart-Ebene erfordert zusätzliche Ressourcen für die Einrichtung der Hardware und die Integration dieser Datenbanken mit der übrigen Datenplattform. Aber ein solcher Ansatz löst das Problem der Abfrage: Jede Abteilung wird leichter auf die benötigten Daten zugreifen können, da ein bestimmter Mart nur bereichsspezifische Informationen enthält. Darüber hinaus schränken Data Marts den Datenzugriff für Endbenutzer ein und machen EDW sicherer.
Dreischichtige Architektur (Online analytical processing)
Zusätzlich zur Data Mart-Schicht verwenden Unternehmen auch Online Analytical Processing (OLAP) Cubes. Ein OLAP-Würfel ist eine spezielle Art von Datenbank, die Daten aus mehreren Dimensionen darstellt. Während relationale Datenbanken Daten in nur zwei Dimensionen darstellen (denken Sie an Excel oder Google Sheets), ermöglicht OLAP die Zusammenstellung von Daten in mehreren Dimensionen und den Wechsel zwischen den Dimensionen.
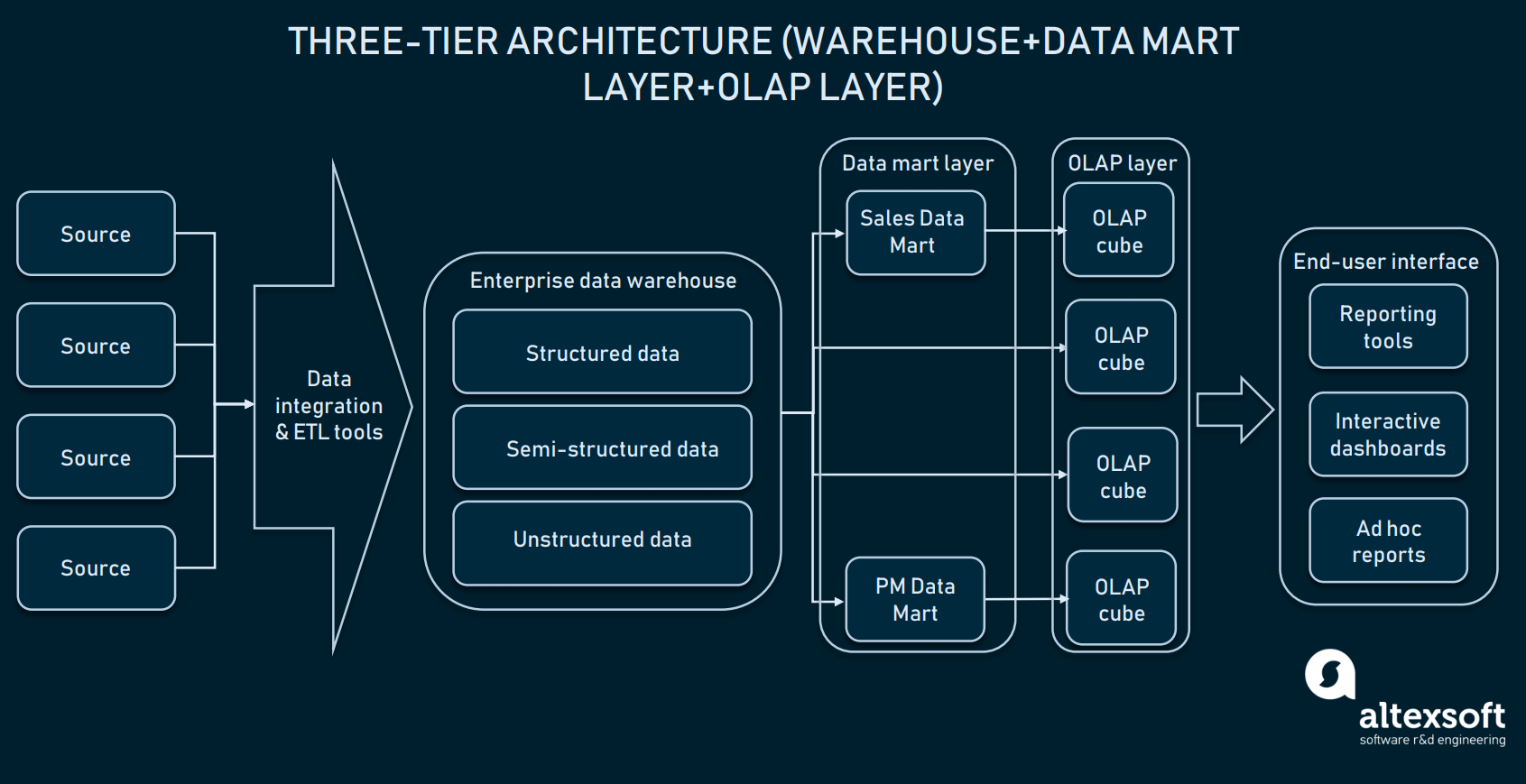
OLAP-Würfel können Informationen aus verteilten Marts oder direkt aus dem EDW beziehen
Es ist ziemlich schwierig, dies in Worten zu erklären, also sehen wir uns dieses praktische Beispiel dafür an, wie ein Würfel aussehen kann.
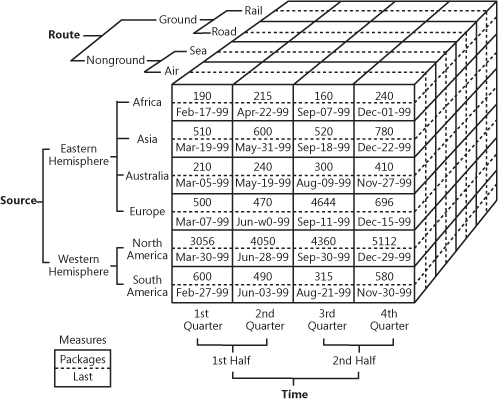
OLAP-Würfel, der mehrdimensionale Verkaufsdaten zeigt
Quelle: oreilly.com
Wie Sie sehen können, fügt ein Würfel den Daten Dimensionen hinzu. Sie können ihn sich wie mehrere miteinander kombinierte Excel-Tabellen vorstellen. Die Vorderseite des Würfels ist die übliche zweidimensionale Tabelle, in der die Region (Afrika, Asien usw.) vertikal angegeben wird, während die Verkaufszahlen und Daten horizontal geschrieben werden. Die Magie beginnt, wenn wir uns die obere Facette des Würfels ansehen, wo die Verkäufe nach Routen segmentiert sind und die untere Facette den Zeitraum angibt. Das nennt man multidimensionale Daten.
Der geschäftliche Nutzen von OLAP besteht darin, dass die Benutzer die Daten zerschneiden und aufteilen können, um detaillierte Berichte zu erstellen. Solange die Cubes für die Arbeit mit Warehouses optimiert sind, können sie sowohl direkt mit einem EDW verwendet werden, um Zugang zu allen Unternehmensdaten zu erhalten, als auch mit jedem Data Mart speziell. Was die Implementierung betrifft, so bieten fast alle Warehouse-Anbieter OLAP als Service an. Ein Beispiel hierfür ist die Dokumentation von Microsoft zu ihrem OLAP-Angebot.
Damit haben wir ein High-Level-Design eines EDW für die Bedürfnisse eines Unternehmens erörtert. Jetzt werden wir uns mit den technischen Komponenten befassen, die ein Warehouse umfassen kann.
Data Warehouse vs. Data Lake vs. Data Mart
Wenn wir über die Architektur der Datenspeicherung sprechen, müssen wir auch die Optionen erwähnen, die ein Data Mart oder ein Data Lake anstelle eines Warehouse bieten. Da sie häufig miteinander verwechselt werden, erläutern wir die Definitionen.
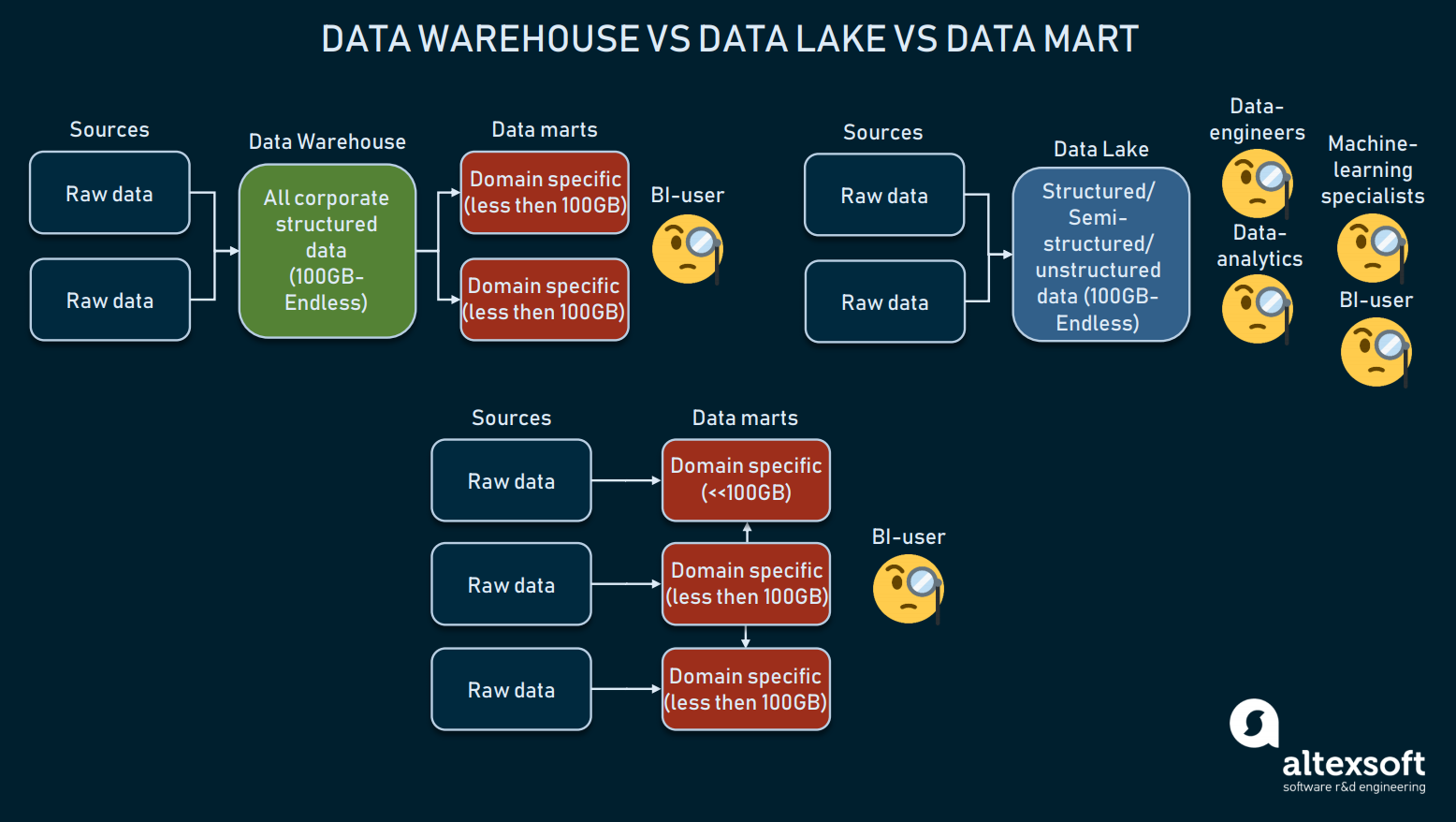
Der Vergleich dreier Formen der Datenspeicherung
Data Warehouses sind dazu gedacht, strukturierte Daten zu speichern, so dass Abfragetools und Endbenutzer umfassende Ergebnisse erhalten können. Warehouses, die meist für BI verwendet werden, variieren in der Regel in der Größe zwischen 100 GB und unendlich.
Data Lakes hingegen werden verwendet, um hauptsächlich Rohdaten oder gemischte Daten zu speichern. Diese werden oft für maschinelles Lernen, Big Data oder Data Mining genutzt. In den letzten Jahren wurden Data Lakes für BI verwendet: Rohdaten werden in einen See geladen und transformiert, was eine Alternative zum ETL-Prozess darstellt. Dieser Ansatz hat zwar seine Vor- und Nachteile, aber Data Lakes können zu unübersichtlich sein, um strukturierte Daten zu erreichen.
Dann gibt es Data Marts, die ebenfalls als Alternative zu DW verwendet werden können. Solche Modelle (wie das Modell von Kimball) gehen davon aus, dass mehrere Data Marts verwendet werden, um die Informationen nach Domänen zu verteilen und miteinander zu verbinden. Aufgrund ihrer geringen Größe (in der Regel weniger als 100 GB) können Data Marts jedoch kaum von Unternehmen genutzt werden. Häufiger werden Data Marts verwendet, um ein großes DW in mehrere funktionsfähige DWs zu unterteilen.
Enterprise Data Warehouse-Komponenten
Es gibt eine Vielzahl von Instrumenten, die zum Aufbau einer Warehousing-Plattform verwendet werden. Die meisten davon haben wir bereits erwähnt, auch das Warehouse selbst. Sehen wir uns also den Zweck der einzelnen Komponenten und ihre Funktionen aus der Vogelperspektive an.
Quellen. Ganz einfach, die Datenbanken, in denen die Rohdaten gespeichert sind.
Extract, Transform, Load (ETL) oder Extract, Load, Transform (ELT) Layer. Dies sind die Werkzeuge, die die eigentliche Verbindung mit den Quelldaten, ihre Extraktion und das Laden an den Ort, an dem sie transformiert werden, durchführen. Die Transformation vereinheitlicht das Datenformat. ETL- und ELT-Ansätze unterscheiden sich darin, dass bei ETL die Transformation vor der EDW in einem Staging-Bereich erfolgt. ELT ist ein modernerer Ansatz, bei dem die gesamte Transformation in einem Warehouse erfolgt.
Staging Area. Im Falle von ETL ist der Staging-Bereich der Ort, an dem die Daten vor dem EDW geladen werden. Hier werden sie bereinigt und in ein bestimmtes Datenmodell transformiert. Der Staging-Bereich kann auch Werkzeuge für das Datenqualitätsmanagement enthalten.
DW-Datenbank. Die Daten werden schließlich in den Speicherbereich geladen. In ELT kann es hier noch zu einer Transformation kommen. In diesem Stadium werden jedoch alle allgemeinen Änderungen vorgenommen, so dass die Daten in ihr(e) endgültige(s) Modell(e) geladen werden. Wie wir bereits erwähnt haben, handelt es sich bei Data Warehouses meist um relationale Datenbanken. DW umfassen auch ein Datenbankmanagementsystem und zusätzlichen Speicher für Metadaten.
Metadatenmodul. Vereinfacht gesagt, sind Metadaten Daten über Daten. Das sind die Erklärungen, die dem Benutzer/Administrator Hinweise geben, auf welches Thema/Domäne sich diese Informationen beziehen. Bei diesen Daten kann es sich um technische Metadaten (z. B. die ursprüngliche Quelle) oder um geschäftliche Metadaten (z. B. das Verkaufsgebiet) handeln. Alle Metadaten werden in einem separaten Modul des EDW gespeichert und von einem Metadatenmanager verwaltet.
Berichtsschicht. Hierbei handelt es sich um Werkzeuge, die den Endnutzern den Zugang zu den Daten ermöglichen. Diese Schicht wird auch als BI-Schnittstelle bezeichnet und dient als Dashboard zur Visualisierung von Daten, zur Erstellung von Berichten und zum Abrufen einzelner Informationen.
Abschließende Überlegung
Das Verständnis der Kette von Werkzeugen, die Daten weiterleiten, kann Ihnen dabei helfen, herauszufinden, was Ihren Anforderungen an die Datenplattform tatsächlich entspricht. Die Einrichtung eines Data Warehouse kann Jahre der Planung und des Testens in Anspruch nehmen, da es sich um ein sehr umfangreiches Projekt handelt.
Als Unternehmer sind Sie vielleicht verwirrt von der Anzahl der Optionen und Technologien, die verwendet werden, daher ist es wichtig, dass Sie sich mit Experten im Bereich Warehousing, ETL und BI beraten. Experten können Ihnen zwar bei den technischen Aspekten helfen, aber um den Geschäftszweck zu definieren, sollten Sie mit denjenigen sprechen, die die Daten bei ihrer Arbeit tatsächlich verwenden werden.