




Kaputte Pakete: IP-Fragmentierung ist fehlerhaft
Im Gegensatz zum öffentlichen Telefonnetz ist das Internet paketvermittelt aufgebaut. Aber wie groß können diese Pakete sein?
 CC BY 2.0 image by ajmexico, inspired by
CC BY 2.0 image by ajmexico, inspired by
Dies ist eine alte Frage, und die IPv4 RFCs beantworten sie ziemlich klar. Die Idee war, das Problem in zwei separate Anliegen aufzuteilen:
-
Was ist die maximale Paketgröße, die von den Betriebssystemen auf beiden Seiten verarbeitet werden kann?
-
Was ist die maximal zulässige Datagrammgröße, die sicher durch die physischen Verbindungen zwischen den Hosts geschoben werden kann?
Wenn ein Paket zu groß für eine physische Verbindung ist, kann ein zwischengeschalteter Router es in mehrere kleinere Datagramme zerlegen, damit es passt. Dieser Vorgang wird als „Vorwärts-IP-Fragmentierung“ bezeichnet, und die kleineren Datagramme werden IP-Fragmente genannt.
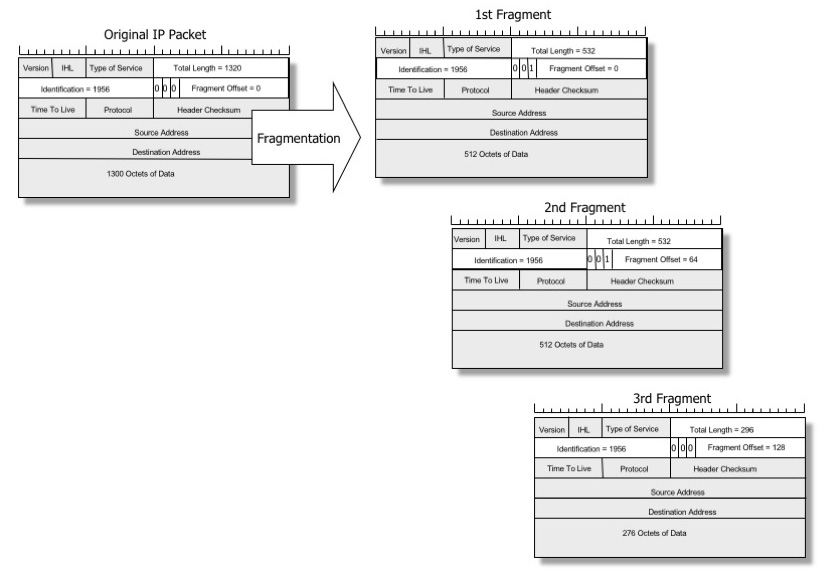 Bild von Geoff Huston, reproduziert mit Genehmigung
Bild von Geoff Huston, reproduziert mit Genehmigung
Die IPv4-Spezifikation definiert die Mindestanforderungen. Aus dem RFC791:
Every internet destination must be able to receive a datagramof 576 octets either in one piece or in fragments tobe reassembled. Every internet module must be able to forward a datagram of 68octets without further fragmentation. Der erste Wert – die erlaubte Größe des wieder zusammengesetzten Pakets – ist normalerweise nicht problematisch. IPv4 definiert das Minimum mit 576 Bytes, aber gängige Betriebssysteme können mit sehr großen Paketen umgehen, typischerweise bis zu 65KiB.
Der zweite Wert ist problematischer. Alle physischen Verbindungen haben inhärente Größenbeschränkungen für Datagramme, abhängig von dem spezifischen Medium, das sie verwenden. Frame Relay zum Beispiel kann Datagramme zwischen 46 und 4.470 Bytes senden. ATM verwendet feste 53 Bytes, klassisches Ethernet kann zwischen 64 und 1500 Bytes senden.
Die Spezifikation definiert die Mindestanforderung – jede physikalische Verbindung muss Datagramme von mindestens 68 Bytes übertragen können. Für IPv6 wurde dieser Mindestwert auf 1280 Byte erhöht (siehe RFC2460).
Die maximale Datagrammgröße, die ohne Fragmentierung übertragen werden kann, ist dagegen in keiner Spezifikation festgelegt und variiert je nach Verbindungstyp. Dieser Wert wird MTU (Maximum Transmission Unit) genannt.
Die MTU definiert eine maximale Datagrammgröße auf einer lokalen physikalischen Verbindung. Das Internet besteht aus inhomogenen Netzen, und auf dem Weg zwischen zwei Hosts kann es Verbindungen mit kürzeren MTU-Werten geben. Die maximale Paketgröße, die ohne Fragmentierung zwischen zwei entfernten Hosts übertragen werden kann, wird als Pfad-MTU bezeichnet und kann für jede Verbindung unterschiedlich sein.
Fragmentierung vermeiden
Man könnte meinen, dass es in Ordnung ist, Anwendungen zu entwickeln, die sehr große Pakete übertragen und sich auf Router verlassen, die die IP-Fragmentierung durchführen. Das ist keine gute Idee. Die Probleme mit diesem Ansatz wurden erstmals 1987 von Kent und Mogul diskutiert. Hier ein paar Schlaglichter:
-
Um ein Paket erfolgreich wieder zusammenzusetzen, müssen alle Fragmente zugestellt werden. Kein Fragment kann beschädigt werden oder während des Fluges verloren gehen. Es gibt einfach keine Möglichkeit, die andere Partei über fehlende Fragmente zu informieren!
-
Das letzte Fragment wird fast nie die optimale Größe haben. Bei großen Übertragungen bedeutet dies, dass ein erheblicher Teil des Datenverkehrs aus suboptimalen kurzen Datagrammen besteht – eine Verschwendung wertvoller Router-Ressourcen.
-
Vor dem erneuten Zusammensetzen muss ein Host partielle, fragmentierte Datagramme im Speicher halten. Dies eröffnet die Möglichkeit für Speichererschöpfungsangriffe.
-
Nachfolgenden Fragmenten fehlt der Header der höheren Schicht. Der TCP- oder UDP-Header ist nur im ersten Fragment vorhanden. Dies macht es für Firewalls unmöglich, Fragment-Datagramme anhand von Kriterien wie Quell- oder Zielport zu filtern.
Eine ausführlichere Beschreibung der IP-Fragmentierungsprobleme findet sich in diesen Artikeln von Geoff Huston:
- Evaluating IPv4 and IPv6 packet fragmentation
- Fragmenting IPv6
Don’t fragment – ICMP Packet too big
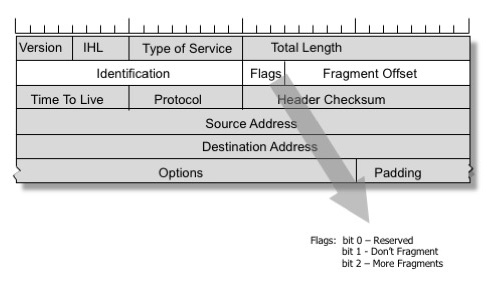
Image by Geoff Huston, reproduced with permission
Eine Lösung für diese Probleme wurde in das IPv4 Protokoll aufgenommen. Ein Absender kann das DF-Flag (Don’t Fragment) im IP-Header setzen und damit die zwischengeschalteten Router auffordern, ein Paket niemals zu fragmentieren. Stattdessen sendet ein Router mit einer Verbindung, die eine kleinere MTU hat, eine ICMP-Meldung „zurück“ und informiert den Absender, die MTU für diese Verbindung zu verringern.
Das TCP-Protokoll setzt das DF-Flag immer. Der Netzwerk-Stack achtet sorgfältig auf eingehende „Packet too big“-ICMP-Meldungen und verfolgt das Merkmal „path MTU“ für jede Verbindung. Diese Technik wird „Path MTU Discovery“ genannt und wird meist für TCP verwendet, obwohl sie auch auf andere IP-basierte Protokolle angewendet werden kann. Die Fähigkeit, die ICMP-Meldungen „Paket zu groß“ auszuliefern, ist entscheidend dafür, dass der TCP-Stack optimal funktioniert.
Wie das Internet tatsächlich funktioniert
In einer perfekten Welt würden die mit dem Internet verbundenen Geräte zusammenarbeiten und fragmentierte Datagramme und die zugehörigen ICMP-Pakete korrekt behandeln. In der Realität werden IP-Fragmente und ICMP-Pakete jedoch sehr oft herausgefiltert.
Das liegt daran, dass das moderne Internet viel komplexer ist als vor 36 Jahren angenommen. Heute ist im Grunde niemand mehr direkt mit dem öffentlichen Internet verbunden.
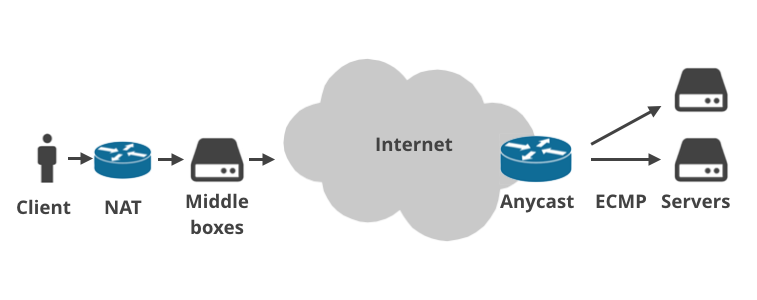
Kundengeräte werden über Heimrouter angeschlossen, die NAT (Network Address Translation) betreiben und in der Regel Firewall-Regeln durchsetzen. Immer häufiger befindet sich mehr als eine NAT-Installation auf dem Paketpfad (z. B. Carrier-Grade-NAT). Dann treffen die Pakete auf die ISP-Infrastruktur, wo es ISP-„Vermittlungsstellen“ gibt. Diese führen alle möglichen merkwürdigen Dinge mit dem Datenverkehr durch: Sie setzen Tarifobergrenzen durch, drosseln Verbindungen, führen Protokollierungen durch, entführen DNS-Anfragen, setzen staatlich verordnete Website-Sperren um, erzwingen transparentes Caching oder „optimieren“ den Datenverkehr auf andere magische Weise. Die Middleboxen werden vor allem von Mobilfunkanbietern genutzt.
Auch zwischen einem Server und dem öffentlichen Internet gibt es oft mehrere Schichten. Dienstanbieter verwenden manchmal Anycast BGP-Routing. Das bedeutet, dass sie dieselben IP-Bereiche von mehreren physischen Standorten in der ganzen Welt aus bearbeiten. Innerhalb eines Rechenzentrums hingegen wird zunehmend ECMP Equal Cost Multi Path für den Lastausgleich verwendet.
Jede dieser Schichten zwischen einem Client und einem Server kann ein Path MTU-Problem verursachen. Erlauben Sie mir, dies anhand von vier Szenarien zu veranschaulichen.
1. Client -> Server DF+ / ICMP
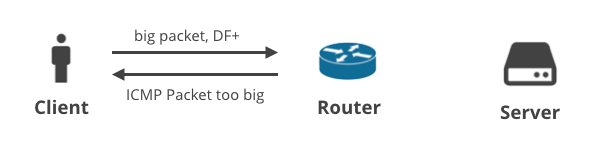
Im ersten Szenario lädt ein Client einige Daten per TCP auf den Server hoch, so dass das DF-Flag in allen Paketen gesetzt ist. Wenn der Client keine geeignete MTU vorhersagen kann, verwirft ein zwischengeschalteter Router die großen Pakete und sendet eine ICMP-Benachrichtigung „Packet too big“ an den Client zurück. Diese ICMP-Pakete können durch falsch konfigurierte NAT-Geräte des Kunden oder ISP-Middle-Boxen verworfen werden.
Nach dem Papier von Maikel de Boer und Jeffrey Bosma aus dem Jahr 2012 blockieren etwa 5 % der IPv4- und 1 % der IPv6-Hosts eingehende ICMP-Pakete.
Meine Erfahrung bestätigt dies. ICMP-Nachrichten werden in der Tat oft aus vermeintlichen Sicherheitsgründen verworfen, aber das ist relativ leicht zu beheben. Ein größeres Problem gibt es bei bestimmten mobilen ISPs mit seltsamen Middleboxen. Diese ignorieren ICMP oft vollständig und führen ein sehr aggressives Rewriting von Verbindungen durch. Orange Polska zum Beispiel ignoriert nicht nur eingehende ICMP-Meldungen „Paket zu groß“, sondern schreibt auch den Verbindungsstatus um und klemmt die MSS auf nicht verhandelbare 1344 Bytes.
2. Client -> Server DF- / Fragmentierung
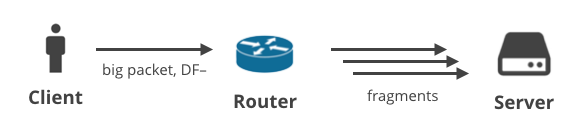
Im nächsten Szenario lädt ein Client einige Daten mit einem anderen Protokoll als TCP hoch, bei dem das DF-Flag gelöscht ist. Dies könnte zum Beispiel ein Benutzer sein, der ein Spiel mit UDP spielt oder ein Telefongespräch führt. Die großen ausgehenden Pakete könnten an irgendeinem Punkt des Pfades fragmentiert werden.
Wir können dies emulieren, indem wir ping mit einer großen Nutzlast starten:
$ ping -s 2048 facebook.comDieses spezielle ping wird bei Nutzlasten von mehr als 1472 Bytes fehlschlagen. Jede größere Größe wird fragmentiert und kann nicht ordnungsgemäß zugestellt werden. Es gibt mehrere Gründe, warum Server Fragmente falsch handhaben können, aber eines der häufigsten Probleme ist die Verwendung von ECMP-Lastausgleich. Aufgrund des ECMP-Hashings ist es wahrscheinlich, dass das erste Datagramm, das einen Protokoll-Header enthält, einem anderen Server zugewiesen wird als die restlichen Fragmente, wodurch der Zusammenbau verhindert wird.
Eine ausführlichere Diskussion dieses Problems finden Sie unter:
- Unser früherer Bericht über ECMP.
- Wie Google versucht, ECMP-Fragmentierungsprobleme mit Maglev L4 Load Balancer zu lösen.
Außerdem ist die Fehlkonfiguration von Servern und Routern ein bedeutendes Problem. Laut RFC7852 verwerfen zwischen 30% und 55% der Server IPv6-Datagramme, die einen Fragmentierungs-Header enthalten.
3. Server -> Client DF+ / ICMP
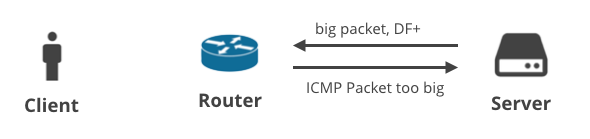
Das nächste Szenario handelt von einem Client, der Daten über TCP herunterlädt. Wenn der Server die korrekte MTU nicht vorhersagen kann, sollte er eine ICMP-Meldung „Packet too big“ erhalten. Einfach, nicht wahr?
Dummerweise ist das nicht der Fall, wieder wegen des ECMP-Routings. Die ICMP-Meldung wird höchstwahrscheinlich an den falschen Server geliefert – der 5-Tupel-Hash des ICMP-Pakets stimmt nicht mit dem 5-Tupel-Hash der problematischen Verbindung überein. Wir haben in der Vergangenheit über dieses Problem geschrieben und einen einfachen Userspace-Daemon entwickelt, um es zu lösen. Er funktioniert, indem er die eingehende ICMP-Meldung „Paket zu groß“ an alle ECMP-Server sendet, in der Hoffnung, dass derjenige mit der problematischen Verbindung sie sieht.
Außerdem kann das ICMP-Paket aufgrund des Anycast-Routings an das falsche Rechenzentrum geliefert werden! Das Internet-Routing ist oft asymmetrisch, und der beste Pfad von einem zwischengeschalteten Router könnte die ICMP-Pakete an den falschen Ort leiten.
Fehlende ICMP-Benachrichtigungen „Paket zu groß“ können dazu führen, dass Verbindungen abgewürgt werden und die Zeit abläuft. Dies wird oft als PMTU-Blackhole bezeichnet. Um diesen pessimistischen Fall zu unterstützen, implementiert Linux eine Abhilfe – MTU Probing RFC4821. MTU Probing versucht, automatisch Pakete zu identifizieren, die aufgrund einer falschen MTU verworfen wurden, und verwendet Heuristiken, um diese zu optimieren. Diese Funktion wird über eine sysctl gesteuert:
$ echo 1 > /proc/sys/net/ipv4/tcp_mtu_probingAber MTU Probing ist nicht unproblematisch. Erstens neigt sie dazu, überlastungsbedingte Paketverluste falsch als MTU-Probleme zu kategorisieren. Lang laufende Verbindungen haben in der Regel eine reduzierte MTU. Zweitens implementiert Linux kein MTU Probing für IPv6.
4. Server -> Client DF- / Fragmentierung
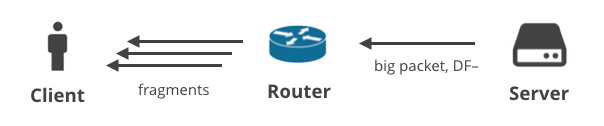
Schließlich gibt es eine Situation, in der der Server große Pakete über ein Nicht-TCP-Protokoll mit deaktiviertem DF-Bit sendet. In diesem Szenario werden die großen Pakete auf dem Weg zum Client fragmentiert. Diese Situation lässt sich am besten anhand großer DNS-Antworten veranschaulichen. Hier sind zwei DNS-Anfragen, die große Antworten erzeugen und dem Client als mehrere IP-Fragmente zugestellt werden:
$ dig +notcp +dnssec DNSKEY org @199.19.56.1$ dig +notcp +dnssec DNSKEY org @2001:500:f::1Diese Anfragen können aufgrund des bereits erwähnten falsch konfigurierten Heimrouters, fehlerhaften NAT, fehlerhaften ISP-Installationen oder zu restriktiven Firewall-Einstellungen fehlschlagen.
Boer und Bosma zufolge blockieren etwa 6 % der IPv4- und 10 % der IPv6-Hosts eingehende Fragment-Datagramme.
Hier sind einige Links mit mehr Informationen über die spezifischen Fragmentierungsprobleme, die DNS betreffen:
- DNS-OARC Reply Size Test
- IPv6, große UDP-Pakete und DNS
Das Internet funktioniert trotzdem!
Wie kann es sein, dass das Internet immer noch funktioniert, wenn all diese Dinge schief gehen?
 CC BY-SA 3.0, Quelle: Wikipedia
CC BY-SA 3.0, Quelle: Wikipedia
Das liegt vor allem an dem Erfolg von Ethernet. Die überwiegende Mehrheit der Verbindungen im öffentlichen Internet sind Ethernet (oder davon abgeleitet) und unterstützen die MTU von 1500 Bytes.
Wenn Sie blindlings von der MTU von 1500 ausgehen, werden Sie überrascht sein, wie oft es einfach funktioniert. Das Internet funktioniert vor allem deshalb, weil wir alle eine MTU von 1500 verwenden und nur selten IP-Fragmentierung und ICMP-Nachrichten senden müssen.
Dies funktioniert nicht mehr bei einer ungewöhnlichen Konfiguration mit Verbindungen, die eine nicht standardmäßige MTU haben. VPNs und andere Netzwerktunnelsoftware müssen darauf achten, dass die Fragmentierung und ICMP-Nachrichten einwandfrei funktionieren.
Dies ist besonders in der IPv6-Welt zu beobachten, in der sich viele Benutzer durch Tunnel verbinden. Ein gesunder ICMP-Durchgang in beide Richtungen ist sehr wichtig, vor allem, da die Fragmentierung in IPv6 grundsätzlich nicht funktioniert (wir haben zwei Quellen zitiert, die behaupten, dass zwischen 10 und 50 % der IPv6-Hosts den IPv6-Fragment-Header blockieren).
Da die Path-MTU-Probleme in IPv6 so häufig sind, beschränken viele IPv6-Server die Path-MTU auf das vom Protokoll vorgeschriebene Minimum von 1280 Byte. Dieser Ansatz tauscht ein wenig Leistung gegen beste Zuverlässigkeit.
Online ICMP blackhole checker
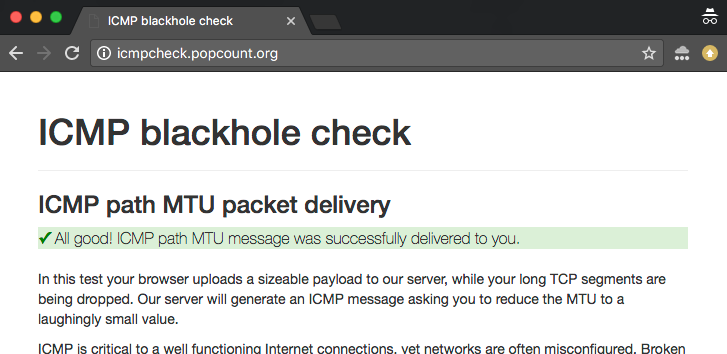
Um diese Probleme zu erforschen und zu beheben, haben wir einen Online-Checker entwickelt. Sie können zwei Versionen des Tests finden:
- IPv4 Version: http://icmpcheck.popcount.org
- IPv6 Version: http://icmpcheckv6.popcount.org
Diese Seiten starten zwei Tests:
- Der erste Test sendet ICMP-Nachrichten an Ihren Computer, mit der Absicht, die Pfad-MTU auf einen lächerlich kleinen Wert zu reduzieren.
- Der zweite Test sendet Fragment-Datagramme an Sie zurück.
Wenn Sie beide Tests bestehen, sollten Sie die Gewissheit haben, dass sich das Internet auf Ihrer Seite des Kabels gut verhält.
Es ist auch einfach, die Tests von der Kommandozeile aus zu starten, falls Sie sie auf dem Server ausführen wollen:
perl -e "print 'packettoolongyaithuji6reeNab4XahChaeRah1diej4' x 180" > payload.bincurl -v -s http://icmpcheck.popcount.org/icmp --data @payload.bincurl -v -s http://icmpcheckv6.popcount.org/icmp --data @payload.binDies sollte die Pfad-MTU zu unserem Server auf 905 Bytes reduzieren. Sie können dies überprüfen, indem Sie einen Blick in die Routing-Cache-Tabelle werfen. Unter Linux tun Sie dies mit:
ip route get `dig +short icmpcheck.popcount.org`Es ist möglich, den Routing-Cache unter Linux zu löschen:
ip route flush cache to `dig +short icmpcheck.popcount.org`Der zweite Test prüft, ob Fragmente ordnungsgemäß an den Client zugestellt werden:
curl -v -s http://icmpcheck.popcount.org/frag -o /dev/nullcurl -v -s http://icmpcheckv6.popcount.org/frag -o /dev/nullZusammenfassung
In diesem Blog-Beitrag haben wir die Probleme bei der Ermittlung von Pfad-MTU-Werten im Internet beschrieben. ICMP- und Fragment-Datagramme werden oft auf beiden Seiten der Verbindungen blockiert. Clients können auf falsch konfigurierte Firewalls und NAT-Geräte stoßen oder ISPs verwenden, die Verbindungen aggressiv abfangen. Außerdem verwenden die Clients häufig VPNs oder IPv6-Tunnel, die, wenn sie falsch konfiguriert sind, zu Problemen mit der Pfad-MTU führen können.
Die Server hingegen setzen immer häufiger auf Anycast oder ECMP. Beides sowie Router- und Firewall-Fehlkonfigurationen sind häufig die Ursache dafür, dass ICMP- und Fragment-Datagramme verworfen werden.
Abschließend hoffen wir, dass der Online-Test nützlich ist und Ihnen einen besseren Einblick in das Innenleben Ihrer Netzwerke geben kann. Der Test enthält nützliche Beispiele für die tcpdump-Syntax, die Ihnen weitere Einblicke verschaffen. Viel Spaß beim Netzwerk-Debugging!
Ist es spannend, Fragmentierungsprobleme für 10 % des Internets zu beheben? Wir suchen Systemingenieure aller Couleur, Golang-Programmierer, C-Programmierer und Praktikanten an mehreren Standorten! Kommen Sie zu uns nach San Francisco, London, Austin, Champaign und Warschau.
-
In IPv6 funktioniert die „Forward“-Fragmentierung etwas anders als in IPv4. Den zwischengeschalteten Routern ist es untersagt, die Pakete zu fragmentieren, aber die Quelle kann es trotzdem tun. Dies ist oft verwirrend – ein Host könnte aufgefordert werden, ein Paket zu fragmentieren, das er in der Vergangenheit übertragen hat. Bei zustandslosen Protokollen wie DNS macht dies wenig Sinn. ︎
-
Als Randbemerkung: Es gibt auch eine „minimale Übertragungseinheit“! Bei der üblichen Ethernet-Rahmung muss jedes übertragene Datagramm mindestens 64 Byte auf Schicht 2 haben. Dies entspricht 22 Bytes auf der UDP- und 10 Bytes auf der TCP-Schicht. Mehrere Implementierungen haben bei kürzeren Paketen uninitialisierten Speicher verloren! ︎
-
Streng genommen heißt das ICMP-Paket in IPv4 „Destination Unreachable, Fragmentation Needed and Don’t Fragment was Set“. Aber ich finde die IPv6 ICMP-Fehlerbeschreibung „Packet too big“ viel klarer. ︎
-
Als Hinweis enthält der TCP-Stack auch einen maximal zulässigen „MSS“-Wert in SYN-Paketen (MSS ist im Grunde ein MTU-Wert, der um die Größe der IP- und TCP-Header reduziert wird). Dies ermöglicht es den Hosts zu wissen, wie hoch die MTU auf ihren Verbindungen ist. Hinweis: Dies sagt nichts über die MTU auf den Dutzenden von Internetverbindungen zwischen den beiden Hosts aus! ︎
-
Lassen Sie uns auf Nummer sicher gehen. Eine bessere MTU ist 1492, um DSL- und PPPoE-Verbindungen zu berücksichtigen. ︎