




Statistische Analyse: Signifikanz und Konfidenzintervalle
Bei jeder statistischen Analyse arbeiten Sie wahrscheinlich mit einer Stichprobe und nicht mit Daten aus der Grundgesamtheit. Ihr Ergebnis repräsentiert daher möglicherweise nicht die gesamte Grundgesamtheit – und könnte sogar sehr ungenau sein, wenn Ihre Stichprobe nicht sehr gut war.
Sie brauchen daher eine Möglichkeit, um zu messen, wie sicher Sie sind, dass Ihr Ergebnis genau ist und nicht nur zufällig zustande gekommen ist. Statistiker verwenden dafür zwei miteinander verbundene Begriffe: Konfidenz und Signifikanz.
Diese Seite erklärt diese Konzepte.
Statistische Signifikanz
Der Begriff Signifikanz hat in der Statistik eine ganz besondere Bedeutung. Er gibt an, wie wahrscheinlich es ist, dass ein Ergebnis nicht zufällig zustande gekommen ist.

In der Abbildung stellt der blaue Kreis die gesamte Bevölkerung dar. Wenn du eine Stichprobe nimmst, kann deine Stichprobe aus der gesamten Grundgesamtheit stammen. Es ist jedoch wahrscheinlicher, dass sie kleiner ist. Wenn sie nur aus dem gelben Kreis stammt, haben Sie einen großen Teil der Grundgesamtheit erfasst. Es kann aber auch sein, dass Sie Pech haben (oder Ihr Stichprobenverfahren schlecht konzipiert haben) und die Stichprobe nur aus dem kleinen roten Kreis stammt. Dies hätte schwerwiegende Folgen für die Repräsentativität Ihrer Stichprobe für die gesamte Grundgesamtheit.
Eine der besten Möglichkeiten, um sicherzustellen, dass Sie einen größeren Teil der Grundgesamtheit abdecken, ist die Verwendung einer größeren Stichprobe. Der Stichprobenumfang wirkt sich stark auf die Genauigkeit Ihrer Ergebnisse aus (mehr dazu finden Sie auf unserer Seite über Stichproben und Stichprobendesign).
Ein anderes Element wirkt sich jedoch ebenfalls auf die Genauigkeit aus: die Variation innerhalb der Grundgesamtheit selbst. Sie können dies beurteilen, indem Sie die Streuung Ihrer Daten messen (mehr dazu finden Sie auf unserer Seite über einfache statistische Analysen). Bei einer größeren Streuung ist die Wahrscheinlichkeit größer, dass Sie eine Stichprobe auswählen, die nicht typisch ist.
Das Konzept der Signifikanz bringt einfach den Stichprobenumfang und die Streuung in der Grundgesamtheit zusammen und nimmt eine numerische Bewertung der Wahrscheinlichkeit vor, dass Sie einen Stichprobenfehler gemacht haben, d. h. dass Ihre Stichprobe nicht repräsentativ für Ihre Grundgesamtheit ist.
Die Signifikanz wird als Wahrscheinlichkeit ausgedrückt, dass Ihre Ergebnisse zufällig entstanden sind, allgemein bekannt als p-Wert. In der Regel sollte dieser Wert unter einem bestimmten Wert liegen, in der Regel entweder 0,05 (5 %) oder 0,01 (1 %), obwohl in einigen Ergebnissen auch 0,10 (10 %) angegeben wird.
Null- und Alternativhypothese
Wenn Sie ein Experiment oder eine Marktforschungsarbeit durchführen, möchten Sie in der Regel wissen, ob das, was Sie tun, eine Wirkung hat. Daher kann man es als Hypothese formulieren:
-x hat eine Wirkung auf y.
Dies wird in der Statistik als „Alternativhypothese“ bezeichnet und oft als H1 bezeichnet.
Die „Nullhypothese“ oder H0 besagt, dass x keinen Einfluss auf y hat.
Statistisch gesehen besteht der Zweck von Signifikanztests darin, herauszufinden, ob die Ergebnisse darauf hindeuten, dass die Nullhypothese verworfen werden muss – in diesem Fall ist es wahrscheinlicher, dass die alternative Hypothese zutrifft.
Wenn Ihre Ergebnisse nicht signifikant sind, können Sie die Nullhypothese nicht zurückweisen und müssen zu dem Schluss kommen, dass es keinen Effekt gibt.
Der p-Wert ist die Wahrscheinlichkeit, dass Sie die Ergebnisse erhalten hätten, wenn Ihre Nullhypothese wahr wäre.
Berechnung der Signifikanz
Eine Möglichkeit zur Berechnung der Signifikanz ist die Verwendung eines z-Scores. Dieser beschreibt den Abstand eines Datenpunktes zum Mittelwert in Form der Anzahl der Standardabweichungen (mehr über Mittelwert und Standardabweichung finden Sie auf unserer Seite über einfache statistische Analysen).
Für einen einfachen Vergleich wird der z-Score nach folgender Formel berechnet:
$$z=\frac{x – \mu}{\sigma}$$
wobei \(x\) der Datenpunkt, \(\mu\) der Mittelwert der Grundgesamtheit oder Verteilung und \(\sigma\) die Standardabweichung ist.
Nehmen wir zum Beispiel an, dass wir testen möchten, ob eine Spiele-App beliebter ist als andere Spiele. Nehmen wir an, dass die durchschnittliche Spiele-App 1000 Mal heruntergeladen wird, mit einer Standardabweichung von 110. Unser Spiel wurde 1200 Mal heruntergeladen. Sein z-Score ist:
$$z=\frac{1200-1000}{110}=1.81$$
Ein höherer z-Score signalisiert, dass das Ergebnis weniger wahrscheinlich zufällig ist.
Sie können eine statistische z-Tabelle verwenden, um Ihren z-Score in einen p-Wert umzuwandeln. Wenn Ihr p-Wert niedriger ist als das gewünschte Signifikanzniveau, sind Ihre Ergebnisse signifikant.
Anhand der z-Tabelle lässt sich der z-Wert für unsere Spiele-App (1,81) in einen p-Wert von 0,9649 umrechnen. Das ist besser als unser gewünschtes Niveau von 5 % (0,05) (weil 1-0,9649 = 0,0351 oder 3,5 %), also können wir sagen, dass dieses Ergebnis signifikant ist.
Beachten Sie, dass es einen kleinen Unterschied für eine Stichprobe aus einer Grundgesamtheit gibt, bei der der z-Score mit der Formel berechnet wird:
$$z=\frac{(x-\mu)}{(\sigma/\sqrt n)}$$
wobei x der Datenpunkt ist (in der Regel Ihr Stichprobenmittelwert), µ der Mittelwert der Grundgesamtheit oder Verteilung, σ die Standardabweichung und √n die Quadratwurzel des Stichprobenumfangs ist.
Ein Beispiel soll dies verdeutlichen.
Angenommen, Sie überprüfen, ob Biologiestudenten tendenziell bessere Noten erzielen als ihre Kommilitonen in anderen Fächern. Sie könnten feststellen, dass die durchschnittliche Testnote für eine Stichprobe von 40 Biologen 80 beträgt, mit einer Standardabweichung von 5, verglichen mit 78 für alle Studenten an dieser Universität oder Schule.
$$$z=\frac{(80-78)}{(5/\sqrt 40)}=2,53$$
Unter Verwendung der z-Tabelle entspricht 2,53 einem p-Wert von 0,9943. Man kann diesen Wert von 1 abziehen und erhält 0,0054. Dieser Wert ist kleiner als 1 %, so dass wir sagen können, dass dieses Ergebnis auf dem 1 %-Niveau signifikant ist und die Biologen bessere Ergebnisse in den Tests erzielen als der durchschnittliche Student an dieser Universität.
Dies bedeutet nicht unbedingt, dass die Biologen klüger sind oder besser in den Tests abschneiden als die Studenten anderer Fächer. Es könnte vielmehr bedeuten, dass die Prüfungen in Biologie einfacher sind als die in anderen Fächern. Ein signifikantes Ergebnis ist KEIN Beweis für einen kausalen Zusammenhang, aber es zeigt Ihnen, dass es ein Problem geben könnte, das Sie untersuchen sollten.
Weitere Informationen zum Testen auf Signifikanz von Stichprobenmittelwerten und zum Testen von Unterschieden zwischen Gruppen finden Sie auf unserer Seite über Hypothesenentwicklung und -prüfung.
Konfidenzintervalle
Ein Konfidenzintervall (oder Konfidenzniveau) ist ein Bereich von Werten, in dem der wahre Wert mit einer bestimmten Wahrscheinlichkeit liegt.
Effektiv misst es, wie sicher Sie sind, dass der Mittelwert Ihrer Stichprobe (der Stichprobenmittelwert) mit dem Mittelwert der Gesamtpopulation, aus der Ihre Stichprobe entnommen wurde (der Populationsmittelwert), übereinstimmt.
Wenn Ihr Mittelwert beispielsweise 12,4 beträgt und Ihr 95 %-Konfidenzintervall 10,3-15,6 beträgt, bedeutet dies, dass Sie zu 95 % sicher sind, dass der wahre Wert Ihres Populationsmittelwertes zwischen 10,3 und 15,6 liegt. Mit anderen Worten, er liegt vielleicht nicht bei 12,4, aber Sie sind einigermaßen sicher, dass er nicht sehr weit davon entfernt ist.
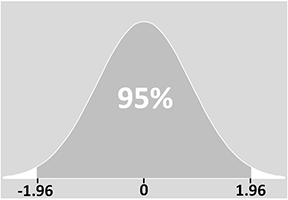
Das nachstehende Diagramm zeigt dies in der Praxis für eine Variable, die einer Normalverteilung folgt (weitere Informationen dazu finden Sie auf unserer Seite über statistische Verteilungen).

Die genaue Bedeutung eines Konfidenzintervalls besteht darin, dass, wenn Sie Ihr Experiment viele, viele Male durchführen würden, 95% der Intervalle, die Sie aus diesen Experimenten konstruiert haben, den wahren Wert enthalten würden. Mit anderen Worten, in 5 % Ihrer Experimente würde Ihr Intervall NICHT den wahren Wert enthalten.
Aus dem Diagramm können Sie ersehen, dass eine 5 %ige Chance besteht, dass das Konfidenzintervall den Mittelwert der Grundgesamtheit nicht enthält (die beiden „Schwänze“ von 2,5 % auf jeder Seite). Mit anderen Worten, in einer von 20 Stichproben oder Experimenten wird der Wert, den wir für das Konfidenzintervall erhalten, nicht den wahren Mittelwert einschließen: der Mittelwert der Grundgesamtheit wird tatsächlich außerhalb des Konfidenzintervalls liegen.
Berechnung des Konfidenzintervalls
Bei der Berechnung eines Konfidenzintervalls werden Ihre Stichprobenwerte und einige Standardmaße (Mittelwert und Standardabweichung) verwendet (weitere Informationen zu deren Berechnung finden Sie auf unserer Seite über einfache statistische Analysen).
Am einfachsten lässt es sich anhand eines Beispiels erklären.
Angenommen, wir haben die Körpergröße einer Gruppe von 40 Personen untersucht und festgestellt, dass der Mittelwert 159,1 cm und die Standardabweichung 25,4 cm beträgt.
Standardabweichung für Konfidenzintervalle
Im Normalfall würden Sie die Standardabweichung der Grundgesamtheit zur Berechnung des Konfidenzintervalls verwenden. Es ist jedoch sehr unwahrscheinlich, dass Sie wissen, wie hoch diese ist.
Glücklicherweise können Sie die Standardabweichung der Stichprobe verwenden, vorausgesetzt, Sie haben eine ausreichend große Stichprobe. Als Grenzwert gilt im Allgemeinen eine Stichprobengröße von 30 oder mehr, aber je größer, desto besser.
Wir müssen herausfinden, ob unser Mittelwert eine vernünftige Schätzung der Größe aller Personen ist, oder ob wir eine besonders große (oder kleine) Stichprobe ausgewählt haben.
Wir verwenden eine Formel zur Berechnung eines Konfidenzintervalls. Diese lautet:
$$Mittelwert \pm z \frac{(SD)}{\sqrt n}$$
Wobei SD = Standardabweichung und n die Anzahl der Beobachtungen oder der Stichprobenumfang ist.
Der z-Wert wird aus statistischen Tabellen für unsere gewählte Referenzverteilung entnommen. Diese Tabellen enthalten den z-Wert für ein bestimmtes Konfidenzintervall (z. B. 95 % oder 99 %).
In diesem Fall messen wir die Körpergröße von Personen, und wir wissen, dass die Körpergröße der Bevölkerung einer (weitgehend) normalen Verteilung folgt (weitere Informationen hierzu finden Sie auf unserer Seite über statistische Verteilungen).
Der z-Wert für ein 95%-Konfidenzintervall ist 1,96 für die Normalverteilung (aus statistischen Standardtabellen).
Anhand der obigen Formel beträgt das 95%-Konfidenzintervall also:
$$159,1 \pm 1,96 \frac{(25,4)}{\sqrt 40}$$
Wenn wir diese Berechnung durchführen, finden wir, dass das Konfidenzintervall 151,23-166,97 cm beträgt. Wir können also mit 95%iger Sicherheit sagen, dass der Mittelwert der Population in diesen Bereich fällt.
Verstehen des z-Scores oder z-Wertes
Der z-Score ist ein Maß für die Standardabweichung vom Mittelwert. In unserem Beispiel wissen wir also, dass 95 % der Werte innerhalb von ± 1,96 Standardabweichungen vom Mittelwert liegen:
Bewertung des Konfidenzintervalls
Als allgemeine Faustregel gilt: Ein kleines Konfidenzintervall ist besser. Das Konfidenzintervall wird mit zunehmendem Stichprobenumfang enger, weshalb eine größere Stichprobe immer vorzuziehen ist. Wie auf unserer Seite über Stichproben und Stichprobenplanung erläutert, würde Ihr ideales Experiment die gesamte Bevölkerung einbeziehen, aber das ist in der Regel nicht möglich.
Schlussfolgerung
Konfidenzintervalle und Signifikanz sind Standardmethoden, um die Qualität Ihrer statistischen Ergebnisse zu zeigen. Es wird von Ihnen erwartet, dass Sie sie routinemäßig angeben, wenn Sie eine statistische Analyse durchführen, und Sie sollten im Allgemeinen genaue Zahlen angeben. So stellen Sie sicher, dass Ihre Forschung gültig und zuverlässig ist.