




Welche Liga ist die beste?
Diese Arbeit wurde gemeinsam mit Madeline Gall verfasst.
Während das Scouting für einige Sportarten einfach ist (College Football → NFL), kann das Scouting für die NHL ein mühsamer Prozess sein. Bei Spielern aus mehr als 45 internationalen Eishockeyligen, von denen jede ihre eigenen Regeln und Schwierigkeiten hat, wie kann man da die Qualität der Leistung eines Spielers angemessen beurteilen? Vergleiche zwischen den Ligen sind nicht leicht möglich; 18 Punkte für einen Achtzehnjährigen, der in einer untergeordneten Liga gegen andere Achtzehnjährige spielt, sollten nicht den gleichen Wert haben wie 18 Punkte für einen Achtzehnjährigen, der gegen Veteranen in der NHL spielt.
Es gab andere Versuche, dies zu berücksichtigen, einschließlich der Übersetzungsvariablen für Spieler, wie die Hockey-Übersetzungsfaktoren von Rob Vollman und die NHL Equivalency Ratings (NHLe) von Gabriel Desjardin. Desjardins NHLe befasste sich zuvor mit dem Vergleich und der Vorhersage von Spielerleistungen bei Übergängen von einer Liga in die NHL (Wechsel von einer anderen Liga in die NHL). Es war für einen schnellen, allgemeinen Vergleich hervorragend geeignet und hat sicherlich seine Vorteile (einfache und schnelle Berechnung), aber die Methode hat auch einige Nachteile. Zunächst einmal wurden die Qualität des Teams, die Position und das Alter nicht unbedingt berücksichtigt. Die Übersetzungsfaktoren werden anhand der Statistiken von Spielern berechnet, die mindestens 20 Spiele in der jeweiligen Liga absolviert haben, bevor sie mindestens 20 Spiele in der NHL gespielt haben. Das bedeutet, dass es eine Menge wertvoller Daten über diese Zwischenübergänge gibt, die nicht genutzt werden.
In diesem Projekt stellen wir eine neue Methode für den Vergleich und die Prognose von Spielerleistungen in verschiedenen Ligen vor, die eine bereinigte Z-Score-Metrik verwendet, die diesen Nachteilen Rechnung trägt. Diese Metrik berücksichtigt Faktoren wie Alter, Liga, Saison und Position, die sich auf die P/PG-Metrik eines Spielers auswirken, und kann auf jede beliebige Liga angewendet werden. Diese neue Metrik ist notwendig, da es viele Merkmale gibt, die sich von Liga zu Liga unterscheiden. Aufgrund der unterschiedlichen Spielstile und der Schwierigkeit der Gegner gibt es keine einheitliche Kennzahl, mit der sich die Leistung von Spielern in Eishockeyligen auf der ganzen Welt vergleichbar bewerten ließe. Auch andere Faktoren wie die Stärke der Torhüter, die Anzahl der Strafen und die Größe der Spielfelder sind in den internationalen Ligen nicht einheitlich. So kann es zu Szenarien kommen, in denen Spieler mit ähnlicher Stärke scheinbar unterschiedliche Leistungen erbringen.
Ein Beispiel dafür sind Thomas Harley und Ville Heinola aus dem letzten Draft 2019. Beide sind Spieler aus unterschiedlichen Ligen, die gegen unterschiedliche Gegner spielen und sehr unterschiedliche Zahlen vorweisen können, aber dennoch ungefähr gleich bewertet werden. Harley, ein in den USA geborener Verteidiger, der in der kanadischen Junioren-Eishockeyliga spielt, steht derzeit bei den Mississauga Steelheads in der Ontario Hockey League unter Vertrag. Er wurde von den Dallas Stars in der ersten Runde des NHL Entry Draft 2019 an 18. Stelle gedraftet. Heinola wiederum ist ein finnischer Profi-Eishockey-Verteidiger, der derzeit für Lukko in der Liiga spielt und an die Winnipeg Jets in der National Hockey League ausgeliehen ist. Er wurde als einer der besten internationalen Schlittschuhläufer eingestuft, die für den NHL Entry Draft 2019 in Frage kommen. Heinola wurde von den Jets an 20. Stelle gedraftet. Wie wurden diese beiden Spieler am Ende von ihren jeweiligen Teams bewertet? Wahrscheinlich mit etwas ähnlichem wie unserer Metrik, zusätzlich zu den Scouting-Informationen.
Für unsere Metrik haben wir uns nicht nur von früheren Ansätzen wie NHLe inspirieren lassen, sondern auch von dem jüngsten Aufschwung von Elo. Elo ist eine Methode zur Berechnung der relativen Fähigkeiten von Spielern in Nullsummenspielen. Ursprünglich wurde Elo im Zusammenhang mit der Bewertung von Schachspielern entwickelt, kann aber auch in anderen Bereichen wie dem Profisport eingesetzt werden. Um mehr zu lesen und Beispiele für Elo im Sport zu sehen, finden Sie hier ein Tutorial von 538. Elo ist einfach ein spezielles Modell für den paarweisen Vergleich. Wir werden den Prozess durchlaufen, mit dem wir unser Elo-Modell für den paarweisen Vergleich erstellt haben.
Zu Beginn haben wir einen Datensatz verwendet, der etwa 300.000 Beobachtungen aus den verfügbaren Spielerinformationen (Name, Position, Liga, Geburtstag usw.) und Spielerstatistiken (gespielte Spiele, Tore, Assists usw.) enthielt, die wir von eliteprospects.com abgerufen haben. Eine der ersten Fragen, auf die wir stießen, war, welche Art von Antwortvariable wir erstellen könnten, um die Spielerstatistiken zu vergleichen und dabei Alter, Ligastärke, Position usw. zu berücksichtigen. Die Leistung von Spielern wurde in der NHL umfassend berechnet; es gibt verschiedene Messungen wie WAR, GAR, Corsi usw. Die Datenerfassung ist jedoch nicht in allen Ligen gleich. In einigen Ligen wurden Statistiken wie Treffer und Blocks nicht so proaktiv erfasst wie in anderen, was bedeutete, dass wir nur Variablen, die in allen Ligen allgegenwärtig sind, als Faktoren in unserer Regression verwenden konnten.
Bei der Erstellung der neuen Antwortvariablen wollten wir die Punkte pro Spiel so umwandeln, dass Alter, Saison, Position und Liga berücksichtigt werden. Der erste Schritt bestand darin, den Logarithmus der Punkte pro Spiel plus eins zu nehmen. Diese Transformation hatte eine eher normale Verteilung, während die Rohpunkte pro Spiel sehr rechtsschief waren. Obwohl die logarithmische Transformation dazu beitrug, dass die Daten normaler verteilt zu sein schienen, berücksichtigten die logarithmischen Punkte pro Spiel immer noch nicht die oben aufgeführten Variablen. Um diese Variablen zu berücksichtigen, beschlossen wir, einen z-Score für die Log-Punkte pro Spiel jedes Spielers zu erstellen. Der erste Schritt bestand darin, den Mittelwert und die Standardabweichung für jede Gruppe aus Position, Saison, Liga und Alter zu berechnen. Dann wurde für jede Spielerbeobachtung ein z-Score unter Verwendung des Mittelwerts und der Standardabweichung berechnet, die zu den Variablen gehörten, für die wir die Kontrolle durchführten. Der z-Score des Logarithmus der Punkte pro Spiel plus eins war also unsere endgültige Antwortvariable. Die z-Werte schienen noch normaler verteilt zu sein als die logarithmischen Punkte pro Spiel, und die z-Werte für Gruppen wie Verteidiger und Stürmer waren ebenfalls normal verteilt.
Erstellung des Paired-Comparison-Modells, das einem Elo-Modell sehr ähnlich ist. Zu Beginn erstellen wir einen Vergleichsdatenrahmen. Wir erstellen Paare von Spieler-Liga-Saisons für jeden Spieler, so dass es einen kleinen Datenrahmen aller paarweisen Vergleiche für die Ligen gibt, in denen sie gespielt haben. Das bedeutet, dass ein Spieler, der in K Ligen gespielt hat, K-choose-2 Paare von Spieler-Liga-Saisons hat. Als Nächstes werden alle Paare eliminiert, die dieselbe Liga haben, sowie Paare, die weiter als eine Saison auseinander liegen, und eine Ergebnisvariable berechnet. Diese Variable kann entweder kontinuierlich oder binär sein, je nach der verwendeten Regression. Es ist wichtig zu verstehen, dass die „härtere“ Liga, in der gespielt wird, eigentlich eine niedrigere Ergebnisvariable hätte. Dies beruht auf der Annahme, dass härtere Ligen bessere Verteidiger und Torhüter haben, was es schwieriger macht, Tore zu erzielen.
| Spielername | Liga | Saison | Z- Score |
|---|---|---|---|
| Kris Letang | QMJHL | 2006-07 | 1.829 |
| Kris Letang | NHL | 2006-07 | 1.158 |
| Kris Letang | AHL | 2007-08 | 1.557 |
| Liga 1 | Saison 1 | Z-Score 1 | Liga 2 | Saison 2 | Z-Score 2 | Z-Score Differenz |
|---|---|---|---|---|---|---|
| QMJHL | 2006-07 | 1.829 | NHL | 2006-07 | 1.158 | 0.671 |
| NHL | 2006-07 | 1.158 | AHL | 2007-08 | 1.557 | -0.399 |
| QMJHL | 2006-07 | 1.829 | AHL | 2007-08 | 1.557 | 0.272 |
Nach der Erstellung des gepaarten Vergleichsmodells wurden verschiedene Arten von Regressionen zur Berechnung der Koeffizienten verwendet. Wir konzentrierten uns auf die Verwendung eines selbst erstellten logistischen Modells, des Bradley-Terry-Modells (unter Verwendung des BTm-Pakets in R), die beide binäre Ergebnisse erzeugten, sowie auf eine gewöhnliche Regression der kleinsten Quadrate, die ein kontinuierliches Ergebnis erzeugte. Um zu bewerten, welche Regression die genauesten Ergebnisse liefert, teilten wir zunächst die gepaarten Daten im Verhältnis 70:30 für Trainings- und Teststichproben auf. Anschließend wurde die Wahrscheinlichkeit eines Sieges für alle Ligen auf der Grundlage der bereinigten Punkte pro Spiel (Z-Score) vorhergesagt. Es wurde ein Schwellenwert für „Gewinnen“ festgelegt; wenn die Wahrscheinlichkeit größer als der Schwellenwert war, war das vorhergesagte Ergebnis = 1. Andernfalls war es = 0. Anschließend wurden die vorhergesagten Ergebnisse mit den tatsächlichen Ergebnissen verglichen, um die Vorhersagegenauigkeit für jedes Modell zu berechnen. Die Ergebnisse sind in der folgenden Tabelle dargestellt.
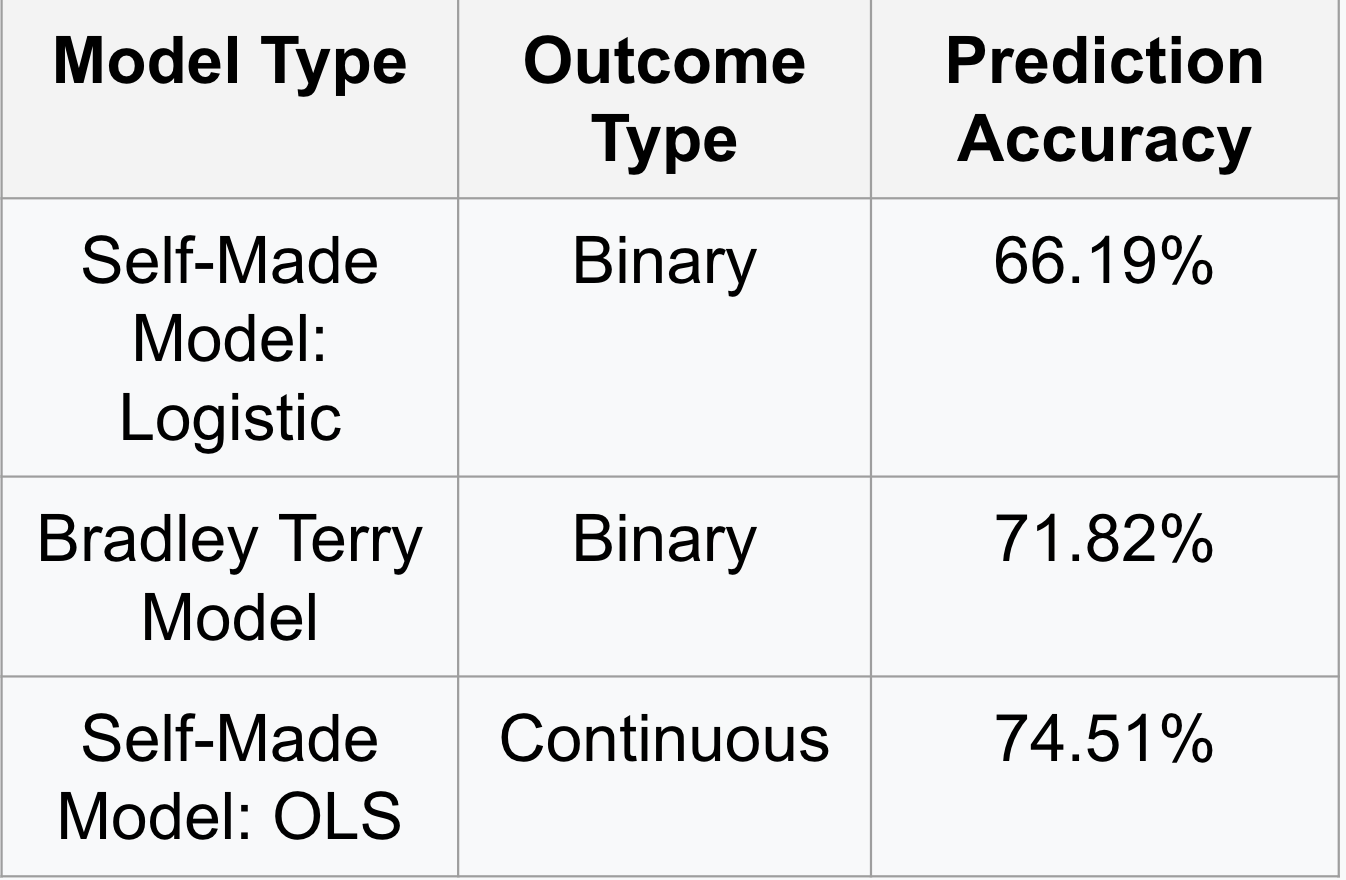
Nachdem unsere verschiedenen Modellierungsmethoden erstellt waren, konnten wir die Stärkekoeffizienten aus den Modellen verwenden, um eine Rangliste der Ligen nach ihrer Stärke zu erstellen. Es war keine Überraschung, dass die National Hockey League für jedes Jahr von 2008 bis 2018 und für die gesamten Stärkekoeffizienten als die stärkste Liga gilt. Die andere Liga, die durchweg als zweitstärkste angesehen wurde, war die Weltmeisterschaft, was Sinn macht, da hier die besten Spieler aus verschiedenen Ländern gegeneinander antreten und dieses Turnier aus vielen Spielern besteht, die auch in der NHL spielen. Betrachtet man nur die Ligen, so gehören die AHL, die KHL, die SHL und die DEL durchweg zu den stärksten Ligen mit über 45 Mannschaften. Die endgültige Rangliste der 10 stärksten Ligen umfasst die NHL, die Weltmeisterschaft, die Junioren-Weltmeisterschaft, die KHL, die SHL, die AHL, die USDP, die Junioren-Weltmeisterschaft U18, die DEL und die NLA. Einige der Ligen, die vielleicht eine Überraschung waren, waren die Juniorenligen oder die USDP. Diese Ligen tauchten in unserer Rangliste weiter oben auf, weil wir in unserem Modell das Alter berücksichtigten. Dadurch konnte die Stärke auf der Qualität der Spieler basieren und nicht auf dem Alter. Jedes der drei von uns erstellten Modelle ergab ähnliche Ranglisten mit nur geringen Abweichungen.
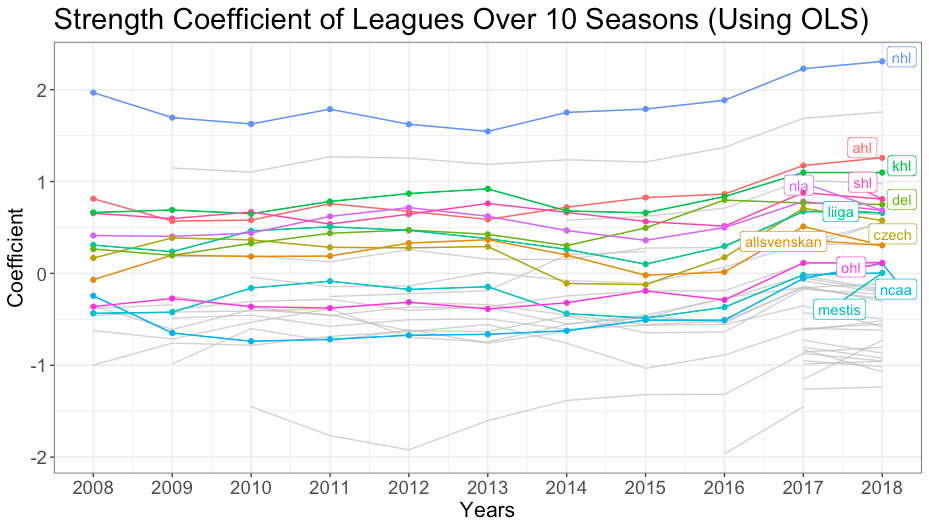
Stärkekoeffizienten im Zeitverlauf: Die obige Grafik zeigt die Stärkekoeffizienten für jede Liga für jedes Jahr von 2008 bis 2018. Die bekannteren Ligen und die konstant starken Ligen sind oben hervorgehoben.
Nachdem wir eine Rangliste der Ligen basierend auf unseren bereinigten Punkten pro Spiel erstellt haben, war der nächste Schritt, zu sehen, wie diese Ranglisten im Vergleich zu den reinen Punkten pro Spiel sind. Bei der Verwendung der reinen Punkte pro Spiel stellten wir fest, dass drei Dinge mit den Stärkekoeffizienten der Ligen passierten. Bei Ligen mit einem höheren Stärkekoeffizienten waren diese Ligen tendenziell immer noch die stärkeren Ligen für die bereinigten Punkte pro Spiel. Bei den Ligen, die sich im Mittelfeld aller Ligen befanden, waren ihre Stärkekoeffizienten für die rohen Punkte pro Spiel sehr ähnlich wie ihre Stärkekoeffizienten für die bereinigten Punkte pro Spiel. Die Ligen mit den niedrigsten Stärkekoeffizienten für rohe Punkte pro Spiel wiesen schließlich schlechtere Stärkekoeffizienten für bereinigte Punkte pro Spiel auf. Die einzigen Ligen mit niedrigeren Stärkekoeffizienten, deren Stärkekoeffizienten durch die bereinigten Punkte pro Spiel verbessert wurden, waren Ligen mit jungen Spielern. Dieser Trend gilt für die Juniorenweltmeisterschaften der U20 und U18 sowie für die Highschool-Liga der Vereinigten Staaten in Minnesota. Die High-School-Liga in Minnesota galt als die mit Abstand schlechteste Liga, wenn man die rohen Punkte pro Spiel als Antwortvariable verwendete, aber bei Verwendung der bereinigten Punkte pro Spiel schnitt diese Liga besser ab als 10 andere Ligen, von denen viele professionelle Ligen sind. Dadurch konnten wir die Schwächen der Punkte pro Spiel als Prädiktor für die Ligastärke besser erkennen, und es wurde auch deutlich, wie wichtig es ist, das Alter bei der Bestimmung der Ligastärke zu berücksichtigen.
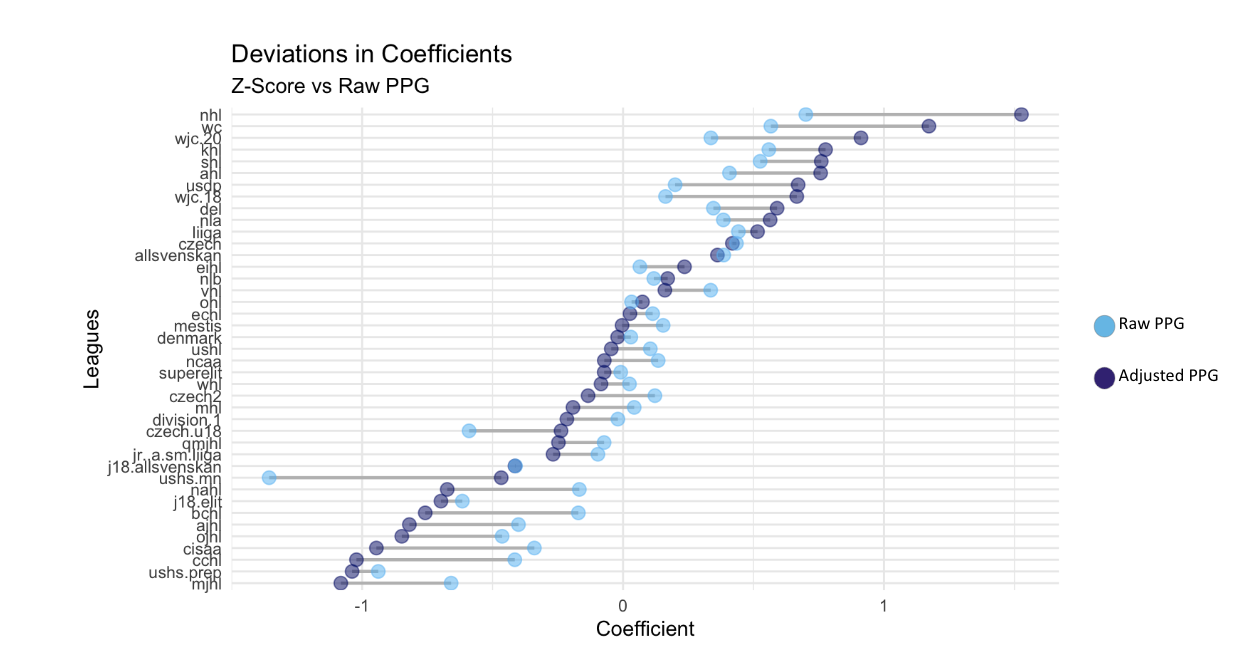
Stärkekoeffizienten für jede Liga für rohe P/GP vs. bereinigte P/GP: Dieses Diagramm zeigt die Stärkekoeffizienten für jede Liga für die zwei verschiedenen Antwortvariablen. Die Stärkekoeffizienten wurden mit der gleichen Modellierungsmethode berechnet.
Wie bereits erwähnt, musste eine neue Schätzung für die Spielerleistung erstellt werden, da die vorhandenen Prädiktoren wie Punkte pro Spiel aufgrund von Alter, Ligastärke, Mannschaftsstärke und Jahr verzerrt sind. Durch die Erstellung von Perzentilen für Spielertypen kann ein potenzieller Spieler mit anderen ähnlichen Spielern verglichen werden, was eine genauere Vorhersage ermöglicht. Das Perzentil von log P/GP und die von uns gewählte Methode sind sehr nützlich, weil sie eine Vorhersage der Leistung eines beliebigen Spielers in einer der über 45 Ligen ermöglichen. Bei so vielen Ligen ist es nicht garantiert, dass ein Spieler von dieser Liga in die NHL gedraftet worden wäre, aber ohne die Modellmethode ist das nicht nötig, um eine genaue Vorhersage zu treffen.
Die bereinigten Punkte pro Spiel von Jake Geuntzel in der Saison 2017-2018 für die Pittsburgh Penguins betrugen zum Beispiel .94. Anhand dieser bereinigten Punkte pro Spiel können wir seine bereinigten Punkte pro Spiel in jeder anderen Liga vorhersagen. Unten haben wir einige der gängigsten Ligen und Jake Guentzels vorausgesagte bereinigte Punkte pro Spiel in jeder dieser Ligen dargestellt. Zum Vergleich: 2016-2017 hatte Jake Guentzel eine bereinigte Punktzahl pro Spiel von 2,30 in der AHL. Unsere prognostizierten bereinigten Punkte pro Spiel von 2 sind ziemlich nah dran.
Unsere Methode zur Vorhersage der bereinigten Punkte pro Spiel eines Spielers, um zu bestimmen, wie ein Spieler in einer bestimmten Liga abschneiden könnte, ist eine einfache Berechnung anhand unserer Stärkekoeffizienten aus dem zuvor beschriebenen Modellierungsprozess. Um zwei Ligen zu vergleichen, subtrahieren Sie deren Stärkekoeffizienten voneinander. Dann addieren Sie diesen Wert zu den bereinigten Punkten pro Spiel oder dem z-Score der Liga, in der der Spieler Daten erfasst hat. Die Summe des z-Scores und der Differenz der Stärkekoeffizienten ergibt die bereinigten Punkte pro Spiel für eine beliebige andere Liga.
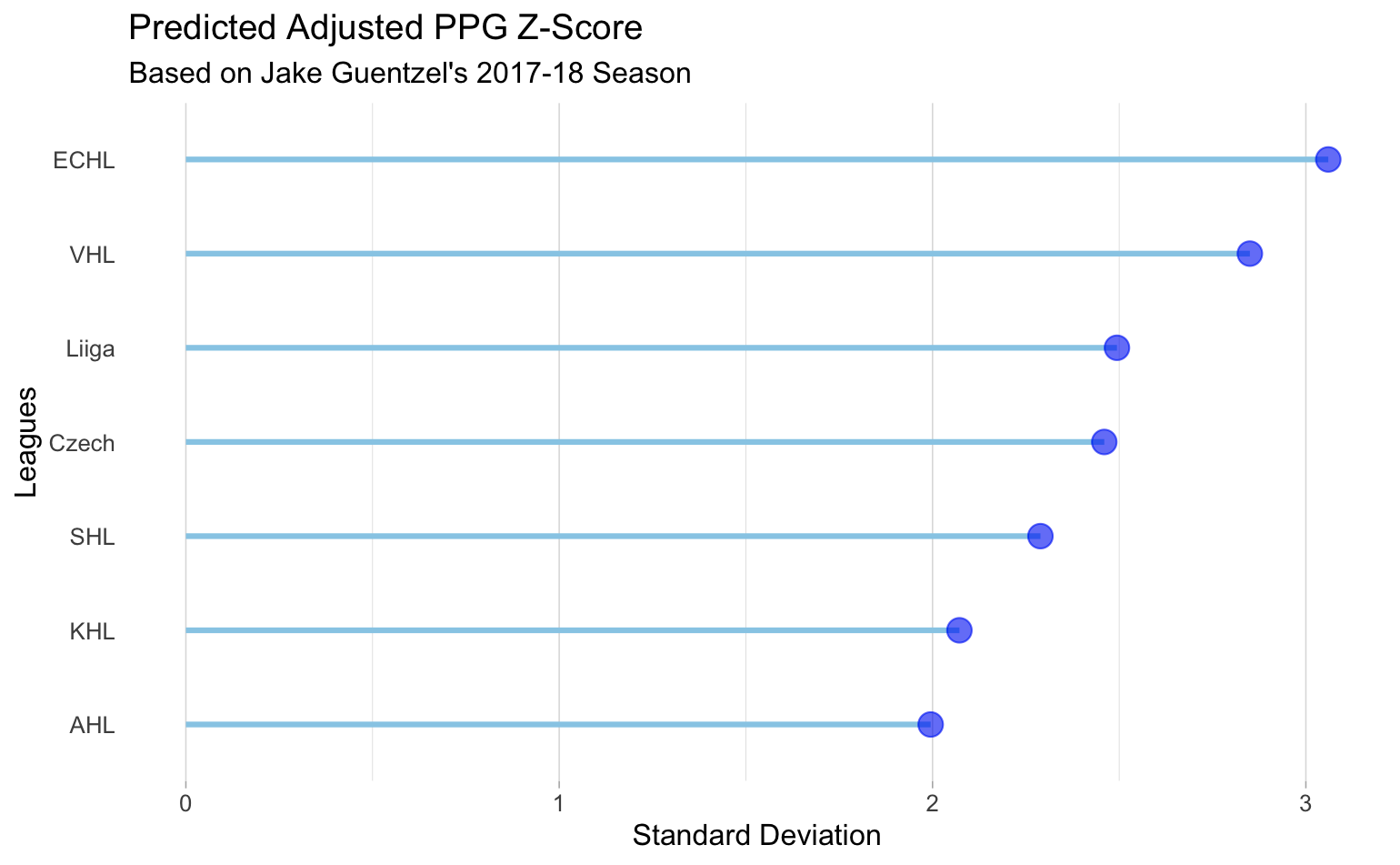
Nicht nur die Vorhersage der Leistung eines einzelnen Spielers ist für Scouting-Zwecke nützlich, sondern die Stärkekoeffizienten geben auch Aufschluss über die Stärke der Liga. Die Koeffizienten berücksichtigen das Alter, die Saison, die Position und die Liga. Dies könnte es einem Scout ermöglichen, mehr Ressourcen in eine Jugendliga zu investieren, die möglicherweise im Schatten steht. Dies liegt daran, dass das Alter eine wichtige Determinante für die Punkte pro Spiel ist, aber wenn man alle anderen Störvariablen berücksichtigt, gab es einige Jugendligen, die insgesamt eine viel bessere Ligastärke hatten als einige Profiligen.
Diese Konzepte lassen sich auch im wirklichen Leben anwenden. In den Monaten vor dem Draft 2016 gab es Diskussionen darüber, wen die Columbus Blue Jackets als drittbesten Spieler auswählen würden. Die meisten Scouts hielten den finnischen Stürmer Jesse Puljujarvi für die erste Wahl, doch die Fans waren schockiert, als sie hörten, dass CBJ sich stattdessen für den kanadischen Centerspieler Pierre-Luc Dubois entschieden hatte. Ein kurzer Blick auf die Zahlen verrät jedoch, dass diese Entscheidung nicht überraschend ist. Während seiner Zeit in der Eishockey-Profiliga Liiga erzielte Puljujarvi in 50 regulären Saisonspielen beeindruckende 28 Punkte und war damit der fünftbeste Spieler der Liiga unter 20 Jahren. Dubois hingegen spielte in einer kleineren Eishockeyliga, belegte aber dennoch mit 99 Punkten in 62 Spielen den dritten Platz in der QMJHL. Anhand der Koeffizienten können wir ihr bereinigtes P/GP in der NHL zum Vergleich berechnen, und wir stellen fest, dass Dubois aus statistischer Sicht vor Puljujarvi liegt. Natürlich wäre dies nicht das Einzige, was die Scouts bei der Draftentscheidung berücksichtigen würden. Dubois‘ beeindruckende Größe und Körperlichkeit spielten bei ihrer Entscheidung sicherlich auch eine Rolle, aber man kann davon ausgehen, dass die Blue Jackets ein besseres Bild davon hatten, wie die beiden Spieler im Vergleich zueinander abschneiden, als sie sich für Dubois und nicht für Puljujarvi entschieden.
Eine weitere Anwendung neben dem Vergleich von Spieler zu Spieler wäre der Vergleich von Liga zu Liga. Um auf das Beispiel Harley vs. Heinola zurückzukommen, können wir ihre jeweiligen Ligen mit anderen Ligen von ähnlichem Status bewerten. Anstatt die NHL mit der OHL zu vergleichen, wo der Unterschied offensichtlich ist, kann man eine differenziertere Bewertung vornehmen, indem man die OHL mit anderen nordamerikanischen Minor Leagues vergleicht. Aus den nachstehenden Diagrammen geht hervor, dass die OHL tatsächlich die stärkste Liga in den nordamerikanischen untergeordneten Ligen ist, während die Liiga im Vergleich zu anderen Profiligen einen mittleren Rang einnimmt.
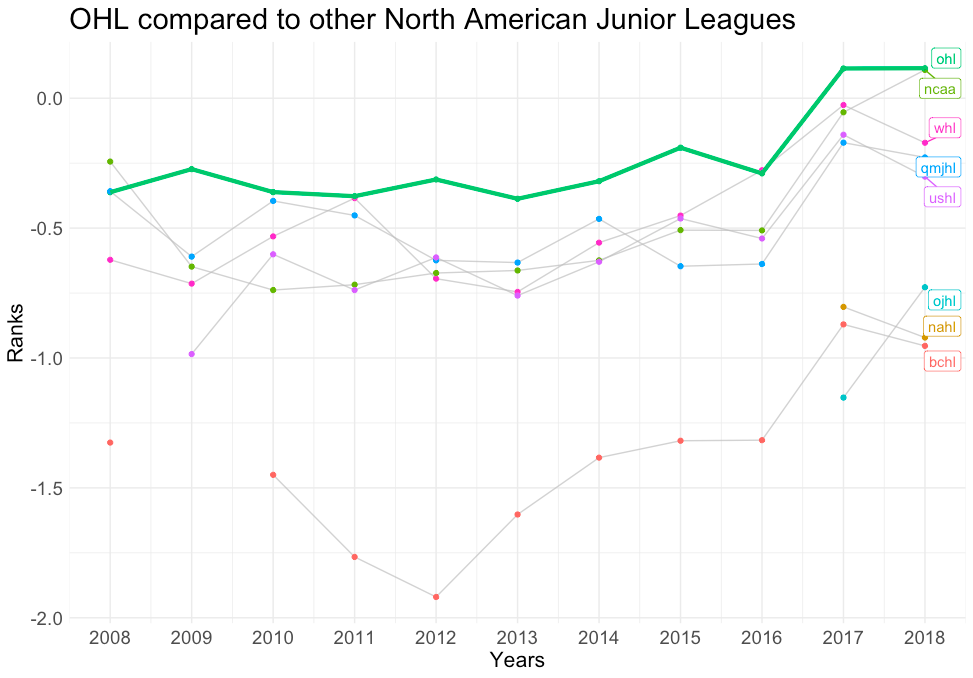
OHL im Vergleich zu anderen NA-Juniorligen: Diese Grafik zeigt die Stärkekoeffizienten für alle nordamerikanischen Juniorenligen, wobei die OHL grün hervorgehoben ist.
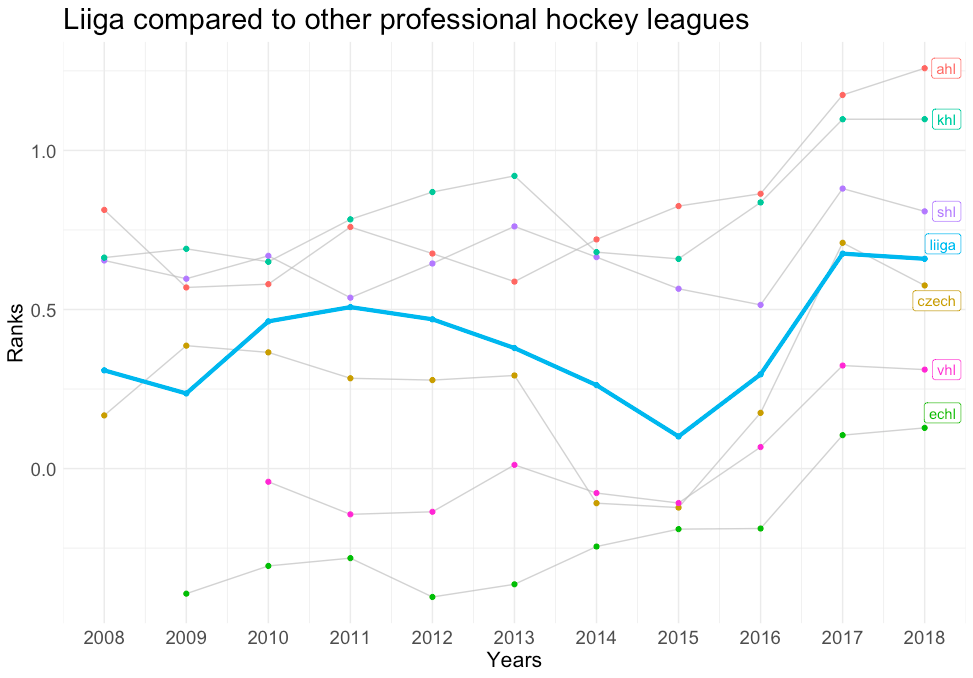
Liiga im Vergleich zu anderen professionellen Hockeyligen: Diese Grafik zeigt die Stärkekoeffizienten für alle professionellen Eishockeyligen weltweit, wobei die Liiga hellblau hervorgehoben ist.
Bei der bereinigten Punktzahl pro Spiel werden nicht nur Störvariablen wie Alter, Position, Liga und Saison eines Spielers berücksichtigt, die die Einschätzung des Wertes eines Spielers verändern können. Die verwendeten Modellierungstechniken ermöglichen Spielervergleiche in Eishockeyligen auf der ganzen Welt, nicht nur in den bekannten großen Ligen. Dadurch können die Teams vorhersagen, wie ein bestimmter Spieler in ihrer Liga im Vergleich zu ähnlichen Spielern abschneiden wird, was bisher nur mit Hilfe eines verzerrten Schätzers möglich war. Die bereinigte Punktzahl pro Spiel ermöglicht einen ganzheitlicheren Ansatz für die Bewertung von Spielern und bietet einen Weg für Spieler, die zuvor vielleicht übersehen wurden oder am Rande standen. Die bereinigten Punkte pro Spiel bieten bereits zahlreiche Anwendungsmöglichkeiten, aber auch andere Daten wie Scout-Ranglisten oder erwartete Tore usw. können verwendet werden. Mit detaillierteren Daten in der Zukunft über alle Ligen hinweg, kann diese Methode auch weiter verbessert werden.
Die Forschung in diesem Artikel wurde auch auf der CBJHAC20 von Katerina Wu vorgestellt. Die Folien finden Sie hier.
Folgen Sie uns auf Twitter @kattaqueue und @madelinejgall!