




¿Cómo de buenos son los encuestadores? Analizando el conjunto de datos de Five-Thirty-Eight
Analizamos el conjunto de datos del ranking de encuestadores de la venerable web de predicción política Five-Thirty-Eight.

Este es un año electoral y la escena de las encuestas en torno a las elecciones (tanto presidenciales generales como de la Cámara de Representantes y el Senado) se está calentando. Esto será cada vez más emocionante en los próximos días, con tweets, contra-tweets, peleas en las redes sociales, y un sinfín de pundonor en la televisión.
Sabemos que no todas las encuestas son de la misma calidad. Entonces, ¿cómo darle sentido a todo esto? ¿Cómo identificar a los encuestadores fiables utilizando datos y análisis?

En el mundo del análisis predictivo político (y de algunos otros asuntos como los deportes, los fenómenos sociales, la economía, etc.), Five-Thirty-Eight es un nombre formidable.
Desde principios de 2008, el sitio ha publicado artículos -normalmente creando o analizando información estadística- sobre una amplia variedad de temas de la actualidad política y las noticias políticas. El sitio web, dirigido por el científico de datos y estadístico Nate Silver, alcanzó especial prominencia y fama generalizada en torno a las elecciones presidenciales de 2012, cuando su modelo predijo correctamente el ganador de los 50 estados y el Distrito de Columbia.
Y antes de que te burles y digas «¿Pero qué pasa con las elecciones de 2016?», quizá te convenga leer este artículo sobre cómo la elección de Donald Trump estuvo dentro del margen de error normal de los modelos estadísticos.
Para los lectores más curiosos de la política, tienen todo un saco de artículos sobre las elecciones de 2016 aquí.
Los profesionales de la ciencia de los datos deberían aficionarse a Five-Thirty-Eight porque no rehúye explicar sus modelos predictivos en términos muy técnicos (al menos lo suficientemente complejos para los profanos).

Aquí se habla de adoptar la famosa distribución t, mientras que la mayoría de los demás agregadores de encuestas pueden contentarse con la omnipresente distribución Normal.
Sin embargo, yendo más allá del uso de sofisticadas técnicas de modelado estadístico, el equipo a cargo de Silver se enorgullece de una metodología única -la calificación de los encuestadores- para ayudar a que sus modelos sigan siendo muy precisos y fiables.
En este artículo, analizamos sus datos sobre estos métodos de calificación.
Cinco Treinta y Ocho no se priva de explicar sus modelos predictivos en términos muy técnicos (al menos lo suficientemente complejos para el profano).
Calificación y clasificación de los encuestadores
Hay una multitud de encuestadores que operan en este país. Leer y calibrar la calidad de las mismas puede ser muy agotador y díscolo. Según el sitio web, «leer encuestas puede ser peligroso para la salud. Los síntomas incluyen la selección de los resultados, el exceso de confianza, la aceptación de los números basura y los juicios apresurados. Afortunadamente, tenemos una cura». (fuente)
Hay encuestas. Luego, hay encuestas de encuestas. Luego, hay encuestas ponderadas de encuestas. Sobre todo, hay una encuesta de encuestas con ponderaciones que se modelan estadísticamente y cambian dinámicamente las ponderaciones.
¿Te suena familiar otra famosa metodología de clasificación de la que has oído hablar como científico de datos? El ranking de productos de Amazon o el ranking de películas de Netflix? Probablemente, sí.
Esencialmente, Five-Thirty-Eight utiliza este sistema de calificación/clasificación para ponderar los resultados de las encuestas (a los resultados de los encuestadores mejor clasificados se les da más importancia y tal y cual). También hacen un seguimiento activo de la precisión y las metodologías que hay detrás de los resultados de cada encuestador y ajustan su clasificación a lo largo del año.
Hay encuestas. Luego, hay encuestas de encuestas. Luego, hay encuestas ponderadas de encuestas. Sobre todo, hay una encuesta de encuestas con ponderaciones que se modelan estadísticamente y que cambian dinámicamente.
Es interesante observar que su metodología de clasificación no califica necesariamente como mejor a un encuestador con un mayor tamaño de muestra. La siguiente captura de pantalla de su página web lo demuestra claramente. Mientras que las encuestadoras como Rasmussen Reports y HarrisX tienen tamaños de muestra más grandes, es, de hecho, el Marist College, el que obtiene la calificación A+ con un tamaño de muestra modesto.
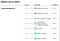
Afortunadamente, también abren sus datos de clasificación de encuestadores (junto con casi todos sus otros conjuntos de datos) aquí en Github. Y si sólo te interesa una tabla bonita, aquí la tienes.
Naturalmente, como científico de datos, es posible que quieras profundizar en los datos en bruto y entender cosas como,
- cómo se correlaciona su clasificación numérica con la precisión de los encuestadores
- si tienen un sesgo partidista hacia la selección de encuestadores particulares (en la mayoría de los casos, pueden ser categorizados como de tendencia demócrata o republicana)
- ¿quiénes son los encuestadores mejor clasificados? ¿Realizan muchos sondeos o son selectivos?
Intentamos analizar el conjunto de datos para adquirir tales conocimientos. Vamos a profundizar en el código y los resultados, ¿de acuerdo?
El análisis
Puedes encontrar el Jupyter Notebook aquí en mi repo de Github.
La fuente
Para empezar, puedes sacar los datos directamente de su Github, en un Pandas DataFrame, como sigue,

Hay 23 columnas en este conjunto de datos. Así es como se ven,

Algunas transformaciones y limpieza
Notamos que una columna tiene algún espacio extra. Otras pocas pueden necesitar alguna extracción y conversión de tipo de datos.



Después de aplicar esta extracción, el nuevo DataFrame tiene columnas adicionales, lo que lo hace más adecuado para el filtrado y el modelado estadístico.

Examinando y cuantificando la columna «538 Grade»
La columna «538 Grades» contiene el quid del conjunto de datos: la letra de la calificación del encuestador. Al igual que en un examen normal, A+ es mejor que A, y A es mejor que B+. Si trazamos los recuentos de las calificaciones de las letras, observamos 15 gradaciones, en total, de A+ a F.

En lugar de trabajar con tantas gradaciones categóricas, podríamos combinarlas en un pequeño número de calificaciones numéricas – 4 para A+/A/A-, 3 para las B, etc.

Boxplots
Entrando en el análisis visual, podemos empezar con los boxplots.
Supongamos que queremos comprobar qué método de sondeo rinde más en términos de error de predicción. El conjunto de datos tiene una columna llamada «Error medio simple», que se define como «El error medio de la firma, calculado como la diferencia entre el resultado encuestado y el resultado real para el margen que separa a los dos primeros clasificados en la carrera.»

Entonces, nos puede interesar comprobar si los encuestadores con un determinado sesgo partidista aciertan más que otros en las elecciones.

¿Notas algo interesante arriba? Si usted es un pensador progresista y liberal, con toda probabilidad, puede ser partidario del partido demócrata. Pero, en promedio, las encuestadoras con inclinación republicana, califican las elecciones con más precisión y con menos variabilidad. Más vale tener cuidado con esas encuestas!
Otra columna interesante en el conjunto de datos se llama «NCPP/AAPOR/Roper». En ella se «indica si la empresa encuestadora era miembro del National Council on Public Polls, signataria de la iniciativa de transparencia de la American Association for Public Opinion Research o colaboradora del archivo de datos del Roper Center for Public Opinion Research». Efectivamente, una afiliación indica la adhesión a una metodología de sondeo más sólida» (fuente).
¿Cómo juzgar la validez de la afirmación anterior? El conjunto de datos tiene una columna llamada «Plus-Minus avanzado», que es «una puntuación que compara el resultado de un encuestador con el de otras empresas de sondeo de las mismas carreras y que pondera más los resultados recientes. Las puntuaciones negativas son favorables e indican una calidad superior a la media» (fuente).
Aquí hay un boxplot entre estos dos parámetros. No sólo los encuestadores, asociados a NCCP/AAPOR/Roper, exhiben una puntuación de error más baja, sino que también muestran una variabilidad considerablemente baja. Sus predicciones parecen ser estables y robustas.

Si usted es un pensador progresista y liberal, con toda probabilidad, puede ser partidario del partido demócrata. Pero, por término medio, los encuestadores con sesgo republicano, califican las elecciones con más precisión y con menos variabilidad.
Participaciones de dispersión y regresión
Para entender la correlación entre los parámetros, podemos observar las participaciones de dispersión con ajuste de regresión. Usamos las bibliotecas Seaborn y Scipy Python y una función personalizada para generar estos gráficos.
Por ejemplo, podemos relacionar las «Carreras Llamadas Correctamente» con el «Plus-Minus Predictivo». Según Five-Thirty-Eight, el «Predictive Plus-Minus» es «una proyección de lo acertado que será el encuestador en futuras elecciones. Se calcula revirtiendo la puntuación del Plus-Minus Avanzado de un encuestador a una media basada en nuestros indicadores de calidad metodológica.» (fuente)

O bien, podemos comprobar cómo la «Calificación Numérica» que definimos, se correlaciona con la media de errores de las encuestas. Una tendencia negativa indica que una calificación numérica más alta está asociada a un menor error en las encuestas.

También podemos comprobar si el «# de encuestas para el análisis de sesgo» ayuda a reducir el «Grado de sesgo partidista» que se asigna a cada encuestador. Podemos observar una relación descendente, lo que indica que la disponibilidad de un elevado número de encuestas sí ayuda a reducir el grado de sesgo partidista. Sin embargo, la relación parece muy poco lineal y una escala logarítmica habría sido mejor para ajustar la curva.

¿Se debe confiar más en los encuestadores más activos? Trazamos el histograma del número de encuestas y vemos que sigue una ley de potencia negativa. Podemos filtrar los encuestadores con números muy bajos y muy altos de encuestas y crear un gráfico de dispersión personalizado. Sin embargo, observamos una correlación casi inexistente entre el número de sondeos y la puntuación del Plus-Minus Predictivo. Por lo tanto, un gran número de encuestas no conduce necesariamente a una alta calidad de las encuestas y al poder predictivo.