




Enterprise Data Warehouse: Conceptos, arquitectura y componentes
Tiempo de lectura: 12 minutos
A lo largo del día tomamos muchas decisiones basándonos en experiencias anteriores. Nuestro cerebro almacena billones de datos sobre acontecimientos pasados y aprovecha esos recuerdos cada vez que tenemos que tomar una decisión. Al igual que las personas, las empresas generan y recogen toneladas de datos sobre el pasado. Y estos datos pueden utilizarse para tomar mejores decisiones.
Mientras que nuestro cerebro sirve tanto para procesar como para almacenar, las empresas necesitan múltiples herramientas para trabajar con los datos. Y una de las más importantes es un almacén de datos.
En este artículo, hablaremos de qué es un almacén de datos empresarial, sus tipos y funciones, y cómo se utiliza en el procesamiento de datos. Definiremos en qué se diferencian los almacenes empresariales de los habituales, qué tipos de almacenes de datos existen y cómo funcionan. El enfoque es proporcionar información sobre el valor empresarial de cada enfoque arquitectónico y conceptual para construir un almacén.
¿Qué es un almacén de datos empresarial?
Si sabes cuánto es un terabyte, probablemente te impresionará el hecho de que Netflix tenía unos 44 terabytes de datos en su almacén allá por 2016. El tamaño por sí solo insinúa por qué lo llamamos un almacén, en lugar de sólo una base de datos. Así que empecemos por lo básico.
Un almacén de datos empresariales (EDW) es una forma de repositorio corporativo que almacena y gestiona todos los datos empresariales históricos de una empresa. La información suele proceder de diferentes sistemas como ERPs, CRMs, registros físicos y otros archivos planos. Para preparar los datos para su posterior análisis, deben colocarse en un único almacén. De este modo, diferentes unidades de negocio pueden consultarlo y analizar la información desde múltiples ángulos.
Con un almacén de datos, una empresa puede gestionar enormes conjuntos de datos, sin necesidad de administrar múltiples bases de datos. Esta práctica es una forma de almacenamiento de datos a prueba de futuro para la inteligencia empresarial (BI), que es un conjunto de métodos/tecnologías de transformación de datos brutos en conocimientos procesables. Siendo el EDW una parte importante del mismo, el sistema es similar a un cerebro humano que almacena información, pero con esteroides.
Almacén de datos empresarial vs almacén de datos habitual: ¿cuál es la diferencia?
Cualquier almacén de datos es una base de datos que siempre está conectada con las fuentes de datos en bruto a través de herramientas de integración de datos en un extremo y de interfaces analíticas en el otro. Si es así, ¿por qué aislamos la forma empresarial para la discusión?
Cualquier almacén proporciona un almacenamiento que tiene mecanismos para transformar los datos, moverlos y presentarlos al usuario final. La diferencia entre un almacén de datos habitual y uno empresarial radica en su diversidad arquitectónica y funcionalidad, mucho más amplia. Debido a su compleja estructura y tamaño, los EDW suelen descomponerse en bases de datos más pequeñas, por lo que los usuarios finales se sienten más cómodos consultando estas bases de datos más pequeñas. Teniendo en cuenta esto, nos centramos en un almacén empresarial para cubrir todo el espectro de funcionalidad.
Sin embargo, el tamaño de un almacén no define su complejidad técnica, los requisitos de las capacidades analíticas y de elaboración de informes, el número de modelos de datos y los propios datos. Por lo tanto, para entender lo que hace que un almacén sea un almacén, vamos a sumergirnos en sus conceptos y funciones básicas.
Conceptos y funciones de los almacenes de datos empresariales
Con todas las campanas y silbatos, en el corazón de cada almacén yacen conceptos y funciones básicas. Estos pilares definen un almacén como fenómeno tecnológico:
Sirve de almacenamiento por excelencia. Un almacén de datos empresarial es un repositorio unificado para todos los datos empresariales que se producen en la organización.
Refleja los datos de origen. El EDW se nutre de los datos de sus espacios de almacenamiento originales como Google Analytics, CRMs, dispositivos IoT, etc. Si los datos están dispersos en múltiples sistemas, es inmanejable. Por lo tanto, el propósito de EDW es proporcionar la semejanza de los datos de la fuente original en un único repositorio. Como siempre hay datos nuevos y relevantes generados tanto dentro como fuera de la empresa, el flujo de datos requiere una infraestructura dedicada a gestionarlos antes de que entren en un almacén.
Almacena datos estructurados. Los datos almacenados en un EDW están siempre estandarizados y estructurados. Esto hace posible que los usuarios finales los consulten a través de interfaces de BI y formen informes. Y esto es lo que diferencia a un almacén de datos de un lago de datos. Los lagos de datos se utilizan para almacenar datos no estructurados con fines analíticos. Pero a diferencia de los almacenes, los lagos de datos son utilizados más por los ingenieros/científicos de datos para trabajar con grandes conjuntos de datos en bruto.
Datos orientados al negocio. El foco principal de un almacén son los datos de negocio que pueden relacionarse con diferentes dominios. Para entender con qué se relacionan los datos, siempre se estructuran en torno a un tema específico llamado modelo de datos. Un ejemplo de tema puede ser una región de ventas o las ventas totales de un artículo determinado. Además, se añaden metadatos para explicar con detalle de dónde procede cada dato.
Dependiente del tiempo. Los datos recogidos suelen ser datos históricos, ya que describen acontecimientos pasados. Para entender cuándo y durante cuánto tiempo tuvo lugar una determinada tendencia, la mayoría de los datos almacenados suelen dividirse en períodos de tiempo.
No volátil. Una vez colocados en un almacén, los datos nunca se borran de él. Los datos pueden ser manipulados, modificados o actualizados debido a cambios en la fuente, pero nunca están destinados a ser borrados, al menos por los usuarios finales. Al hablar de datos históricos, los borrados son contraproducentes para los fines analíticos. Sin embargo, las revisiones generales pueden ocurrir una vez cada pocos años para deshacerse de los datos irrelevantes.
Considerando los principios básicos, veremos los tipos de implementación de los DW.
Tipos de almacenes de datos
Considerando las funciones de los EDW, siempre hay un espacio para la discusión sobre cómo diseñarlo técnicamente. En el caso del almacenamiento y procesamiento de datos, son específicos y distintos para diferentes tipos de empresas. Dependiendo de la cantidad de datos, la complejidad analítica, las cuestiones de seguridad y el presupuesto, por supuesto, siempre hay una opción sobre cómo configurar su sistema.
Almacén de datos clásico
El almacenamiento unificado que tiene su hardware y software dedicado se considera una variante clásica para un EDW. Con el almacenamiento físico, no es necesario configurar herramientas de integración de datos entre varias bases de datos. En su lugar, el EDW puede conectarse con las fuentes de datos a través de las API para obtener información constantemente y transformarla en el proceso. Así, todo el trabajo se realiza o bien en el área de staging (el lugar donde se transforman los datos antes de cargarlos en el DW), o bien en el propio almacén.
Un almacén de datos clásico se considera superlativo a uno virtual (del que hablamos más adelante), porque no hay ninguna capa adicional de abstracción. Simplifica el trabajo de los ingenieros de datos y facilita la gestión del flujo de datos en la parte de preprocesamiento, así como la elaboración de informes reales. Los inconvenientes del almacén clásico dependen de la implementación real, pero para la mayoría de las empresas son:
- Infraestructura tecnológica costosa, tanto de hardware como de software;
- Contratación de un equipo de ingenieros de datos y especialistas en DevOps para configurar y mantener toda la plataforma de datos.
Cuándo utilizarlo: apropiado para organizaciones de todos los tamaños que quieran procesar sus datos y hacer uso de ellos. Los almacenes clásicos permiten transformarse en diferentes estilos arquitectónicos de la plataforma de datos, así como escalar hacia arriba y hacia abajo a propósito.
Almacén de datos virtual
Un almacén de datos virtual es un tipo de EDW utilizado como alternativa a un almacén clásico. Esencialmente, se trata de múltiples bases de datos conectadas virtualmente, por lo que pueden ser consultadas como un único sistema.
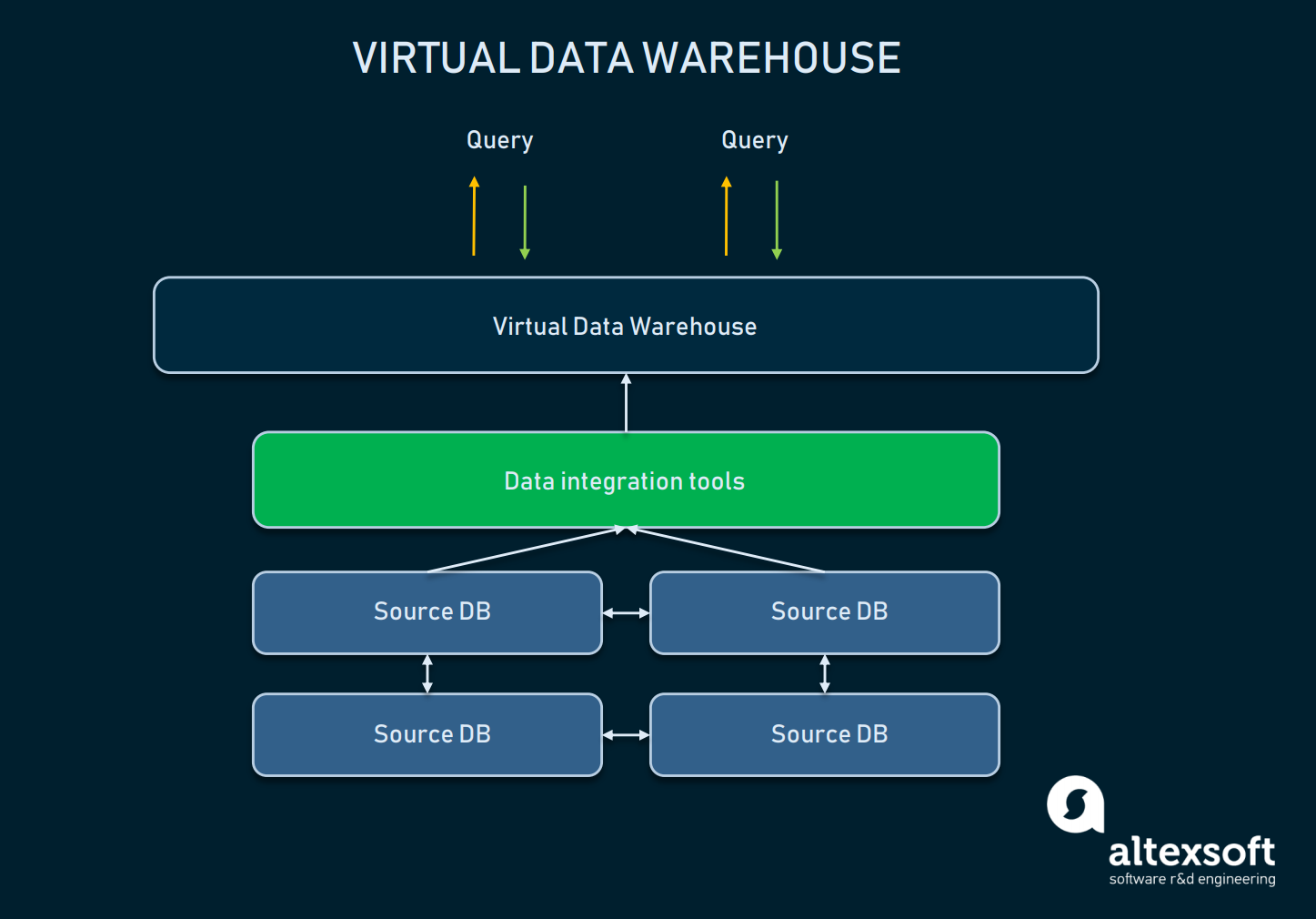
Un esquema de relaciones entre la abstracción del DW virtual y las bases de datos fuente
Tal enfoque permite a las organizaciones mantener la sencillez: Los datos pueden permanecer en sus fuentes, pero aún pueden ser extraídos con la ayuda de herramientas analíticas. Los almacenes virtuales se pueden utilizar si no se quiere complicar con toda la infraestructura subyacente, o si los datos que se tienen son fácilmente manejables tal y como están. Sin embargo, este enfoque tiene muchos inconvenientes:
- Las múltiples bases de datos requerirán un mantenimiento y costes constantes de software y hardware.
- Los datos almacenados en un DW virtual siguen necesitando un software de transformación para hacerlos digeribles para los usuarios finales y las herramientas de informes.
- Las consultas de datos complejas pueden llevar demasiado tiempo, ya que los datos necesarios pueden colocarse en dos bases de datos distintas.
Cuándo utilizarlo: es adecuado para las empresas que tienen datos en bruto de forma estandarizada que no requieren análisis complejos. También se adapta a las organizaciones que no utilizan el BI de forma sistemática, o que quieren empezar con él.
Cloud Data Warehouse
Desde hace una década, las tecnologías en la nube/sin nubes se han convertido en un estándar para establecer tecnologías a nivel de organización. Encontrarás innumerables proveedores en el mercado que ofrecen warehousing-as-a-service. Por nombrar algunos:
- Amazon Redshift/ Página de precios
- IBM Db2/ Página de precios
- Google BigQuery/ Página de precios
- Snowflake/ Página de precios
- Microsoft SQL Data Warehouse/ Página de precios
Todos los proveedores mencionados ofrecen warehousing totalmente gestionado, escalable como parte de sus herramientas de BI, o se centran en EDW como un servicio independiente, como hace Snowflake. En este caso, la arquitectura de almacén en la nube tiene las mismas ventajas que cualquier otro servicio en la nube. Su infraestructura se mantiene por usted, lo que significa que no necesita configurar sus propios servidores, bases de datos y herramientas para gestionarla. El precio de este servicio dependerá de la cantidad de memoria requerida y de las capacidades informáticas de consulta.
El único aspecto que podría preocuparle en cuanto a una plataforma de almacén en la nube es la seguridad de los datos. Los datos de su empresa son algo sensible. Por lo tanto, querrá comprobar si el proveedor que ha elegido es de confianza para evitar filtraciones. Esto no significa necesariamente que un almacén on-premise sea más seguro, pero en este caso, la seguridad de sus datos está en sus manos.
Cuándo utilizar: Las plataformas en la nube son una gran opción para organizaciones de cualquier tamaño. Si necesita que todo se configure por usted, incluyendo la integración de datos gestionada, el mantenimiento del DW y el soporte de BI.
Arquitectura de almacenes de datos empresariales
Aunque hay muchos enfoques arquitectónicos que amplían las capacidades de los almacenes de una manera u otra, nos centraremos en los más esenciales. Sin entrar en demasiados detalles técnicos, toda la cadena de datos puede dividirse en tres capas:
- Capa de datos brutos (fuentes de datos)
- Almacén y su ecosistema
- Interfaz de usuario (herramientas analíticas)
Las herramientas que se ocupan de la extracción, transformación y carga de datos en un almacén constituyen una categoría aparte de herramientas conocidas como ETL. Además, bajo el paraguas de ETL, las herramientas de integración de datos realizan manipulaciones con los datos antes de colocarlos en un almacén. Estas herramientas operan entre una capa de datos brutos y un almacén.
Cuando los datos se cargan en un almacén, también pueden ser transformados. Por lo tanto, el almacén requerirá cierta funcionalidad para la limpieza/estandarización/dimensionalización. Estos y otros factores determinarán la complejidad de la arquitectura. Veremos la arquitectura EDW desde el punto de vista de las necesidades crecientes de la organización.
Arquitectura de un nivel
Dado que la integración de datos está bien configurada, podemos elegir nuestro almacén de datos. En la mayoría de los casos, un almacén de datos es una base de datos relacional con módulos para permitir datos multidimensionales, o uno que puede separar alguna información específica del dominio para facilitar el acceso. En su forma más primitiva, el almacén puede tener sólo una arquitectura de un nivel.
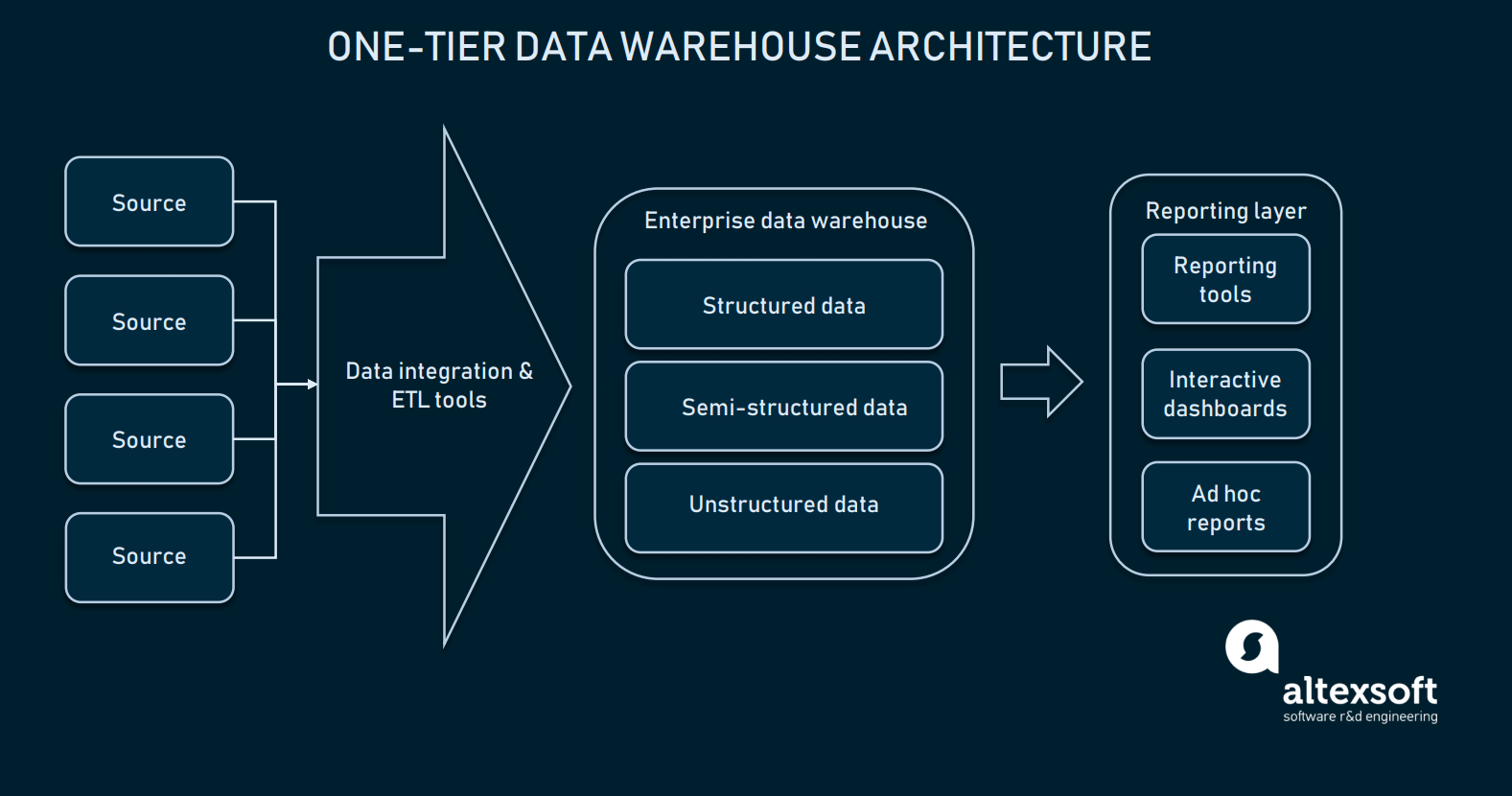
La capa de informes está conectada directamente con toda la base de datos del EDW
La arquitectura de un nivel para el EDW significa que tiene una base de datos conectada directamente con las interfaces analíticas donde el usuario final puede hacer consultas. Establecer la conexión directa entre un EDW y las herramientas analíticas conlleva varios retos:
- Tradicionalmente, se puede considerar que su almacenamiento es un almacén a partir de 100GB de datos. Trabajar con él directamente puede dar lugar a resultados de consulta desordenados, así como a una baja velocidad de procesamiento.
- La consulta de datos directamente desde el DW puede requerir una entrada precisa, para que el sistema sea capaz de filtrar los datos no requeridos. Lo que dificulta un poco el manejo de las herramientas de presentación.
- Existen capacidades limitadas de flexibilidad/analítica.
Además, la arquitectura de un solo nivel establece algunos límites a la complejidad de los informes. Este enfoque rara vez se utiliza para plataformas de datos a gran escala, debido a su lentitud e imprevisibilidad. Para realizar consultas de datos avanzadas, un almacén puede ampliarse con instancias de bajo nivel que faciliten el acceso a los datos.
Arquitectura de dos niveles (capa de data mart)
En la arquitectura de dos niveles, se añade un nivel de data mart entre la interfaz de usuario y el EDW. Un data mart es un repositorio de bajo nivel que contiene información específica del dominio. En pocas palabras, es otra base de datos de menor tamaño que amplía el EDW con información dedicada a sus departamentos de ventas/operaciones, marketing, etc.
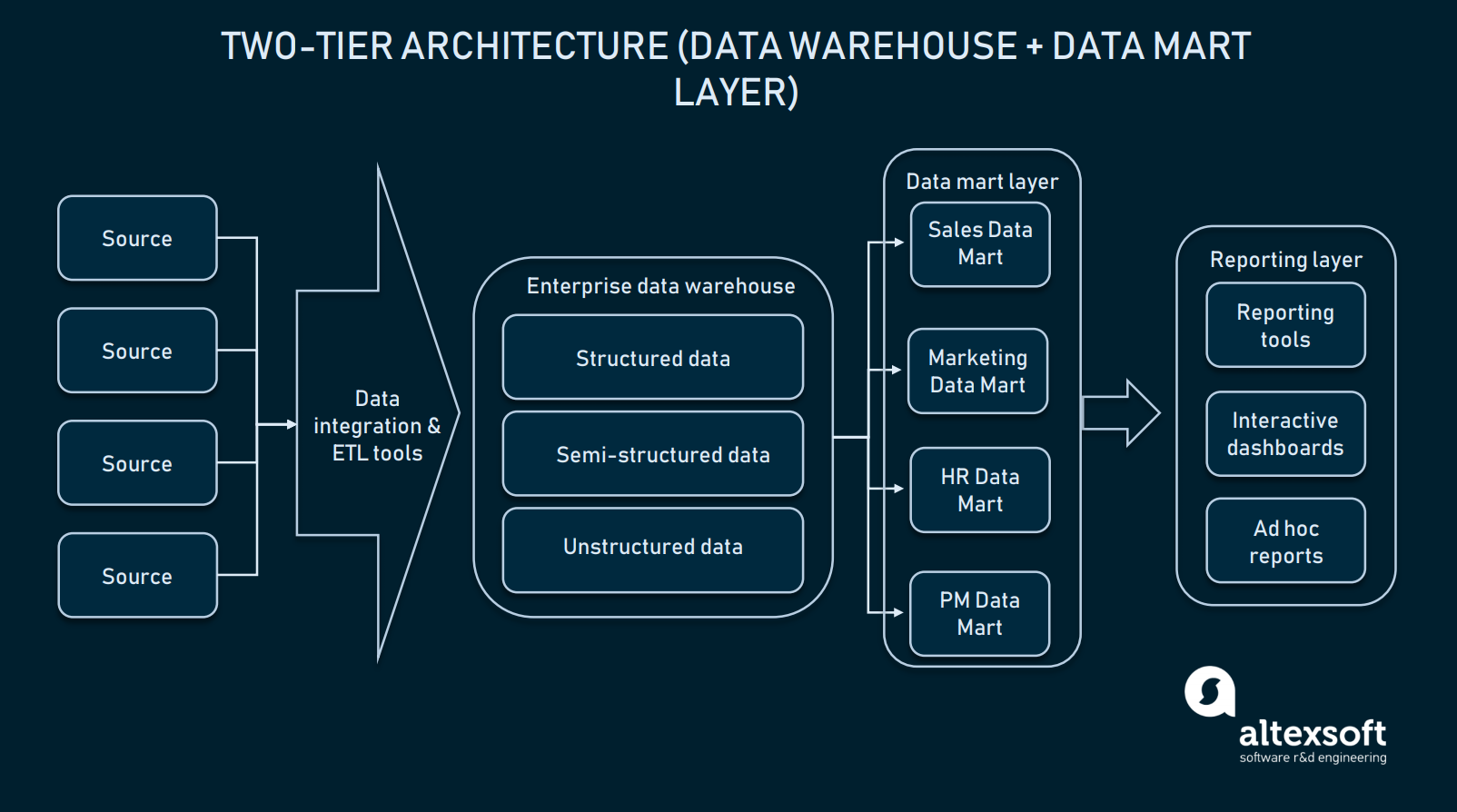
En la arquitectura de dos niveles, un EDW se amplía con data marts para proporcionar datos específicos del dominio
La creación de la capa de data mart requerirá recursos adicionales para establecer el hardware e integrar esas bases de datos con el resto de la plataforma de datos. Sin embargo, este enfoque resuelve el problema de las consultas: Cada departamento accederá más fácilmente a los datos necesarios porque un determinado mart contendrá sólo información específica del dominio. Además, los marts de datos limitarán el acceso a los datos para los usuarios finales, haciendo que el EDW sea más seguro.
Arquitectura de tres niveles (Procesamiento analítico en línea)
Encima de la capa del mart de datos, las empresas también utilizan cubos de procesamiento analítico en línea (OLAP). Un cubo OLAP es un tipo específico de base de datos que representa datos de múltiples dimensiones. Mientras que las bases de datos relacionales representan los datos en sólo dos dimensiones (piense en Excel o Google Sheets), OLAP permite compilar datos en múltiples dimensiones y moverse entre ellas.
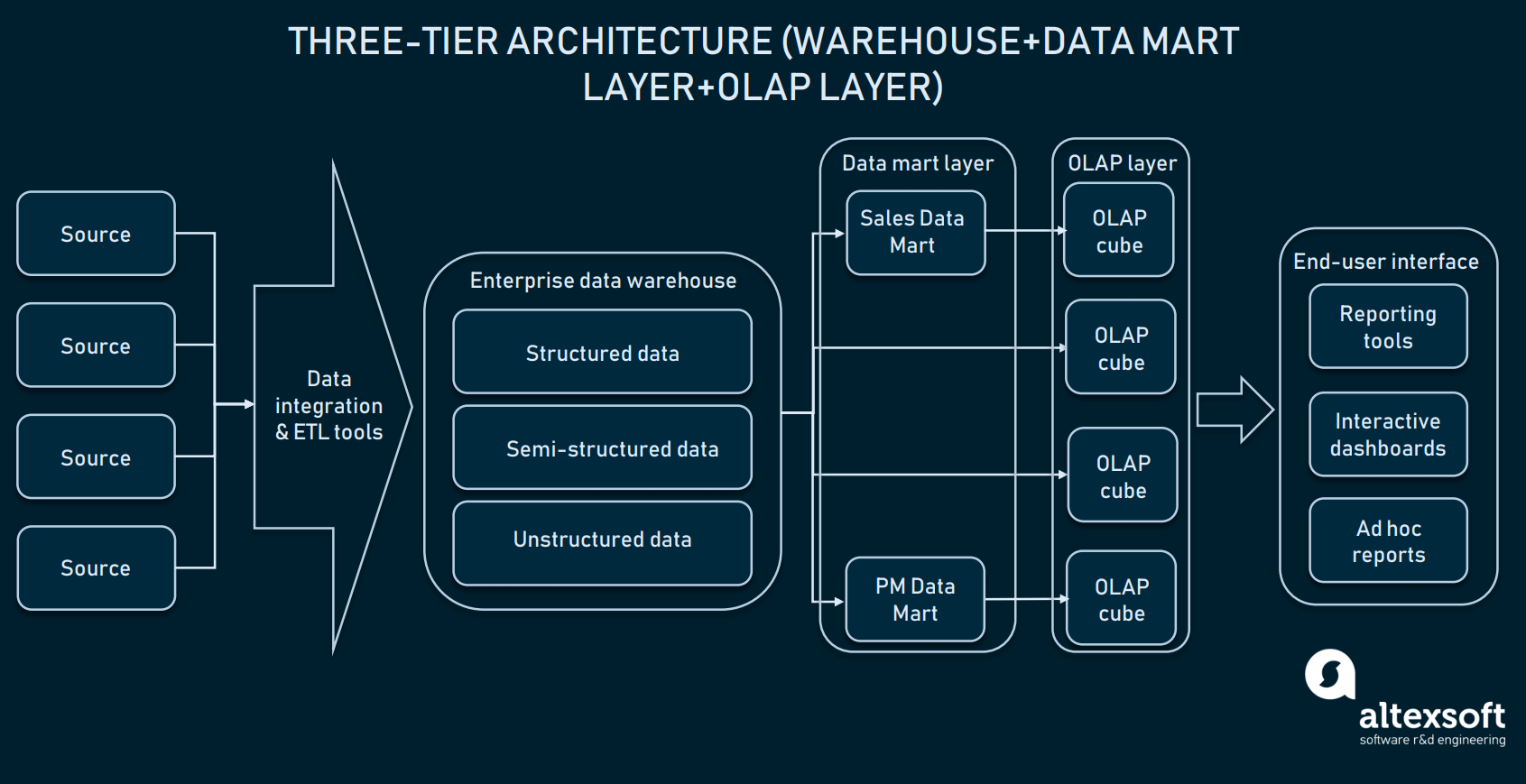
La capa de cubos OLAP puede obtener información de los marts distribuidos o directamente del EDW
Es bastante difícil de explicar con palabras, así que veamos este práctico ejemplo de cómo puede ser un cubo.
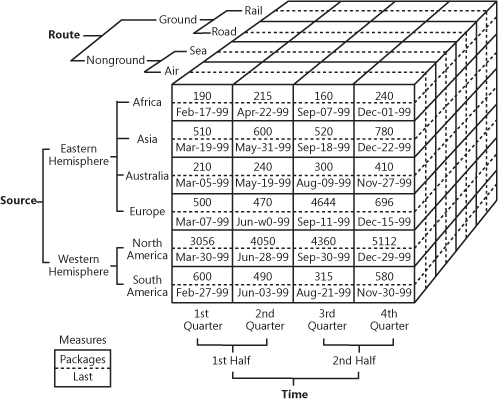
Cubo OLAP que demuestra datos de ventas multidimensionales
Fuente: oreilly.com
Así que, como puede ver, un cubo añade dimensiones a los datos. Puede pensar en él como varias tablas de Excel combinadas entre sí. La parte delantera del cubo es la habitual tabla bidimensional, en la que la región (África, Asia, etc.) se especifica verticalmente, mientras que los números de ventas y las fechas se escriben horizontalmente. La magia comienza cuando miramos la faceta superior del cubo, donde las ventas se segmentan por rutas y en la parte inferior se especifica el periodo de tiempo. Esto es lo que se conoce como datos multidimensionales.
El valor empresarial de OLAP es que permite a los usuarios cortar los datos para elaborar informes detallados. Siempre que los cubos estén optimizados para trabajar con almacenes, pueden utilizarse tanto directamente con un EDW para dar acceso a todos los datos corporativos como con cada data mart específicamente. En términos de implementación, casi todos los proveedores de almacenes ofrecen OLAP como servicio. Como ejemplo, consulte la documentación de Microsoft sobre su oferta de OLAP.
En este punto, hemos discutido un diseño de alto nivel de un EDW aplicado a las necesidades de la organización. Ahora vamos a profundizar en los componentes técnicos que puede incluir un almacén.
Data Warehouse vs Data Lake vs Data Mart
Hablando de la arquitectura de almacenamiento de datos, tenemos que mencionar opciones como utilizar un data mart o un data lake en lugar de un almacén. A menudo se confunden, por lo que vamos a elaborar las definiciones.
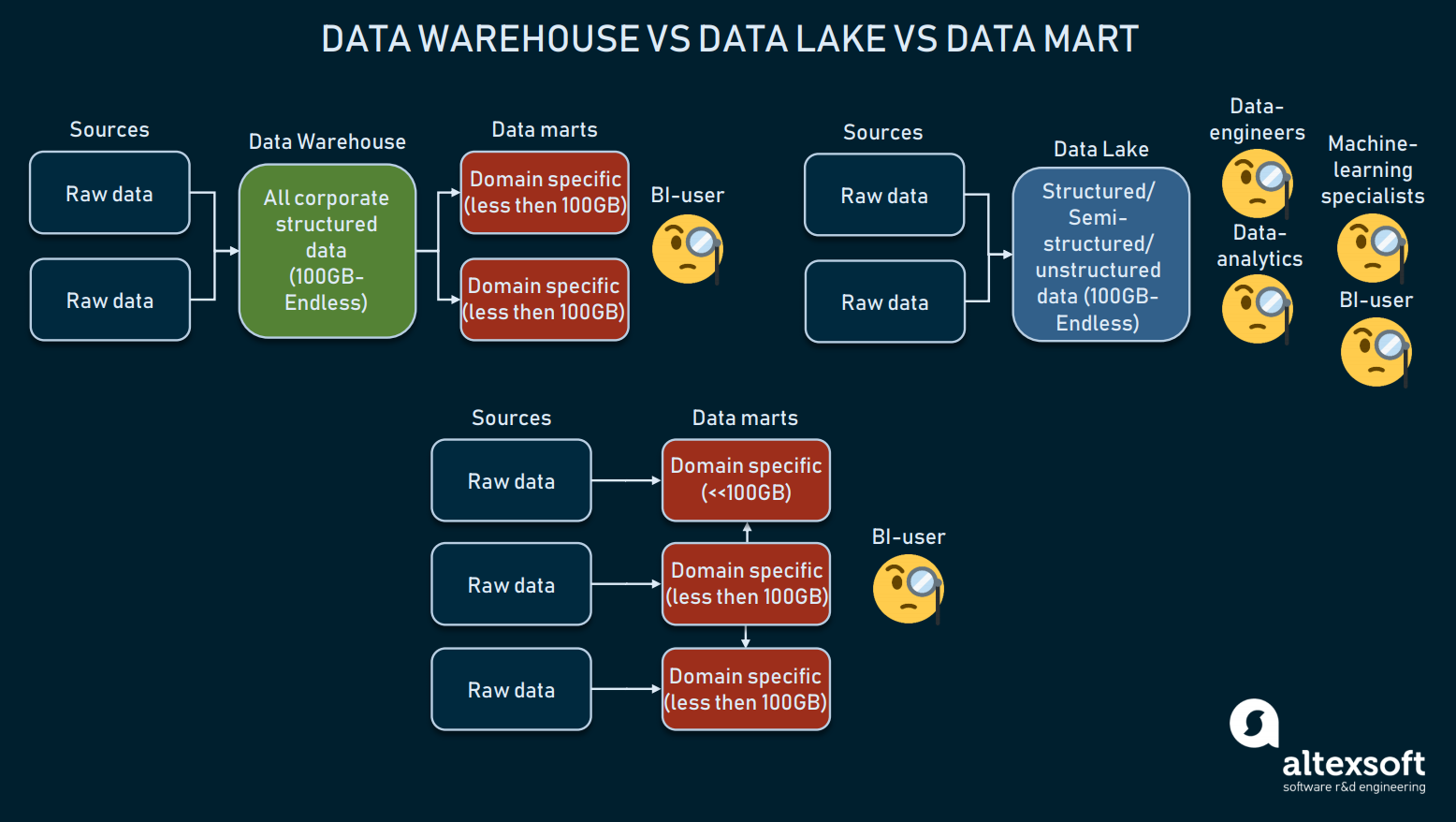
La comparación de tres formas de almacenamiento de datos
Los almacenes de datos están destinados a almacenar datos estructurados, para que las herramientas de consulta y los usuarios finales puedan obtener resultados completos. Los almacenes, utilizados sobre todo para el BI, suelen tener un tamaño que oscila entre los 100 GB y el infinito.
Los lagos de datos, sin embargo, se utilizan para almacenar sobre todo datos brutos o mixtos. Suelen aprovecharse para fines de aprendizaje automático, big data o minería de datos. Desde hace un par de años, los lagos de datos se utilizan para el BI: los datos brutos se cargan en un lago y se transforman, lo que constituye una alternativa al proceso ETL. Si bien este enfoque tiene sus pros y sus contras, los lagos de datos pueden ser demasiado desordenados para llegar a los datos estructurados.
Entonces tenemos los marts de datos, que también pueden ser utilizados como una alternativa al DW. Estos modelos (como el de Kimball) suponen el uso de múltiples data marts para distribuir la información por dominios y conectarse entre sí. Pero, debido a su pequeño tamaño (normalmente menos de 100 GB), los data marts apenas pueden ser utilizados por las empresas. Más a menudo, los data marts se utilizan para segmentar un gran DW en otros más operables.
Componentes del Data Warehouse Empresarial
Hay una gran cantidad de instrumentos utilizados para configurar una plataforma de warehousing. Ya hemos mencionado la mayoría de ellos, incluyendo un almacén en sí. Así que, vamos a ver a vista de pájaro el propósito de cada componente y sus funciones.
Fuentes. Eso es simple, las bases de datos donde se almacenan los datos en bruto.
Capa de extracción, transformación y carga (ETL) o Extract, Load, Transform (ELT). Son las herramientas que realizan la conexión real con los datos de origen, su extracción y carga al lugar donde serán transformados. La transformación unifica el formato de los datos. Los enfoques ETL y ELT se diferencian en que en el ETL la transformación se realiza antes del EDW, en una zona de preparación. ELT es un enfoque más moderno que se encarga de toda la transformación en un almacén.
Área de preparación. En el caso de ETL, el área de staging es el lugar donde se cargan los datos antes del EDW. Aquí se limpiarán y transformarán a un modelo de datos determinado. El área de staging también puede incluir herramientas para la gestión de la calidad de los datos.
Base de datos EDW. Los datos se cargan finalmente en el espacio de almacenamiento. En el ELT, puede que todavía se necesite alguna transformación aquí. Pero, en esa etapa, se aplicarán todos los cambios generales, por lo que los datos se cargarán en su(s) modelo(s) final(es). Como hemos mencionado, los almacenes de datos suelen ser bases de datos relacionales. El DW también incluirá un sistema de gestión de bases de datos y un almacenamiento adicional para los metadatos.
Módulo de metadatos. En pocas palabras, los metadatos son datos sobre datos. Son las explicaciones que dan pistas a los usuarios/administradores de a qué tema/dominio se refiere esta información. Estos datos pueden ser meta técnicos (por ejemplo, la fuente inicial), o meta comerciales (por ejemplo, la región de ventas). Toda la meta se almacena en un módulo separado de EDW y es gestionada por un gestor de metadatos.
Capa de informes. Son las herramientas que dan acceso a los datos a los usuarios finales. También llamada interfaz de BI, esta capa servirá como cuadro de mando para visualizar los datos, formar informes y extraer piezas de información por separado.
Pensamiento final
Comprender la cadena de herramientas que transmiten los datos puede ayudarle a averiguar lo que realmente se ajusta a los requisitos de su plataforma de datos. La planificación de la creación de un almacén puede requerir años de planificación y pruebas, debido a su escala en su forma más básica.
Como propietario de una empresa, es posible que se sienta confundido por la cantidad de opciones y tecnologías utilizadas, por lo que es vital consultar con expertos en el campo del almacenamiento, ETL y BI. Mientras que los expertos pueden ayudarle con el aspecto técnico, para definir el propósito del negocio, hable con los que utilizarán los datos reales en su trabajo.