




Introducción al diseño de bases de datos
Identificación de atributos
Los elementos de datos que se quieren guardar para cada entidad se llaman «atributos».
Sobre los productos que vende, quiere saber, por ejemplo, cuál es el precio, cuál es el nombre del fabricante y cuál es el número de tipo. Sobre los clientes se sabe su número de cliente, su nombre y su dirección. De las tiendas sabes el código de ubicación, el nombre y la dirección. De las ventas sabes cuándo se produjeron, en qué tienda, qué productos se vendieron y la suma total de la venta. Del vendedor conoces su número de personal, su nombre y su dirección. Lo que se incluirá precisamente no es de importancia todavía; se trata sólo de lo que se quiere guardar.
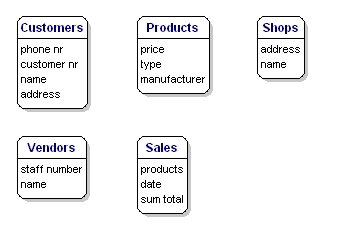
Figura 6: Entidades con atributos.
Datos derivados
Los datos derivados son datos que se derivan de los otros datos que ya has guardado. En este caso, la «suma total» es un caso clásico de datos derivados. Usted sabe exactamente lo que se ha vendido y lo que cuesta cada producto, por lo que siempre puede calcular cuánto es la suma total de las ventas. Así que realmente no es necesario guardar la suma total.
¿Entonces por qué se guarda aquí? Pues porque es una venta, y el precio del producto puede variar en el tiempo. Un producto puede tener un precio de 10 euros hoy y de 8 euros el mes que viene, y para su administración necesita saber lo que costaba en el momento de la venta, y la forma más fácil de hacerlo es guardarlo aquí. Hay muchas formas más elegantes, pero son demasiado profundas para este artículo.
Presentación de Entidades y Relaciones: Diagrama de Relación de Entidades (ERD)
El Diagrama de Relación de Entidades (ERD) da una visión gráfica de la base de datos. Hay varios estilos y tipos de diagramas ER. Una notación muy utilizada es la notación «pata de gallo», en la que las entidades se representan como rectángulos y las relaciones entre las entidades se representan como líneas entre las entidades. Los signos al final de las líneas indican el tipo de relación. El lado de la relación que es obligatorio para que el otro exista se indicará mediante un guión en la línea. Las entidades no obligatorias se indican mediante un círculo. «Muchos» se indica a través de una ‘pata de gallo’; la línea de relación se divide en tres líneas.
En este artículo hacemos uso de DeZign for Databases para diseñar y presentar nuestra base de datos.
Una relación obligatoria 1:1 se representa de la siguiente manera:
Figura 7: Relación obligatoria uno a uno.
Una relación obligatoria 1:N:
Figura 8: Relación obligatoria uno a muchos.
Una relación M:N es:
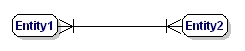
Figura 9: Relación obligatoria de muchos a muchos.
El modelo de nuestro ejemplo tendrá este aspecto:
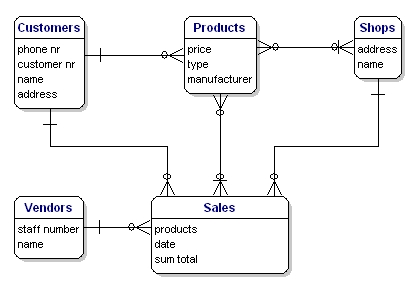
Figura 10: Modelo con relaciones.
Asignación de claves
Claves primarias
Una clave primaria (PK) es uno o más atributos de datos que identifican de forma exclusiva a una entidad. Una clave que consta de dos o más atributos se denomina clave compuesta. Todos los atributos que forman parte de una clave primaria deben tener un valor en cada registro (que no puede dejarse vacío) y la combinación de los valores dentro de estos atributos debe ser única en la tabla.
En el ejemplo hay algunos candidatos obvios para la clave primaria. Los clientes tienen todos un número de cliente, los productos tienen todos un número de producto único y las ventas tienen un número de ventas. Cada uno de estos datos es único y cada registro contendrá un valor, por lo que estos atributos pueden ser una clave primaria. A menudo se utiliza una columna de números enteros para la clave primaria, de modo que un registro se puede encontrar fácilmente a través de su número.
Las entidades de enlace suelen referirse a los atributos de clave primaria de las entidades que enlazan. La clave primaria de una entidad de enlace suele ser una colección de estos atributos de referencia. Por ejemplo, en la entidad Sales_details podríamos utilizar la combinación de las PK’s de las entidades sales y products como PK de Sales_details. De este modo, se garantiza que el mismo producto (tipo) sólo puede utilizarse una vez en la misma venta. Múltiples artículos del mismo tipo de producto en una venta deben ser indicados por la cantidad.
En el ERD los atributos de clave primaria se indican con el texto ‘PK’ detrás del nombre del atributo. En el ejemplo sólo la entidad ‘tienda’ no tiene un candidato obvio para la PK, por lo que introduciremos un nuevo atributo para esa entidad: shopnr.
Claves foráneas
La clave foránea (FK) en una entidad es la referencia a la clave primaria de otra entidad. En el ERD ese atributo se indicará con ‘FK’ detrás de su nombre. La clave foránea de una entidad también puede ser parte de la clave primaria, en ese caso el atributo se indicará con ‘PF’ detrás de su nombre. Este suele ser el caso de las entidades de enlace, ya que normalmente se vinculan dos instancias una sola vez (con 1 venta sólo se vende 1 tipo de producto 1 vez).
Si ponemos todas las entidades de enlace, PK’s y FK’s en el ERD, obtenemos el modelo que se muestra a continuación. Tenga en cuenta que el atributo «productos» ya no es necesario en «Ventas», porque «productos vendidos» está ahora incluido en la tabla de enlaces. En la tabla de enlaces se ha añadido otro campo, «cantidad», que indica cuántos productos se han vendido. El campo «cantidad» también se ha añadido en la tabla de existencias, para indicar cuántos productos quedan en el almacén.
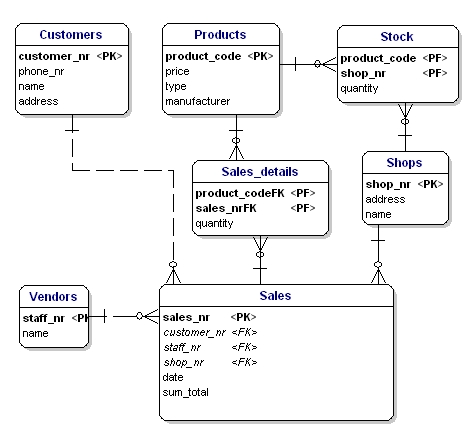
Figura 11: Claves primarias y claves foráneas.
Definición del tipo de datos del atributo
Ahora es el momento de averiguar qué tipos de datos hay que utilizar para los atributos. Hay muchos tipos de datos diferentes. Algunos están estandarizados, pero muchas bases de datos tienen sus propios tipos de datos que tienen sus propias ventajas. Algunas bases de datos ofrecen la posibilidad de definir sus propios tipos de datos, en caso de que los tipos estándar no puedan hacer lo que usted necesita.
Los tipos de datos estándar que toda base de datos conoce, y son los más utilizados, son: CHAR, VARCHAR, TEXT, FLOAT, DOUBLE e INT.
Texto:
- CHAR(longitud) – incluye texto (caracteres, números, puntuaciones…). CHAR tiene como característica que siempre guarda una cantidad fija de posiciones. Si define un CHAR(10) puede guardar hasta diez posiciones como máximo, pero si sólo utiliza dos posiciones la base de datos seguirá guardando 10 posiciones. Las ocho posiciones restantes se llenarán con espacios.
- VARCHAR(length) – incluye texto (caracteres, números, puntuación…). VARCHAR es lo mismo que CHAR, la diferencia es que VARCHAR sólo ocupa el espacio necesario.
- TEXT – puede contener grandes cantidades de texto. Dependiendo del tipo de base de datos esto puede sumar gigabytes.
Números:
- INT – contiene un número entero positivo o negativo. Muchas bases de datos tienen variaciones del INT, como TINYINT, SMALLINT, MEDIUMINT, BIGINT, INT2, INT4, INT8. Estas variaciones difieren del INT sólo en el tamaño de la cifra que cabe en él. Un INT normal es de 4 bytes (INT4) y cabe en cifras de -2147483647 a +2147483646, o si se define como UNSIGNED de 0 a 4294967296. El INT8, o BIGINT, puede tener un tamaño aún mayor, de 0 a 18446744073709551616, pero ocupa hasta 8 bytes de espacio en disco, aunque sólo haya un número pequeño en él.
- FLOAT, DOUBLE – La misma idea que INT, pero también puede almacenar números de punto flotante. . Tenga en cuenta que esto no siempre funciona perfectamente. Por ejemplo en MySQL el cálculo con estos números de punto flotante no es perfecto, (1/3)*3 resultará con los flotadores de MySQL en 0.9999999, no 1.
Otros tipos:
- BLOB – para datos binarios como archivos.
- INET – para direcciones IP. También se puede utilizar para máscaras de red.
Para nuestro ejemplo los tipos de datos son los siguientes:
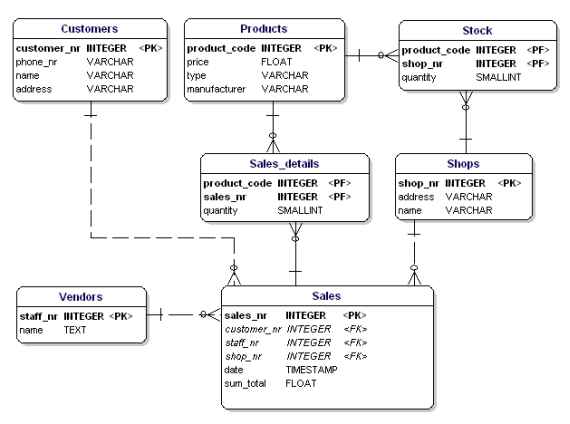
Figura 12: Modelo de datos que muestra los tipos de datos.
Normalización
La normalización hace que su modelo de datos sea flexible y fiable. Genera cierta sobrecarga porque normalmente se obtienen más tablas, pero le permite hacer muchas cosas con su modelo de datos sin tener que ajustarlo. Puedes leer más sobre la normalización de bases de datos en este artículo.
Normalización, la primera forma
La primera forma de normalización establece que no puede haber grupos de columnas que se repitan en una entidad. Podríamos haber creado una entidad ‘ventas’ con atributos para cada uno de los productos que se han comprado. Esto se vería así:

Figura 13: No en la primera forma normal.
Lo malo de esto es que ahora sólo se pueden vender 3 productos. Si tuviera que vender 4 productos, tendría que iniciar una segunda venta o ajustar su modelo de datos añadiendo atributos ‘product4’. Ambas soluciones no son deseables. En estos casos siempre debes crear una nueva entidad que vincules con la anterior a través de una relación uno a varios.
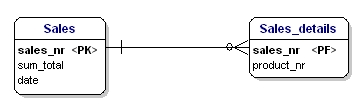
Figura 14: De acuerdo con la 1ª forma normal.
Normalización, la segunda forma
La segunda forma de normalización establece que todos los atributos de una entidad deben ser totalmente dependientes de la clave primaria completa. Esto significa que cada atributo de una entidad sólo puede ser identificado a través de la clave primaria completa. Supongamos que tenemos la fecha en la entidad Sales_details:

Figura 15: No está en la segunda forma normal.
Esta entidad no está según la segunda forma de normalización, porque para poder buscar la fecha de una venta, no tengo que saber qué se vende (productnr), lo único que necesito saber es el número de venta. Esto se solucionó dividiendo las tablas en la de ventas y la de Sales_details:
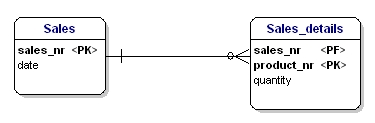
Figura 16: De acuerdo con la 2ª forma normal.
Ahora cada atributo de las entidades depende de todo el PK de la entidad. La fecha depende del número de ventas, y la cantidad depende del número de ventas y del producto vendido.
Normalización, la tercera forma
La tercera forma de normalización establece que todos los atributos tienen que depender directamente de la clave primaria, y no de otros atributos. Esto parece ser lo que establece la segunda forma de normalización, pero en la segunda forma en realidad se establece lo contrario. En la segunda forma de normalización señalas los atributos a través de la PK, en la tercera forma de normalización todo atributo tiene que depender de la PK, y nada más.

Figura 17: No en la tercera forma normal.
En este caso el precio de un producto suelto depende del número de pedido, y el número de pedido depende del número de producto y del número de venta. Esto no está de acuerdo con la tercera forma de normalización. De nuevo, la división de las tablas lo resuelve.
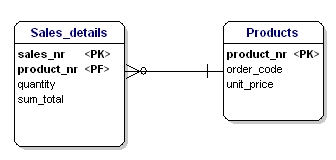
Figura 18: De acuerdo con la tercera forma normal.
Normalización, más formas
Hay más formas de normalización que las tres mencionadas anteriormente, pero esas no son de gran interés para el usuario medio. Estas otras formas son altamente especializadas para ciertas aplicaciones. Si te ciñes a las reglas de diseño y a la normalización mencionada en este artículo, crearás un diseño que funciona muy bien para la mayoría de las aplicaciones.
Modelo de datos normalizado
Si aplicas las reglas de normalización, verás que el ‘fabricante’ de la tabla de productos también debería ser una tabla independiente:
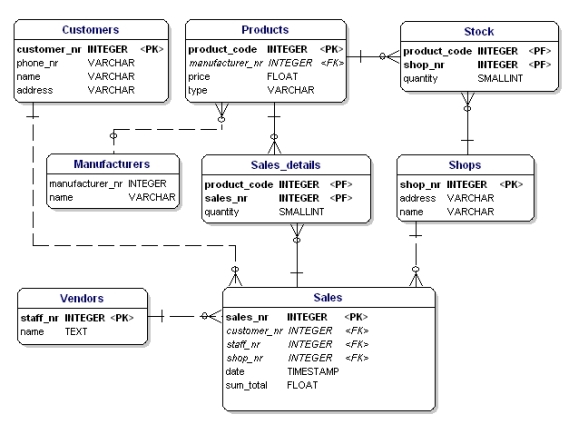
Figura 19: Modelo de datos según la 1ª, 2ª y 3ª forma normal.