




Paquetes rotos: La fragmentación IP es defectuosa
A diferencia de la red telefónica pública, Internet tiene un diseño de conmutación de paquetes. Pero, ¿qué tamaño pueden tener estos paquetes?
 Imagen CC BY 2.0 por ajmexico, inspirada en
Imagen CC BY 2.0 por ajmexico, inspirada en
Esta es una vieja pregunta y los RFCs de IPv4 la responden con bastante claridad. La idea era dividir el problema en dos preocupaciones separadas:
-
¿Cuál es el tamaño máximo de los paquetes que pueden manejar los sistemas operativos en ambos extremos?
-
¿Cuál es el tamaño máximo de datagrama permitido que puede ser empujado con seguridad a través de las conexiones físicas entre los hosts?
Cuando un paquete es demasiado grande para un enlace físico, un router intermedio podría cortarlo en múltiples datagramas más pequeños con el fin de hacerlo caber. Este proceso se denomina fragmentación IP «hacia adelante» y los datagramas más pequeños se llaman fragmentos IP.
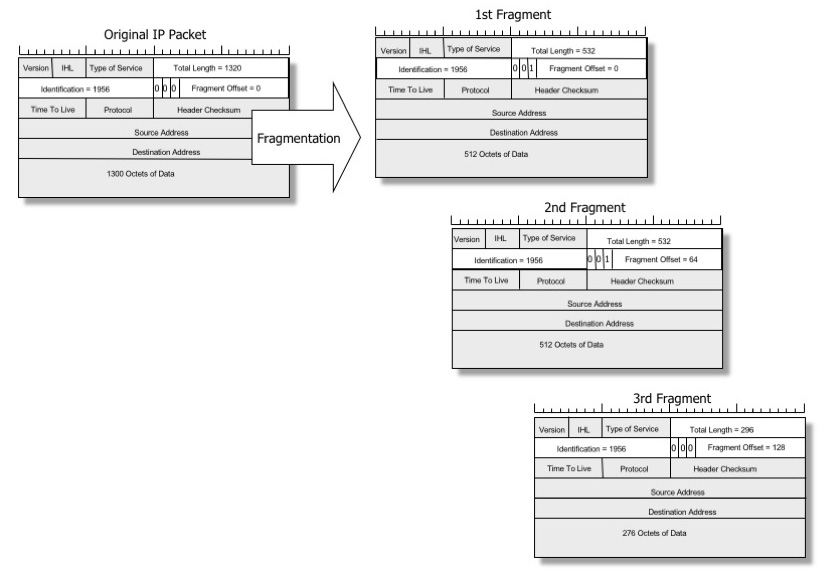 Imagen de Geoff Huston, reproducida con permiso
Imagen de Geoff Huston, reproducida con permiso
La especificación IPv4 define los requisitos mínimos. Del RFC791:
Every internet destination must be able to receive a datagramof 576 octets either in one piece or in fragments tobe reassembled. Every internet module must be able to forward a datagram of 68octets without further fragmentation. El primer valor -el tamaño permitido del paquete reensamblado- no suele ser problemático. IPv4 define el mínimo como 576 bytes, pero los sistemas operativos más populares pueden soportar paquetes muy grandes, normalmente de hasta 65KiB.
El segundo es más problemático. Todas las conexiones físicas tienen límites inherentes al tamaño de los datagramas, dependiendo del medio específico que utilicen. Por ejemplo, Frame Relay puede enviar datagramas de entre 46 y 4.470 bytes. ATM utiliza 53 bytes fijos, Ethernet clásica puede hacer entre 64 y 1500 bytes.
La especificación define el requisito mínimo – cada enlace físico debe ser capaz de transmitir datagramas de al menos 68 bytes. Para IPv6 ese valor mínimo se ha elevado a 1.280 bytes (ver RFC2460).
Por otro lado, el tamaño máximo de datagrama que se puede transmitir sin fragmentación no está definido por ninguna especificación y varía según el tipo de enlace. Este valor se denomina MTU (Maximum Transmission Unit).
La MTU define un tamaño máximo de datagrama en un enlace físico local. Internet se crea a partir de redes no homogéneas, y en el camino entre dos hosts puede haber enlaces con valores de MTU más cortos. El tamaño máximo de paquete que puede ser transmitido sin fragmentación entre dos hosts remotos se llama MTU de la ruta, y puede ser potencialmente diferente para cada conexión.
Evitar la fragmentación
Uno podría pensar que está bien construir aplicaciones que transmitan paquetes muy grandes y confiar en los routers para realizar la fragmentación IP. Esto no es una buena idea. Los problemas con este enfoque fueron discutidos por primera vez por Kent y Mogul en 1987. Aquí hay un par de puntos destacados:
-
Para reensamblar con éxito un paquete, todos los fragmentos deben ser entregados. Ningún fragmento puede corromperse o perderse durante el vuelo. Simplemente no hay manera de notificar a la otra parte sobre los fragmentos perdidos.
-
El último fragmento casi nunca tendrá el tamaño óptimo. En el caso de las transferencias grandes, esto significa que una parte significativa del tráfico estará compuesta por datagramas cortos subóptimos, lo que supone un desperdicio de los valiosos recursos del router.
-
Antes del reensamblaje, un host debe mantener los datagramas parciales y fragmentados en la memoria. Esto abre una oportunidad para los ataques de agotamiento de memoria.
-
Los fragmentos posteriores carecen de la cabecera de capa superior. La cabecera TCP o UDP sólo está presente en el primer fragmento. Esto hace imposible que los cortafuegos filtren los datagramas de fragmentos basándose en criterios como los puertos de origen o destino.
Una descripción más elaborada de los problemas de fragmentación de IP puede encontrarse en estos artículos de Geoff Huston:
- Evaluación de la fragmentación de paquetes IPv4 e IPv6
- Fragmentación de IPv6
No fragmentar – Paquete ICMP demasiado grande
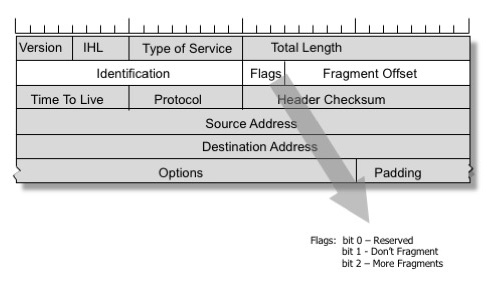
Imagen de Geoff Huston, reproducida con permiso
Una solución a estos problemas fue incluida en el protocolo IPv4. Un remitente puede establecer la bandera DF (Don’t Fragment) en la cabecera IP, pidiendo a los routers intermedios que nunca realicen la fragmentación de un paquete. En su lugar, un router con un enlace que tenga una MTU más pequeña enviará un mensaje ICMP «hacia atrás» e informará al remitente para que reduzca la MTU para esta conexión.
El protocolo TCP siempre establece la bandera DF. La pila de la red busca cuidadosamente los mensajes ICMP «Packet too big» entrantes y mantiene un registro de la característica «path MTU» para cada conexión. Esta técnica se denomina «path MTU discovery», y se utiliza sobre todo para TCP, aunque también puede aplicarse a otros protocolos basados en IP. Ser capaz de entregar los mensajes ICMP «Packet too big» (paquete demasiado grande) es crítico para mantener el funcionamiento óptimo de la pila TCP.
Cómo funciona realmente Internet
En un mundo perfecto, los dispositivos conectados a Internet cooperarían y manejarían correctamente los fragmentos de datagramas y los paquetes ICMP asociados. Sin embargo, en la realidad, los fragmentos IP y los paquetes ICMP se filtran con mucha frecuencia.
Esto se debe a que la Internet moderna es mucho más compleja de lo previsto hace 36 años. Hoy en día, básicamente nadie se conecta directamente a la Internet pública.
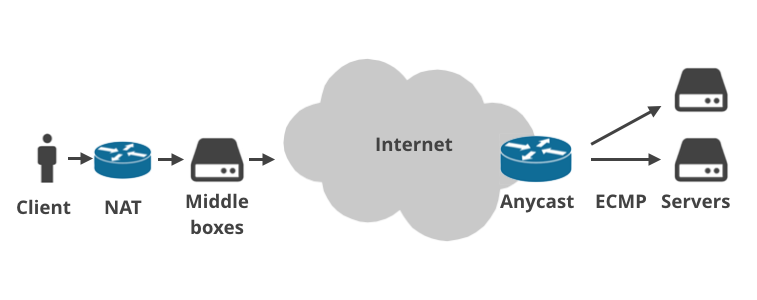
Los dispositivos de los clientes se conectan a través de routers domésticos que hacen NAT (traducción de direcciones de red) y suelen aplicar reglas de cortafuegos. Cada vez es más frecuente que haya más de una instalación NAT en la ruta de los paquetes (por ejemplo, NAT de grado de operador). Luego, los paquetes llegan a la infraestructura del ISP, donde hay «cajas intermedias» del ISP. Éstas realizan todo tipo de cosas extrañas en el tráfico: imponen límites de planes, aceleran las conexiones, realizan registros, secuestran las solicitudes de DNS, implementan prohibiciones de sitios web impuestas por el gobierno, fuerzan el almacenamiento en caché transparente o, posiblemente, «optimizan» el tráfico de alguna otra manera mágica. Las cajas intermedias son utilizadas especialmente por las telecos móviles.
De forma similar, a menudo hay múltiples capas entre un servidor y la Internet pública. Los proveedores de servicios a veces utilizan el enrutamiento Anycast BGP. Es decir: manejan los mismos rangos de IP desde múltiples ubicaciones físicas en todo el mundo. Por otro lado, dentro de un centro de datos es cada vez más popular el uso de ECMP Equal Cost Multi Path para el balanceo de carga.
Cada una de estas capas entre un cliente y un servidor puede causar un problema de Path MTU. Permítanme ilustrar esto con cuatro escenarios.
1. Cliente -> Servidor DF+ / ICMP
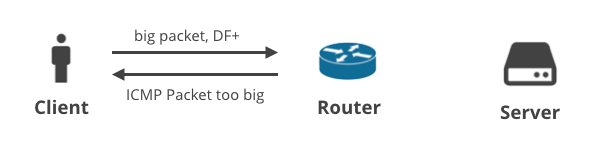
En el primer escenario, un cliente carga algunos datos al servidor usando TCP de modo que la bandera DF se establece en todos los paquetes. Si el cliente no puede predecir una MTU adecuada, un router intermedio descartará los paquetes grandes y enviará una notificación ICMP «Packet too big» al cliente. Estos paquetes ICMP podrían ser descartados por los dispositivos NAT del cliente mal configurados o las cajas intermedias del ISP.
Según el artículo de Maikel de Boer y Jeffrey Bosma de 2012, alrededor del 5% de los hosts IPv4 y el 1% de los IPv6 bloquean los paquetes ICMP entrantes.
Mi experiencia lo confirma. Efectivamente, los mensajes ICMP se descartan a menudo por supuestas ventajas de seguridad, pero esto es relativamente fácil de solucionar. Un problema mayor es con ciertos ISPs móviles con cajas intermedias extrañas. Estos a menudo ignoran completamente el ICMP y realizan una reescritura de la conexión muy agresiva. Por ejemplo, Orange Polska no sólo ignora los mensajes ICMP entrantes de «Paquete demasiado grande», sino que también reescribe el estado de la conexión y sujeta el MSS a un valor no negociable de 1344 bytes.
2. Cliente -> Servidor DF- / fragmentación
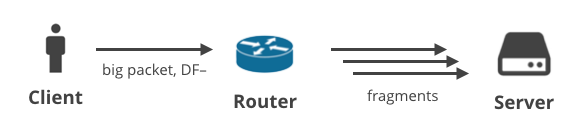
En el siguiente escenario, un cliente carga algunos datos con un protocolo distinto de TCP, que tiene la bandera DF desactivada. Por ejemplo, esto podría ser un usuario jugando un juego usando UDP, o teniendo una llamada de voz. Los grandes paquetes de salida podrían fragmentarse en algún punto de la ruta.
Podemos emular esto lanzando ping con un gran tamaño de carga útil:
$ ping -s 2048 facebook.comEste ping en particular fallará con cargas útiles mayores a 1472 bytes. Cualquier tamaño mayor se fragmentará y no se entregará correctamente. Hay múltiples razones por las que los servidores pueden manejar mal los fragmentos, pero uno de los problemas más populares es el uso del balanceo de carga ECMP. Debido al hashing de ECMP, el primer datagrama que contiene una cabecera de protocolo es probable que se equilibre la carga a un servidor diferente que el resto de los fragmentos, impidiendo el reensamblaje.
Para una discusión más detallada de este problema, ver:
- Nuestro anterior escrito sobre ECMP.
- Cómo Google intenta resolver los problemas de fragmentación de ECMP con el equilibrador de carga Maglev L4.
Además, la mala configuración del servidor y del router es un problema importante. Según el RFC7852, entre el 30% y el 55% de los servidores abandonan los datagramas IPv6 que contienen cabeceras de fragmentación.
3. Servidor -> Cliente DF+ / ICMP
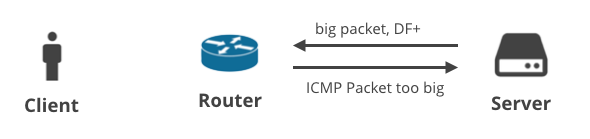
El siguiente escenario trata de un cliente que descarga algunos datos a través de TCP. Cuando el servidor no logra predecir la MTU correcta, debería recibir un mensaje ICMP «Paquete demasiado grande». Fácil, ¿verdad?
Lamentablemente, no lo es, de nuevo debido al enrutamiento ECMP. Lo más probable es que el mensaje ICMP se entregue al servidor equivocado – el hash de 5 tuplas del paquete ICMP no coincidirá con el hash de 5 tuplas de la conexión problemática. Escribimos sobre esto en el pasado, y desarrollamos un simple demonio de espacio de usuario para resolverlo. Funciona difundiendo la notificación ICMP entrante «Packet too big» a todos los servidores ECMP, esperando que el que tiene la conexión problemática la vea.
Además, debido al enrutamiento Anycast, el ICMP podría ser entregado al centro de datos equivocado. El enrutamiento de Internet es a menudo asimétrico y la mejor ruta de un router intermedio podría dirigir los paquetes ICMP al lugar equivocado.
Las notificaciones ICMP «Packet too big» (paquete demasiado grande) pueden dar lugar a que las conexiones se bloqueen y se agoten. Esto a menudo se llama un agujero negro PMTU. Para ayudar a este caso pesimista Linux implementa una solución – MTU Probing RFC4821. El sondeo de MTU intenta identificar automáticamente los paquetes perdidos debido a una MTU incorrecta, y utiliza la heurística para ajustarla. Esta función se controla a través de un sysctl:
$ echo 1 > /proc/sys/net/ipv4/tcp_mtu_probingPero el sondeo de MTU no está exento de problemas. En primer lugar, tiende a categorizar erróneamente la pérdida de paquetes relacionada con la congestión como problemas de MTU. Las conexiones de larga duración tienden a terminar con una MTU reducida. En segundo lugar, Linux no implementa MTU Probing para IPv6.
4. Servidor -> Cliente DF- / fragmentación
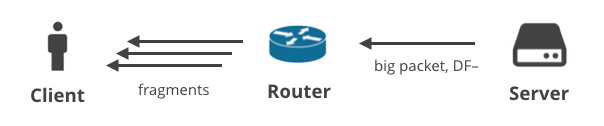
Por último, hay una situación en la que el servidor envía paquetes grandes utilizando un protocolo no TCP con el bit DF claro. En este escenario, los paquetes grandes se fragmentarán en el camino hacia el cliente. Esta situación se ilustra mejor con grandes respuestas DNS. Aquí hay dos peticiones DNS que generarán respuestas grandes y serán entregadas al cliente como múltiples fragmentos IP:
$ dig +notcp +dnssec DNSKEY org @199.19.56.1$ dig +notcp +dnssec DNSKEY org @2001:500:f::1Estas peticiones pueden fallar debido a lo ya mencionado del router doméstico mal configurado, NAT roto, instalaciones ISP rotas, o configuraciones de cortafuegos demasiado restrictivas.
Según Boer y Bosma alrededor del 6% de los hosts IPv4 y el 10% de los IPv6 bloquean los datagramas de fragmentos entrantes.
Aquí hay algunos enlaces con más información sobre los problemas específicos de fragmentación que afectan al DNS:
- DNS-OARC Reply Size Test
- IPv6, Large UDP Packets and the DNS
¡Pero Internet sigue funcionando!
Con todas estas cosas que van mal, ¿cómo se las arregla Internet para funcionar?
 CC BY-SA 3.0, fuente: Wikipedia
CC BY-SA 3.0, fuente: Wikipedia
Esto se debe principalmente al éxito de Ethernet. La gran mayoría de los enlaces en la Internet pública son Ethernet (o derivados de ella) y soportan la MTU de 1500 bytes.
Si asumes ciegamente la MTU de 1500, te sorprenderá la frecuencia con la que funciona sin problemas. Internet sigue funcionando sobre todo porque todos usamos una MTU de 1500 y rara vez necesitamos hacer fragmentación IP y enviar mensajes ICMP.
Esto deja de funcionar en una configuración inusual con enlaces que tienen una MTU no estándar. Las VPNs y otro software de túneles de red deben tener cuidado de que los fragmentos y los mensajes ICMP funcionen bien.
Esto es especialmente visible en el mundo IPv6, donde muchos usuarios se conectan a través de túneles. Tener un paso saludable de ICMP en ambos sentidos es muy importante, especialmente porque la fragmentación en IPv6 básicamente no funciona (citamos dos fuentes que afirman que entre el 10% y el 50% de los hosts IPv6 bloquean la cabecera de fragmentos de IPv6).
Dado que los problemas de Path MTU en IPv6 son tan comunes, muchos servidores IPv6 reducen el Path MTU al mínimo ordenado por el protocolo de 1280 bytes. Este enfoque intercambia un poco de rendimiento por una mayor fiabilidad.
Comprobador de agujeros negros ICMP en línea
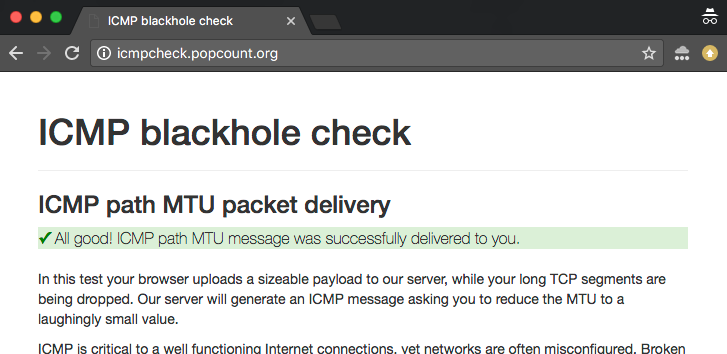
Para ayudar a explorar y depurar estos problemas, hemos creado un comprobador en línea. Puede encontrar dos versiones de la prueba:
- Versión IPv4: http://icmpcheck.popcount.org
- Versión IPv6: http://icmpcheckv6.popcount.org
Estos sitios lanzan dos pruebas:
- La primera prueba enviará mensajes ICMP a su ordenador, con la intención de reducir la MTU de la ruta a un valor ridículamente pequeño.
- La segunda prueba le enviará datagramas fragmentados.
Recibir un «pase» en estas dos pruebas debería darle una seguridad razonable de que Internet en su lado del cable se está comportando bien.
También es fácil ejecutar las pruebas desde la línea de comandos, en caso de que quiera ejecutarlo en el servidor:
perl -e "print 'packettoolongyaithuji6reeNab4XahChaeRah1diej4' x 180" > payload.bincurl -v -s http://icmpcheck.popcount.org/icmp --data @payload.bincurl -v -s http://icmpcheckv6.popcount.org/icmp --data @payload.binEsto debería reducir la MTU de la ruta a nuestro servidor a 905 bytes. Puedes verificar esto mirando la tabla de caché de enrutamiento. En Linux se hace con:
ip route get `dig +short icmpcheck.popcount.org`Es posible borrar la caché de enrutamiento en Linux:
ip route flush cache to `dig +short icmpcheck.popcount.org`La segunda prueba verifica si los fragmentos se entregan correctamente al cliente:
curl -v -s http://icmpcheck.popcount.org/frag -o /dev/nullcurl -v -s http://icmpcheckv6.popcount.org/frag -o /dev/nullResumen
En esta entrada del blog describimos los problemas para detectar los valores de MTU de la ruta en Internet. Los datagramas ICMP y fragmentados suelen bloquearse en ambos lados de las conexiones. Los clientes pueden encontrar cortafuegos mal configurados, dispositivos NAT o utilizar ISPs que interceptan agresivamente las conexiones. Los clientes también suelen utilizar VPN o túneles IPv6 que, mal configurados, pueden causar problemas de MTU en la ruta.
Los servidores, por otro lado, dependen cada vez más de Anycast o ECMP. Ambas cosas, así como la mala configuración del router y del cortafuegos, son a menudo la causa de la caída de datagramas ICMP y fragmentados.
Por último, esperamos que la prueba en línea sea útil y pueda darle más información sobre el funcionamiento interno de sus redes. La prueba tiene ejemplos útiles de la sintaxis de tcpdump, útil para obtener más información. Feliz depuración de la red!
¿Es emocionante arreglar los problemas de fragmentación del 10% de Internet? ¡Estamos contratando a ingenieros de sistemas de todo tipo, programadores de Golang, C wranglers, y pasantes en múltiples ubicaciones! Únase a nosotros en San Francisco, Londres, Austin, Champaign y Varsovia.
-
En IPv6 la fragmentación de «reenvío» funciona de forma ligeramente diferente que en IPv4. Los routers intermedios tienen prohibido fragmentar los paquetes, pero el origen sí puede hacerlo. Esto es a menudo confuso – a un host se le puede pedir que fragmente un paquete que transmitió en el pasado. Esto tiene poco sentido para los protocolos sin estado como el DNS. ︎
-
¡También existe una «unidad mínima de transmisión»! En el marco de Ethernet comúnmente utilizado, cada datagrama transmitido debe tener al menos 64 bytes en la capa 2. Esto se traduce en 22 bytes en UDP y 10 bytes en la capa TCP. ¡Múltiples implementaciones solían filtrar memoria no inicializada en paquetes más cortos! ︎
-
En términos estrictos, en IPv4 el paquete ICMP se denomina «Destination Unreachable, Fragmentation Needed and Don’t Fragment was Set». Pero la descripción del error ICMP de IPv6 «Paquete demasiado grande» me parece mucho más clara. ︎
-
Como pista, la pila TCP también incluye un valor «MSS» máximo permitido en los paquetes SYN (MSS es básicamente un valor MTU reducido por el tamaño de las cabeceras IP y TCP). Esto permite a los hosts saber cuál es la MTU en sus enlaces. Nota: ¡esto no dice cuál es la MTU en las docenas de enlaces de Internet entre los dos hosts! ︎
-
Error en el lado seguro. Una mejor MTU es 1492, para acomodar las conexiones DSL y PPPoE. ︎