




Enterprise Data Warehouse: Concepts, Architecture, and Components
Lukuaika: 12 minuuttia
Kautta päivän teemme monia päätöksiä aikaisempaan kokemukseen tukeutuen. Aivomme tallentavat triljoonia bittejä tietoa aiemmista tapahtumista ja hyödyntävät näitä muistoja aina, kun joudumme tekemään päätöksen. Kuten ihmiset, myös yritykset tuottavat ja keräävät valtavasti tietoa menneisyydestä. Ja tätä dataa voidaan käyttää parempien päätösten tekemiseen.
Vaikka aivomme palvelevat sekä käsittelyä että tallentamista, yritykset tarvitsevat useita työkaluja datan käsittelyyn. Ja yksi tärkeimmistä on tietovarasto.
Tässä artikkelissa keskustelemme siitä, mikä yrityksen tietovarasto on, sen tyypeistä ja toiminnoista sekä siitä, miten sitä käytetään tietojenkäsittelyssä. Määrittelemme, miten yritysten tietovarastot eroavat tavallisista tietovarastoista, millaisia tietovarastoja on olemassa ja miten ne toimivat. Painopisteenä on antaa tietoa kunkin arkkitehtuurisen ja konseptuaalisen lähestymistavan liiketoiminnallisesta arvosta tietovaraston rakentamisessa.
Mikä on yritystietovarasto?
Jos tiedät, paljonko teratavu on, olisit luultavasti vaikuttunut siitä, että Netflixin tietovarastossa oli noin 44 teratavua dataa vuonna 2016. Jo pelkkä koko viittaa siihen, miksi kutsumme sitä tietovarastoksi pelkän tietokannan sijaan. Aloitetaan siis perusasioista.
Yritystietovarasto (Enterprise Data Warehouse, EDW) on eräänlainen yritysrekisteri, joka tallentaa ja hallinnoi kaikkea yrityksen historiallista liiketoimintatietoa. Tiedot tulevat yleensä eri järjestelmistä, kuten toiminnanohjausjärjestelmistä, CRM-järjestelmistä, fyysisistä tallenteista ja muista litteistä tiedostoista. Jotta tiedot voidaan valmistella myöhempää analysointia varten, ne on sijoitettava yhteen säilytyspaikkaan. Näin eri liiketoimintayksiköt voivat kysyä sitä ja analysoida tietoja useista eri näkökulmista.
Tietovaraston avulla yritys voi hallita valtavia tietokokonaisuuksia hallinnoimatta useita tietokantoja. Tällainen käytäntö on tulevaisuudenkestävä tapa tallentaa tietoja business intelligencea (BI) varten, joka on joukko menetelmiä/teknologioita raakadatan muuntamiseksi käyttökelpoisiksi oivalluksiksi. Koska EDW on tärkeä osa sitä, järjestelmä muistuttaa ihmisen aivoja, jotka tallentavat tietoa, mutta steroideilla.
Yritystietovarasto vs. tavallinen tietovarasto: mitä eroa on?
Jokainen tietovarasto on tietokanta, joka on aina yhteydessä raakadatalähteisiin dataintegraatiotyökalujen kautta toisessa päässä ja analyyttisten rajapintojen kautta toisessa päässä. Jos näin on, miksi eristämme keskustelua varten yritysmuodon?
Jokainen tietovarasto tarjoaa tallennustilan, jossa on mekanismeja tiedon muuntamiseen, siirtämiseen ja esittämiseen loppukäyttäjälle. Ero tavallisen tietovaraston ja yritysmuotoisen tietovaraston välillä on sen paljon laajempi arkkitehtuurinen monimuotoisuus ja toiminnallisuus. Monimutkaisen rakenteen ja koon vuoksi EDW:t on usein purettu pienempiin tietokantoihin, joten loppukäyttäjien on helpompi tehdä kyselyjä näistä pienemmistä tietokannoista. Tämä huomioon ottaen keskitymme yritysvarastoon kattaaksemme koko toiminnallisuuden kirjon.
Varaston koko ei kuitenkaan määrittele sen teknistä monimutkaisuutta, analyysi- ja raportointivalmiuksia koskevia vaatimuksia, tietomallien lukumäärää eikä itse tietoa. Jotta ymmärtäisimme, mikä tekee tietovarastosta tietovaraston, sukelletaan sen keskeisiin käsitteisiin ja toiminnallisuuksiin.
Yritystietovaraston käsitteet ja toiminnot
Kaikkien kellojen ja pillien lisäksi jokaisen tietovaraston ytimessä ovat peruskäsitteet ja -toiminnot. Nämä pilarit määrittelevät tietovaraston teknologisena ilmiönä:
Toimii perimmäisenä varastona. Yrityksen tietovarasto on yhtenäinen säilytyspaikka kaikelle organisaatiossa koskaan esiintyvälle yrityksen liiketoimintatiedolle.
Reflected the source data. EDW lähtee dataa alkuperäisistä tallennustiloista, kuten Google Analyticsista, CRM:stä, IoT-laitteista jne. Jos tiedot ovat hajallaan useissa eri järjestelmissä, se on hallitsematonta. Niinpä EDW:n tarkoituksena on tarjota alkuperäisen lähdetiedon kaltaiset tiedot yhdessä säilytyspaikassa. Koska sekä yrityksen sisällä että sen ulkopuolella syntyy aina uutta, merkityksellistä tietoa, tietovirta edellyttää erityistä infrastruktuuria sen hallitsemiseksi, ennen kuin se pääsee varastoon.
Tallentaa strukturoitua tietoa. EDW:hen tallennetut tiedot ovat aina standardoituja ja strukturoituja. Tämä mahdollistaa sen, että loppukäyttäjät voivat tehdä kyselyjä BI-rajapintojen ja lomakeraporttien avulla. Ja tämä erottaa tietovaraston datajärvestä. Data lakeja käytetään strukturoimattoman datan tallentamiseen analyyttisiin tarkoituksiin. Mutta toisin kuin tietovarastoja, data-järviä käyttävät enemmänkin data-insinöörit/tiedemiehet, jotka työskentelevät suurten raakadatamäärien kanssa.
Aineistolähtöinen data. Tietovaraston pääpaino on liiketoimintadatassa, joka voi liittyä eri osa-alueisiin. Jotta voidaan ymmärtää, mihin data liittyy, se on aina jäsennetty tietyn aiheen ympärille, jota kutsutaan tietomalliksi. Esimerkki aiheesta voi olla myyntialue tai tietyn nimikkeen kokonaismyynti. Lisäksi lisätään metatietoa, joka selittää yksityiskohtaisesti, mistä kukin tieto on peräisin.
Aikariippuvainen. Kerättävä tieto on yleensä historiallista tietoa, koska se kuvaa menneitä tapahtumia. Jotta voidaan ymmärtää, milloin ja kuinka kauan tietty suuntaus tapahtui, useimmat tallennetut tiedot on yleensä jaettu aikajaksoihin.
Haihtumaton. Kun tiedot on sijoitettu varastoon, niitä ei koskaan poisteta sieltä. Tietoja voidaan manipuloida, muuttaa tai päivittää lähdemuutosten vuoksi, mutta niitä ei ole koskaan tarkoitus poistaa, ainakaan loppukäyttäjien toimesta. Kun puhutaan historiallisesta datasta, poistot ovat analyyttisten tarkoitusten kannalta haitallisia. Silti yleisiä tarkistuksia voi tapahtua muutaman vuoden välein, jotta epäolennaisista tiedoista päästään eroon.
Perusperiaatteita ajatellen tarkastelemme DW:iden toteutustyyppejä.
Tietovarastotyypit
EDW:n toimintoja ajatellen on aina keskustelun varaa siitä, miten se suunnitellaan teknisesti. Mitä tulee tietojen varastointiin ja käsittelyyn, ne ovat spesifisiä ja erillisiä erityyppisille yrityksille. Tietojen määrästä, analyyttisestä monimutkaisuudesta, turvallisuuskysymyksistä ja budjetista riippuen on tietysti aina olemassa vaihtoehto, miten järjestelmä kannattaa perustaa.
Klassinen tietovarasto
Klassisena EDW-vaihtoehtona pidetään yhtenäistä tallennusta, jossa on oma laitteisto ja ohjelmisto. Kun kyseessä on fyysinen tallennus, sinun ei tarvitse perustaa tietojen integrointityökaluja useiden tietokantojen välille. Sen sijaan EDW voidaan liittää tietolähteisiin API:iden kautta, jolloin tietoja voidaan jatkuvasti hankkia ja muuntaa prosessin aikana. Kaikki työ tehdään siis joko staging-alueella (paikka, jossa tiedot muunnetaan ennen DW:hen lataamista) tai itse tietovarastossa.
Klassista tietovarastoa pidetään virtuaalisen tietovaraston (jota käsittelemme jäljempänä) ylivertaisena, koska siinä ei ole ylimääräistä abstraktiokerrosta. Se yksinkertaistaa datasuunnittelijoiden työtä ja helpottaa tiedonkulun hallintaa esikäsittelyn puolella sekä varsinaista raportointia. Klassisen varaston haitat riippuvat varsinaisesta toteutuksesta, mutta useimmille yrityksille ne ovat:
- Kallis teknologinen infrastruktuuri, sekä laitteisto että ohjelmisto;
- Data-insinöörien ja DevOps-asiantuntijoiden tiimin palkkaaminen koko data-alustan perustamista ja ylläpitoa varten.
Kuinka käyttää: Soveltuu kaikenkokoisille organisaatiolle, jotka haluavat käsitellä dataansa ja hyödyntää sitä. Klassiset tietovarastot mahdollistavat tietoalustan muuntamisen eri arkkitehtuurityyleihin sekä skaalautumisen tarkoituksenmukaisesti ylös- ja alaspäin.
Virtuaalinen tietovarasto
Virtuaalinen tietovarasto on eräänlainen EDW, jota käytetään klassisen tietovaraston vaihtoehtona. Pohjimmiltaan nämä ovat useita tietokantoja, jotka on yhdistetty virtuaalisesti, joten niitä voidaan kysyä yhtenä järjestelmänä.
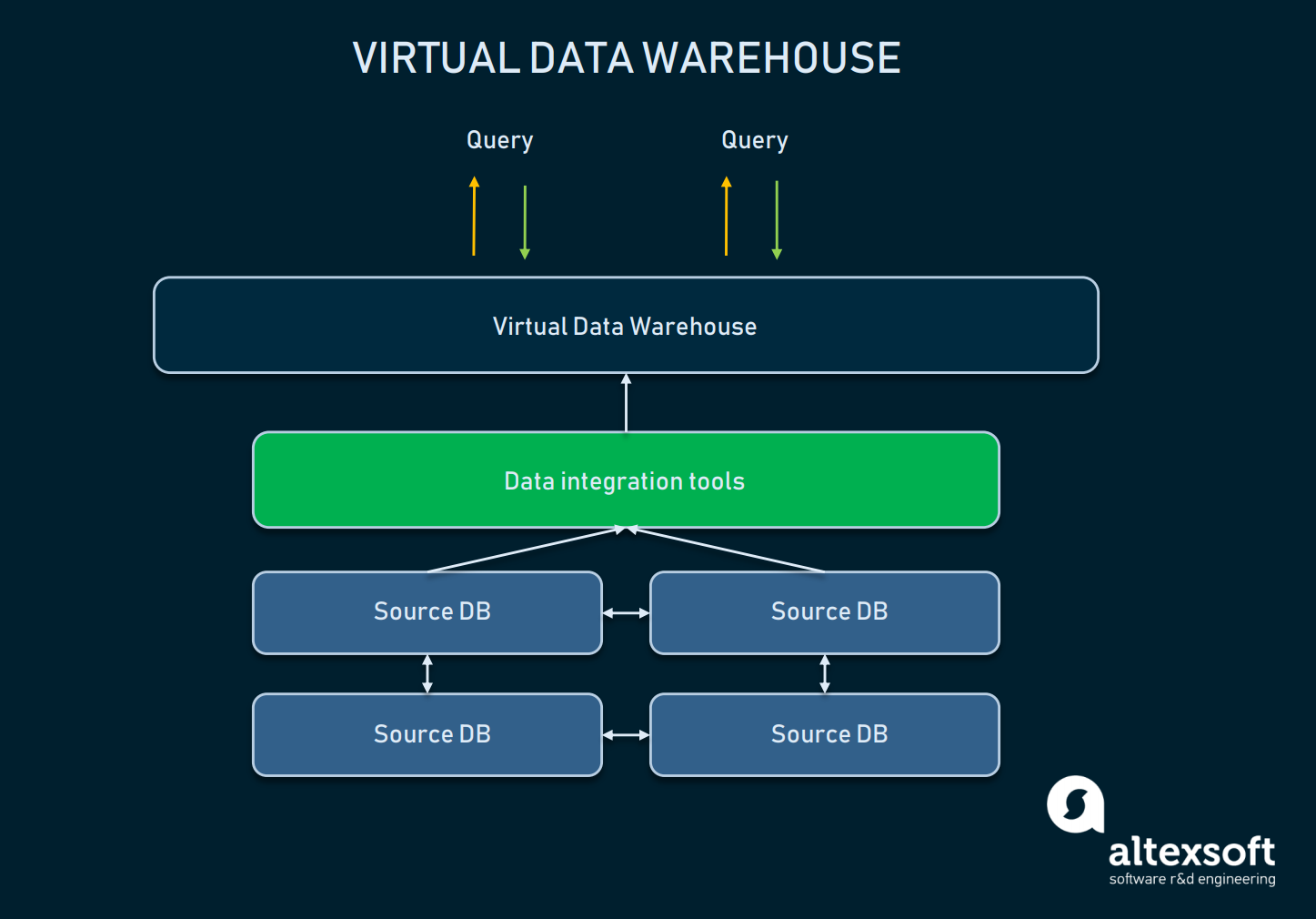
Virtuaalisen DW:n ja lähdetietokantojen abstraktioiden välinen relaatiosysteemi
Tällaisen lähestymistavan avulla organisaatiot pystyvät pitämään asian yksinkertaisena: Tiedot voivat pysyä lähteissään, mutta ne voidaan silti vetää analyysityökalujen avulla. Virtuaalivarastoja voidaan käyttää, jos ei haluta sotkea kaikkea taustalla olevaa infrastruktuuria tai jos olemassa oleva data on helposti hallittavissa sellaisenaan. Tällaisella lähestymistavalla on kuitenkin monia haittapuolia:
- Monet tietokannat vaativat jatkuvaa ohjelmistojen ja laitteistojen ylläpitoa ja kustannuksia.
- Virtuaaliseen DW:hen tallennetut tiedot vaativat edelleen muunnosohjelmiston, jotta ne saadaan loppukäyttäjien ja raportointityökalujen sulateltaviksi.
- Yksimutkaiset tietokyselyt saattavat viedä liikaa aikaa, koska tarvittavat tiedot saatetaan sijoittaa kahteen erilliseen tietokantaan.
Kuinka käyttää: Sopii yrityksille, joilla on raakadataa standardoidussa muodossa, joka ei vaadi monimutkaista analytiikkaa. Sopii myös organisaatioille, jotka eivät käytä BI:tä systemaattisesti tai haluavat aloittaa sen käytön.
Pilvitietovarasto
Pilvi/pilvettömät teknologiat ovat jo vuosikymmenen ajan tulleet enemmän standardiksi organisaatiotason teknologioiden perustamisessa. Markkinoilta löytyy lukemattomia palveluntarjoajia, jotka tarjoavat tietovarastointia palveluna. Muutamia mainitakseni:
- Amazon Redshift/ Hinnoittelusivu
- IBM Db2/ Hinnoittelusivu
- Google BigQuery/ Hinnoittelusivu
- Snowflake/ Hinnoittelusivu
- Microsoft SQL Data Warehouse/ Hinnoittelusivu
Kaikki mainitut palveluntarjoajat tarjoavat täysin hallinnoitua, skaalautuvaa tietovarastointia osana BI-työkalujaan tai keskittyvät EDW:hen erillisenä palveluna, kuten Snowflake tekee. Tällöin pilvivarastoarkkitehtuurilla on samat edut kuin muillakin pilvipalveluilla. Sen infrastruktuuria ylläpidetään puolestasi, eli sinun ei tarvitse perustaa omia palvelimia, tietokantoja ja työkaluja sen hallintaan. Tällaisen palvelun hinta riippuu tarvittavan muistin määrästä ja kyselyihin tarvittavien laskentakapasiteettien määrästä.
Ainoa näkökohta, josta saatat olla huolissasi pilvivarastoalustan suhteen, on tietoturva. Yritystietosi ovat arkaluonteinen asia. Haluat siis tarkistaa, voiko valitsemaasi myyjään luottaa tietoturvaloukkausten välttämiseksi. Tämä ei välttämättä tarkoita, että on-premise-varasto olisi turvallisempi, mutta tässä tapauksessa tietojesi turvallisuus on sinun käsissäsi.
Milloin kannattaa käyttää: Pilvialustat ovat erinomainen valinta kaikenkokoisille organisaatioille. Jos tarvitset kaiken valmiina, mukaan lukien hallitun dataintegraation, DW:n ylläpidon ja BI-tuen.
Yrityksen tietovarastojen arkkitehtuuri
Vaikka on olemassa monia arkkitehtuurisia lähestymistapoja, jotka laajentavat tietovarasto-ominaisuuksia tavalla tai toisella, keskitymme olennaisimpiin niistä. Sukeltamatta liikaa teknisiin yksityiskohtiin, koko dataputki voidaan jakaa kolmeen kerrokseen:
- Raakadatakerros (tietolähteet)
- Varasto ja sen ekosysteemi
- Käyttäjärajapinta (analytiikkatyökalut)
Työkalutoiminnot, jotka koskevat datan louhintaa, muokkausta (Extraction), muuntamista (Transformaatio) ja lataamista (Loading) tietovarastoon, muodostavat erillisen työkalujen kategorian, joka tunnetaan nimellä ETL. ETL:n alle kuuluvat myös dataintegraatiotyökalut, jotka suorittavat datan käsittelyä ennen sen sijoittamista varastoon. Nämä työkalut toimivat raakadatakerroksen ja varaston välissä.
Kun tiedot ladataan varastoon, niitä voidaan myös muuntaa. Varasto vaatii siis tiettyjä toiminnallisuuksia puhdistamiseen/standardisointiin/ulottuvuuksien määrittelyyn. Nämä ja muut tekijät määrittävät arkkitehtuurin monimutkaisuuden. Tarkastelemme EDW-arkkitehtuuria organisaation kasvavien tarpeiden näkökulmasta.
Yksitasoinen arkkitehtuuri
Jos tietojen integrointi on hyvin konfiguroitu, voimme valita tietovarastomme. Useimmissa tapauksissa tietovarasto on relaatiotietokanta, jossa on moduuleja, jotka mahdollistavat moniulotteisen datan, tai sellainen, jossa voidaan erottaa joitakin toimialakohtaisia tietoja helpomman saatavuuden vuoksi. Alkeellisimmillaan tietovarasto voi olla vain yksitasoinen arkkitehtuuri.
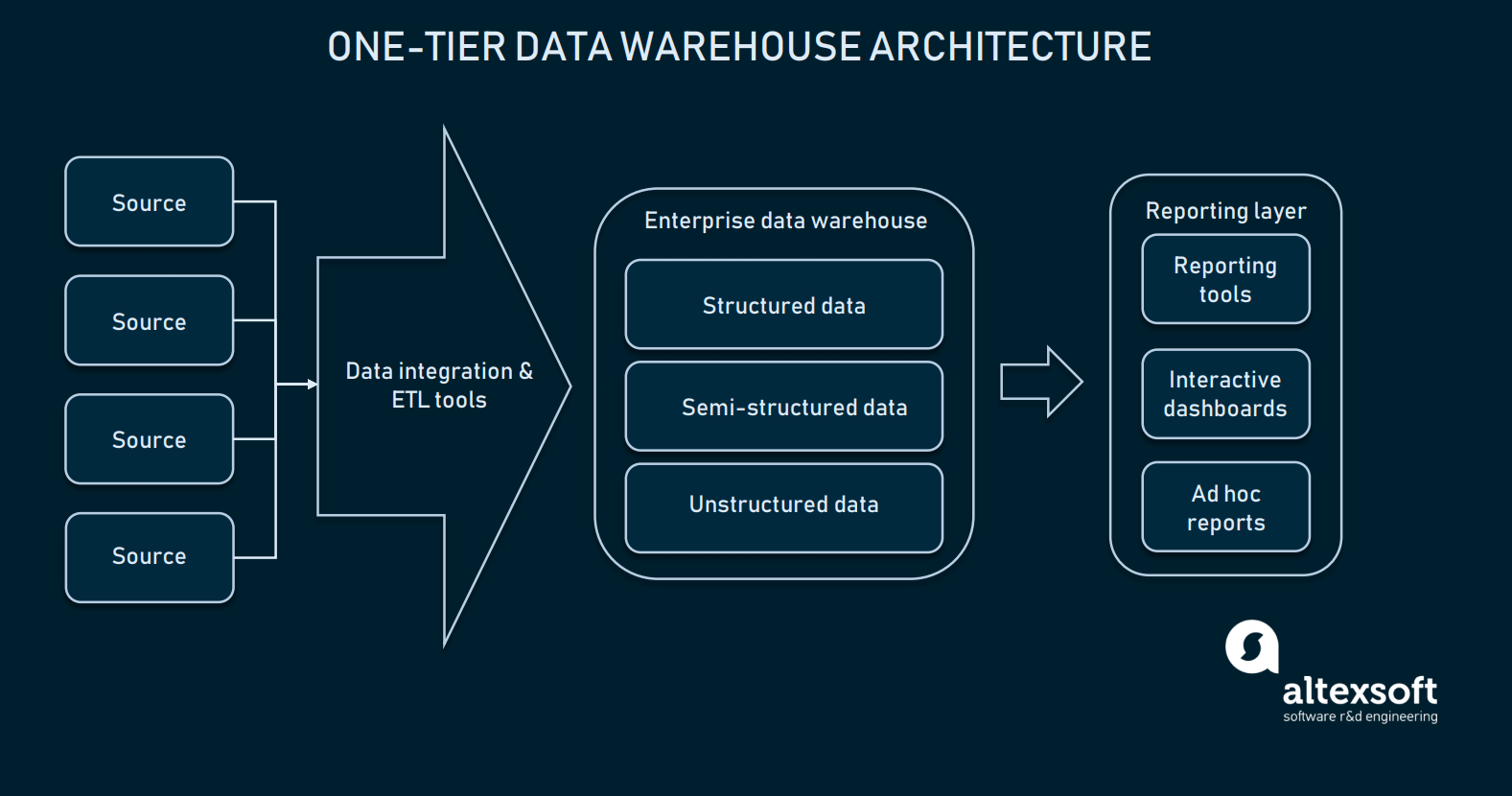
Raportointikerros on kytketty suoraan koko EDW:n tietokantaan
Yksitasoinen arkkitehtuuri EDW:ssä tarkoittaa, että tietokanta on kytketty suoraan analyyttisiin käyttöliittymiin, joissa loppukäyttäjä voi tehdä kyselyitä. Suoran yhteyden asettaminen EDW:n ja analytiikkatyökalujen välille tuo mukanaan useita haasteita:
- Traditionaalisesti tallennustilaa voidaan pitää varastona 100 Gt:n tietomäärästä alkaen. Työskentely suoraan sen kanssa voi johtaa sotkuisiin kyselytuloksiin sekä alhaiseen käsittelynopeuteen.
- Datan kysely suoraan DW:stä voi vaatia tarkkaa syöttöä, jotta järjestelmä pystyy suodattamaan pois ei-toivotut tiedot. Mikä tekee esitystyökalujen kanssa toimimisesta hieman hankalaa.
- Olemassa on rajallinen joustavuus/analyyttiset ominaisuudet.
Lisäksi yksitasoinen arkkitehtuuri asettaa joitakin rajoja raportoinnin monimutkaisuudelle. Tällaista lähestymistapaa käytetään harvoin laajamittaisissa tietoalustoissa sen hitauden ja arvaamattomuuden vuoksi. Kehittyneiden tietokyselyjen suorittamiseksi tietovarastoa voidaan laajentaa matalan tason instansseilla, jotka helpottavat pääsyä tietoihin.
Kaksikerroksinen arkkitehtuuri (data mart layer)
Kaksikerroksisessa arkkitehtuurissa käyttöliittymän ja EDW:n väliin lisätään data mart -taso. Data mart on matalan tason tietovarasto, joka sisältää toimialuekohtaista tietoa. Yksinkertaisesti sanottuna se on toinen, pienemmän kokoluokan tietokanta, joka laajentaa EDW:tä myynti-/toimintaosastoille, markkinoinnille jne. tarkoitetuilla tiedoilla.
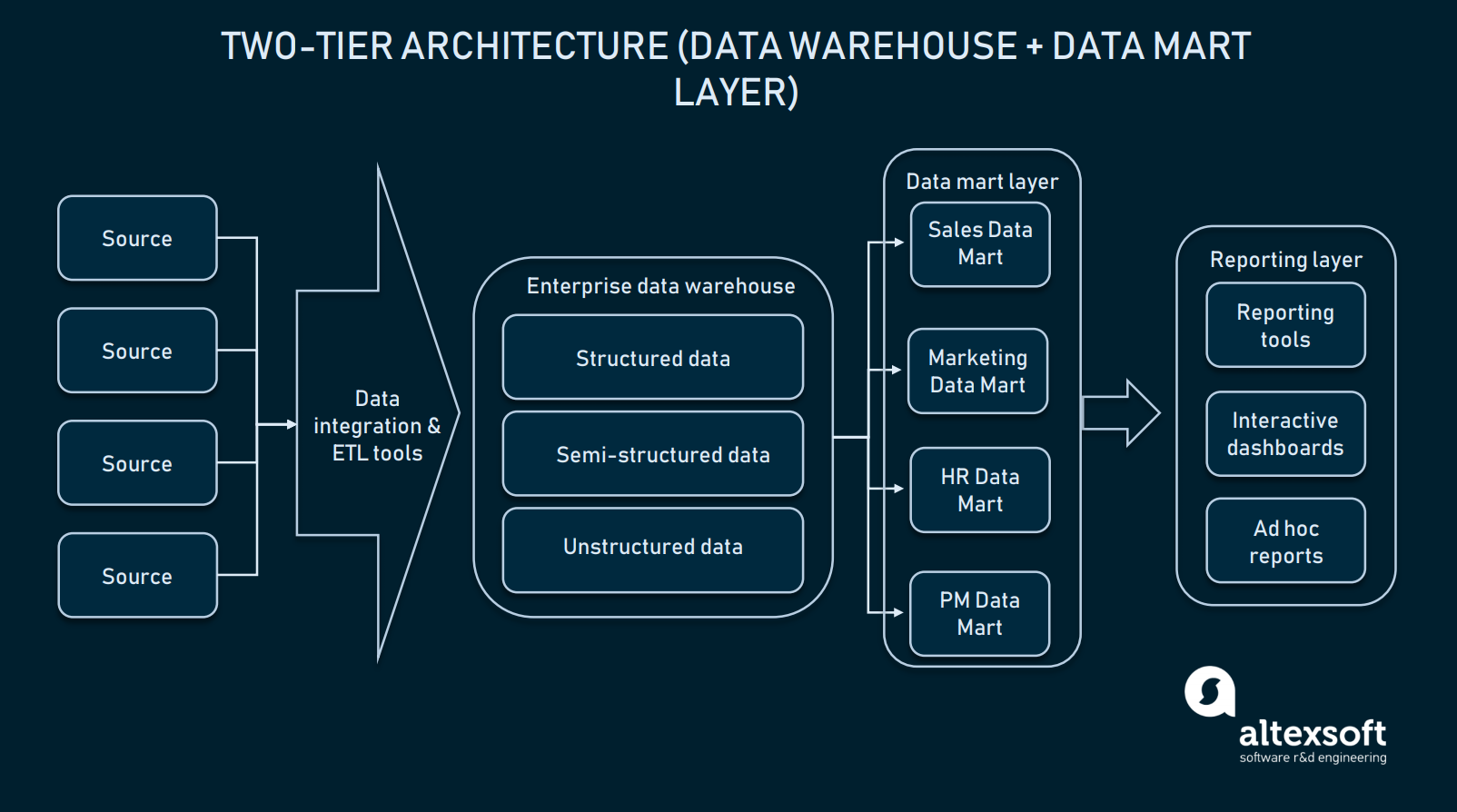
Kahden tason arkkitehtuurissa EDW:tä laajennetaan tietomarketeilla, jotta se tarjoaa toimialakohtaisia tietoja
Tietomarttikerroksen luominen vaatii lisäresursseja, jotta voidaan ottaa käyttöön laitteistoja ja integroida nuo tietokannat muuhun tietopalvelualustaan. Tällainen lähestymistapa ratkaisee kuitenkin kyselyn ongelman: Kukin osasto pääsee tarvittaviin tietoihin helpommin käsiksi, koska tietty karttatietokanta sisältää vain toimialakohtaista tietoa. Lisäksi datamartit rajoittavat loppukäyttäjien pääsyä tietoihin, mikä tekee EDW:stä turvallisemman.
Kolmitasoinen arkkitehtuuri (Online analytical processing)
Datamarttikerroksen päälle yritykset käyttävät myös OLAP-kuutioita (online analytical processing). OLAP-kuutio on tietyntyyppinen tietokanta, joka edustaa tietoja useista ulottuvuuksista. Kun relaatiotietokannat edustavat tietoja vain kahdessa ulottuvuudessa (ajattele Exceliä tai Google Sheetsia), OLAP mahdollistaa tietojen kokoamisen useista ulottuvuuksista ja siirtymisen ulottuvuuksien välillä.
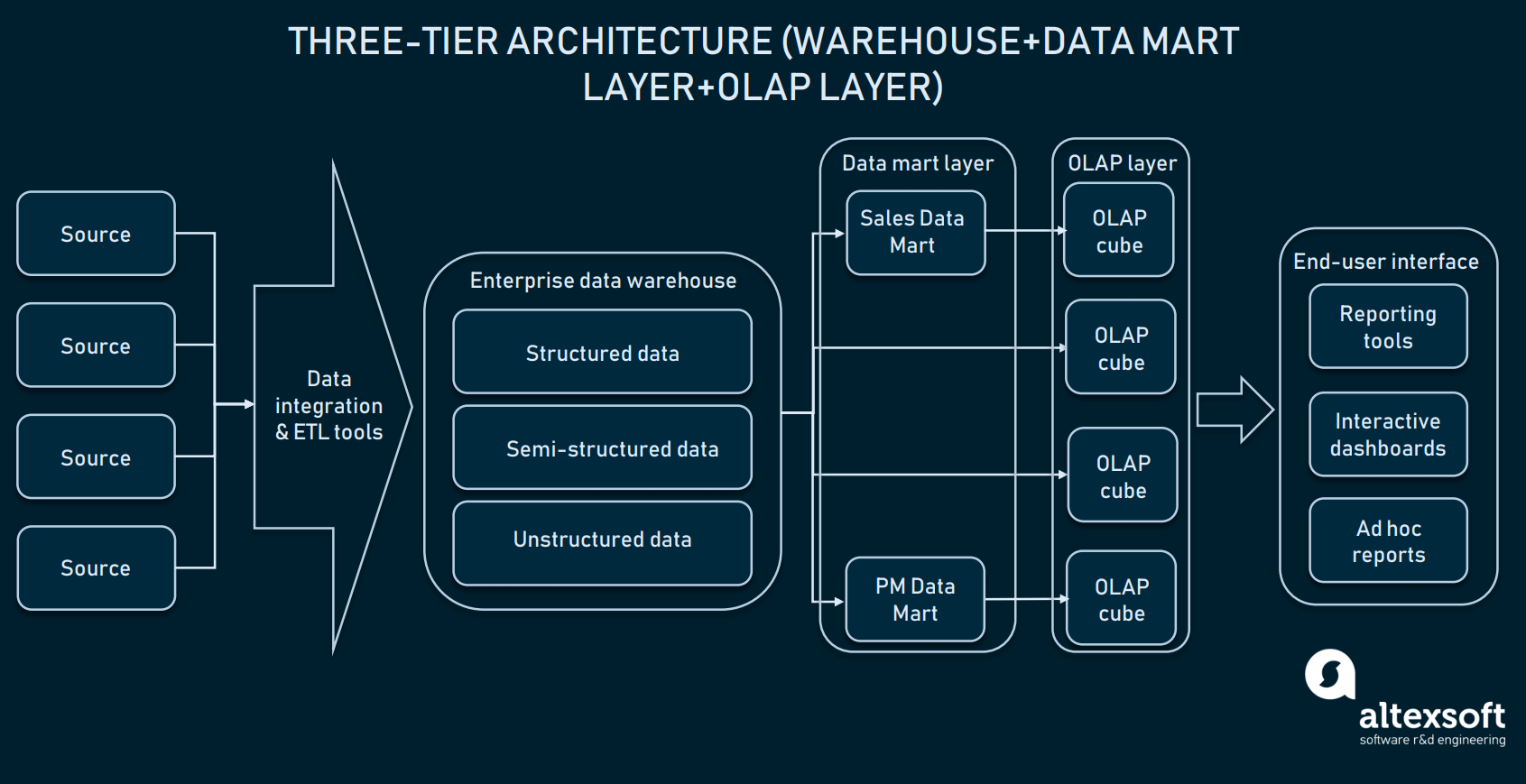
OLAP-kuutiot-kerros voi hankkia tietoja hajautetuista datamarteista (distributed marts) tai suoraan EDW:stä
Tietoa on melko hankala selittää sanoin, joten tarkastellaanpa tätä kätevää esimerkkiä siitä, miltä kuutio voi näyttää.
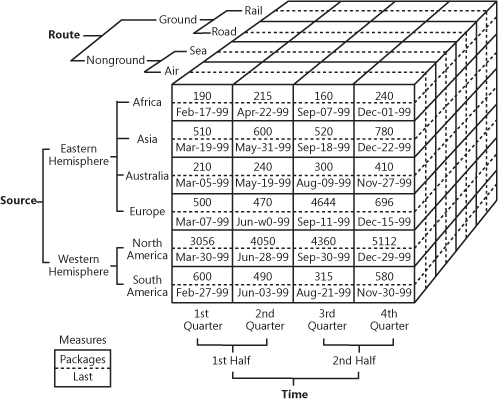
OLAP-kuutio, joka havainnollistaa moniulotteisia myyntitietoja
Lähde: oreilly.com
Kuten näet, kuutio lisää tietoihin ulottuvuuksia. Voit ajatella sen olevan useita Excel-taulukoita yhdistettynä toisiinsa. Kuution etupuoli on tavallinen kaksiulotteinen taulukko, jossa alue (Afrikka, Aasia jne.) on määritetty pystysuunnassa, kun taas myyntiluvut ja päivämäärät on kirjoitettu vaakasuunnassa. Taika alkaa, kun tarkastelemme kuution ylempää puolta, jossa myynti on segmentoitu reiteittäin ja alempana on määritetty ajanjakso. Tätä kutsutaan moniulotteiseksi dataksi.
OLAP:n liiketaloudellinen arvo on siinä, että sen avulla käyttäjät voivat pilkkoa tietoja yksityiskohtaisten raporttien laatimiseksi. Kunhan kuutiot on optimoitu toimimaan yhdessä tietovarastojen kanssa, niitä voidaan käyttää sekä suoraan EDW:n kanssa, jolloin ne antavat pääsyn kaikkeen yritystietoon, että erikseen kunkin datamartin kanssa. Toteutuksen osalta lähes kaikki varastopalvelujen tarjoajat tarjoavat OLAPia palveluna. Esimerkkinä mainittakoon Microsoftin dokumentaatio heidän OLAP-tarjonnastaan.
Tältä osin olemme käsitelleet EDW:n korkean tason suunnittelua organisaation tarpeisiin sovellettuna. Nyt pureudumme teknisiin komponentteihin, joita varasto voi sisältää.
Datavaratalo vs. Data Lake vs. Data Mart
Tietovarastoarkkitehtuurista puhuttaessa on mainittava sellaiset vaihtoehdot kuin datamartin tai datajärven käyttäminen varaston sijaan. Usein sekoitetaan toisiinsa, joten tarkennamme määritelmiä.
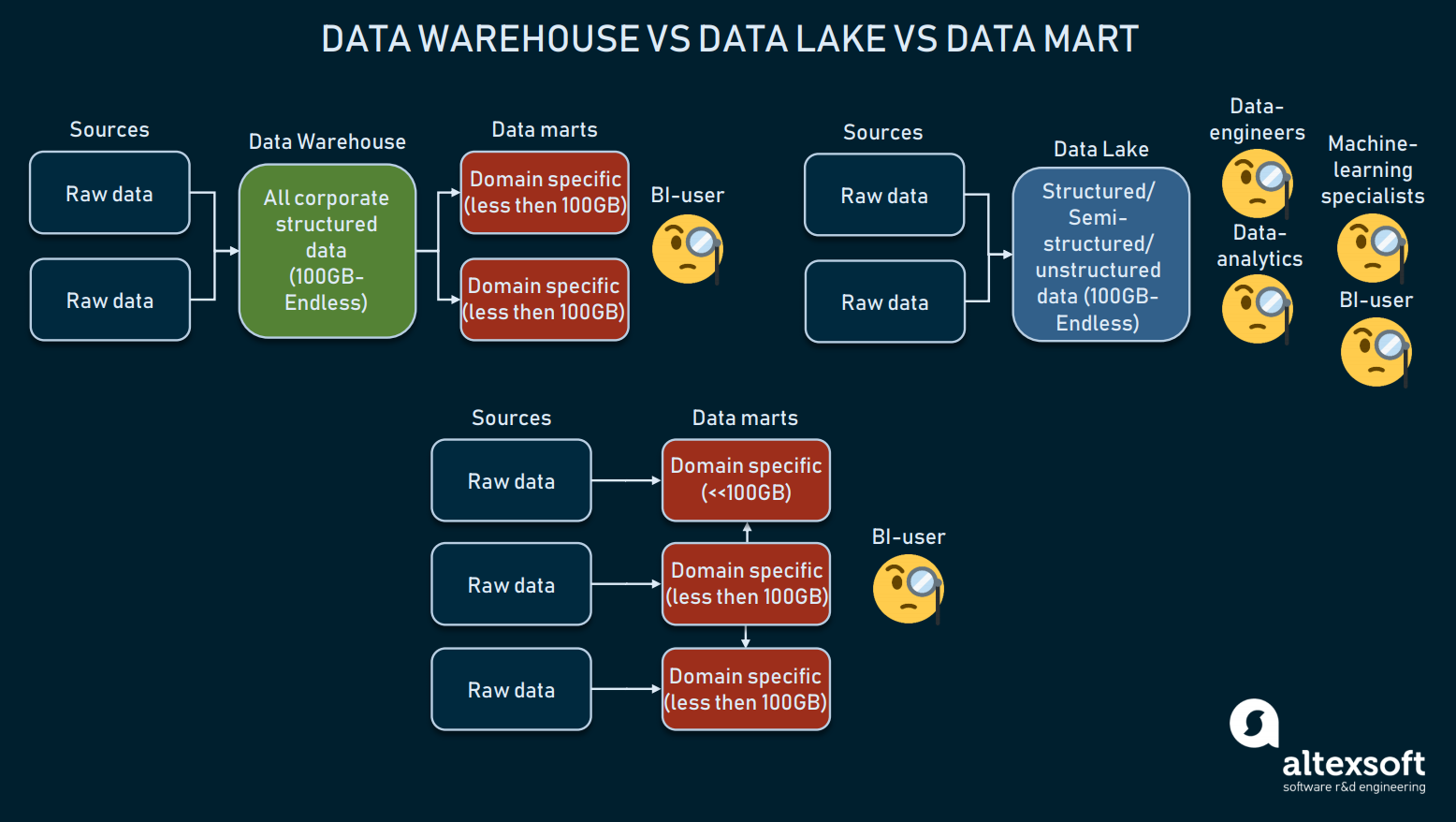
Kolmen datan tallennusmuodon vertailu
Datavarastot on tarkoitettu strukturoitujen tietojen tallentamiseen, jotta kyselytyökalut ja loppukäyttäjät saavat kattavat tulokset. Useimmiten BI:hen käytettävien tietovarastojen koko vaihtelee yleensä 100 Gt:n ja äärettömän välillä.
Data-järviä sen sijaan käytetään lähinnä raakadatan tai sekalaisen datan tallentamiseen. Niitä hyödynnetään usein koneoppimista, big dataa tai tiedonlouhintaa varten. Parin viime vuoden ajan datajärviä käytettiin BI:hen: raakadata ladataan järveen ja muunnetaan, mikä on vaihtoehto ETL-prosessille. Vaikka tällä lähestymistavalla on hyvät ja huonot puolensa, datajärvet voivat olla liian sotkuisia strukturoidun datan tavoittamiseksi.
Sitten meillä on data marts, joita voidaan myös käyttää vaihtoehtona DW:lle. Tällaisissa malleissa (kuten Kimballin mallissa) oletetaan, että käytetään useita tietomarketteja, jotka jakavat tietoja toimialoittain ja yhdistävät ne toisiinsa. Niiden pienen koon (yleensä alle 100 Gt) vuoksi yritykset tuskin pystyvät käyttämään datamartteja. Useimmiten datamartteja käytetään suuren DW:n segmentoimiseksi useampiin toimiviin.
Yritysten tietovarastokomponentit
Varastointialustan perustamiseen käytetään paljon välineitä. Olemme jo maininneet useimmat niistä, mukaan lukien itse tietovarasto. Tarkastellaan siis lintuperspektiivistä kunkin komponentin tarkoitusta ja toimintoja.
Lähteet. Se on yksinkertaista, tietokannat, joihin raakadata tallennetaan.
Extract, Transform, Load (ETL) tai Extract, Load, Transform (ELT) -kerros. Nämä ovat työkaluja, jotka suorittavat varsinaisen yhteyden lähdetietoihin, niiden louhinnan ja lataamisen paikkaan, jossa ne muunnetaan. Muunnos yhtenäistää tiedon muodon. ETL- ja ELT-lähestymistavat eroavat toisistaan siinä, että ETL:ssä muunnos tehdään ennen EDW:tä, staging-alueella. ELT on nykyaikaisempi lähestymistapa, joka hoitaa kaiken muunnoksen varastossa.
Staging area. ETL:n tapauksessa staging area on paikka, johon tiedot ladataan ennen EDW:tä. Siellä se puhdistetaan ja muunnetaan tiettyyn tietomalliin. Staging-alue voi sisältää myös työkaluja tiedon laadunhallintaa varten.
DW-tietokanta. Tiedot ladataan lopuksi tallennustilaan. ELT:ssä se saattaa vaatia tässä vielä jonkin verran muunnosta. Mutta tässä vaiheessa kaikki yleiset muutokset tehdään, joten tieto ladataan lopulliseen malliinsa (lopullisiin malleihinsa). Kuten mainitsimme, tietovarastot ovat useimmiten relaatiotietokantoja. DW sisältää myös tietokannan hallintajärjestelmän ja ylimääräistä tallennustilaa metatietoja varten.
Metatietomoduuli. Yksinkertaisesti sanottuna metatieto on tietoa tiedosta. Ne ovat selityksiä, jotka antavat käyttäjille/hallinnoijille vihjeitä siitä, mihin aiheeseen/alueeseen tämä tieto liittyy. Nämä tiedot voivat olla teknisiä metatietoja (esim. alkuperäinen lähde) tai liiketoiminnan metatietoja (esim. myyntialue). Kaikki metatiedot tallennetaan EDW:n erilliseen moduuliin ja niitä hallinnoi metatiedonhallinta.
Raportointikerros. Nämä ovat työkaluja, jotka antavat loppukäyttäjille pääsyn tietoihin. Tätä kerrosta kutsutaan myös BI-käyttöliittymäksi, ja se toimii kojelautana tietojen visualisoimiseksi, raporttien muodostamiseksi ja erillisten tietojen vetämiseksi.
Loppuajatus
Työkalujen ketjun ymmärtäminen, jonka avulla tiedot kulkevat eteenpäin, voi auttaa sinua hahmottamaan, mikä oikeastaan sopii tietoalustasi vaatimuksiin. Tietovaraston perustamisen suunnittelu voi vaatia vuosia suunnittelua ja testausta, koska se on laajuudeltaan kaikkein yksinkertaisimmillaan.
Yrityksen omistajana saatat hämmentyä vaihtoehtojen ja käytettävien tekniikoiden määrästä, joten on elintärkeää konsultoida tietovarastoinnin, ETL:n ja BI:n alan asiantuntijoita. Vaikka asiantuntijat voivat auttaa sinua teknisissä asioissa, liiketoimintatarkoituksen määrittelemiseksi sinun on puhuttava niiden kanssa, jotka tulevat käyttämään varsinaisia tietoja työssään.