




Tietokantojen suunnittelun johdanto
Attribuuttien tunnistaminen
Tietoelementtejä, jotka haluat tallentaa kullekin entiteetille, kutsutaan ”attribuuteiksi”.
Haluat tietää myytävistä tuotteista esimerkiksi hinnan, valmistajan nimen ja tyyppinumeron. Asiakkaista tiedät heidän asiakasnumeronsa, nimensä ja osoitteensa. Myymälöistä tiedät sijaintikoodin, nimen ja osoitteen. Myynneistä tiedät, milloin ne tapahtuivat, missä liikkeessä, mitä tuotteita myytiin ja mikä oli myynnin loppusumma. Myyjästä tiedät hänen henkilökuntansa numeron, nimen ja osoitteen. Sillä, mitä tarkalleen ottaen sisällytetään, ei ole vielä merkitystä; kyse on vain siitä, mitä haluat tallentaa.
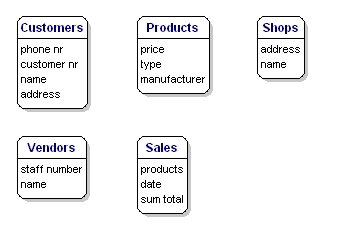
Kuva 6: Entiteetit attribuutteineen.
Derived Data
Derived data on dataa, joka on johdettu muista jo tallennetuista tiedoista. Tässä tapauksessa ’Summa summa’ on klassinen johdetun datan tapaus. Tiedät tarkalleen, mitä on myyty ja mitä kukin tuote maksaa, joten voit aina laskea, kuinka paljon myynnin loppusumma on. Näin ollen kokonaissummaa ei oikeastaan tarvitse tallentaa.
Miksi se sitten tallennetaan tähän? No, koska kyseessä on myynti, ja tuotteen hinta voi vaihdella ajan myötä. Tuotteen hinta voi olla tänään 10 euroa ja ensi kuussa 8 euroa, ja hallintoa varten sinun on tiedettävä, mitä se maksoi myyntihetkellä, ja helpoin tapa tehdä se on tallentaa se tähän. On paljon tyylikkäämpiä tapoja, mutta ne ovat liian syvällisiä tähän artikkeliin.
Ominaisuuksien ja suhteiden esittäminen: Entity Relationship Diagram (ERD)
Entity Relationship Diagram (ERD) antaa graafisen yleiskuvan tietokannasta. ER-kaavioita on useita tyylejä ja tyyppejä. Paljon käytetty merkintätapa on ”crowfeet”-merkintätapa, jossa oliot esitetään suorakulmioina ja olioiden väliset suhteet olioiden välisinä viivoina. Viivojen lopussa olevat merkit ilmaisevat suhteen tyypin. Suhteen se puoli, joka on pakollinen toisen suhteen olemassaololle, osoitetaan viivalla. Ei-pakolliset entiteetit merkitään ympyrällä. ”Monet” ilmaistaan ”variksenjalan” kautta; suhdeviiva jakautuu kolmeksi viivaksi.
Tässä artikkelissa käytämme DeZign for Databases -ohjelmaa tietokantamme suunnitteluun ja esittämiseen.
1:1 pakollinen suhde esitetään seuraavasti:
Kuva 7: Pakollinen yksi yhteen -suhde.
A 1:N pakollinen suhde:
Kuva 8: Pakollinen yksi monelle -suhde.
M:N-suhde on:
Kuva 9: Pakollinen monesta moneen -suhde.
Esimerkkimme malli näyttää seuraavalta:
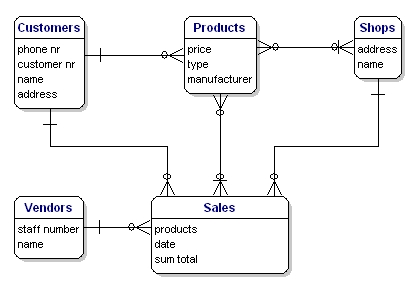
Kuva 10: Malli suhteineen.
Avainten määrittäminen
Primääriavaimet
Primääriavain (Primary Key, PK) on yksi tai useampi data-attribuutti, joka yksilöi olion yksiselitteisesti. Avainta, joka koostuu kahdesta tai useammasta attribuutista, kutsutaan yhdistelmäavaimeksi. Kaikilla ensisijaiseen avaimeen kuuluvilla attribuuteilla on oltava arvo jokaisessa tietueessa (jota ei voi jättää tyhjäksi), ja näiden attribuuttien sisältämien arvojen yhdistelmän on oltava taulukossa yksilöllinen.
Esimerkissä on muutamia ilmeisiä ehdokkaita ensisijaiseksi avaimeksi. Asiakkailla on kaikilla asiakasnumero, tuotteilla on kaikilla yksilöllinen tuotenumero ja myynneillä on myyntinumero. Jokainen näistä tiedoista on yksilöllinen ja jokainen tietue sisältää arvon, joten nämä attribuutit voivat olla ensisijainen avain. Usein ensisijaisena avaimena käytetään kokonaislukusaraketta, jotta tietue voidaan helposti löytää sen numeron perusteella.
Link-entiteetit viittaavat yleensä linkitettävien entiteettien ensisijaisen avaimen attribuutteihin. Linkki-entiteetin ensisijainen avain on yleensä kokoelma näitä viiteattribuutteja. Esimerkiksi oliossa Myynti_tiedot voisimme käyttää olioiden Myynti ja Tuotteet PK-arvojen yhdistelmää olion Myynti_tiedot PK-arvona. Näin varmistamme, että samaa tuotetta (tyyppiä) voidaan käyttää vain kerran samassa myynnissä. Useat saman tuotetyypin tuotteet myynnissä on ilmoitettava määrällä.
ERD:ssä primääriavainattribuutit on merkitty attribuutin nimen perässä olevalla tekstillä ”PK”. Esimerkissä vain entiteetillä ’shop’ ei ole ilmeistä ehdokasta PK:ksi, joten otamme käyttöön uuden attribuutin kyseiselle entiteetille: shopnr.
Vieraat avaimet
Yksikön vierasavain (Foreign Key, FK) on viittaus toisen entiteetin ensisijaiseen avaimeen. ERD:ssä kyseinen attribuutti merkitään ”FK”:lla sen nimen perässä. Entiteetin vieras avain voi olla myös osa ensisijaista avainta, jolloin attribuutin nimen perässä on ”PF”. Näin on yleensä linkki-entiteettien kohdalla, koska yleensä kaksi instanssia yhdistetään vain kerran toisiinsa (yhdellä myynnillä myydään vain yksi tuotetyyppi yhden kerran).
Jos laitamme kaikki linkki-entiteetit, PK:t ja FK:t ERD:hen, saamme alla esitetyn mallin. Huomaa, että attribuuttia ”tuotteet” ei enää tarvita kohdassa ”Myynti”, koska ”myydyt tuotteet” sisältyy nyt linkkitaulukkoon. Linkkitaulukkoon lisättiin toinen kenttä, ”quantity”, joka osoittaa, kuinka monta tuotetta on myyty. Määrä-kenttä lisättiin myös varastotaulukkoon osoittamaan, kuinka monta tuotetta on vielä varastossa.
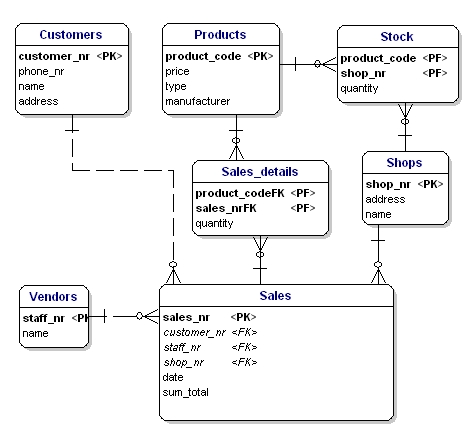
Kuva 11: Primääriavaimet ja vierasavaimet.
Attribuutin tietotyypin määrittäminen
Nyt on aika selvittää, mitä tietotyyppejä attribuuteissa on käytettävä. Erilaisia tietotyyppejä on paljon. Muutamia on standardoitu, mutta monilla tietokannoilla on omia tietotyyppejä, joilla kaikilla on omat etunsa. Joissakin tietokannoissa on mahdollisuus määritellä omia tietotyyppejä siltä varalta, että vakiotyypit eivät pysty tekemään tarvitsemiasi asioita.
Vakiotietotyypit, jotka jokainen tietokanta tuntee ja joita käytetään eniten, ovat: CHAR, VARCHAR, TEXT, FLOAT, DOUBLE ja INT.
Text:
- CHAR(pituus) – sisältää tekstiä (merkkejä, numeroita, välimerkkejä…). CHAR:lle on ominaista, että se tallentaa aina kiinteän määrän paikkoja. Jos määrittelet CHAR(10):n, voit tallentaa enintään kymmenen paikkaa, mutta jos käytät vain kahta paikkaa, tietokanta tallentaa silti 10 paikkaa. Loput kahdeksan paikkaa täytetään välilyönneillä.
- VARCHAR(pituus) – sisältää tekstiä (merkkejä, numeroita, välimerkkejä…). VARCHAR on sama kuin CHAR, erona on, että VARCHAR vie tilaa vain niin paljon kuin on tarpeen.
- TEXT – voi sisältää suuria määriä tekstiä. Riippuen tietokannan tyypistä tämä voi olla jopa gigatavuja.
Numbers:
- INT – sisältää positiivisen tai negatiivisen kokonaisluvun. Monissa tietokannoissa on muunnelmia INT:stä, kuten TINYINT, SMALLINT, MEDIUMINT, BIGINT, INT2, INT4, INT8. Nämä muunnelmat eroavat INT:stä vain siihen mahtuvan luvun koon suhteen. Tavallinen INT on 4 tavua (INT4), ja siihen mahtuu lukuja -2147483647 – +2147483646, tai jos määrittelet sen UNSIGNED-muodossa 0 – 4294967296. INT8 eli BIGINT voi olla vieläkin suurempi, 0:sta 18446744073709551616:een, mutta se vie 8 tavua levytilaa, vaikka siinä olisi vain pieni luku.
- FLOAT, DOUBLE – Sama idea kuin INT:llä, mutta voi tallentaa myös liukulukuja. . Huomaa, että tämä ei aina toimi täydellisesti. Esimerkiksi MySQL:ssä laskeminen näillä liukuluvuilla ei ole täydellistä, (1/3)*3 antaa MySQL:n liukuluvuilla tulokseksi 0.9999999, ei 1.
Muut tyypit:
- BLOB – binääritiedoille kuten tiedostoille.
- INET – IP-osoitteille. Käytettävissä myös verkkomaskille.
Esimerkissämme tietotyypit ovat seuraavat:
Kuva 12: Tietomalli, jossa näkyvät tietotyypit.
Normalisointi
Normalisointi tekee tietomallista joustavan ja luotettavan. Se aiheuttaa jonkin verran yleiskustannuksia, koska saat yleensä enemmän taulukoita, mutta sen avulla voit tehdä monia asioita tietomallillasi ilman, että sitä tarvitsee säätää. Voit lukea lisää tietokannan normalisoinnista tästä artikkelista.
Normalisointi, ensimmäinen muoto
Normalisoinnin ensimmäisessä muodossa todetaan, että oliossa ei saa olla toistuvia sarakeryhmiä. Olisimme voineet luoda olion ’myynti’, jossa olisi ollut attribuutteja jokaiselle ostetulle tuotteelle. Tämä näyttäisi seuraavalta:

Kuva 13: Ei ensimmäisessä normaalimuodossa.
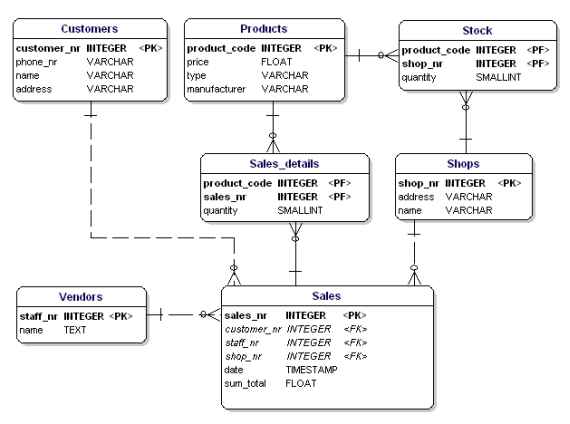
Virheellistä tässä on se, että nyt voidaan myydä vain 3 tuotetta. Jos sinun pitäisi myydä 4 tuotetta, sinun pitäisi aloittaa toinen myynti tai mukauttaa tietomallia lisäämällä ’product4’-attribuutteja. Molemmat ratkaisut ovat epätoivottuja. Näissä tapauksissa on aina luotava uusi entiteetti, joka yhdistetään vanhaan entiteettiin yksi-moneen-suhteen avulla.
Kuva 14: 1. normaalimuodon mukaisesti.
Normalisointi, toinen muoto
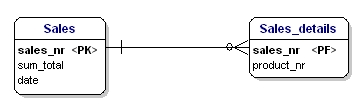
Toisen normalisointimuodon mukaan olion kaikkien attribuuttien tulisi olla täysin riippuvaisia koko pääavaimesta. Tämä tarkoittaa, että olion jokainen attribuutti voidaan tunnistaa vain koko pääavaimen kautta. Oletetaan, että meillä olisi päivämäärä oliossa Sales_details:

Kuva 15: Ei 2. normaalimuodossa.
Tämä olio ei ole toisen normaalimuodon mukainen, koska voidakseni katsoa myynnin päivämäärän minun ei tarvitse tietää, mitä on myyty (productnr), vaan minun tarvitsee tietää vain myyntinumero. Tämä ratkaistiin jakamalla taulut myynti- ja myynti_tiedot-tauluun:
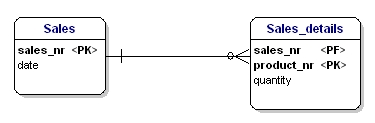
Kuva 16: 2. normaalimuodon mukainen.
Nyt jokainen olioiden attribuutti on riippuvainen koko olion PK:sta. Päivämäärä on riippuvainen myyntinumerosta, ja määrä on riippuvainen myyntinumerosta ja myydystä tuotteesta.
Normalisointi, kolmas muoto
Kolmannessa normalisointimuodossa todetaan, että kaikkien attribuuttien on oltava suoraan riippuvaisia pääavaimesta, eikä muista attribuuteista. Tämä näyttää siltä, mitä normalisoinnin toisessa muodossa sanotaan, mutta toisessa muodossa sanotaan itse asiassa päinvastoin. Toisessa normalisointimuodossa osoitat attribuutit PK:n kautta, kolmannessa normalisointimuodossa jokaisen attribuutin on oltava riippuvainen PK:sta, eikä mistään muusta.

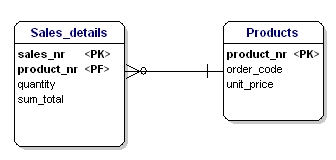
Kuva 17: Ei 3. normaalimuodossa.
Tässä tapauksessa irtotuotteen hinta on riippuvainen tilausnumerosta, ja tilausnumero on riippuvainen tuotenumerosta ja myyntinumerosta. Tämä ei ole kolmannen normaalimuodon mukaista. Taulukoiden jakaminen taas ratkaisee tämän.
Kuva 18: Kolmannen normaalimuodon mukainen.
Normalisointi, lisää muotoja
Normalisointimuotoja on muitakin kuin edellä mainitut kolme muotoa, mutta ne eivät kiinnosta keskivertokäyttäjää. Nämä muut lomakkeet ovat erittäin erikoistuneita tiettyihin sovelluksiin. Jos noudatat tässä artikkelissa mainittuja suunnittelusääntöjä ja normalisointia, luot suunnittelun, joka toimii erinomaisesti useimmissa sovelluksissa.
Normalisoitu tietomalli
Jos sovellat normalisointisääntöjä, huomaat, että myös tuotetaulukon ’valmistaja’ pitäisi olla erillinen taulukko:
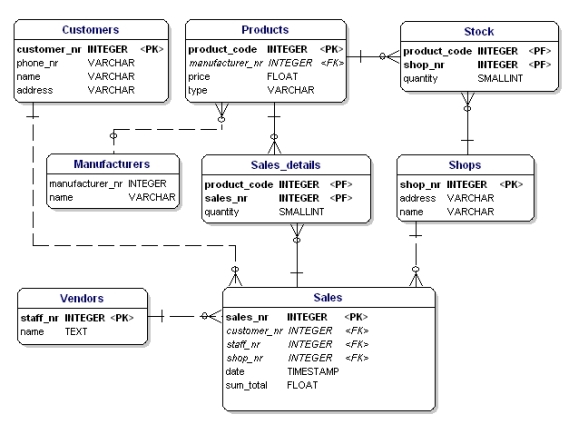
Kuva 19: 1., 2. ja 3. normaalimuodon mukainen tietomalli.