




Des paquets cassés : La fragmentation IP est défectueuse
Par opposition au réseau téléphonique public, l’internet a une conception à commutation de paquets. Mais quelle taille peuvent bien avoir ces paquets ?
 CC BY 2.0 image par ajmexico, inspiré par
CC BY 2.0 image par ajmexico, inspiré par
C’est une vieille question et les RFC IPv4 y répondent assez clairement. L’idée était de diviser le problème en deux préoccupations distinctes :
-
Quelle est la taille maximale des paquets qui peut être gérée par les systèmes d’exploitation des deux extrémités ?
-
Quelle est la taille maximale autorisée des datagrammes qui peuvent être poussés en toute sécurité à travers les connexions physiques entre les hôtes ?
Lorsqu’un paquet est trop gros pour une liaison physique, un routeur intermédiaire pourrait le découper en plusieurs datagrammes plus petits afin de le faire tenir. Ce processus est appelé fragmentation IP « en avant » et les datagrammes plus petits sont appelés fragments IP.
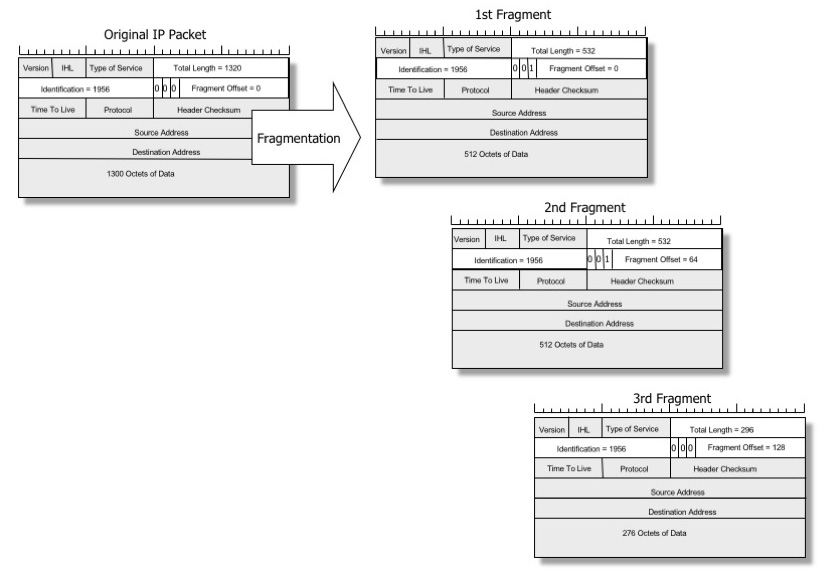 Image de Geoff Huston, reproduite avec autorisation
Image de Geoff Huston, reproduite avec autorisation
La spécification IPv4 définit les exigences minimales. D’après la RFC791:
Every internet destination must be able to receive a datagramof 576 octets either in one piece or in fragments tobe reassembled. Every internet module must be able to forward a datagram of 68octets without further fragmentation. La première valeur – taille autorisée des paquets réassemblés – ne pose généralement pas de problème. IPv4 définit le minimum comme 576 octets, mais les systèmes d’exploitation populaires peuvent faire face à de très gros paquets, généralement jusqu’à 65KiB.
La seconde est plus gênante. Toutes les connexions physiques ont des limites inhérentes à la taille des datagrammes, en fonction du support spécifique qu’elles utilisent. Par exemple, Frame Relay peut envoyer des datagrammes entre 46 et 4 470 octets. ATM utilise 53 octets fixes, Ethernet classique peut faire entre 64 et 1500 octets.
La spec définit l’exigence minimale – chaque lien physique doit être capable de transmettre des datagrammes d’au moins 68 octets. Pour IPv6, cette valeur minimale a été portée à 1 280 octets (voir RFC2460).
En revanche, la taille maximale des datagrammes pouvant être transmis sans fragmentation n’est définie par aucune spécification et varie selon le type de lien. Cette valeur est appelée MTU (Maximum Transmission Unit).
Le MTU définit une taille maximale de datagramme sur une liaison physique locale. L’internet est créé à partir de réseaux non homogènes, et sur le chemin entre deux hôtes, il peut y avoir des liens avec des valeurs MTU plus courtes. La taille maximale de paquet qui peut être transmise sans fragmentation entre deux hôtes distants est appelée MTU de chemin, et peut potentiellement être différente pour chaque connexion.
Éviter la fragmentation
On pourrait penser que c’est bien de construire des applications qui transmettent de très gros paquets et qui comptent sur les routeurs pour effectuer la fragmentation IP. Ce n’est pas une bonne idée. Les problèmes liés à cette approche ont été abordés pour la première fois par Kent et Mogul en 1987. Voici quelques points saillants:
-
Pour réussir à réassembler un paquet, tous les fragments doivent être livrés. Aucun fragment ne peut être corrompu ou se perdre en vol. Il n’y a tout simplement aucun moyen de notifier l’autre partie des fragments manquants!
-
Le dernier fragment n’aura presque jamais la taille optimale. Pour les transferts importants, cela signifie qu’une partie significative du trafic sera composée de datagrammes courts sous-optimaux – un gaspillage des précieuses ressources du routeur.
-
Avant le réassemblage, un hôte doit conserver en mémoire des datagrammes partiels et fragmentés. Cela ouvre une opportunité pour les attaques par épuisement de la mémoire.
-
Les fragments subséquents n’ont pas l’en-tête de la couche supérieure. L’en-tête TCP ou UDP n’est présent que dans le premier fragment. Il est donc impossible pour les pare-feu de filtrer les datagrammes de fragments en fonction de critères tels que les ports source ou destination.
Une description plus élaborée des problèmes de fragmentation IP se trouve dans ces articles de Geoff Huston :
- Evaluation de la fragmentation des paquets IPv4 et IPv6
- Fragmentation d’IPv6
Don’t fragment – ICMP Packet too big
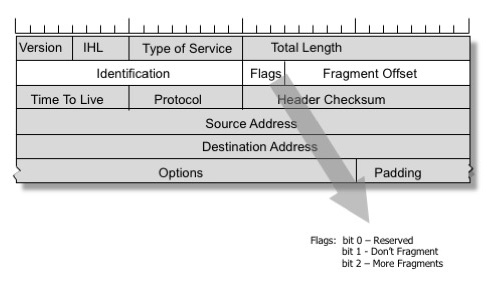
Image de Geoff Huston, reproduite avec permission
Une solution à ces problèmes a été incluse dans le protocole IPv4. Un expéditeur peut définir le drapeau DF (Don’t Fragment) dans l’en-tête IP, demandant aux routeurs intermédiaires de ne jamais effectuer la fragmentation d’un paquet. Au lieu de cela, un routeur avec un lien ayant une MTU plus petite enverra un message ICMP « en arrière » et informera l’expéditeur de réduire la MTU pour cette connexion.
Le protocole TCP active toujours le drapeau DF. La pile réseau regarde attentivement les messages ICMP « Packet too big » entrants et garde la trace de la caractéristique « path MTU » pour chaque connexion. Cette technique est appelée « path MTU discovery » et est surtout utilisée pour le protocole TCP, bien qu’elle puisse également être appliquée à d’autres protocoles basés sur IP. Être capable de délivrer les messages ICMP « Packet too big » est essentiel pour que la pile TCP fonctionne de manière optimale.
Comment Internet fonctionne réellement
Dans un monde parfait, les appareils connectés à Internet coopéreraient et traiteraient correctement les datagrammes fragmentés et les paquets ICMP associés. Dans la réalité cependant, les fragments IP et les paquets ICMP sont très souvent filtrés.
C’est parce que l’internet moderne est beaucoup plus complexe que prévu il y a 36 ans. Aujourd’hui, pratiquement personne n’est branché directement sur l’internet public.
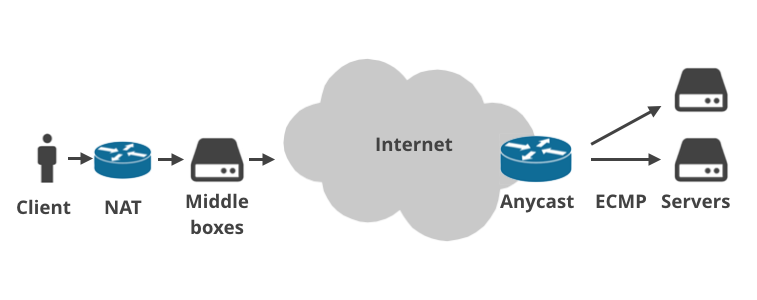
Les appareils des clients se connectent par le biais de routeurs domestiques qui font de la NAT (traduction d’adresse réseau) et appliquent généralement des règles de pare-feu. De plus en plus souvent, il y a plus d’une installation NAT sur le chemin des paquets (par exemple, NAT de classe opérateur). Ensuite, les paquets atteignent l’infrastructure du FAI où se trouvent les « boîtes intermédiaires » du FAI. Ils effectuent toutes sortes d’opérations bizarres sur le trafic : application de plafonds de forfaits, étranglement des connexions, journalisation, détournement de requêtes DNS, interdiction de sites Web imposée par le gouvernement, mise en place d’une mise en cache transparente ou « optimisation » du trafic d’une manière magique. Les boîtes intermédiaires sont utilisées notamment par les telcos mobiles.
De même, il y a souvent plusieurs couches entre un serveur et l’internet public. Les fournisseurs de services utilisent parfois le routage BGP Anycast. C’est-à-dire : ils traitent les mêmes plages IP à partir de plusieurs emplacements physiques dans le monde. Au sein d’un centre de données d’autre part, il est de plus en plus populaire d’utiliser ECMP Equal Cost Multi Path pour l’équilibrage de charge.
Chacune de ces couches entre un client et un serveur peut causer un problème de Path MTU. Permettez-moi d’illustrer cela avec quatre scénarios.
1. Client -> Serveur DF+ / ICMP
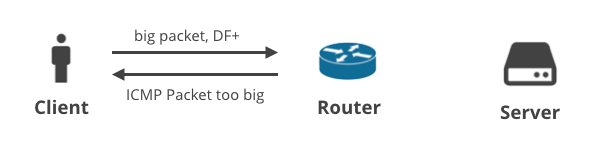
Dans le premier scénario, un client télécharge quelques données vers le serveur en utilisant TCP de sorte que le drapeau DF est activé sur tous les paquets. Si le client ne parvient pas à prédire un MTU approprié, un routeur intermédiaire abandonne les gros paquets et renvoie une notification ICMP « Packet too big » au client. Ces paquets ICMP pourraient être abandonnés par des dispositifs NAT de clients mal configurés ou des boîtes intermédiaires de FAI.
Selon l’article de Maikel de Boer et Jeffrey Bosma de 2012, environ 5% des hôtes IPv4 et 1% des hôtes IPv6 bloquent les paquets ICMP entrants.
Mon expérience le confirme. Les messages ICMP sont en effet souvent abandonnés pour des avantages de sécurité perçus, mais cela est relativement facile à corriger. Un problème plus important concerne certains FAI mobiles avec des boîtes intermédiaires bizarres. Ceux-ci ignorent souvent complètement l’ICMP et effectuent une réécriture de connexion très agressive. Par exemple, Orange Polska ignore non seulement les messages ICMP entrants « Packet too big », mais réécrit également l’état de la connexion et serre le MSS à un 1344 octets non négociable.
2. Client -> Serveur DF- / fragmentation
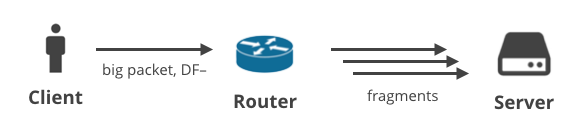
Dans le scénario suivant, un client télécharge quelques données avec un protocole autre que TCP, qui a le drapeau DF effacé. Par exemple, il peut s’agir d’un utilisateur jouant à un jeu en utilisant UDP, ou ayant un appel vocal. Les gros paquets sortants pourraient être fragmentés à un certain point du chemin.
Nous pouvons émuler cela en lançant ping avec une grande taille de charge utile :
$ ping -s 2048 facebook.comCette ping particulière échouera avec des charges utiles supérieures à 1472 octets. Toute taille supérieure sera fragmentée et ne sera pas délivrée correctement. Il existe de multiples raisons pour lesquelles les serveurs peuvent mal gérer les fragments, mais l’un des problèmes les plus courants est l’utilisation de l’équilibrage de charge ECMP. En raison du hachage ECMP, le premier datagramme contenant un en-tête de protocole est susceptible d’être équilibré en charge vers un serveur différent du reste des fragments, empêchant le réassemblage.
Pour une discussion plus détaillée de ce problème, voir :
- Notre précédent article sur l’ECMP.
- Comment Google tente de résoudre les problèmes de fragmentation ECMP avec l’équilibreur de charge Maglev L4.
De plus, la mauvaise configuration des serveurs et des routeurs est un problème important. Selon RFC7852, entre 30% et 55% des serveurs abandonnent les datagrammes IPv6 contenant un en-tête de fragmentation.
3. Serveur -> Client DF+ / ICMP
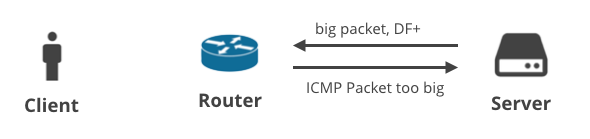
Le scénario suivant concerne un client téléchargeant des données sur TCP. Lorsque le serveur ne parvient pas à prédire le bon MTU, il devrait recevoir un message ICMP « Packet too big ». Facile, non ?
Malheureusement, ce n’est pas le cas, encore une fois à cause du routage ECMP. Le message ICMP sera très probablement livré au mauvais serveur – le hachage de 5-tuple du paquet ICMP ne correspondra pas au hachage de 5-tuple de la connexion problématique. Nous avons écrit sur ce sujet dans le passé, et avons développé un simple démon en espace utilisateur pour résoudre ce problème. Il fonctionne en diffusant la notification ICMP entrante « Packet too big » à tous les serveurs ECMP, en espérant que celui qui a la connexion problématique la verra.
En outre, en raison du routage Anycast, l’ICMP pourrait être livré au mauvais centre de données tout à fait ! Le routage Internet est souvent asymétrique et le meilleur chemin à partir d’un routeur intermédiaire pourrait diriger les paquets ICMP au mauvais endroit.
Les notifications ICMP manquantes « Packet too big » peuvent entraîner le blocage et la temporisation des connexions. Ce phénomène est souvent appelé un trou noir PMTU. Pour aider ce cas pessimiste, Linux met en œuvre une solution de contournement – MTU Probing RFC4821. MTU Probing essaie d’identifier automatiquement les paquets abandonnés à cause d’un mauvais MTU, et utilise des heuristiques pour l’ajuster. Cette fonctionnalité est contrôlée par un sysctl:
$ echo 1 > /proc/sys/net/ipv4/tcp_mtu_probingMais MTU probing n’est pas sans poser de problèmes. Tout d’abord, il a tendance à mal catégoriser les pertes de paquets liées à la congestion comme des problèmes de MTU. Les connexions de longue durée ont tendance à se retrouver avec un MTU réduit. Deuxièmement, Linux ne met pas en œuvre le sondage MTU pour IPv6.
4. Serveur -> Client DF- / fragmentation
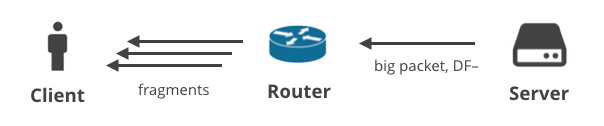
Enfin, il y a une situation où le serveur envoie de gros paquets en utilisant un protocole non-TCP avec le bit DF clair. Dans ce scénario, les gros paquets seront fragmentés sur le chemin vers le client. Cette situation est parfaitement illustrée par des réponses DNS volumineuses. Voici deux requêtes DNS qui généreront de grosses réponses et seront livrées au client sous forme de multiples fragments IP :
$ dig +notcp +dnssec DNSKEY org @199.19.56.1$ dig +notcp +dnssec DNSKEY org @2001:500:f::1Ces requêtes pourraient échouer en raison de ce qui a déjà été mentionné le routeur domestique mal configuré, le NAT cassé, les installations de FAI cassées ou les paramètres de pare-feu trop restrictifs.
Selon Boer et Bosma, environ 6% des hôtes IPv4 et 10% des hôtes IPv6 bloquent les datagrammes fragmentés entrants.
Voici quelques liens avec plus d’informations sur les problèmes de fragmentation spécifiques affectant le DNS :
- DNS-OARC Reply Size Test
- IPv6, les gros paquets UDP et le DNS
Mais Internet fonctionne toujours !
Avec toutes ces choses qui tournent mal, comment l’internet parvient-il encore à fonctionner ?
 CC BY-SA 3.0, source : Wikipédia
CC BY-SA 3.0, source : Wikipédia
C’est principalement dû au succès d’Ethernet. La grande majorité des liens de l’internet public sont Ethernet (ou dérivés de celui-ci) et supportent le MTU de 1500 octets.
Si vous assumez aveuglément le MTU de 1500, vous serez surpris de voir combien de fois cela fonctionnera très bien. L’internet continue de fonctionner principalement parce que nous utilisons tous un MTU de 1500 et avons rarement besoin de faire de la fragmentation IP et d’envoyer des messages ICMP.
Cela cesse de fonctionner sur une configuration inhabituelle avec des liens ayant un MTU non standard. Les VPN et autres logiciels de tunnels réseau doivent faire attention à ce que les fragments et les messages ICMP fonctionnent bien.
Ceci est particulièrement visible dans le monde IPv6, où de nombreux utilisateurs se connectent via des tunnels. Avoir un passage sain d’ICMP dans les deux sens est très important, d’autant plus que la fragmentation dans IPv6 ne fonctionne fondamentalement pas (nous avons cité deux sources affirmant qu’entre 10% et 50% des hôtes IPv6 bloquent l’en-tête de fragmentation IPv6).
Puisque les problèmes de Path MTU dans IPv6 sont si communs, de nombreux serveurs IPv6 brident le Path MTU au minimum mandaté par le protocole de 1280 octets. Cette approche échange un peu de performance pour une meilleure fiabilité.
Vérificateur en ligne de trous noirs ICMP
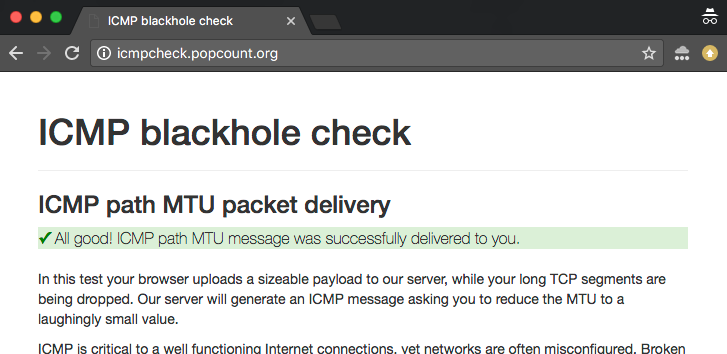
Pour aider à explorer et déboguer ces problèmes, nous avons construit un vérificateur en ligne. Vous pouvez trouver deux versions du test :
- Version IPv4 : http://icmpcheck.popcount.org
- IPv6 version : http://icmpcheckv6.popcount.org
Ces sites lancent deux tests:
- Le premier test délivrera des messages ICMP à votre ordinateur, avec l’intention de réduire le Path MTU à une valeur ridiculement petite.
- Le second test vous renverra des datagrammes fragmentés.
Recevoir un « pass » dans ces deux tests devrait vous donner une assurance raisonnable que l’internet de votre côté du câble se comporte bien.
Il est également facile d’exécuter les tests à partir de la ligne de commande, au cas où vous voudriez l’exécuter sur le serveur:
perl -e "print 'packettoolongyaithuji6reeNab4XahChaeRah1diej4' x 180" > payload.bincurl -v -s http://icmpcheck.popcount.org/icmp --data @payload.bincurl -v -s http://icmpcheckv6.popcount.org/icmp --data @payload.binCela devrait réduire le MTU du chemin vers notre serveur à 905 octets. Vous pouvez vérifier cela en regardant dans la table de cache de routage. Sous Linux, vous le faites avec :
ip route get `dig +short icmpcheck.popcount.org`Il est possible d’effacer le cache de routage sous Linux :
ip route flush cache to `dig +short icmpcheck.popcount.org`Le second test vérifie si les fragments sont correctement délivrés au client :
curl -v -s http://icmpcheck.popcount.org/frag -o /dev/nullcurl -v -s http://icmpcheckv6.popcount.org/frag -o /dev/nullSummary
Dans ce billet de blog, nous avons décrit les problèmes de détection des valeurs de Path MTU sur internet. Les datagrammes ICMP et fragmentés sont souvent bloqués des deux côtés des connexions. Les clients peuvent rencontrer des pare-feu mal configurés, des dispositifs NAT ou utiliser des FAI qui interceptent agressivement les connexions. Les clients utilisent aussi souvent des VPN ou des tunnels IPv6 qui, mal configurés, peuvent causer des problèmes de MTU de chemin.
De leur côté, les serveurs s’appuient de plus en plus souvent sur Anycast ou ECMP. Ces deux choses, ainsi que la mauvaise configuration des routeurs et des pare-feu, sont souvent la cause de l’abandon des datagrammes ICMP et fragmentés.
Enfin, nous espérons que le test en ligne est utile et peut vous donner un meilleur aperçu du fonctionnement interne de vos réseaux. Le test a des exemples utiles de la syntaxe de tcpdump, utiles pour obtenir plus de perspicacité. Bon débogage réseau !
Réparer des problèmes de fragmentation pour 10% de l’internet, c’est excitant ? Nous recrutons des ingénieurs système de tous bords, des programmeurs Golang, des wranglers C, et des stagiaires dans plusieurs endroits ! Rejoignez-nous à San Francisco, Londres, Austin, Champaign et Varsovie.
-
En IPv6, la fragmentation « forward » fonctionne légèrement différemment qu’en IPv4. Il est interdit aux routeurs intermédiaires de fragmenter les paquets, mais la source peut toujours le faire. Cela prête souvent à confusion – on peut demander à un hôte de fragmenter un paquet qu’il a transmis dans le passé. Cela n’a guère de sens pour les protocoles sans état comme le DNS. ︎
-
En passant, il existe aussi une « unité de transmission minimale » ! Dans le cadrage Ethernet couramment utilisé, chaque datagramme transmis doit comporter au moins 64 octets sur la couche 2. Cela se traduit par 22 octets sur la couche UDP et 10 octets sur la couche TCP. De multiples implémentations utilisées pour faire fuir la mémoire non initialisée sur des paquets plus courts ! ︎
-
Strictement parlant en IPv4 le paquet ICMP est nommé « Destination Unreachable, Fragmentation Needed et Don’t Fragment was Set ». Mais je trouve la description de l’erreur ICMP IPv6 « Packet too big » beaucoup plus claire. ︎
-
En guise d’indication, la pile TCP inclut également une valeur maximale autorisée « MSS » dans les paquets SYN (MSS est fondamentalement une valeur MTU réduite par la taille des en-têtes IP et TCP). Cela permet aux hôtes de savoir quel est le MTU sur leurs liaisons. Remarque : cela ne dit pas quel est le MTU sur les dizaines de liens internet entre les deux hôtes ! ︎
-
Prenons le côté sûr. Un meilleur MTU est 1492, pour tenir compte des connexions DSL et PPPoE. ︎