




Gebroken pakketten: IP fragmentatie is gebrekkig
In tegenstelling tot het openbare telefoonnetwerk heeft het internet een Packet Switched ontwerp. Maar hoe groot mogen deze pakketten zijn?
 CC BY 2.0 image by ajmexico, inspired by
CC BY 2.0 image by ajmexico, inspired by
Dit is een oude vraag en de IPv4 RFC’s geven er vrij duidelijk antwoord op. Het idee was om het probleem op te splitsen in twee afzonderlijke problemen:
-
Wat is de maximale pakketgrootte die kan worden verwerkt door besturingssystemen aan beide uiteinden?
-
Wat is de maximaal toegestane datagramgrootte die veilig door de fysieke verbindingen tussen de hosts kan worden gedrukt?
Wanneer een pakket te groot is voor een fysieke verbinding, kan een tussenliggende router het in meerdere kleinere datagrammen hakken om het passend te maken. Dit proces wordt “voorwaartse” IP-fragmentatie genoemd en de kleinere datagrammen worden IP-fragmenten genoemd.
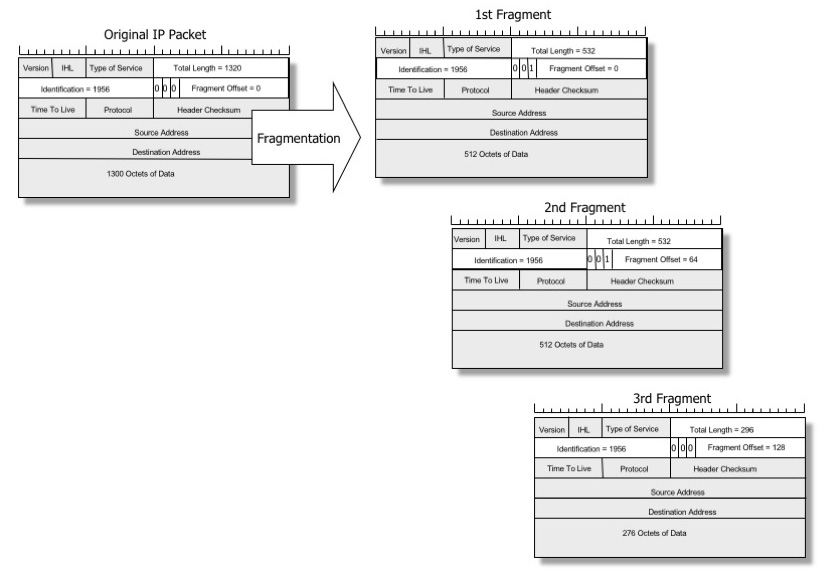 Afbeelding door Geoff Huston, gereproduceerd met toestemming
Afbeelding door Geoff Huston, gereproduceerd met toestemming
De IPv4-specificatie definieert de minimale vereisten. Uit de RFC791:
Every internet destination must be able to receive a datagramof 576 octets either in one piece or in fragments tobe reassembled. Every internet module must be able to forward a datagram of 68octets without further fragmentation. De eerste waarde – toegestane hergeassembleerde pakketgrootte – is typisch geen probleem. IPv4 definieert het minimum als 576 bytes, maar populaire besturingssystemen kunnen zeer grote pakketten aan, meestal tot 65KiB.
De tweede waarde is problematischer. Alle fysieke verbindingen hebben inherente datagramgrootte beperkingen, afhankelijk van het specifieke medium dat zij gebruiken. Frame Relay bijvoorbeeld kan datagrammen verzenden tussen 46 en 4.470 bytes. ATM gebruikt vaste 53 bytes, klassiek Ethernet kan tussen 64 en 1500 bytes.
De spec definieert de minimale eis – elke fysieke verbinding moet in staat zijn om datagrammen van tenminste 68 bytes te verzenden. Voor IPv6 is die minimale waarde opgetrokken tot 1.280 bytes (zie RFC2460).
De maximale datagramgrootte die zonder fragmentatie kan worden verzonden, wordt echter door geen enkele specificatie gedefinieerd en varieert per verbindingstype. Deze waarde wordt de MTU (Maximum Transmission Unit) genoemd.
De MTU definieert een maximale datagramgrootte op een lokale fysieke link. Het internet is opgebouwd uit niet-homogene netwerken, en op het pad tussen twee hosts kunnen er links zijn met kortere MTU-waarden. De maximale pakketgrootte die zonder fragmentatie tussen twee hosts op afstand kan worden verzonden, wordt de MTU van het pad genoemd, en kan voor elke verbinding anders zijn.
Fragmentatie vermijden
Een mens zou kunnen denken dat het prima is om toepassingen te bouwen die zeer grote pakketten verzenden en op routers vertrouwen om de IP-fragmentatie uit te voeren. Dit is echter geen goed idee. De problemen met deze aanpak werden voor het eerst besproken door Kent en Mogul in 1987. Hier volgen een paar hoogtepunten:
-
Om een pakket met succes opnieuw samen te stellen, moeten alle fragmenten worden afgeleverd. Geen enkel fragment kan corrupt raken of tijdens de vlucht verloren gaan. Er is eenvoudigweg geen manier om de andere partij te informeren over ontbrekende fragmenten!
-
Het laatste fragment zal bijna nooit de optimale grootte hebben. Voor grote overdrachten betekent dit dat een aanzienlijk deel van het verkeer zal bestaan uit suboptimale korte datagrammen – een verspilling van kostbare routerresources.
-
Voor de hermontage moet een host gedeeltelijke, gefragmenteerde datagrammen in het geheugen bewaren. Dit biedt de mogelijkheid van geheugenuitputtingsaanvallen.
-
Subsequente fragmenten missen de header van de hogere laag. De TCP- of UDP-header is alleen in het eerste fragment aanwezig. Dit maakt het voor firewalls onmogelijk om fragmentdatagrammen te filteren op basis van criteria zoals bron- of bestemmingspoorten.
Een uitgebreidere beschrijving van IP-fragmentatieproblemen is te vinden in deze artikelen van Geoff Huston:
- Evaluating IPv4 and IPv6 packet fragmentation
- Fragmenting IPv6
Don’t fragment – ICMP Packet too big
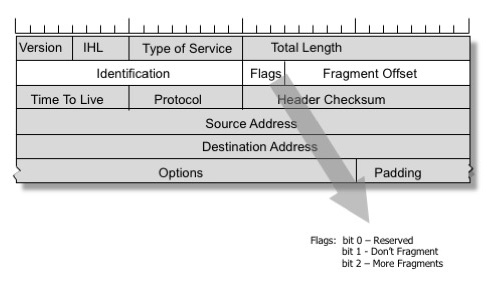
Image by Geoff Huston, reproduced with permission
Een oplossing voor deze problemen werd in het IPv4 protocol opgenomen. Een verzender kan de DF (Don’t Fragment) vlag in de IP header zetten, om tussenliggende routers te vragen nooit fragmentatie van een pakket uit te voeren. In plaats daarvan zal een router met een verbinding die een kleinere MTU heeft, een ICMP-bericht “terugsturen” en de afzender informeren om de MTU voor deze verbinding te verkleinen.
Het TCP-protocol zet altijd de DF-vlag. De netwerk stack kijkt zorgvuldig naar binnenkomende “Packet too big” ICMP berichten en houdt voor iedere verbinding het “path MTU” kenmerk bij. Deze techniek wordt “path MTU discovery” genoemd, en wordt meestal gebruikt voor TCP, hoewel het ook kan worden toegepast op andere IP-gebaseerde protocollen. Het kunnen afleveren van de ICMP “Packet too big”-berichten is van cruciaal belang om de TCP-stack optimaal te laten werken.
Hoe werkt het internet eigenlijk
In een perfecte wereld zouden op het internet aangesloten apparaten samenwerken en op de juiste manier omgaan met fragment datagrammen en de bijbehorende ICMP-pakketten. In werkelijkheid worden IP-fragmenten en ICMP-pakketten echter zeer vaak uitgefilterd.
Dit komt omdat het moderne internet veel complexer is dan 36 jaar geleden werd verwacht. Tegenwoordig is in principe niemand meer rechtstreeks op het openbare internet aangesloten.
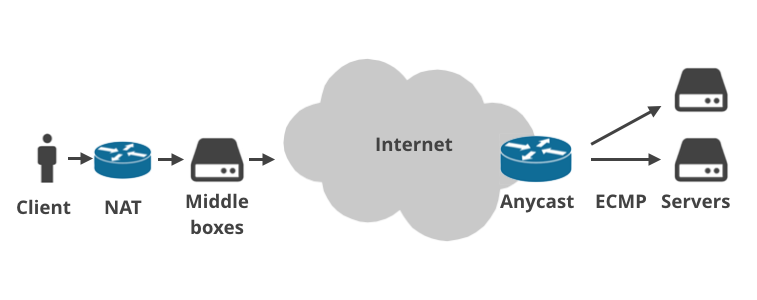
De apparaten van klanten maken verbinding via thuisrouters die NAT (Network Address Translation) doen en gewoonlijk firewallregels afdwingen. Steeds vaker is er meer dan één NAT-installatie op het pakketpad (bijv. carrier-grade NAT). Vervolgens komen de pakketten terecht op de ISP-infrastructuur waar ISP “middle boxes” staan. Deze doen allerlei vreemde dingen met het verkeer: ze dwingen plan-caps af, smoren verbindingen af, voeren logging uit, kapen DNS-verzoeken, leggen door de overheid opgelegde verboden op websites op, dwingen transparante caching af of “optimaliseren” het verkeer op een andere magische manier. De middle boxes worden vooral door mobiele telco’s gebruikt.
Op dezelfde manier zijn er vaak meerdere lagen tussen een server en het openbare internet. Service providers gebruiken soms Anycast BGP routing. Dat wil zeggen dat zij dezelfde IP-bereiken vanaf meerdere fysieke locaties over de hele wereld behandelen. Binnen een datacenter daarentegen wordt het steeds populairder om ECMP Equal Cost Multi Path te gebruiken voor load balancing.
Elke van deze lagen tussen een client en server kan een Path MTU probleem veroorzaken. Laat me dit illustreren met vier scenario’s.
1. Client -> Server DF+ / ICMP
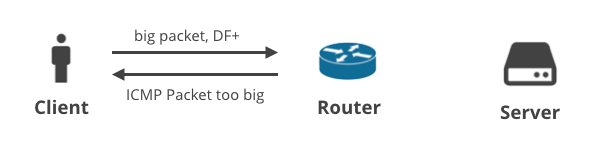
In het eerste scenario uploadt een client gegevens naar de server met TCP, zodat de DF-flag op alle pakketten wordt gezet. Als de client er niet in slaagt om een geschikte MTU te voorspellen, zal een tussenliggende router de grote pakketten laten vallen en een ICMP “Packet too big” notificatie terugsturen naar de client. Deze ICMP-pakketten kunnen worden gedropt door verkeerd geconfigureerde NAT-apparaten van klanten of ISP middle boxes.
Volgens het artikel van Maikel de Boer en Jeffrey Bosma uit 2012 blokkeert ongeveer 5% van de IPv4- en 1% van de IPv6-hosts inkomende ICMP-pakketten.
Mijn ervaring bevestigt dit. ICMP berichten worden inderdaad vaak gedropt vanwege vermeende veiligheidsvoordelen, maar dit is relatief eenvoudig op te lossen. Een groter probleem is er met bepaalde mobiele ISP’s met vreemde middle boxes. Deze negeren ICMP vaak volledig en voeren zeer agressieve connection rewriting uit. Orange Polska negeert bijvoorbeeld niet alleen inkomende “Packet too big” ICMP-berichten, maar herschrijft ook de verbindingsstatus en klemt de MSS af op een niet-onderhandelbare 1344 bytes.
2. Client -> Server DF- / fragmentatie
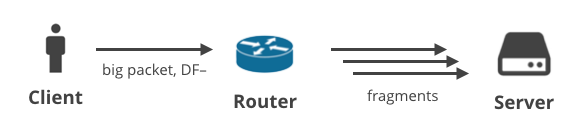
In het volgende scenario uploadt een client gegevens met een ander protocol dan TCP, waarbij de DF-vlag is gewist. Dit kan bijvoorbeeld een gebruiker zijn die een spel speelt met UDP, of die een telefoongesprek voert. De grote uitgaande pakketten zouden op een bepaald punt in het pad gefragmenteerd kunnen raken.
We kunnen dit emuleren door ping te starten met een grote payload grootte:
$ ping -s 2048 facebook.comDeze specifieke ping zal falen met payloads groter dan 1472 bytes. Elke grotere lading zal gefragmenteerd worden en niet goed worden afgeleverd. Er zijn meerdere redenen waarom servers een fout maken met fragmenten, maar een van de populaire problemen is het gebruik van ECMP load balancing. Door de ECMP hashing zal het eerste datagram dat een protocol header bevat waarschijnlijk naar een andere server worden load-balanced dan de rest van de fragmenten, waardoor de hermontage wordt verhinderd.
Voor een meer gedetailleerde bespreking van dit probleem, zie:
- Onze vorige bijdrage over ECMP.
- Hoe Google probeert ECMP fragmentatie problemen op te lossen met Maglev L4 Load balancer.
Verder is server en router misconfiguratie een belangrijk probleem. Volgens RFC7852 laat tussen 30% en 55% van de servers IPv6-datagrammen met fragmentatieheaders vallen.
3. Server -> Client DF+ / ICMP
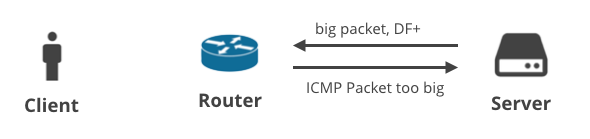
Het volgende scenario gaat over een client die gegevens downloadt via TCP. Wanneer de server er niet in slaagt de juiste MTU te voorspellen, zou hij een ICMP “Packet too big” bericht moeten ontvangen. Makkelijk, toch?
Helaas is dat niet zo, alweer vanwege ECMP routing. Het ICMP bericht zal waarschijnlijk bij de verkeerde server worden afgeleverd – de 5-tuple hash van het ICMP pakket zal niet overeenkomen met de 5-tuple hash van de problematische verbinding. We hebben hier in het verleden over geschreven, en een eenvoudige userpace daemon ontwikkeld om dit op te lossen. Het werkt door het broadcasten van de inkomende ICMP “Packet too big” melding naar alle ECMP servers, in de hoop dat degene met de problematische verbinding het ziet.
Door Anycast routing kan de ICMP ook bij het verkeerde datacenter worden afgeleverd! Internet routing is vaak asymmetrisch en het beste pad van een tussenliggende router kan de ICMP-pakketten naar de verkeerde plaats sturen.
Missende ICMP “Packet too big” meldingen kunnen resulteren in verbindingen die vastlopen en een time-out krijgen. Dit wordt vaak een PMTU blackhole genoemd. Om dit pessimistische geval te verhelpen heeft Linux een workaround geïmplementeerd – MTU Probing RFC4821. MTU Probing probeert automatisch pakketten te identificeren die gedropt worden door de verkeerde MTU, en gebruikt heuristieken om dit aan te passen. Deze functie wordt geregeld via een sysctl:
$ echo 1 > /proc/sys/net/ipv4/tcp_mtu_probingMaar MTU probing is niet zonder zijn eigen problemen. Ten eerste heeft het de neiging om congestie-gerelateerd pakketverlies verkeerd te categoriseren als MTU problemen. Lang lopende verbindingen hebben de neiging om te eindigen met een gereduceerde MTU. Ten tweede implementeert Linux geen MTU Probing voor IPv6.
4. Server -> Client DF- / fragmentatie
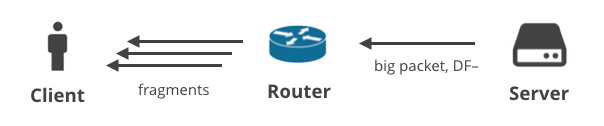
Ten slotte is er een situatie waarin de server grote pakketten verstuurt met een niet-TCP protocol waarbij het DF-bit is uitgeschakeld. In dit scenario worden de grote pakketten op het pad naar de client gefragmenteerd. Deze situatie wordt het best geïllustreerd met grote DNS antwoorden. Hier zijn twee DNS-verzoeken die grote antwoorden genereren en bij de client worden afgeleverd als meerdere IP-fragmenten:
$ dig +notcp +dnssec DNSKEY org @199.19.56.1$ dig +notcp +dnssec DNSKEY org @2001:500:f::1Deze verzoeken kunnen mislukken als gevolg van de reeds genoemde verkeerd geconfigureerde thuisrouter, kapotte NAT, kapotte ISP-installaties, of te restrictieve firewall-instellingen.
Volgens Boer en Bosma blokkeert ongeveer 6% van de IPv4- en 10% van de IPv6-hosts inkomende fragment-datagrammen.
Hier zijn enkele links met meer informatie over de specifieke fragmentatieproblemen van DNS:
- DNS-OARC Reply Size Test
- IPv6, Large UDP Packets and the DNS
Het internet werkt nog steeds!
Terwijl al deze dingen fout gaan, hoe slaagt het internet er dan toch in om te werken?
 CC BY-SA 3.0, bron: Wikipedia
CC BY-SA 3.0, bron: Wikipedia
Dit is vooral te danken aan het succes van Ethernet. De overgrote meerderheid van de verbindingen in het openbare internet is Ethernet (of daarvan afgeleid) en ondersteunt de MTU van 1500 bytes.
Als je blindelings uitgaat van de MTU van 1500, zul je verbaasd zijn hoe vaak het gewoon goed werkt. Het internet blijft meestal werken omdat we allemaal een MTU van 1500 gebruiken en zelden IP-fragmentatie hoeven te doen en ICMP-berichten hoeven te versturen.
Dit werkt niet meer bij een ongebruikelijke opstelling met links die een niet-standaard MTU hebben. VPN’s en andere netwerk tunnel software moeten er op letten dat de fragmenten en ICMP berichten goed werken.
Dit is vooral zichtbaar in de IPv6 wereld, waar veel gebruikers verbinding maken via tunnels. Het hebben van een gezonde doorgang van ICMP in beide richtingen is zeer belangrijk, vooral omdat fragmentatie in IPv6 in principe niet werkt (wij citeerden twee bronnen die beweren dat tussen 10% en 50% van de IPv6 hosts de IPv6 Fragment header blokkeren).
Omdat de Path MTU problemen in IPv6 zo gebruikelijk zijn, klemmen veel IPv6 servers de Path MTU tot het protocol gemandateerde minimum van 1280 bytes. Deze aanpak verruilt een beetje prestatie voor de beste betrouwbaarheid.
Online ICMP blackhole checker
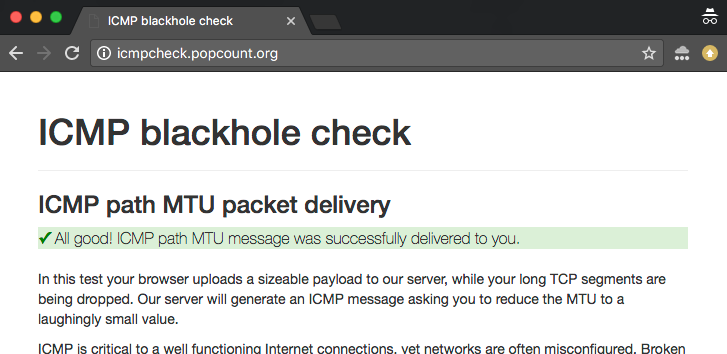
Om deze problemen te onderzoeken en te debuggen, hebben we een online checker gebouwd. U kunt twee versies van de test vinden:
- IPv4 versie: http://icmpcheck.popcount.org
- IPv6 versie: http://icmpcheckv6.popcount.org
Deze sites starten twee tests:
- De eerste test zal ICMP berichten naar uw computer sturen, met de bedoeling om de Path MTU te reduceren tot een lachwekkend kleine waarde.
- De tweede test zal fragment datagrammen naar u terug sturen.
Het ontvangen van een “pass” in beide tests zou u een redelijke zekerheid moeten geven dat het internet aan uw kant van de kabel zich goed gedraagt.
Het is ook gemakkelijk om de tests vanaf de command line uit te voeren, voor het geval u het op de server wilt uitvoeren:
perl -e "print 'packettoolongyaithuji6reeNab4XahChaeRah1diej4' x 180" > payload.bincurl -v -s http://icmpcheck.popcount.org/icmp --data @payload.bincurl -v -s http://icmpcheckv6.popcount.org/icmp --data @payload.binDit zou de path MTU naar onze server tot 905 bytes moeten reduceren. Je kunt dit controleren door in de routing cache tabel te kijken. Op Linux doet u dit met:
ip route get `dig +short icmpcheck.popcount.org`Het is mogelijk om de routing cache op Linux te wissen:
ip route flush cache to `dig +short icmpcheck.popcount.org`De tweede test controleert of fragmenten goed worden afgeleverd bij de client:
curl -v -s http://icmpcheck.popcount.org/frag -o /dev/nullcurl -v -s http://icmpcheckv6.popcount.org/frag -o /dev/nullSamenvatting
In deze blogpost hebben we de problemen beschreven met het detecteren van Path MTU waarden op het internet. ICMP en fragment datagrammen worden vaak aan beide zijden van de verbindingen geblokkeerd. Cliënten kunnen te maken krijgen met verkeerd geconfigureerde firewalls, NAT apparaten of gebruiken ISP’s die agressief verbindingen onderscheppen. Cliënten maken ook vaak gebruik van VPN’s of IPv6-tunnels die, verkeerd geconfigureerd, MTU-problemen op het pad kunnen veroorzaken.
Servers daarentegen vertrouwen steeds vaker op Anycast of ECMP. Beide zaken, alsmede router en firewall misconfiguratie zijn vaak een oorzaak voor ICMP en fragment datagrammen worden gedropt.
Finishing, we hopen dat de online test nuttig is en u meer inzicht kan geven in de innerlijke werking van uw netwerken. De test bevat nuttige voorbeelden van tcpdump syntaxis, handig om meer inzicht te krijgen. Veel plezier met het debuggen van netwerken!
Is het oplossen van fragmentatieproblemen voor 10% van het internet spannend? We zoeken systeemingenieurs van alle strepen, Golang programmeurs, C wranglers, en stagiaires op meerdere locaties! Kom bij ons in San Francisco, Londen, Austin, Champaign en Warschau.
-
In IPv6 werkt de “forward” fragmentatie iets anders dan in IPv4. De tussenliggende routers mogen de pakketten niet fragmenteren, maar de bron mag het nog wel doen. Dit is vaak verwarrend – een host kan gevraagd worden om een pakket te fragmenteren dat hij in het verleden heeft verzonden. Dit heeft weinig zin voor stateless protocollen zoals DNS. ︎
-
Terzijde: er bestaat ook een “minimum transmission unit”! Bij de gebruikelijke Ethernet-framing moet elk verzonden datagram op laag 2 ten minste 64 bytes bevatten. Dit vertaalt zich naar 22 bytes op UDP en 10 bytes op TCP laag. Meerdere implementaties lekten ongeïnitialiseerd geheugen op kortere pakketten! ︎
-
Strict genomen heet het ICMP-pakket in IPv4 “Destination Unreachable, Fragmentation Needed and Don’t Fragment was Set”. Maar ik vind de IPv6 ICMP foutomschrijving “Packet too big” veel duidelijker. ︎
-
Als hint kan de TCP-stack ook een maximaal toegestane “MSS”-waarde in SYN-pakketten opnemen (MSS is in feite een MTU-waarde verminderd met de grootte van IP- en TCP-headers). Hierdoor kunnen de hosts weten wat de MTU is op hun links. Let op: dit zegt niet wat de MTU is op de tientallen internetverbindingen tussen de twee hosts! ︎
-
Laten we het zekere voor het onzekere nemen. Een betere MTU is 1492, om rekening te houden met DSL en PPPoE verbindingen. ︎