




Bevezetés az adatbázis-tervezésbe
Attribútumok azonosítása
Az egyes entitásokhoz elmenteni kívánt adatelemeket “attribútumoknak” nevezzük.
Az Ön által értékesített termékekről tudni szeretné például, hogy mennyi az ára, mi a gyártó neve és mi a típusszáma. A vásárlókról tudod a vásárlószámukat, a nevüket és a címüket. Az üzletekről tudod a helykódot, a nevet, a címet. Az eladásokról tudja, hogy mikor történtek, melyik üzletben, milyen termékeket adtak el, és mennyi volt az eladás összege. Az eladókról tudod az alkalmazottak számát, nevét és címét. Hogy pontosan mi kerül bele, annak még nincs jelentősége, még csak arról van szó, hogy mit szeretnél megmenteni.
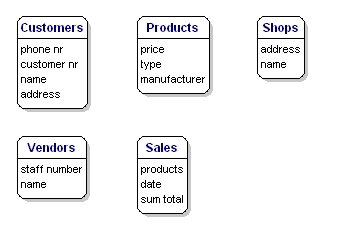
6. ábra: Entitások attribútumokkal.
Származott adatok
A származtatott adatok olyan adatok, amelyek más, már elmentett adatokból származnak. Ebben az esetben az “összesített összeg” a származtatott adatok klasszikus esete. Pontosan tudja, hogy mit adtak el, és mennyibe kerülnek az egyes termékek, így mindig ki tudja számolni, hogy mennyi az eladások összege. Tehát valójában nincs szükség a végösszeg elmentésére.
Akkor miért kell itt elmenteni? Nos, mert ez egy eladás, és a termék ára idővel változhat. Egy termék ára lehet ma 10 euró, a következő hónapban pedig 8 euró, és az adminisztrációhoz tudnod kell, hogy mennyibe került az eladás időpontjában, és ezt a legegyszerűbben úgy tudod megtenni, ha ide mented. Rengeteg elegánsabb módja is van, de ezek túl mélyrehatóak ehhez a cikkhez.
Egységek és kapcsolatok bemutatása: Entitáskapcsolati diagram (ERD)
Az entitáskapcsolati diagram (ERD) grafikus áttekintést ad az adatbázisról. Az ER-diagramoknak többféle stílusa és típusa létezik. Egy sokat használt jelölés a “crowfeet” jelölés, ahol az entitások téglalapokként, az entitások közötti kapcsolatok pedig az entitások közötti vonalként vannak ábrázolva. A vonalak végén lévő jelek jelzik a kapcsolat típusát. A kapcsolatnak azt az oldalát, amelyik kötelező a másik létezéséhez, a vonalon egy kötőjel jelzi. A nem kötelező entitásokat egy kör jelzi. A “sok” egy “varjútollal” van jelölve; a kapcsolati vonal három vonalra oszlik.
Ebben a cikkben a DeZign for Databases programot használjuk adatbázisunk tervezéséhez és bemutatásához.
A kötelező 1:1 kapcsolat a következőképpen van ábrázolva:
7. ábra: Kötelező egy az egyhez kapcsolat.
Egy 1:N kötelező kapcsolat:
8. ábra: Kötelező egy a sokhoz kapcsolat.
Egy M:N kapcsolat:
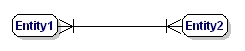
9. ábra: Kötelező sok a sokhoz kapcsolat.
Példánk modellje így fog kinézni:
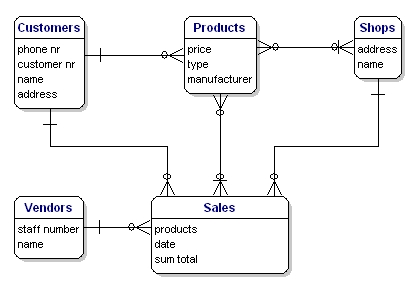
10. ábra: Modell kapcsolatokkal.
Kulcsok hozzárendelése
Primer kulcsok
A primer kulcs (PK) egy vagy több adatattribútum, amely egyedileg azonosít egy entitást. A két vagy több attribútumból álló kulcsot összetett kulcsnak nevezzük. Az elsődleges kulcs részét képező minden attribútumnak minden rekordban rendelkeznie kell egy értékkel (amely nem maradhat üresen), és az attribútumokon belüli értékek kombinációjának egyedinek kell lennie a táblázatban.
A példában van néhány nyilvánvaló jelölt az elsődleges kulcsra. Az ügyfelek mindegyike rendelkezik egy ügyfélszámmal, a termékek mindegyike rendelkezik egy egyedi termékszámmal, az eladások pedig egy értékesítési számmal. Mindegyik adat egyedi, és minden rekord tartalmazni fog egy értéket, így ezek az attribútumok lehetnek elsődleges kulcsok. Gyakran egy egész szám oszlopot használnak elsődleges kulcsként, így egy rekord könnyen megtalálható a számán keresztül.
A link-entitások általában az általuk összekapcsolt entitások elsődleges kulcs attribútumaira hivatkoznak. A link-entitás elsődleges kulcsa általában ezen referencia-attribútumok gyűjteménye. Például a Sales_details entitásban a Sales_details PK-jaként használhatjuk a sales és products entitások PK-jainak kombinációját. Így biztosítjuk, hogy ugyanazt a terméket (típust) csak egyszer lehessen használni ugyanabban az értékesítésben. Ugyanazon terméktípus több darabját egy értékesítésben a mennyiséggel kell jelezni.
Az ERD-ben az elsődleges kulcs attribútumokat az attribútum neve mögött a “PK” szöveg jelzi. A példában csak a ‘shop’ entitásnak nincs nyilvánvaló PK-jelöltje, ezért egy új attribútumot vezetünk be az adott entitáshoz: shopnr.
Foreign Keys
A Foreign Key (FK) egy entitásban egy másik entitás elsődleges kulcsára való hivatkozás. Az ERD-ben ez az attribútum a neve mögött “FK”-val lesz jelölve. Egy entitás idegen kulcsa lehet az elsődleges kulcs része is, ebben az esetben az attribútumot a neve mögött “PF” betűvel jelöljük. Ez általában a link-entitásoknál van így, mert általában két példányt csak egyszer kapcsolunk össze (1 eladás esetén csak 1 terméktípust adunk el 1 alkalommal).
Ha az összes link-entitást, PK-t és FK-t betesszük az ERD-be, akkor az alábbiakban látható modellt kapjuk. Felhívjuk a figyelmet arra, hogy a “termékek” attribútumra már nincs szükség az “Értékesítés”-ben, mivel az “eladott termékek” már szerepel a link-táblázatban. A link-táblába egy másik mezőt is beillesztettünk, a “mennyiséget”, amely azt jelzi, hogy hány terméket adtak el. A mennyiség mezőt a készlet-táblában is hozzáadtuk, hogy jelezze, hány termék van még raktáron.
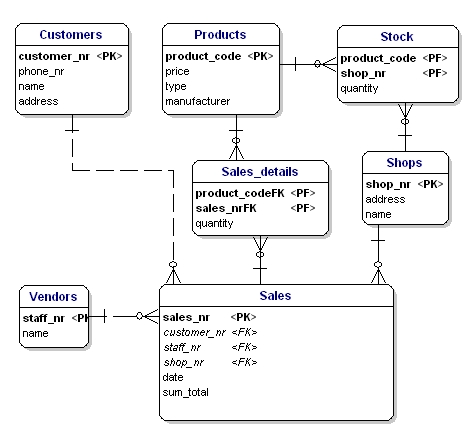
11. ábra: Elsődleges kulcsok és idegen kulcsok.
Az attribútum adattípusának meghatározása
Most itt az ideje, hogy kitaláljuk, milyen adattípusokat kell használni az attribútumokhoz. Rengeteg különböző adattípus létezik. Néhányat szabványosítottak, de sok adatbázisnak van saját adattípusa, amelyeknek mind megvan a maguk előnye. Néhány adatbázisban lehetőség van saját adattípusok definiálására arra az esetre, ha a szabványos típusok nem képesek arra, amire szükségünk van.
A szabványos adattípusok, amelyeket minden adatbázis ismer, és amelyeket a legtöbbször használnak, a következők: CHAR, VARCHAR, TEXT, FLOAT, DOUBLE és INT.
Text:
- CHAR(hossz) – szövegeket (karaktereket, számokat, írásjeleket…) tartalmaz. A CHAR jellemzője, hogy mindig fix számú pozíciót ment el. Ha CHAR(10)-et definiálunk, akkor maximum tíz pozíciót menthetünk el, de ha csak két pozíciót használunk, akkor is 10 pozíciót ment az adatbázis. A fennmaradó nyolc pozíciót szóközök töltik ki.
- VARCHAR(length) – szöveget (karaktereket, számokat, írásjeleket…) tartalmaz. A VARCHAR ugyanaz, mint a CHAR, a különbség az, hogy a VARCHAR csak annyi helyet foglal, amennyi szükséges.
- TEXT – nagy mennyiségű szöveget tartalmazhat. Az adatbázis típusától függően ez akár gigabájtokat is jelenthet.
Numbers:
- INT – pozitív vagy negatív egész számot tartalmaz. Az INT-nek számos adatbázisban vannak változatai, például TINYINT, SMALLINT, MEDIUMINT, BIGINT, INT2, INT4, INT8. Ezek a változatok csak a beléjük illeszkedő szám méretében különböznek az INT-től. A hagyományos INT 4 bájtos (INT4), és -2147483647 és +2147483646 közötti számok férnek bele, vagy ha UNSIGNED-ként definiáljuk, akkor 0 és 4294967296 között. Az INT8, vagy BIGINT még nagyobb méretű lehet, 0-tól 18446744073709551616-ig, de 8 bájtnyi lemezterületet foglal el, még akkor is, ha csak egy kis szám van benne.
- FLOAT, DOUBLE – Ugyanaz az elképzelés, mint az INT, de lebegőpontos számok tárolására is alkalmas. . Vegyük figyelembe, hogy ez nem mindig működik tökéletesen. Például a MySQL-ben ezekkel a lebegőpontos számokkal való számolás nem tökéletes, (1/3)*3 a MySQL lebegőpontos számokkal 0.999999999 lesz az eredmény, nem pedig 1.
Más típusok:
- BLOB – bináris adatok, például fájlok számára.
- INET – IP címek számára. Netmaszkokhoz is használható.
Példánkban az adattípusok a következők:
12. ábra: Adattípusokat megjelenítő adatmodell.
Normalizálás
A normalizálás rugalmassá és megbízhatóvá teszi az adatmodellt. Némi többletköltséget generál, mert általában több táblázatot kapunk, de lehetővé teszi, hogy sok mindent elvégezhessünk az adatmodellünkkel anélkül, hogy igazítanunk kellene rajta. Az adatbázis normalizálásról bővebben ebben a cikkben olvashat.
Normalizálás, az első forma
A normalizálás első formája szerint egy entitásban nem lehetnek ismétlődő oszlopcsoportok. Létrehozhattunk volna egy “értékesítés” nevű entitást, amelynek attribútumai a megvásárolt termékek mindegyikéhez tartoznak. Ez így nézne ki:

13. ábra: Nem az első normálformában.
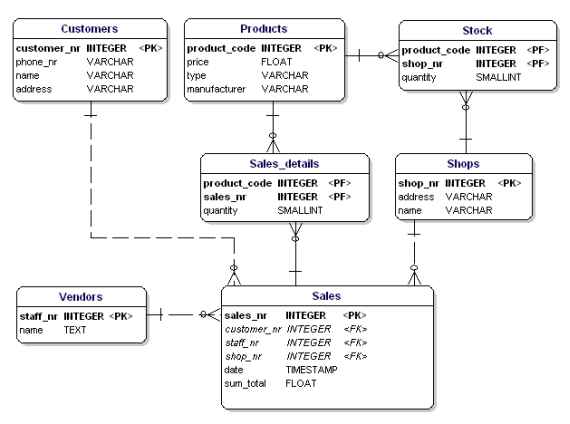
Az a baj ezzel, hogy most már csak 3 terméket lehet eladni. Ha 4 terméket kellene eladni, akkor egy második eladást kellene indítani, vagy az adatmodellt kellene módosítani a ‘product4’ attribútum hozzáadásával. Mindkét megoldás nem kívánatos. Ezekben az esetekben mindig egy új entitást kell létrehoznia, amelyet egy egy a sokhoz kapcsolaton keresztül összekapcsol a régivel.
14. ábra: Az 1. normálformának megfelelően.
Normalizáció, a második forma
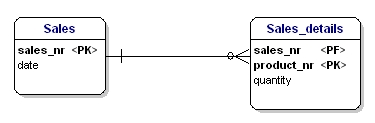
A normalizáció második formája szerint az entitás minden attribútumának teljes mértékben a teljes elsődleges kulcs függvényének kell lennie. Ez azt jelenti, hogy egy entitás minden egyes attribútuma csak a teljes elsődleges kulcson keresztül azonosítható. Tegyük fel, hogy a Sales_details entitásban a dátum:

15. ábra: Nem a 2. normál formában.
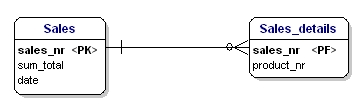
Ez az entitás nem a második normálformának megfelelő, mert ahhoz, hogy egy eladás dátumát megnézhessem, nem kell tudnom, hogy mit adtak el (productnr), csak az eladási számot kell tudnom. Ezt úgy oldottuk meg, hogy a táblákat felosztottuk az értékesítés és az értékesítés_adatok táblára:
16. ábra: A 2. normálformának megfelelően.
Most az entitások minden egyes attribútuma függ az entitás teljes PK-jától. A dátum függ az értékesítési számtól, a mennyiség pedig az értékesítési számtól és az eladott terméktől.
Normalizálás, a harmadik forma
A normalizálás harmadik formája szerint minden attribútumnak közvetlenül az elsődleges kulcstól kell függenie, és nem más attribútumoktól. Úgy tűnik, hogy ez az, amit a normalizálás második formája állít, de a második formában valójában az ellenkezőjét állítják. A normalizálás második formájában az attribútumokra a PK-n keresztül mutat rá, a normalizálás harmadik formájában minden attribútumnak a PK-tól kell függenie, és semmi mástól.

17. ábra: Nem a 3. normálformában.
Ez esetben a laza termék ára függ a rendelési számtól, a rendelési szám pedig a termékszámtól és az értékesítési számtól. Ez nem felel meg a harmadik normálformának. Ismét a táblázatok felosztása oldja meg ezt.
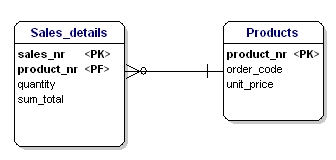
18. ábra: A 3. normálformának megfelelően.
Normalizálás, további formák
A fent említett három formánál több normalizálási forma is létezik, de ezek az átlagfelhasználót nem nagyon érdeklik. Ezek a többi formák erősen specializáltak bizonyos alkalmazásokra. Ha ragaszkodik a tervezési szabályokhoz és az ebben a cikkben említett normalizáláshoz, akkor olyan tervezést hozhat létre, amely a legtöbb alkalmazáshoz nagyszerűen működik.
Normalizált adatmodell
Ha alkalmazza a normalizálási szabályokat, akkor azt fogja tapasztalni, hogy a terméktáblában a “gyártónak” is külön táblának kell lennie:
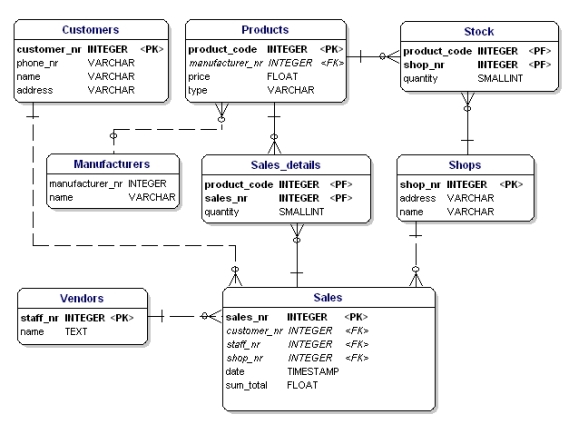
19. ábra: Adatmodell az 1., 2. és 3. normálforma szerint.