




Törött csomagok:
A nyilvános telefonhálózattal ellentétben az internet Packet Switched felépítésű. De mekkorák lehetnek ezek a csomagok?
 CC BY 2.0 image by ajmexico, inspired by
CC BY 2.0 image by ajmexico, inspired by
Ez egy régi kérdés, és az IPv4 RFC-k elég egyértelműen válaszolnak rá. Az ötlet az volt, hogy a problémát két különálló problémára osztották:
-
Melyik az a maximális csomagméret, amelyet az operációs rendszerek mindkét végén kezelni tudnak?
-
Melyik az a maximális megengedett adatcsomagméret, amelyet biztonságosan át lehet tolni a hosztok közötti fizikai kapcsolatokon?
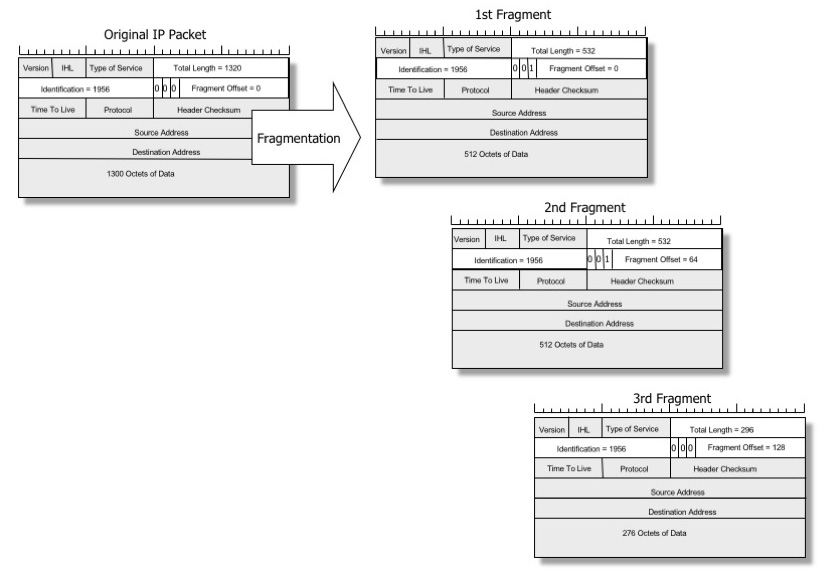
Ha egy csomag túl nagy a fizikai kapcsolathoz, egy köztes útválasztó több kisebb adatcsomagra darabolhatja, hogy beférjen. Ezt a folyamatot “továbbított” IP-fragmentálásnak nevezik, a kisebb adatcsomagokat pedig IP-fragmentumoknak.
 A képet Geoff Huston készítette, engedéllyel sokszorosítva
A képet Geoff Huston készítette, engedéllyel sokszorosítva
Az IPv4 specifikáció meghatározza a minimális követelményeket. Az RFC791-ből:
Every internet destination must be able to receive a datagramof 576 octets either in one piece or in fragments tobe reassembled. Every internet module must be able to forward a datagram of 68octets without further fragmentation. Az első érték – a megengedett újra összerakott csomagméret – általában nem okoz problémát. Az IPv4 576 bájtban határozza meg a minimumot, de a népszerű operációs rendszerek nagyon nagy csomagokkal is megbirkóznak, jellemzően 65 kB-ig.
A második már problémásabb. Minden fizikai kapcsolatnak vannak eredendő datagram méretkorlátjai, az általuk használt konkrét médiumtól függően. A Frame Relay például 46 és 4470 bájt közötti datagramok küldésére képes. Az ATM fix 53 bájtot használ, a klasszikus Ethernet 64 és 1500 bájt között képes.
A specifikáció meghatározza a minimális követelményt – minden fizikai kapcsolatnak képesnek kell lennie legalább 68 bájt méretű datagramok továbbítására. Az IPv6 esetében ezt a minimális értéket 1280 bájtra emelték (lásd RFC2460).
A fragmentálás nélkül továbbítható datagram maximális méretét viszont semmilyen specifikáció nem határozza meg, és linktípusonként változik. Ezt az értéket MTU-nak (Maximum Transmission Unit) nevezik.
Az MTU meghatározza a maximális datagram méretet egy helyi fizikai kapcsolaton. Az internet nem homogén hálózatokból jön létre, és a két állomás közötti útvonalon lehetnek rövidebb MTU értékű linkek. A két távoli hoszt között töredezettség nélkül továbbítható maximális csomagméretet Path MTU-nak nevezzük, és ez potenciálisan minden kapcsolatnál eltérő lehet.
Kerüljük a töredezettséget
Az ember azt gondolhatná, hogy nem baj, ha olyan alkalmazásokat építünk, amelyek nagyon nagy csomagokat továbbítanak, és az IP töredezettségét az útválasztókra bízzuk. Ez azonban nem jó ötlet. Az ezzel a megközelítéssel kapcsolatos problémákat először Kent és Mogul tárgyalta 1987-ben. Íme néhány kiemelés:
-
A csomag sikeres újra összerakásához az összes fragmentumot át kell adni. Egyetlen töredék sem romolhat meg vagy veszhet el menet közben. Egyszerűen nincs mód arra, hogy a másik felet értesítsük a hiányzó fragmentumokról!
-
Az utolsó fragmentum szinte soha nem lesz optimális méretű. Nagy átvitelek esetén ez azt jelenti, hogy a forgalom jelentős része nem optimális rövid datagramokból fog állni – az értékes útválasztó erőforrások pazarlása.
-
Az újbóli összerakás előtt az állomásnak részleges, töredezett datagramoknak kell a memóriában tartania. Ez lehetőséget ad a memória kimerítését célzó támadásokra.
-
A további töredékekből hiányzik a magasabb szintű fejléc. A TCP vagy UDP fejléc csak az első töredékben van jelen. Ez lehetetlenné teszi, hogy a tűzfalak olyan kritériumok alapján szűrjék a töredezett adatkapcsolatokat, mint a forrás- vagy célportok.
Az IP-fragmentációs problémák részletesebb leírása Geoff Huston alábbi cikkeiben található:
- Az IPv4 és az IPv6 csomagtöredezettségének értékelése
- Az IPv6 töredezettsége
Nem töredezik – ICMP csomag túl nagy
A kép Geoff Huston, engedélyével sokszorosítva
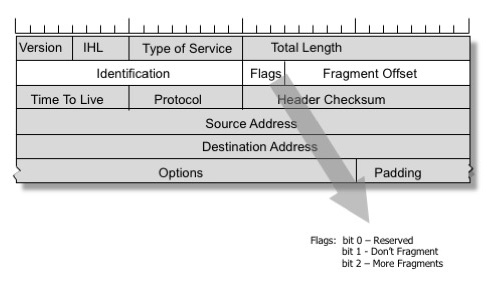
Az IPv4 protokollban már szerepelt megoldás ezekre a problémákra. A feladó beállíthatja a DF (Don’t Fragment) jelzőt az IP-fejlécben, ezzel kérve a köztes útválasztókat, hogy soha ne végezzék el a csomag fragmentálását. Ehelyett egy kisebb MTU-val rendelkező kapcsolattal rendelkező útválasztó egy ICMP üzenetet küld “visszafelé”, és tájékoztatja a feladót, hogy csökkentse az MTU-t ezen a kapcsolaton.
A TCP protokoll mindig beállítja a DF jelzőt. A hálózati verem gondosan figyeli a bejövő “Packet too big” ICMP üzeneteket, és minden kapcsolatnál nyomon követi az “path MTU” jellemzőt. Ezt a technikát “path MTU discovery”-nek nevezik, és leginkább a TCP esetében használják, bár más IP-alapú protokolloknál is alkalmazható. Az ICMP “túl nagy csomag” üzenetek kézbesítésének képessége kritikus fontosságú a TCP-verem optimális működéséhez.
Hogyan működik valójában az internet
Egy tökéletes világban az internethez csatlakozó eszközök együttműködnének és helyesen kezelnék a töredezett adatképeket és a hozzájuk tartozó ICMP-csomagokat. A valóságban azonban az IP-darabkákat és az ICMP-csomagokat nagyon gyakran kiszűrik.
Ez azért van, mert a modern internet sokkal összetettebb, mint azt 36 évvel ezelőtt gondoltuk. Ma már gyakorlatilag senki sem csatlakozik közvetlenül a nyilvános internetre.
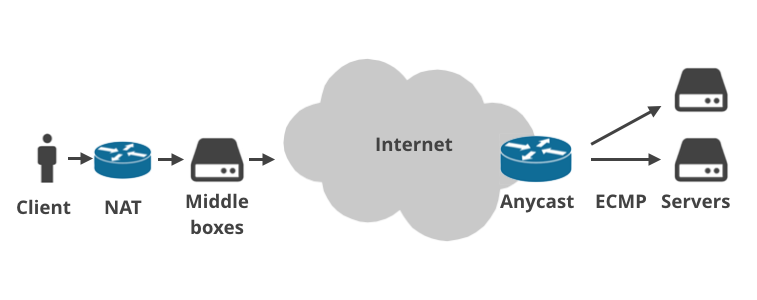
Az ügyfelek eszközei otthoni routereken keresztül csatlakoznak, amelyek NAT-ot (hálózati címfordítást) végeznek, és általában tűzfalszabályokat alkalmaznak. Egyre gyakrabban fordul elő, hogy a csomag útvonalán egynél több NAT telepítés van (pl. szolgáltatói szintű NAT). Ezután a csomagok elérik az internetszolgáltató infrastruktúráját, ahol vannak internetszolgáltatói “köztes dobozok”. Ezek mindenféle furcsa dolgot művelnek a forgalommal: korlátozzák a terveket, korlátozzák a kapcsolatokat, naplózást végeznek, eltérítik a DNS-kérelmeket, kormányzati tiltást vezetnek be weboldalakra, átlátszó gyorsítótárazást kényszerítenek ki, vagy valamilyen más varázslatos módon “optimalizálják” a forgalmat. A köztes dobozokat különösen a mobilszolgáltatók használják.
Hasonlóképpen, gyakran több réteg van egy szerver és a nyilvános internet között. A szolgáltatók néha Anycast BGP útválasztást használnak. Azaz: ugyanazt az IP-tartományt kezelik a világ több fizikai helyéről. Egy adatközponton belül viszont egyre népszerűbb az ECMP Equal Cost Multi Path használata terheléselosztásra.
A kliens és a kiszolgáló közötti minden ilyen réteg okozhat Path MTU problémát. Engedje meg, hogy ezt négy forgatókönyvvel illusztráljam.
1. Ügyfél -> Kiszolgáló DF+ / ICMP
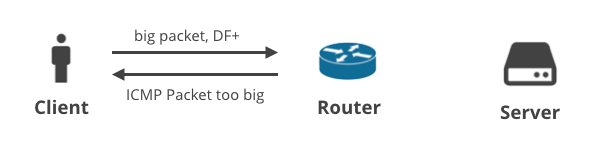
Az első forgatókönyvben az ügyfél TCP segítségével tölt fel néhány adatot a kiszolgálóra, így a DF jelző minden csomagon be van állítva. Ha az ügyfél nem tudja megjósolni a megfelelő MTU-t, egy köztes útválasztó eldobja a nagy csomagokat, és egy ICMP “Packet too big” (túl nagy csomag) értesítést küld vissza az ügyfélnek. Ezeket az ICMP-csomagokat az ügyfél rosszul konfigurált NAT-eszközei vagy az internetszolgáltatók köztes dobozai ejthetik el.
Maikel de Boer és Jeffrey Bosma 2012-es tanulmánya szerint az IPv4 és az IPv6 hosztok körülbelül 5%-a blokkolja a bejövő ICMP-csomagokat.
A tapasztalatom ezt megerősíti. Az ICMP-üzeneteket valóban gyakran dobják el vélt biztonsági előnyök miatt, de ez viszonylag könnyen javítható. Nagyobb problémát jelentenek bizonyos mobil internetszolgáltatók furcsa középdobozokkal. Ezek gyakran teljesen figyelmen kívül hagyják az ICMP-t, és nagyon agresszív kapcsolat-átírást végeznek. Az Orange Polska például nem csak a bejövő “Packet too big” ICMP-üzeneteket hagyja figyelmen kívül, hanem a kapcsolat állapotát is átírja, és az MSS-t a nem tárgyalható 1344 bájtra szorítja.
2. Ügyfél -> Szerver DF- / fragmentáció
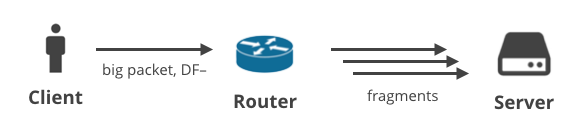
A következő forgatókönyv szerint az ügyfél a TCP-től eltérő protokollal tölt fel adatokat, amelynek a DF-jelzője törölt. Ilyen lehet például egy felhasználó, aki UDP-t használó játékot játszik, vagy hanghívást bonyolít. A nagy kimenő csomagok az útvonal egy pontján töredezetté válhatnak.
Ezt úgy tudjuk emulálni, hogy a ping-t nagy hasznos teherrel indítjuk:
$ ping -s 2048 facebook.comEz a bizonyos ping 1472 bájtnál nagyobb hasznos teherrel sikertelen lesz. Minden ennél nagyobb méret töredezetté válik, és nem lesz megfelelően kézbesítve. Több oka is lehet annak, hogy a szerverek rosszul kezelik a fragmentumokat, de az egyik népszerű probléma az ECMP terheléselosztás használata. Az ECMP hashing miatt a protokollfejlécet tartalmazó első datagram valószínűleg más szerverre kerül terheléskiegyenlítésre, mint a többi töredék, ami megakadályozza az újra összerakást.
A probléma részletesebb tárgyalását lásd:
- Az ECMP-ről szóló korábbi írásunkban.
- Hogy a Google hogyan próbálja megoldani az ECMP fragmentációs problémákat a Maglev L4 Load balancerrel.
Ezeken túlmenően a szerver és az útválasztó rossz konfigurációja is jelentős probléma. Az RFC7852 szerint a szerverek 30-55%-a dobja el a fragmentációs fejlécet tartalmazó IPv6-adatcsomagokat.
3. Kiszolgáló -> Ügyfél DF+ / ICMP
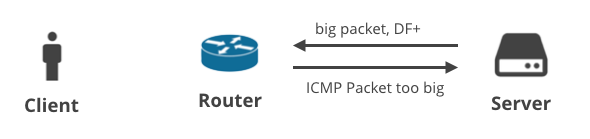
A következő forgatókönyv egy TCP-n keresztül adatokat letöltő ügyfélről szól. Ha a kiszolgáló nem tudja megjósolni a megfelelő MTU-t, akkor egy ICMP “Packet too big” üzenetet kell kapnia. Egyszerű, ugye?
Sajnos nem az, ismét az ECMP útválasztás miatt. Az ICMP üzenet nagy valószínűséggel a rossz kiszolgálónak fog érkezni – az ICMP csomag 5-tuple hash-ja nem fog megegyezni a problémás kapcsolat 5-tuple hash-jával. Erről már írtunk korábban, és kifejlesztettünk egy egyszerű userspace démont a probléma megoldására. Úgy működik, hogy a bejövő ICMP “Packet too big” értesítést az összes ECMP-kiszolgálónak továbbítja, remélve, hogy a problémás kapcsolattal rendelkező szerver látni fogja.
Az Anycast útválasztás miatt az ICMP-t ráadásul teljesen rossz adatközpontba is eljuttathatja! Az internetes útválasztás gyakran aszimmetrikus, és a legjobb útvonal egy köztes útválasztóról rossz helyre irányíthatja az ICMP csomagokat.
Az ICMP “túl nagy csomag” értesítések elmaradása a kapcsolatok leállását és időzítését eredményezheti. Ezt gyakran PMTU feketelyuknak nevezik. Ennek a pesszimista esetnek a megsegítésére a Linux egy megoldást valósít meg – MTU Probing RFC4821. Az MTU Probing megpróbálja automatikusan azonosítani a rossz MTU miatt eldobott csomagokat, és heurisztikát használ a beállításhoz. Ez a funkció egy sysctl segítségével vezérelhető:
$ echo 1 > /proc/sys/net/ipv4/tcp_mtu_probingAz MTU probing azonban nem problémamentes. Először is, hajlamos a torlódással kapcsolatos csomagvesztést MTU-problémaként tévesen kategorizálni. A hosszan futó kapcsolatok általában csökkentett MTU-val végződnek. Másodszor, a Linux nem valósítja meg az MTU Probingot az IPv6 számára.
4. Szerver -> Ügyfél DF- / fragmentáció
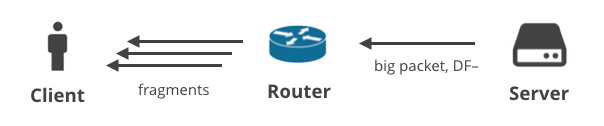
Végezetül, van olyan helyzet, amikor a kiszolgáló nagy csomagokat küld nem-TCP protokollt használva, a DF bit törlésével. Ebben a forgatókönyvben a nagy csomagok töredezetté válnak az ügyfélhez vezető úton. Ezt a helyzetet a legjobban a nagy DNS-válaszok szemléltetik. Íme két olyan DNS-kérés, amely nagy válaszokat generál, és több IP-fragmentumként jut el az ügyfélhez:
$ dig +notcp +dnssec DNSKEY org @199.19.56.1$ dig +notcp +dnssec DNSKEY org @2001:500:f::1Ezek a kérések a már említett rosszul konfigurált otthoni útválasztó, a hibás NAT, a hibás internetszolgáltatói telepítések vagy a túl szigorú tűzfalbeállítások miatt sikertelenek lehetnek.
Boer és Bosma szerint az IPv4- és az IPv6-hostok mintegy 6%-a blokkolja a bejövő fragmentált adatkapcsolatokat.
Itt van néhány link a DNS-t érintő konkrét fragmentációs problémákról:
- DNS-OARC Reply Size Test
- IPv6, nagy UDP csomagok és a DNS
Mégis működik az internet!
Mivel mindezek a dolgok elromlanak, hogyan működik még mindig az internet?
 CC BY-SA 3.0, forrás: Wikipédia
CC BY-SA 3.0, forrás: Wikipédia
Ez elsősorban az Ethernet sikerének köszönhető. A nyilvános internet linkjeinek nagy többsége Ethernet (vagy abból származtatott), és támogatja az 1500 bájtos MTU-t.
Ha vakon feltételezed az 1500-as MTU-t, meg fogsz lepődni, hogy milyen gyakran működik remekül. Az internet többnyire azért működik tovább, mert mindannyian 1500-as MTU-t használunk, és ritkán van szükség IP-fragmentálásra és ICMP-üzenetek küldésére.
Ez szokatlan beállítás esetén, amikor a linkek nem szabványos MTU-val rendelkeznek, nem működik tovább. A VPN-eknek és más hálózati alagútszoftvereknek ügyelniük kell arra, hogy a töredezettség és az ICMP-üzenetek jól működjenek.
Ez különösen az IPv6 világában látható, ahol sok felhasználó alagúton keresztül csatlakozik. Az ICMP egészséges átmenete mindkét irányban nagyon fontos, különösen mivel a fragmentáció az IPv6-ban alapvetően nem működik (két forrást is idéztünk, amelyek szerint az IPv6 hostok 10-50%-a blokkolja az IPv6 Fragment fejlécet).
Mivel az IPv6-ban a Path MTU problémák annyira gyakoriak, sok IPv6 szerver az Path MTU-t a protokoll által előírt 1280 bájtos minimumra szorítja le. Ez a megközelítés egy kis teljesítményt cserél a legjobb megbízhatóságért.
Online ICMP blackhole checker
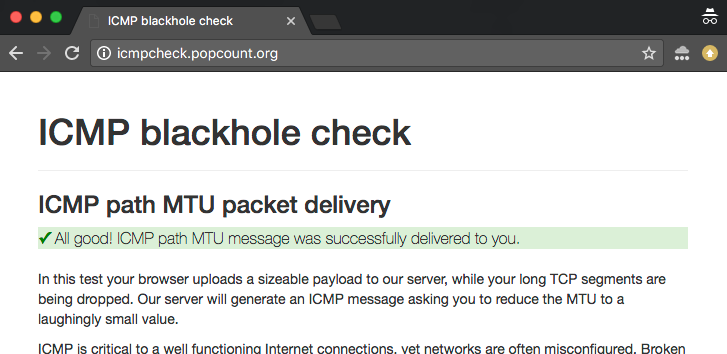
Az ilyen problémák feltárásának és hibakeresésének elősegítésére készítettünk egy online ellenőrző programot. A tesztnek két változata található:
- IPv4 verzió: http://icmpcheck.popcount.org
- IPv6 verzió: http://icmpcheckv6.popcount.org
Ezek az oldalak két tesztet indítanak:
- Az első teszt ICMP-üzeneteket küld a számítógépének, azzal a szándékkal, hogy az útvonal MTU-ját nevetségesen kicsire csökkentse.
- A második teszt töredezett adatképeket küld vissza Önnek.
Az, hogy mindkét tesztben “pass”-t kapunk, kellő biztosítékot adhat arra, hogy az internet a mi oldalunkon jól viselkedik.
A teszteket parancssorból is könnyen lefuttathatjuk, ha esetleg a szerveren szeretnénk futtatni:
perl -e "print 'packettoolongyaithuji6reeNab4XahChaeRah1diej4' x 180" > payload.bincurl -v -s http://icmpcheck.popcount.org/icmp --data @payload.bincurl -v -s http://icmpcheckv6.popcount.org/icmp --data @payload.binEzzel 905 bájtra kell csökkenteni az útvonal MTU-ját a szerverünkhöz. Ezt ellenőrizhetjük az útválasztási gyorsítótár táblázatba való betekintéssel. Linuxon ezt a következővel tehetjük meg:
ip route get `dig +short icmpcheck.popcount.org`Linuxon törölhetjük az útválasztási gyorsítótárat:
ip route flush cache to `dig +short icmpcheck.popcount.org`A második teszt azt ellenőrzi, hogy a töredékek megfelelően érkeznek-e a klienshez:
curl -v -s http://icmpcheck.popcount.org/frag -o /dev/nullcurl -v -s http://icmpcheckv6.popcount.org/frag -o /dev/nullÖsszefoglaló
Ebben a blogbejegyzésben az interneten az útvonal MTU értékek érzékelésének problémáit ismertettük. Az ICMP és a fragmentált adatkapcsolatok gyakran blokkolva vannak a kapcsolatok mindkét oldalán. Az ügyfelek rosszul konfigurált tűzfalakkal, NAT-eszközökkel találkozhatnak, vagy olyan internetszolgáltatókat használhatnak, amelyek agresszíven elfogják a kapcsolatokat. Az ügyfelek gyakran használnak VPN-eket vagy IPv6-alagutakat is, amelyek rosszul konfigurálva útvonal-MTU-problémákat okozhatnak.
A szerverek viszont egyre gyakrabban támaszkodnak az Anycast vagy ECMP módszerekre. Mindkettő, valamint az útválasztó és a tűzfal rossz konfigurációja gyakran okozza az ICMP és a fragmentált adatküldemények elhagyását.
Végezetül reméljük, hogy az online teszt hasznos volt, és nagyobb betekintést nyújt a hálózatok belső működésébe. A teszt hasznos példákat tartalmaz a tcpdump szintaxisára, amelyek hasznosak a további betekintés megszerzéséhez. Boldog hálózati hibakeresést!
Az internet 10%-át érintő töredezettségi problémák megoldása izgalmas? Mindenféle rendszermérnököket, Golang programozókat, C wranglereket és gyakornokokat veszünk fel több helyszínen! Csatlakozz hozzánk San Franciscóban, Londonban, Austinban, Champaignban és Varsóban.
-
Az IPv6-ban a “forward” töredezettség kissé másképp működik, mint az IPv4-ben. A köztes útválasztóknak tilos a csomagok fragmentálása, de a forrás ezt továbbra is megteheti. Ez gyakran zavaró – előfordulhat, hogy egy hosztot arra kérnek, hogy fragmentáljon egy olyan csomagot, amelyet korábban már továbbított. Ennek kevés értelme van az olyan statikus protokollok esetében, mint a DNS. ︎
-
Mellesleg létezik egy “minimális átviteli egység” is! Az általánosan használt Ethernet-keretezésben minden átvitt datagramnak legalább 64 bájtot kell tartalmaznia a 2. rétegben. Ez az UDP-rétegen 22 bájtot, a TCP-rétegen pedig 10 bájtot jelent. Több megvalósításban is előfordult, hogy rövidebb csomagok esetén inicializálatlan memória szivárgott ki! ︎
-
Szigorúan véve az IPv4-ben az ICMP csomag neve “Destination Unreachable, Fragmentation Needed and Don’t Fragment was Set”. De az IPv6 ICMP hibaleírását “Packet too big” (túl nagy csomag) sokkal egyértelműbbnek találom. ︎
-
A TCP stack a SYN csomagokban egy maximálisan megengedett “MSS” értéket is tartalmaz (az MSS alapvetően az IP és TCP fejlécek méretével csökkentett MTU érték). Ez lehetővé teszi a hosztok számára, hogy tudják, mekkora az MTU a linkjeiken. Megjegyzés: ez nem mondja meg, hogy mi az MTU a két állomás közötti tucatnyi internetkapcsolaton! ︎
-
Lépjünk a biztosra. A DSL- és PPPoE-kapcsolatokhoz való alkalmazkodás érdekében jobb az 1492-es MTU. ︎