




Enterprise Data Warehouse: Concetti, architettura e componenti
Tempo di lettura: 12 minuti
Nel corso della giornata prendiamo molte decisioni basandoci su esperienze precedenti. Il nostro cervello immagazzina trilioni di bit di dati su eventi passati e fa leva su questi ricordi ogni volta che dobbiamo prendere una decisione. Come le persone, le aziende generano e raccolgono tonnellate di dati sul passato. E questi dati possono essere utilizzati per prendere decisioni migliori.
Mentre il nostro cervello serve sia per elaborare che per memorizzare, le aziende hanno bisogno di più strumenti per lavorare con i dati. E uno dei più importanti è un data warehouse.
In questo articolo, discuteremo cos’è un data warehouse aziendale, i suoi tipi e funzioni, e come viene utilizzato nell’elaborazione dei dati. Definiremo come i magazzini aziendali sono diversi da quelli usuali, quali tipi di magazzini di dati esistono e come funzionano. L’obiettivo è quello di fornire informazioni sul valore di business di ogni approccio architettonico e concettuale alla costruzione di un magazzino.
Cos’è un Enterprise Data Warehouse?
Se sapete quanto è il terabyte, probabilmente sareste impressionati dal fatto che Netflix aveva circa 44 terabyte di dati nel suo magazzino nel 2016. La dimensione da sola suggerisce il motivo per cui lo chiamiamo magazzino, invece di un semplice database. Quindi cominciamo con le basi.
Un Enterprise Data Warehouse (EDW) è una forma di repository aziendale che memorizza e gestisce tutti i dati storici di un’impresa. Le informazioni di solito provengono da diversi sistemi come ERP, CRM, registrazioni fisiche e altri file piatti. Per preparare i dati per ulteriori analisi, devono essere messi in un unico deposito. In questo modo, diverse unità di business possono interrogarlo e analizzare le informazioni da più angolazioni.
Con un data warehouse, un’impresa può gestire enormi set di dati, senza amministrare più database. Tale pratica è un modo a prova di futuro di memorizzare i dati per la business intelligence (BI), che è un insieme di metodi/tecnologie di trasformazione dei dati grezzi in intuizioni utilizzabili. Con l’EDW che ne è una parte importante, il sistema è simile a un cervello umano che immagazzina informazioni, ma sotto steroidi.
Enterprise data warehouse vs. solito data warehouse: qual è la differenza?
Ogni data warehouse è un database che è sempre connesso con fonti di dati grezzi tramite strumenti di integrazione dati da un lato e interfacce analitiche dall’altro. Se è così, perché isoliamo la forma aziendale per la discussione?
Qualunque magazzino fornisce uno stoccaggio che ha meccanismi per trasformare i dati, spostarli e presentarli all’utente finale. La differenza tra un normale data warehouse e uno enterprise è nella sua diversità architettonica e funzionalità molto più ampia. A causa della struttura complessa e delle dimensioni, gli EDW sono spesso decomposti in database più piccoli, quindi gli utenti finali sono più a loro agio nell’interrogare questi piccoli database. Considerando questo, ci stiamo concentrando su un magazzino aziendale per coprire l’intero spettro di funzionalità.
Tuttavia, la dimensione di un magazzino non definisce la sua complessità tecnica, i requisiti per le capacità analitiche e di reporting, il numero di modelli di dati e i dati stessi. Quindi, per capire cosa fa di un magazzino un magazzino, immergiamoci nei suoi concetti e funzionalità di base.
Concetti e funzioni dell’Enterprise Data Warehouse
Con tutte le campane e i fischietti, nel cuore di ogni magazzino ci sono concetti e funzioni di base. Questi pilastri definiscono un magazzino come fenomeno tecnologico:
Serve come l’immagazzinamento finale. Un data warehouse aziendale è un deposito unificato per tutti i dati aziendali che si verificano nell’organizzazione.
Riflette i dati di origine. L’EDW origina i dati dai suoi spazi di archiviazione originali come Google Analytics, CRM, dispositivi IoT, ecc. Se i dati sono sparsi in più sistemi, sono ingestibili. Quindi, lo scopo di EDW è quello di fornire la somiglianza dei dati sorgente originali in un unico repository. Poiché ci sono sempre nuovi dati rilevanti generati sia all’interno che all’esterno dell’azienda, il flusso di dati richiede un’infrastruttura dedicata per gestirli prima che entrino in un magazzino.
Conserva dati strutturati. I dati memorizzati in un EDW sono sempre standardizzati e strutturati. Questo rende possibile per gli utenti finali di interrogarli tramite interfacce BI e formulare rapporti. E questo è ciò che rende un data warehouse diverso da un data lake. I laghi di dati sono utilizzati per memorizzare dati non strutturati per scopi analitici. Ma a differenza dei magazzini, i laghi di dati sono utilizzati più da ingegneri/scienziati di dati per lavorare con grandi insiemi di dati grezzi.
Dati orientati all’oggetto. L’obiettivo principale di un magazzino sono i dati di business che possono riferirsi a diversi domini. Per capire a cosa si riferiscono i dati, sono sempre strutturati intorno a un soggetto specifico chiamato modello di dati. Un esempio di un soggetto può essere una regione di vendita o le vendite totali di un dato articolo. Inoltre, i metadati vengono aggiunti per spiegare in dettaglio da dove proviene ogni pezzo di informazione.
Tempo dipendente. I dati raccolti sono di solito dati storici, perché descrivono eventi passati. Per capire quando e per quanto tempo una certa tendenza ha avuto luogo, la maggior parte dei dati memorizzati è di solito divisa in periodi di tempo.
Non volatile. Una volta inseriti in un magazzino, i dati non vengono mai cancellati da esso. I dati possono essere manipolati, modificati o aggiornati a causa di cambiamenti alla fonte, ma non sono mai destinati ad essere cancellati, almeno dagli utenti finali. Parlando di dati storici, le cancellazioni sono controproducenti ai fini analitici. Tuttavia, le revisioni generali possono avvenire una volta ogni pochi anni per sbarazzarsi dei dati irrilevanti.
Considerando i principi di base, guarderemo i tipi di implementazione dei DW.
Tipi di data warehouse
Considerando le funzioni EDW, c’è sempre un margine di discussione su come progettarlo tecnicamente. Nel caso dell’immagazzinamento e dell’elaborazione dei dati, essi sono specifici e distinti per diversi tipi di imprese. A seconda della quantità di dati, della complessità analitica, dei problemi di sicurezza e del budget, naturalmente, c’è sempre un’opzione su come impostare il sistema.
Classic data warehouse
Lo stoccaggio unificato che ha il suo hardware e software dedicato è considerato una variante classica per un EDW. Con l’archiviazione fisica, non è necessario impostare strumenti di integrazione dei dati tra più database. Invece, l’EDW può essere collegato con le fonti di dati tramite API per ottenere costantemente informazioni dalla fonte e trasformarle nel processo. Quindi, tutto il lavoro viene fatto o nell’area di staging (il luogo dove i dati vengono trasformati prima di essere caricati nel DW), o nel magazzino stesso.
Un magazzino dati classico è considerato superlativo a uno virtuale (di cui discutiamo sotto), perché non c’è un ulteriore livello di astrazione. Semplifica il lavoro degli ingegneri dei dati e rende più facile gestire il flusso dei dati dal lato della pre-elaborazione, così come il reporting vero e proprio. Gli svantaggi del magazzino classico dipendono dall’implementazione effettiva, ma per la maggior parte delle aziende questi sono:
- Infrastruttura tecnologica costosa, sia hardware che software;
- Assumere un team di ingegneri dei dati e specialisti DevOps per impostare e mantenere l’intera piattaforma dati.
Quando usare: appropriato per organizzazioni di tutte le dimensioni che vogliono elaborare i loro dati e farne uso. I magazzini classici permettono il morphing in diversi stili architettonici della piattaforma di dati, così come lo scaling up e down di proposito.
Virtual data warehouse
Un data warehouse virtuale è un tipo di EDW usato come alternativa a un magazzino classico. Essenzialmente, si tratta di più database collegati virtualmente, in modo che possano essere interrogati come un unico sistema.
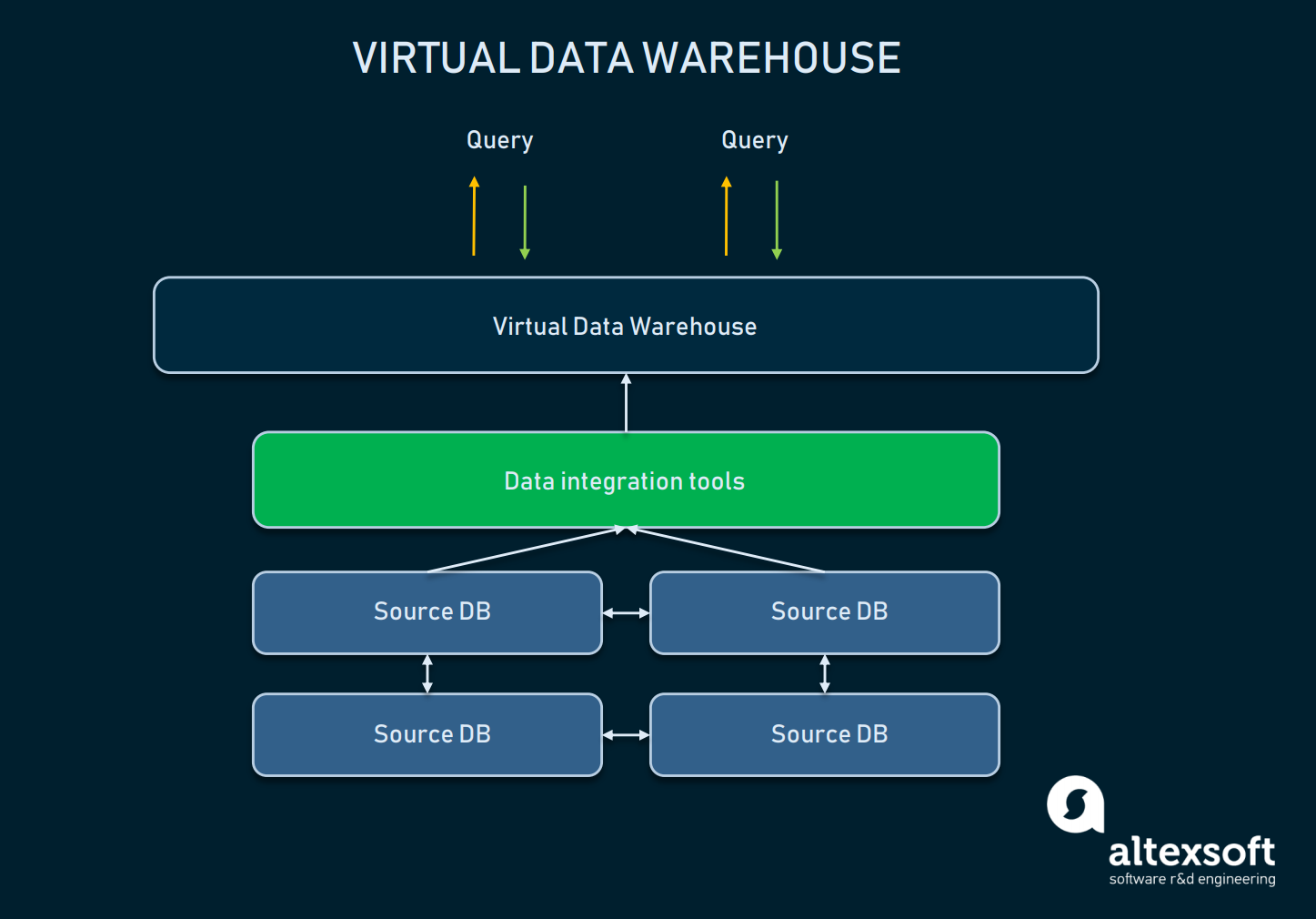
Uno schema di relazioni tra l’astrazione del DW virtuale e i database di origine
Un tale approccio permette alle organizzazioni di mantenere la semplicità: I dati possono rimanere nelle loro fonti, ma possono comunque essere estratti con l’aiuto di strumenti analitici. I magazzini virtuali possono essere utilizzati se non si vuole incasinare tutta l’infrastruttura sottostante, o i dati che si hanno sono facilmente gestibili così come sono. Tuttavia, un tale approccio ha molti svantaggi:
- I database multipli richiederanno una costante manutenzione e costi di software e hardware.
- I dati memorizzati in un DW virtuale richiedono ancora un software di trasformazione per renderli digeribili per gli utenti finali e gli strumenti di reporting.
- Le query di dati complessi possono richiedere troppo tempo, poiché i dati richiesti possono essere collocati in due database separati.
Quando usare: adatto alle aziende che hanno dati grezzi in una forma standardizzata che non richiede analisi complesse. Si adatta anche alle organizzazioni che non usano la BI sistematicamente, o che vogliono iniziare con essa.
Cloud Data Warehouse
Da un decennio, le tecnologie cloud/cloudless sono diventate uno standard per impostare le tecnologie a livello di organizzazione. Troverete innumerevoli fornitori sul mercato che offrono warehousing-as-a-service. Per citarne alcuni:
- Amazon Redshift/pagina dei prezzi
- IBM Db2/pagina dei prezzi
- Google BigQuery/pagina dei prezzi
- Snowflake/pagina dei prezzi
- Microsoft SQL Data Warehouse/pagina dei prezzi
Tutti i fornitori citati offrono un warehousing completamente gestito, warehousing scalabile come parte dei loro strumenti di BI, o si concentrano su EDW come un servizio autonomo, come fa Snowflake. In questo caso, l’architettura del cloud warehouse ha gli stessi vantaggi di qualsiasi altro servizio cloud. La sua infrastruttura è mantenuta per voi, il che significa che non avete bisogno di impostare i vostri server, database e strumenti per gestirla. Il prezzo per tale servizio dipenderà dalla quantità di memoria richiesta e dalla quantità di capacità di calcolo per l’interrogazione.
L’unico aspetto di cui potreste essere preoccupati in termini di una piattaforma di cloud warehouse è la sicurezza dei dati. I vostri dati aziendali sono una cosa sensibile. Quindi, volete controllare se il fornitore che avete scelto può essere affidabile per evitare violazioni. Questo non significa necessariamente che un magazzino on-premise sia più sicuro, ma in questo caso, la sicurezza dei tuoi dati è nelle tue mani.
Quando usare: Le piattaforme cloud sono un’ottima scelta per le organizzazioni di qualsiasi dimensione. Se avete bisogno di tutto, compresa l’integrazione dei dati gestita, la manutenzione del DW e il supporto della BI.
Architettura del Data Warehouse
Mentre ci sono molti approcci architettonici che estendono le capacità del magazzino in un modo o nell’altro, ci concentreremo su quelli più essenziali. Senza entrare troppo nei dettagli tecnici, l’intera pipeline di dati può essere divisa in tre strati:
- Strato dei dati grezzi (fonti di dati)
- Magazzino e il suo ecosistema
- Interfaccia utente (strumenti analitici)
Gli strumenti che riguardano l’estrazione, trasformazione e caricamento dei dati in un magazzino sono una categoria separata di strumenti conosciuti come ETL. Inoltre, sotto l’ombrello ETL, gli strumenti di integrazione dei dati eseguono manipolazioni con i dati prima che siano messi in un magazzino. Questi strumenti operano tra un livello di dati grezzi e un magazzino.
Quando i dati vengono caricati in un magazzino, possono anche essere trasformati. Quindi, il magazzino richiederà alcune funzionalità per la pulizia/standardizzazione/dimensionalizzazione. Questi e altri fattori determineranno la complessità dell’architettura. Guarderemo l’architettura EDW dal punto di vista delle crescenti necessità organizzative.
Architettura one-tier
Dato che l’integrazione dei dati è ben configurata, possiamo scegliere il nostro data warehouse. Nella maggior parte dei casi, un data warehouse è un database relazionale con moduli per permettere dati multidimensionali, o uno che può separare alcune informazioni specifiche del dominio per un accesso più facile. Nella sua forma più primitiva, il warehousing può avere solo un’architettura one-tier.
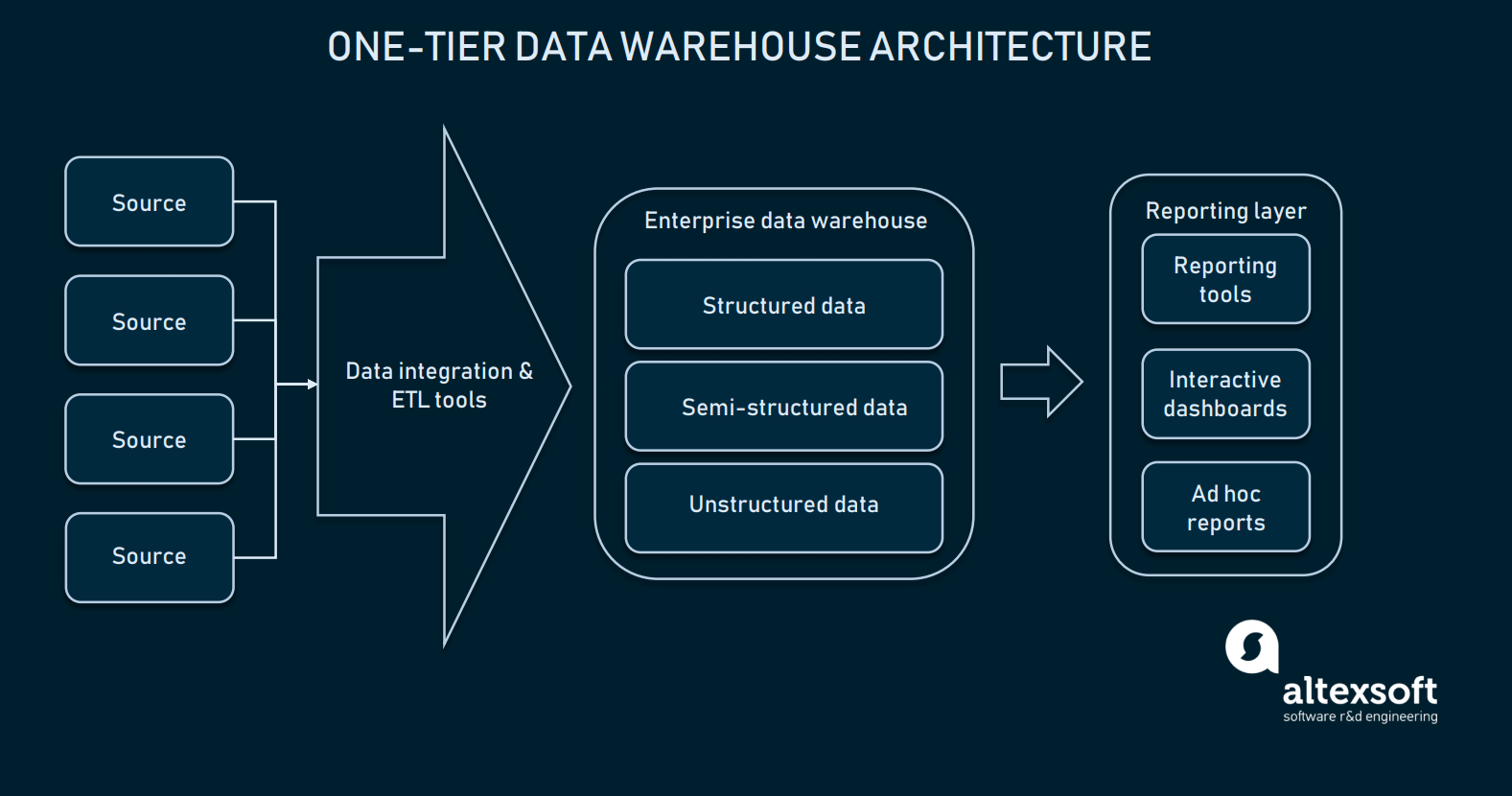
Il livello di reporting è collegato direttamente con l’intero database di EDW
L’architettura one-tier per EDW significa che si ha un database direttamente collegato con le interfacce analitiche dove l’utente finale può fare query. Impostare la connessione diretta tra un EDW e gli strumenti analitici porta diverse sfide:
- Tradizionalmente, si può considerare il proprio storage un magazzino a partire da 100GB di dati. Lavorare direttamente con esso può risultare in risultati di query disordinati, così come una bassa velocità di elaborazione.
- Interrogare i dati direttamente dal DW può richiedere un input preciso, in modo che il sistema sia in grado di filtrare i dati non necessari. Il che rende un po’ difficile avere a che fare con gli strumenti di presentazione.
- Esistono limitate flessibilità/capacità analitiche.
Inoltre, l’architettura one-tier pone alcuni limiti alla complessità del reporting. Tale approccio è raramente usato per piattaforme di dati su larga scala, a causa della sua lentezza e imprevedibilità. Per eseguire query avanzate sui dati, un magazzino può essere esteso con istanze di basso livello che rendono l’accesso ai dati più facile.
Architettura a due livelli (livello data mart)
Nell’architettura a due livelli, un livello data mart viene aggiunto tra l’interfaccia utente e EDW. Un data mart è un repository di basso livello che contiene informazioni specifiche del dominio. In parole povere, è un altro database di dimensioni ridotte che estende EDW con informazioni dedicate per i vostri dipartimenti di vendita/operativi, marketing, ecc.
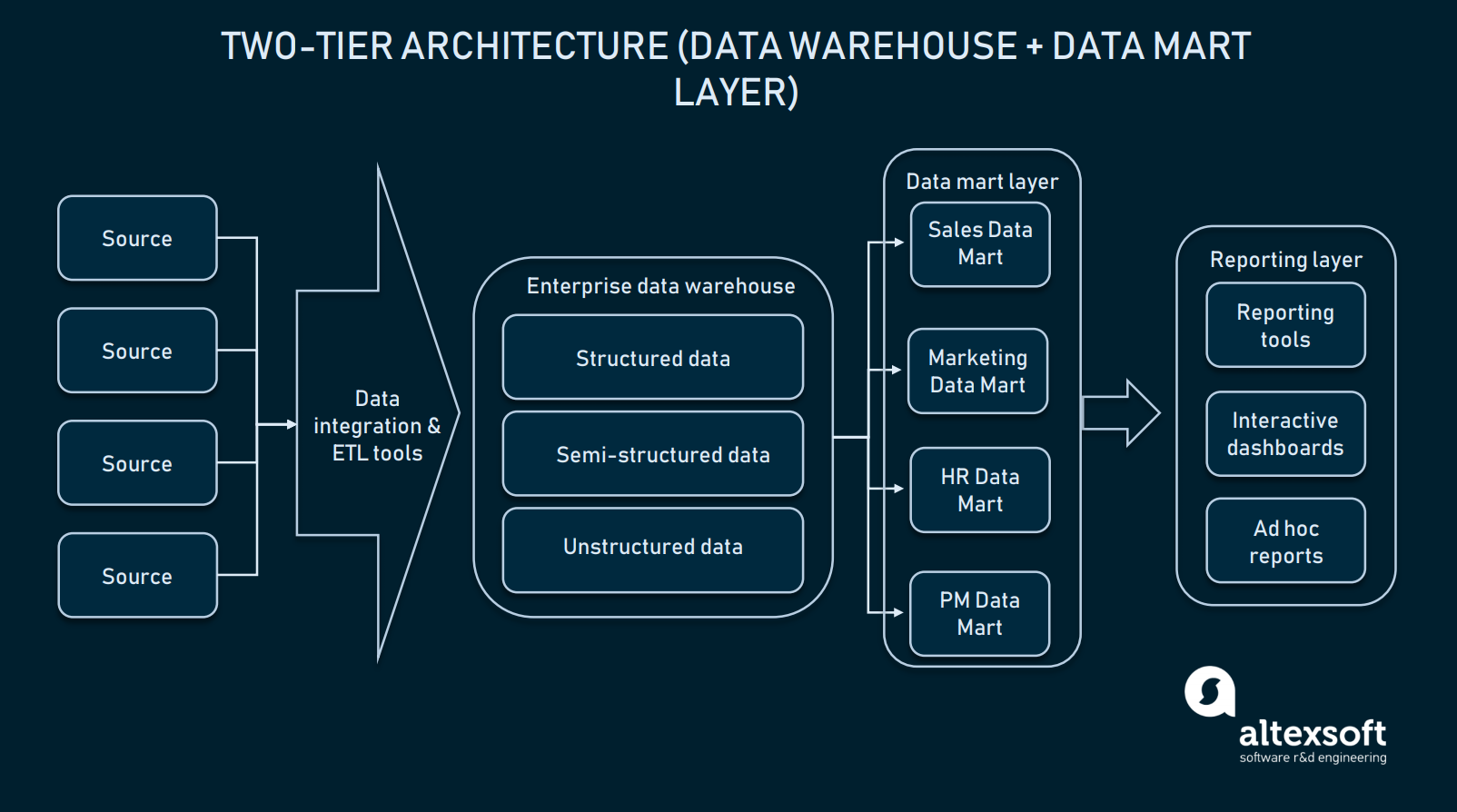
Nell’architettura a due livelli, un EDW è esteso dai data mart per fornire dati specifici del dominio
Creare un livello data mart richiederà risorse aggiuntive per stabilire l’hardware e integrare quei database con il resto della piattaforma dati. Ma un tale approccio risolve il problema dell’interrogazione: Ogni dipartimento accederà ai dati richiesti più facilmente perché un dato mart conterrà solo informazioni specifiche del dominio. Inoltre, i data mart limiteranno l’accesso ai dati per gli utenti finali, rendendo EDW più sicuro.
Architettura a tre livelli (Elaborazione analitica online)
In cima al livello dei data mart, le aziende usano anche cubi di elaborazione analitica online (OLAP). Un cubo OLAP è un tipo specifico di database che rappresenta i dati da più dimensioni. Mentre i database relazionali rappresentano i dati in due sole dimensioni (si pensi a Excel o a Google Sheets), l’OLAP permette di compilare i dati in più dimensioni e di muoversi tra le dimensioni.
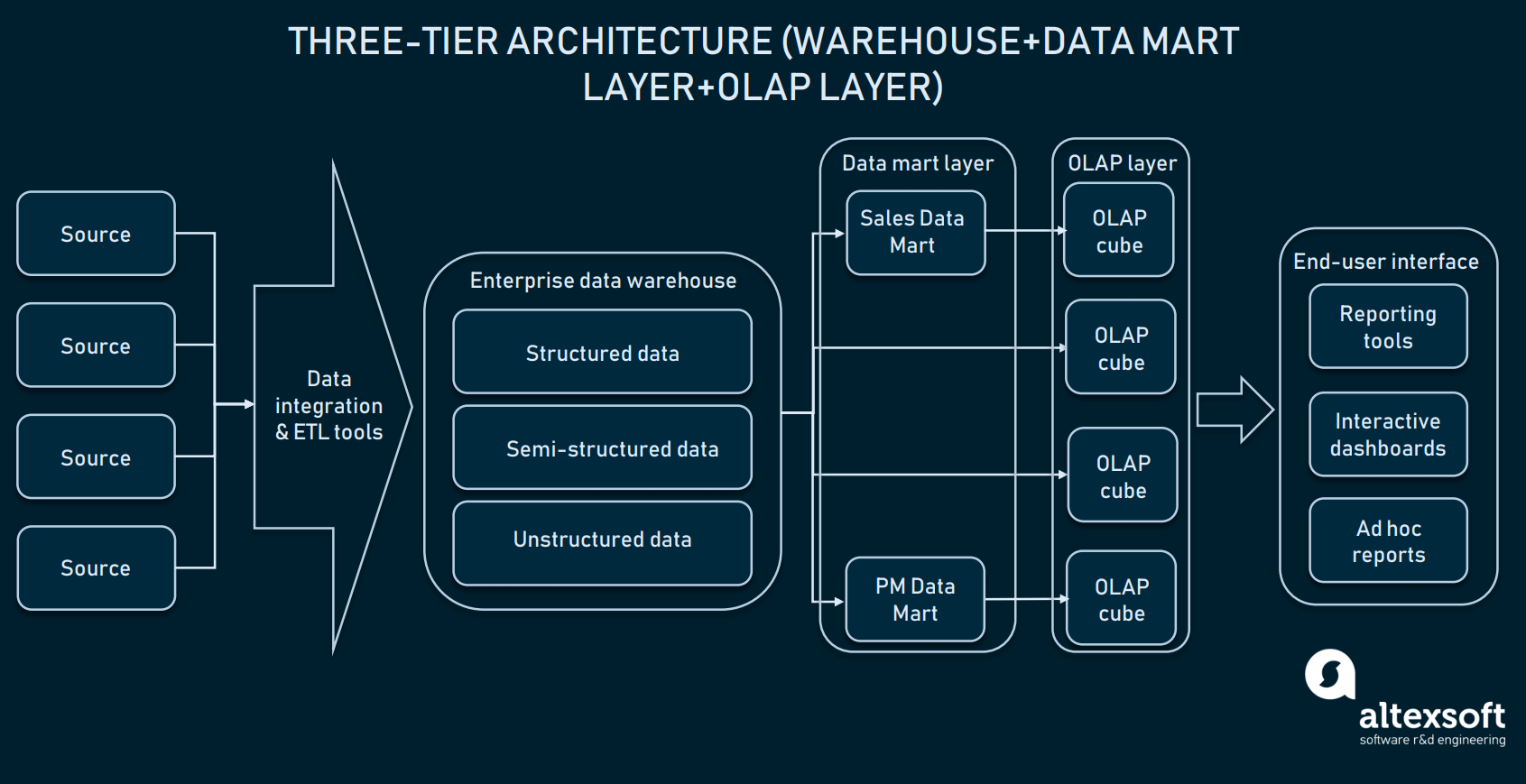
Lo strato dei cubi OLAP può ricavare informazioni da mart distribuiti o direttamente da EDW
È piuttosto difficile da spiegare a parole, quindi guardiamo questo pratico esempio di come può essere un cubo.
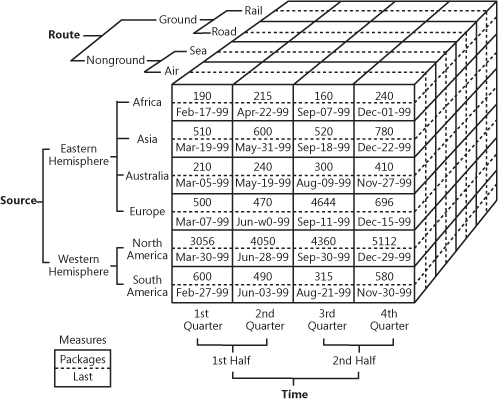
CuboOLAP che dimostra dati di vendita multidimensionali
Fonte: oreilly.com
Così, come potete vedere, un cubo aggiunge dimensioni ai dati. Si può pensare ad esso come a più tabelle Excel combinate tra loro. La parte anteriore del cubo è la solita tabella bidimensionale, dove la regione (Africa, Asia, ecc.) è specificata verticalmente, mentre i numeri di vendita e le date sono scritti orizzontalmente. La magia inizia quando guardiamo la sfaccettatura superiore del cubo, dove le vendite sono segmentate per rotte e la parte inferiore specifica il periodo di tempo. Questo è noto come dati multidimensionali.
Il valore commerciale dell’OLAP è che permette agli utenti di affettare e tagliare i dati per compilare rapporti dettagliati. Finché i cubi sono ottimizzati per lavorare con i magazzini, possono essere usati sia direttamente con un EDW per dare accesso a tutti i dati aziendali o con ogni data mart in modo specifico. In termini di implementazione, quasi tutti i fornitori di magazzini offrono OLAP come servizio. Come esempio, controllate la documentazione di Microsoft sulla loro offerta OLAP.
Su questo punto, abbiamo discusso un design di alto livello di un EDW applicato alle esigenze organizzative. Ora ci addentreremo nei componenti tecnici che un magazzino può includere.
Data Warehouse vs Data Lake vs Data Mart
Parlando dell’architettura di immagazzinamento dati, dobbiamo menzionare opzioni come l’uso di un data mart o un data lake invece di un magazzino. Spesso confusi, elaboreremo le definizioni.
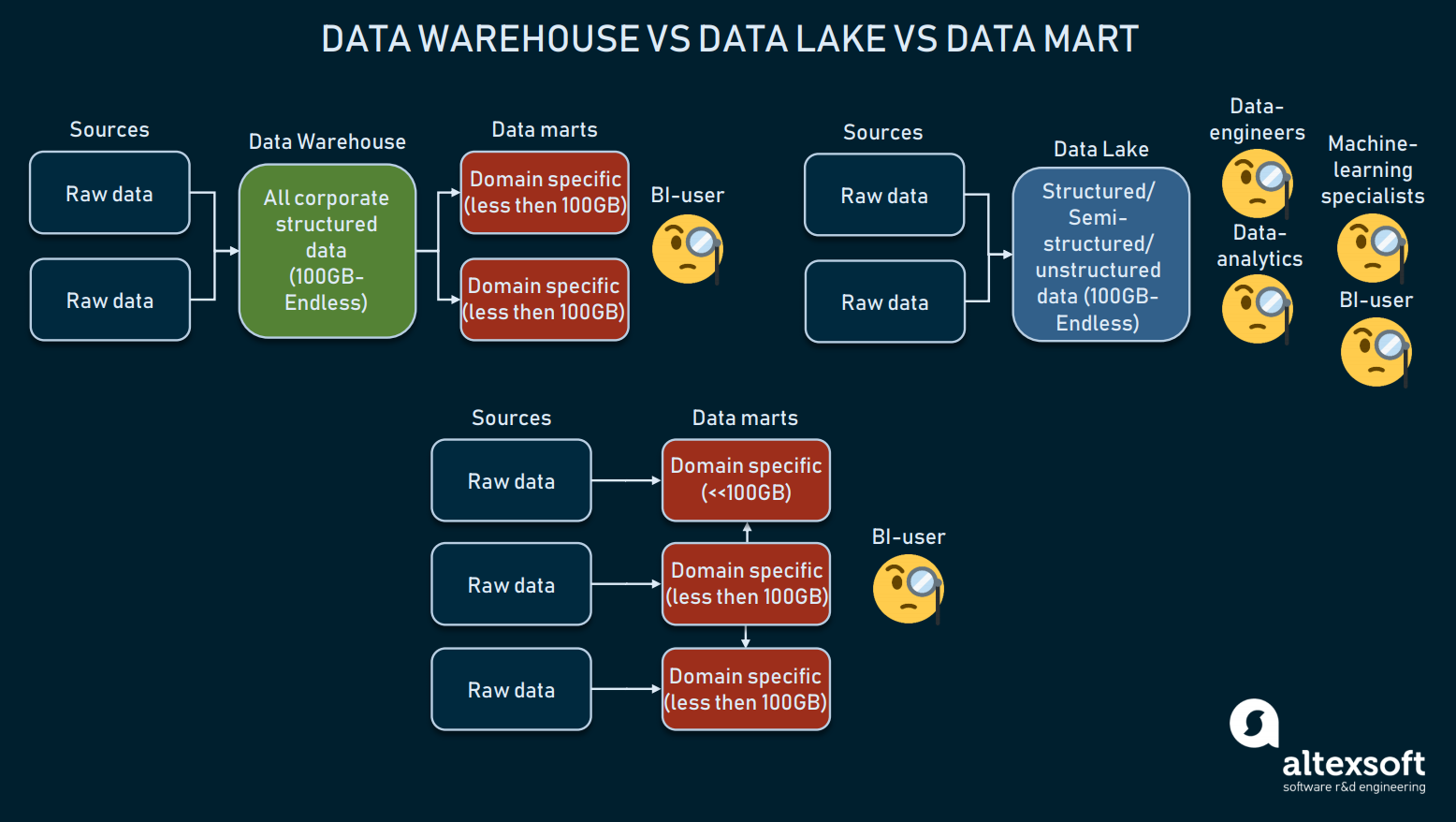
Il confronto di tre forme di archiviazione dei dati
I magazzini di dati sono destinati a memorizzare dati strutturati, in modo che gli strumenti di interrogazione e gli utenti finali possano ottenere risultati completi. I magazzini, usati soprattutto per la BI, di solito variano in dimensioni tra i 100GB e l’infinito.
I laghi di dati, invece, sono usati per memorizzare principalmente dati grezzi o misti. Questi sono spesso utilizzati per l’apprendimento automatico, i big data o il data mining. Negli ultimi due anni, i laghi di dati sono stati utilizzati per la BI: i dati grezzi vengono caricati in un lago e trasformati, il che è un’alternativa al processo ETL. Mentre questo approccio ha i suoi pro e i suoi contro, i laghi di dati possono essere troppo disordinati per raggiungere i dati strutturati.
Allora abbiamo i data mart, che possono anche essere usati come alternativa al DW. Tali modelli (come quello di Kimball) presuppongono l’utilizzo di più data mart per distribuire le informazioni in base ai domini e collegarsi tra loro. Ma, a causa delle loro piccole dimensioni (di solito meno di 100GB), i data mart difficilmente possono essere utilizzati dalle imprese. Più spesso, i data mart sono usati per segmentare un grande DW in altri più operativi.
Componenti dell’Enterprise Data Warehouse
Ci sono molti strumenti usati per impostare una piattaforma di warehousing. Abbiamo già menzionato la maggior parte di essi, incluso il magazzino stesso. Quindi, vediamo a volo d’uccello lo scopo di ogni componente e le sue funzioni.
Fonti. Questo è semplice, le basi di dati dove i dati grezzi sono immagazzinati.
Extract, Transform, Load (ETL) o Extract, Load, Transform (ELT) layer. Questi sono gli strumenti che eseguono la connessione effettiva con i dati di origine, la loro estrazione e il caricamento nel luogo in cui saranno trasformati. La trasformazione unifica il formato dei dati. Gli approcci ETL e ELT differiscono in quanto in ETL la trasformazione viene fatta prima di EDW, in una zona di staging. ELT è un approccio più moderno che gestisce tutta la trasformazione in un magazzino.
Staging area. Nel caso dell’ETL, l’area di staging è il luogo in cui i dati vengono caricati prima di EDW. Qui, saranno puliti e trasformati in un dato modello di dati. L’area di staging può anche includere strumenti per la gestione della qualità dei dati.
Base dati EDW. I dati vengono infine caricati nello spazio di archiviazione. In ELT, potrebbe essere necessaria ancora qualche trasformazione qui. Ma, in quella fase, tutti i cambiamenti generali saranno applicati, quindi i dati saranno caricati nel suo modello finale. Come abbiamo detto, i magazzini di dati sono più spesso database relazionali. Il DW includerà anche un sistema di gestione del database e un’archiviazione aggiuntiva per i metadati.
Meta-dati. In parole povere, i metadati sono dati sui dati. Sono le spiegazioni che danno suggerimenti agli utenti/amministratori su quale soggetto/dominio questa informazione si riferisce. Questi dati possono essere meta tecnici (per esempio la fonte iniziale), o meta commerciali (per esempio la regione di vendita). Tutti i meta sono immagazzinati in un modulo separato di EDW e sono gestiti da un metadata manager.
Strato di reporting. Questi sono strumenti che danno agli utenti finali l’accesso ai dati. Chiamato anche interfaccia BI, questo strato servirà come un cruscotto per visualizzare i dati, formare rapporti ed estrarre pezzi separati di informazioni.
Pensiero finale
Comprendere la catena di strumenti che passa i dati può aiutarti a capire cosa si adatta effettivamente ai requisiti della tua piattaforma di dati. Pianificare la creazione di un magazzino può richiedere anni di pianificazione e test, a causa della sua portata nella forma più elementare.
Come proprietario di un’azienda, potresti essere confuso dal numero di opzioni e tecnologie utilizzate, quindi è fondamentale consultare gli esperti nel campo del warehousing, ETL e BI. Mentre gli esperti possono aiutarvi con l’aspetto tecnico, per definire lo scopo del business, parlate con quelli che useranno i dati effettivi nel loro lavoro.
.