




データベース設計入門
属性の特定
エンティティごとに保存したいデータ要素のことを「属性」と呼びます。 顧客については、顧客番号、名前、住所がわかる。 お店については、地番、名前、住所がわかる。 売上は、いつ、どの店で、どんな商品が売れたか、その合計がわかる。 売り手については、スタッフ番号、名前、住所がわかっている。 正確には何が含まれるかはまだ重要ではなく、まだ何を保存したいかということだけです。
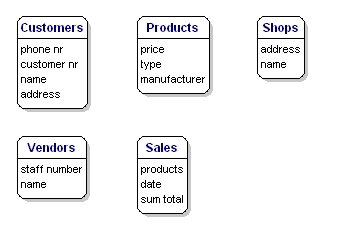
図6:属性を持つエンティティ。
派生データ
派生データとは、すでに保存してある他のデータから派生したデータのことです。 この場合、「合計」は派生データの典型的なケースです。 何が売れたか、各商品の価格はいくらかを正確に知っているので、売上の合計がいくらかを常に計算することができます。 だから、本当は合計を保存する必要はないのです。
では、なぜここに保存されているのでしょうか。 まあ、それは販売であり、製品の価格は時間の経過とともに変化する可能性があるからです。 ある製品の価格が今日は 10 ユーロで、来月は 8 ユーロになる可能性があります。管理者は販売時の価格を知る必要があり、これを行う最も簡単な方法は、ここに保存することです。 もっとエレガントな方法はたくさんありますが、奥が深すぎて今回は割愛します。
エンティティとリレーションシップを表示する。 エンティティ関係図 (ERD)
エンティティ関係図 (ERD) は、データベースの概要をグラフィカルに表示します。 ER ダイアグラムにはいくつかのスタイルとタイプがあります。 よく使われる表記法は、実体を長方形で表し、実体間の関係を実体間の線で表す「クローフィート」表記法である。 線の端にある符号は関係の種類を示す。 他方が存在するために必須である関係の側は、線上にダッシュで示される。 必須でないエンティティは、丸で示される。 “Many “は’crowfeet’を通して示される。関係線は3つの線に分かれる。
この記事では、データベースの設計と提示にDeZign for Databasesを利用します。
図7:1対1の必須の関係は次のように表される。
1対Nの必須の関係:
図8:必須の1対多の関係。
M:Nの関係は:
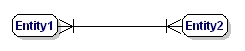
図9:必須の多対多の関係。
私たちの例のモデルは次のようになります:
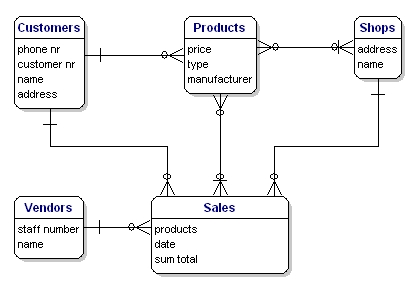
図10:関係付きのモデルです。
キーの割り当て
主キー
主キー(PK)は、エンティティを一意に識別する1つまたは複数のデータ属性です。 2つ以上の属性からなるキーは複合キーと呼ばれます。 主キーのすべての属性は、すべてのレコードに値を持つ必要があり(空白にすることはできません)、これらの属性内の値の組み合わせは、テーブル内で一意でなければなりません。 顧客はすべて顧客番号を持っており、製品はすべて一意の製品番号を持っており、売上は売上番号を持っています。 これらのデータはそれぞれ一意であり、各レコードは値を含むので、これらの属性は主キーになりえます。
リンク・エンティティは通常、リンク先のエンティティの主キー属性を参照します。 リンク エンティティの主キーは、通常、これらの参照属性のコレクションです。 例えばSales_detailsエンティティでは、SalesとProductsエンティティのPKの組み合わせをSales_detailsのPKとして使用することができる。 このようにして、同じ製品(タイプ)は同じ販売で一度だけ使用できることを強制します。
ERDでは、主キー属性は属性名の後ろに’PK’というテキストで表示されます。 この例では、エンティティ「shop」だけがPKの明らかな候補を持っていないので、そのエンティティに新しい属性shopnrを導入します。
外部キー
あるエンティティにおける外部キー(FK)は、他のエンティティの主キーへの参照である。 ERDでは、その属性は名前の後ろに’FK’と表示される。 エンティティの外部キーは、主キーの一部になることもでき、その場合、属性は名前の後ろに’PF’と表示される。 これは通常、リンクエンティティがそうである。なぜなら、通常、2つのインスタンスを一緒に1回だけリンクするからである(1回の販売では、1つの製品タイプだけが1回販売される)。
すべてのリンクエンティティ、PK、FK を ERD に配置すると、以下のようなモデルが得られる。 なお、「販売」については、リンクテーブルに「販売した商品」が含まれるようになったので、「商品」という属性は不要になった。 リンクテーブルには、もうひとつ ‘quantity’ というフィールドが追加されており、これは販売した製品の数を表します。 また、在庫テーブルにも数量フィールドが追加され、店舗にまだ何個の商品があるかを示すようになりました。
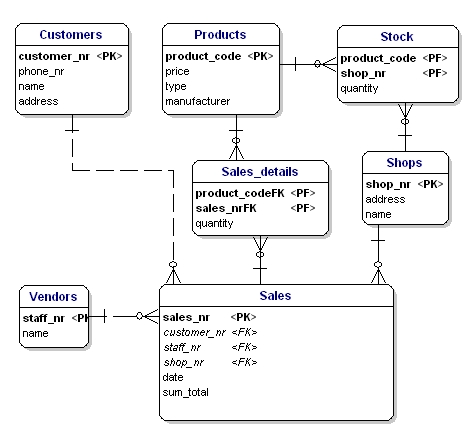
図11:主キーと外部キー。
属性のデータ型の定義
さて、次はどのデータ型を属性に使用する必要があるかを考える番です。 多くの異なるデータ型があります。 いくつかは標準化されていますが、多くのデータベースには独自のデータ型があり、それぞれに利点があります。 データベースによっては、標準のデータ型では対応できない場合に備えて、独自のデータ型を定義することができます。
すべてのデータベースが知っており、最もよく使用される標準データ型は次のとおりです。 CHAR、VARCHAR、TEXT、FLOAT、DOUBLE、およびINTです。
テキスト:
- CHAR(length) – テキスト(文字、数字、句読点…)が含まれます。 CHARは、常に一定量の位置を保存するという特徴があります。 CHAR(10)を定義すると、最大10ポジションまで保存できますが、もし2ポジションしか使わなかったとしても、データベースは10ポジションを保存することになります。 残りの8つのポジションは、スペースで埋められます。
- VARCHAR(length) – テキスト(文字、数字、句読点…)を含みます。 VARCHARはCHARと同じですが、違いはVARCHARは必要なだけのスペースを取ることです。
- TEXT – 大量のテキストを含むことができます。 データベースの種類によっては、これがギガバイトになることもあります。
Numbers:
- INT – 正または負の整数を格納します。 多くのデータベースには、TINYINT、SMALLINT、MEDIUMINT、BIGINT、INT2、INT4、INT8といったINTのバリエーションがある。 これらのバリエーションは、INTに収まる数値の大きさだけがINTと異なっています。 通常のINTは4バイト(INT4)で、-2147483647から+2147483646、またはUNSIGNEDとして定義すれば0から4294967296までの数字に対応します。 INT8(BIGINT)は、0から18446744073709551616とさらに大きなサイズになりますが、小さな数字が入っているだけでも、最大8バイトのディスクスペースを必要とします。
- FLOAT、DOUBLE – INTと同じ考え方だが、浮動小数点数も格納できる。 . これは常に完璧に機能するわけではないことに注意してください。 たとえば MySQL では、これらの浮動小数点数で計算すると、(1/3)*3 は MySQL の浮動小数点数では 1 ではなく 0.9999999 になります。
その他のタイプ:
- BLOB – ファイルなどのバイナリデータ。 ネットマスクにも使用可能。
この例では、データ型は次のとおりです。
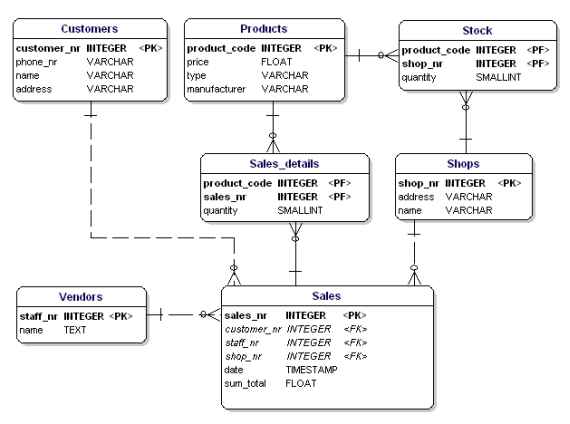
図12:データ型を表示したデータモデル。
正規化
正規化はデータモデルを柔軟かつ信頼性の高いものにする。 通常より多くのテーブルを取得するため、多少のオーバーヘッドが発生しますが、データモデルを調整することなく多くのことを実行できるようになります。
正規化、最初の形式
正規化の最初の形式は、エンティティ内に列のグループを繰り返してはならないことを述べています。 購入された各製品の属性を持つエンティティ’sales’を作成することができました。 これは次のようになります。

図13:第1正規形でない。
これの何がいけないかというと、今は3つの商品しか販売できないことです。 4つの製品を販売する必要がある場合は、2番目の販売を開始するか、’product4’属性を追加することによって、データモデルを調整する必要があります。 どちらも望ましくない解決方法です。 このような場合は、常に新しいエンティティを作成し、一対多のリレーションシップで古いエンティティにリンクする必要があります。
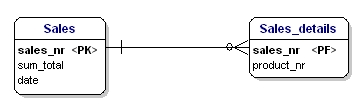
図14:第1正規形にしたがって。
正規化、第2形態
正規化の第2形態は、エンティティのすべての属性が全体の主キーに完全に依存するようにすることを述べています。 これは、エンティティの各属性は主キー全体を通してのみ識別できることを意味します。 Sales_detailsエンティティに日付があったとします:

図15:第2正規形ではありません。
このエンティティは第2正規形に従っていません。なぜなら、販売の日付を調べられるようにするには、何が販売されたか(productnr)を知る必要がなく、知る必要があるのは販売番号だけだからです。 これは、テーブルをsalesとSales_detailsに分割することで解決した:
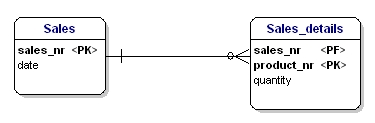
図16:第2正規形にしたがって。
ここで、実体の各属性は、実体のPK全体に依存している。 日付は販売番号に依存し、数量は販売番号と販売された製品に依存する。
正規化、第3の形式
正規化の第3の形式は、すべての属性が主キーに直接依存する必要があり、他の属性には依存しないことを述べています。 これは、正規化の第 2 形式で述べていることのようですが、第 2 形式では実際には反対のことが述べられています。 第2正規形ではPKを通して属性を指摘しますが、第3正規形ではすべての属性はPKに依存する必要があり、それ以外の属性は必要ありません。

図17:第3正規形にはなっていない。
この場合、緩い商品の価格は注文番号に依存し、注文番号は商品番号と販売番号に依存する。 これは第3の形式の正規化に従っていない。 ここでも、テーブルを分割することで解決します。
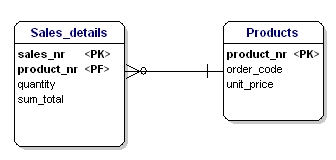
図18:第3正規形に従っている。
正規化、さらなる形
上記の3つの形以外にも正規化の形はありますが、それらは一般のユーザーにとってはあまり興味のないものでしょう。 これらの他のフォームは、特定の用途に高度に特化したものである。 この記事で述べたデザイン・ルールと正規化にこだわれば、ほとんどのアプリケーションで素晴らしい働きをするデザインを作ることができるでしょう。
正規化データ モデル
正規化ルールを適用すると、製品テーブルの「メーカー」も別のテーブルであるべきであることがわかります。
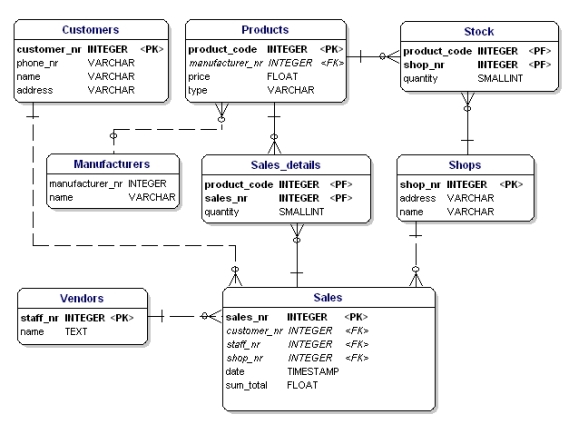
図19:第1、第2、第3正規形に従ったデータモデル。