




Enterprise Data Warehouse: Concepts, Architecture, and Components
Czas czytania: 12 minut
Przez cały dzień podejmujemy wiele decyzji, opierając się na wcześniejszych doświadczeniach. Nasze mózgi przechowują biliony bitów danych o przeszłych wydarzeniach i wykorzystują te wspomnienia za każdym razem, gdy stajemy przed koniecznością podjęcia decyzji. Podobnie jak ludzie, firmy generują i gromadzą tony danych o przeszłości. Dane te mogą być wykorzystywane do podejmowania lepszych decyzji.
Podczas gdy nasz mózg służy zarówno do przetwarzania, jak i przechowywania danych, firmy potrzebują wielu narzędzi do pracy z danymi. Jednym z najważniejszych jest hurtownia danych.
W tym artykule omówimy, czym jest hurtownia danych dla przedsiębiorstw, jakie są jej rodzaje i funkcje oraz jak jest wykorzystywana w przetwarzaniu danych. Zdefiniujemy, czym różnią się hurtownie korporacyjne od zwykłych, jakie istnieją rodzaje hurtowni danych i jak one działają. Skupimy się na dostarczeniu informacji o wartości biznesowej każdego podejścia architektonicznego i koncepcyjnego do budowy hurtowni.
Co to jest hurtownia danych klasy korporacyjnej?
Jeśli wiesz, ile to jest terabajt, prawdopodobnie byłbyś pod wrażeniem faktu, że Netflix miał około 44 terabajtów danych w swojej hurtowni w 2016 roku. Już sam ten rozmiar podpowiada, dlaczego nazywamy go hurtownią, a nie po prostu bazą danych. Zacznijmy więc od podstaw.
Eksploatacyjna hurtownia danych (EDW) jest formą korporacyjnego repozytorium, które przechowuje i zarządza wszystkimi historycznymi danymi biznesowymi przedsiębiorstwa. Informacje te zazwyczaj pochodzą z różnych systemów, takich jak ERP, CRM, zapisy fizyczne i inne pliki płaskie. Aby przygotować dane do dalszej analizy, muszą być one umieszczone w jednym magazynie. W ten sposób różne jednostki biznesowe mogą je odpytywać i analizować informacje pod wieloma kątami.
Dzięki hurtowni danych przedsiębiorstwo może zarządzać ogromnymi zbiorami danych, bez konieczności administrowania wieloma bazami danych. Taka praktyka jest przyszłościowym sposobem przechowywania danych dla business intelligence (BI), który jest zestawem metod/technologii przekształcania surowych danych w użyteczne spostrzeżenia. Ponieważ EDW jest ważną częścią tego systemu, jest on podobny do ludzkiego mózgu przechowującego informacje, ale na sterydach.
Enterprise data warehouse vs zwykła hurtownia danych: jaka jest różnica?
Każda hurtownia danych jest bazą danych, która jest zawsze połączona ze źródłami surowych danych poprzez narzędzia integracji danych z jednej strony i interfejsy analityczne z drugiej. Skoro tak, to dlaczego do dyskusji wyodrębniamy formę korporacyjną?
Każda hurtownia zapewnia pamięć masową, która ma mechanizmy przekształcania danych, przenoszenia ich i prezentowania użytkownikowi końcowemu. Różnica między zwykłą hurtownią danych a korporacyjną polega na jej znacznie większej różnorodności architektonicznej i funkcjonalności. Ze względu na złożoną strukturę i rozmiar, hurtownie EDW są często rozkładane na mniejsze bazy danych, dzięki czemu użytkownicy końcowi mogą wygodniej wykonywać zapytania do tych mniejszych baz. Biorąc to pod uwagę, koncentrujemy się na hurtowni korporacyjnej, aby objąć całe spektrum funkcjonalności.
Jednakże rozmiar hurtowni nie definiuje jej złożoności technicznej, wymagań dotyczących możliwości analitycznych i raportowania, liczby modeli danych i samych danych. Aby więc zrozumieć, co sprawia, że hurtownia jest hurtownią, przyjrzyjmy się jej podstawowym koncepcjom i funkcjonalnościom.
Koncepcje i funkcje hurtowni danych przedsiębiorstwa
Pomimo wszystkich bajerów i gwizdków, w sercu każdej hurtowni leżą podstawowe koncepcje i funkcje. Filary te definiują hurtownię jako zjawisko technologiczne:
Służy jako ostateczna pamięć masowa. Hurtownia danych przedsiębiorstwa to ujednolicone repozytorium wszystkich danych biznesowych, jakie kiedykolwiek pojawiły się w organizacji.
Refleksja danych źródłowych. EDW pozyskuje dane z oryginalnych miejsc ich przechowywania, takich jak Google Analytics, CRM, urządzenia IoT itp. Jeśli dane są rozproszone w wielu systemach, nie da się nimi zarządzać. Tak więc celem EDW jest zapewnienie podobieństwa do oryginalnych danych źródłowych w jednym repozytorium. Ponieważ zawsze generowane są nowe, istotne dane zarówno wewnątrz jak i na zewnątrz firmy, przepływ danych wymaga dedykowanej infrastruktury do zarządzania nimi zanim trafią do hurtowni.
Stores structured data. Dane przechowywane w EDW są zawsze ustandaryzowane i ustrukturyzowane. Dzięki temu użytkownicy końcowi mogą je odpytywać za pomocą interfejsów BI i tworzyć raporty. I to właśnie odróżnia hurtownię danych od jeziora danych. Jeziora danych służą do przechowywania nieustrukturyzowanych danych dla celów analitycznych. Jednak w przeciwieństwie do hurtowni, jeziora danych są wykorzystywane raczej przez inżynierów danych/naukowców do pracy z dużymi zbiorami surowych danych.
Dane zorientowane tematycznie. Głównym celem hurtowni są dane biznesowe, które mogą odnosić się do różnych dziedzin. Aby zrozumieć, do czego odnoszą się dane, są one zawsze zorganizowane wokół określonego tematu zwanego modelem danych. Przykładem tematu może być region sprzedaży lub całkowita sprzedaż danej pozycji. Dodatkowo dodawane są metadane, aby szczegółowo wyjaśnić, skąd pochodzi każdy element informacji.
Zależne od czasu. Gromadzone dane są zazwyczaj danymi historycznymi, ponieważ opisują zdarzenia z przeszłości. Aby zrozumieć, kiedy i jak długo miała miejsce określona tendencja, większość przechowywanych danych jest zwykle podzielona na okresy czasu.
Nieulotne. Po umieszczeniu w magazynie dane nigdy nie są z niego usuwane. Dane mogą być manipulowane, modyfikowane lub aktualizowane ze względu na zmiany w źródle, ale nigdy nie są przeznaczone do usunięcia, przynajmniej przez użytkowników końcowych. Jeśli mówimy o danych historycznych, usuwanie danych jest kontrproduktywne dla celów analitycznych. Jednak ogólne rewizje mogą mieć miejsce raz na kilka lat, aby pozbyć się nieistotnych danych.
Rozważając podstawowe zasady, przyjrzymy się typom implementacji DW.
Rodzaje hurtowni danych
Rozważając funkcje EDW, zawsze istnieje pole do dyskusji na temat tego, jak zaprojektować ją od strony technicznej. W przypadku przechowywania i przetwarzania danych, są one specyficzne i odrębne dla różnych rodzajów przedsiębiorstw. W zależności od ilości danych, złożoności analitycznej, kwestii bezpieczeństwa i budżetu, oczywiście zawsze istnieje opcja, jak skonfigurować system.
Klasyczna hurtownia danych
Zunifikowana pamięć masowa, która ma swój dedykowany sprzęt i oprogramowanie, jest uważana za klasyczny wariant dla EDW. W przypadku fizycznej pamięci masowej nie trzeba konfigurować narzędzi do integracji danych pomiędzy wieloma bazami danych. Zamiast tego, EDW może być połączony ze źródłami danych poprzez API, aby stale pozyskiwać informacje i przekształcać je w procesie. Tak więc cała praca jest wykonywana albo w obszarze inscenizacji (miejsce, w którym dane są przekształcane przed załadowaniem do DW), albo w samej hurtowni.
Klasyczna hurtownia danych jest uważana za nadrzędną w stosunku do wirtualnej (którą omawiamy poniżej), ponieważ nie ma dodatkowej warstwy abstrakcji. Upraszcza to pracę inżynierom danych i ułatwia zarządzanie przepływem danych zarówno po stronie preprocessingu, jak i samego raportowania. Wady klasycznej hurtowni zależą od faktycznego wdrożenia, ale dla większości firm są to:
- Droga infrastruktura technologiczna, zarówno sprzętowa, jak i programowa;
- Zatrudnienie zespołu inżynierów danych i specjalistów DevOps do skonfigurowania i utrzymania całej platformy danych.
Kiedy używać: odpowiednie dla organizacji każdej wielkości, które chcą przetwarzać swoje dane i robić z nich użytek. Klasyczne hurtownie pozwalają na morfing do różnych stylów architektonicznych platformy danych, jak również na skalowanie w górę i w dół w sposób celowy.
Wirtualna hurtownia danych
Wirtualna hurtownia danych jest typem EDW używanym jako alternatywa dla klasycznej hurtowni. Zasadniczo są to liczne bazy danych połączone wirtualnie, dzięki czemu mogą być odpytywane jako jeden system.
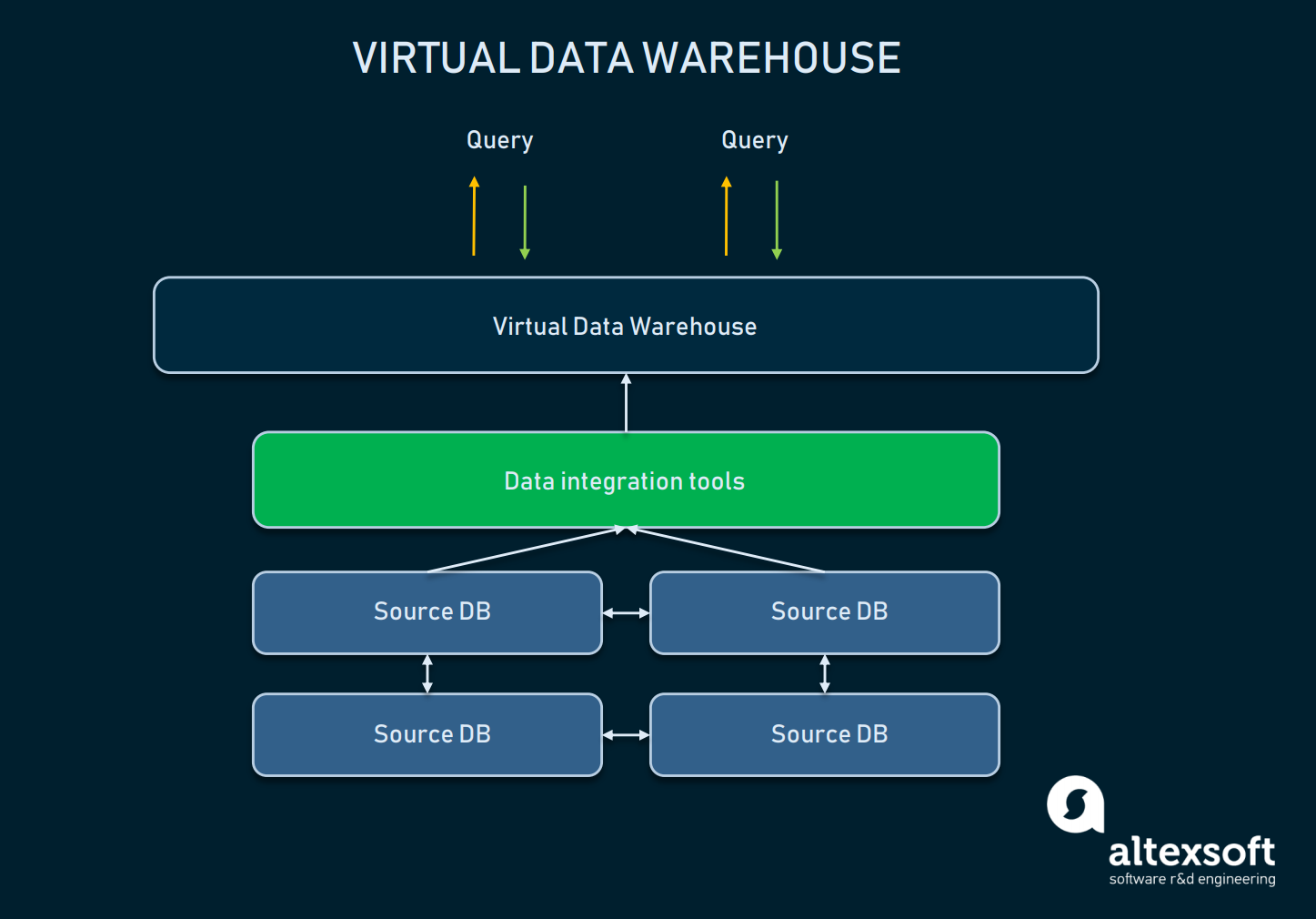
Schemat relacji pomiędzy abstrakcją wirtualnej DW a źródłowymi bazami danych
Takie podejście pozwala organizacjom na zachowanie prostoty: Dane mogą pozostać w swoich źródłach, ale nadal mogą być wyciągane za pomocą narzędzi analitycznych. Wirtualne magazyny mogą być używane, jeśli nie chcesz mieszać się z całą infrastrukturą bazową, lub dane, które posiadasz są łatwe do zarządzania w obecnej postaci. Jednak takie podejście ma wiele wad:
- Wielokrotne bazy danych będą wymagały ciągłej konserwacji oprogramowania i sprzętu oraz ponoszenia kosztów.
- Dane przechowywane w wirtualnym DW nadal wymagają oprogramowania transformującego, aby uczynić je strawnymi dla użytkowników końcowych i narzędzi do raportowania.
- Kompleksowe zapytania o dane mogą zajmować zbyt dużo czasu, ponieważ wymagane fragmenty danych mogą być umieszczone w dwóch oddzielnych bazach danych.
Kiedy używać: odpowiednie dla firm, które mają surowe dane w ustandaryzowanej formie, które nie wymagają złożonej analityki. Pasuje również do organizacji, które nie używają BI systematycznie, lub chcą z nim zacząć.
Chmurowa hurtownia danych
Od dekady technologie chmurowe/ bezchmurowe stały się bardziej standardem przy tworzeniu technologii na poziomie organizacji. Na rynku można znaleźć niezliczonych dostawców, którzy oferują warehousing-as-a-service. Aby wymienić tylko kilka z nich:
- Amazon Redshift/Strona cenowa
- IBM Db2/Strona cenowa
- Google BigQuery/Strona cenowa
- Snowflake/Strona cenowa
- Microsoft SQL Data Warehouse/Strona cenowa
Wszyscy wymienieni dostawcy oferują w pełni zarządzane, skalowalne hurtownie jako część ich narzędzi BI lub koncentrują się na EDW jako samodzielnej usłudze, tak jak Snowflake. W tym przypadku architektura hurtowni w chmurze ma takie same zalety jak każda inna usługa w chmurze. Jej infrastruktura jest utrzymywana za Ciebie, co oznacza, że nie musisz konfigurować własnych serwerów, baz danych i narzędzi do zarządzania nią. Cena takiej usługi będzie zależała od ilości wymaganej pamięci oraz możliwości obliczeniowych dla zapytań.
Jedynym aspektem, o który możesz się martwić w kontekście platformy hurtowni w chmurze jest bezpieczeństwo danych. Dane biznesowe to wrażliwa rzecz. Należy więc sprawdzić, czy wybranemu dostawcy można zaufać, aby uniknąć naruszeń. Nie musi to oznaczać, że magazyn on-premise jest bezpieczniejszy, ale w tym przypadku bezpieczeństwo danych jest w Twoich rękach.
Kiedy używać: Platformy w chmurze to świetny wybór dla organizacji o dowolnej wielkości. Jeśli potrzebujesz wszystkiego, co będzie dla Ciebie przygotowane, w tym zarządzanej integracji danych, konserwacji DW i wsparcia BI.
Architektura korporacyjnych hurtowni danych
Choć istnieje wiele podejść architektonicznych, które w taki czy inny sposób rozszerzają możliwości hurtowni, my skupimy się na tych najbardziej istotnych. Nie wdając się w zbyt wiele technicznych szczegółów, cały potok danych można podzielić na trzy warstwy:
- Warstwa danych surowych (źródła danych)
- Magazyn i jego ekosystem
- Interfejs użytkownika (narzędzia analityczne)
Oprzyrządowanie, które dotyczy Ekstrakcji, Transformacji i Ładowania danych do magazynu jest oddzielną kategorią narzędzi znaną jako ETL. Pod parasolem ETL kryją się również narzędzia integracji danych, które dokonują manipulacji z danymi przed umieszczeniem ich w hurtowni. Narzędzia te działają pomiędzy warstwą surowych danych a hurtownią.
Kiedy dane są ładowane do hurtowni, mogą być również przekształcane. Tak więc, hurtownia będzie wymagała pewnej funkcjonalności do czyszczenia/standaryzacji/ wymiarowania. Te i inne czynniki będą determinowały złożoność architektury. Przyjrzymy się architekturze EDW z punktu widzenia rosnących potrzeb organizacji.
Architektura one-tier
Gdy integracja danych jest dobrze skonfigurowana, możemy wybrać naszą hurtownię danych. W większości przypadków, hurtownia danych jest relacyjną bazą danych z modułami pozwalającymi na wielowymiarowe dane, lub taką, która może oddzielić niektóre informacje specyficzne dla danej domeny dla łatwiejszego dostępu. W swojej najbardziej prymitywnej formie, hurtownia może mieć tylko architekturę jednowarstwową.
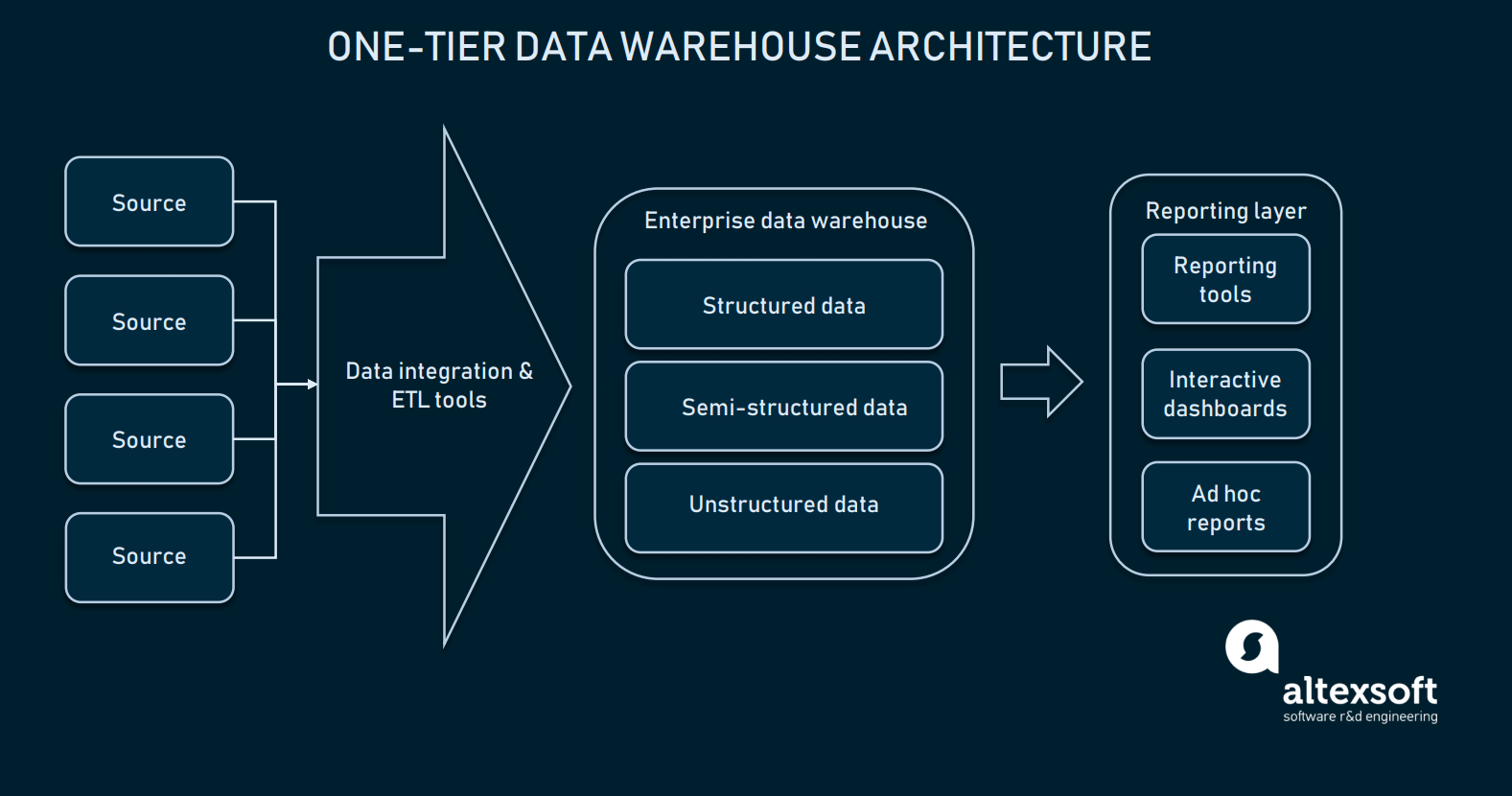
Warstwa raportowania jest połączona bezpośrednio z całą bazą danych EDW
Architektura jednowarstwowa dla EDW oznacza, że masz bazę danych bezpośrednio połączoną z interfejsami analitycznymi, gdzie użytkownik końcowy może wykonywać zapytania. Ustawienie bezpośredniego połączenia pomiędzy EDW a narzędziami analitycznymi niesie ze sobą kilka wyzwań:
- Tradycyjnie można uznać, że Twoja hurtownia zaczyna się od 100GB danych. Bezpośrednia praca z nim może skutkować niechlujnymi wynikami zapytań, a także niską szybkością przetwarzania.
- Pytanie o dane bezpośrednio z DW może wymagać precyzyjnego wprowadzania danych, dzięki czemu system będzie w stanie odfiltrować dane, które nie są potrzebne. Co sprawia, że radzenie sobie z narzędziami prezentacyjnymi jest nieco utrudnione.
- Istnieją ograniczone możliwości elastyczności/analityczne.
Dodatkowo, architektura jednowarstwowa wyznacza pewne granice złożoności raportowania. Takie podejście jest rzadko stosowane w przypadku platform danych o dużej skali, ze względu na powolność i nieprzewidywalność. Aby wykonywać zaawansowane zapytania do danych, hurtownia może być rozszerzona o niskopoziomowe instancje, które ułatwiają dostęp do danych.
Architektura dwuwarstwowa (warstwa data mart)
W architekturze dwuwarstwowej, poziom data mart jest dodany pomiędzy interfejsem użytkownika a EDW. Data mart jest niskopoziomowym repozytorium, które zawiera informacje specyficzne dla danej domeny. Mówiąc prościej, jest to kolejna, mniejsza baza danych, która rozszerza EDW o informacje dedykowane dla działów sprzedaży/operacyjnych, marketingu, itp.
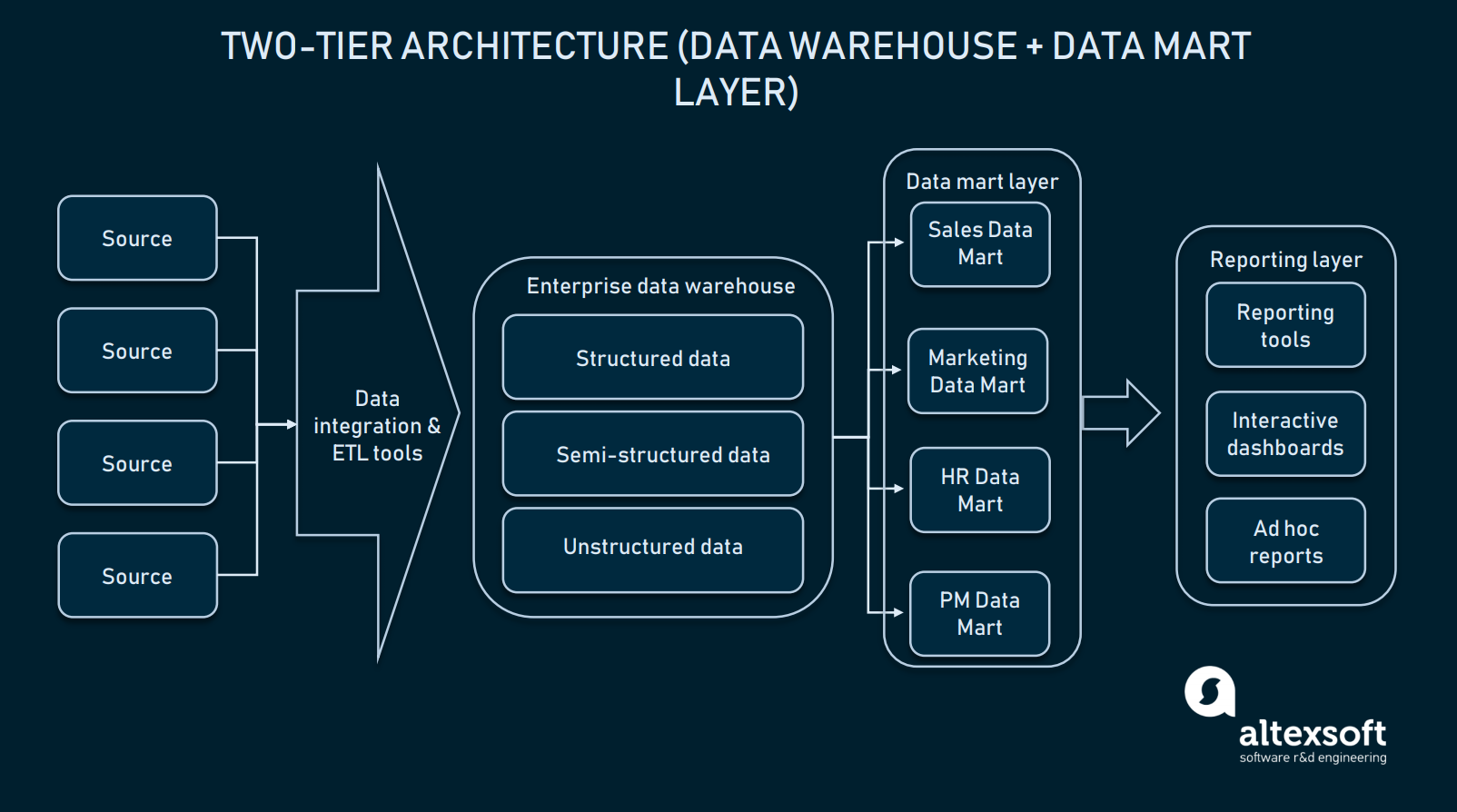
W architekturze dwupoziomowej, EDW jest rozszerzone o data mart w celu dostarczenia danych specyficznych dla danej domeny
Tworzenie warstwy data mart będzie wymagało dodatkowych zasobów do stworzenia sprzętu i zintegrowania tych baz danych z resztą platformy danych. Jednak takie podejście rozwiązuje problem z zapytaniami: Każdy dział będzie miał łatwiejszy dostęp do potrzebnych danych, ponieważ dany mart będzie zawierał tylko informacje specyficzne dla danej domeny. Dodatkowo, data marts ograniczą dostęp do danych dla użytkowników końcowych, czyniąc EDW bardziej bezpiecznym.
Architektura trójwarstwowa (Online analytical processing)
Na wierzchu warstwy data mart, przedsiębiorstwa używają również kostek online analytical processing (OLAP). Kostka OLAP jest szczególnym rodzajem bazy danych, która reprezentuje dane z wielu wymiarów. Podczas gdy relacyjne bazy danych reprezentują dane tylko w dwóch wymiarach (pomyśl o Excelu lub Google Sheets), OLAP pozwala na kompilację danych w wielu wymiarach i poruszanie się pomiędzy wymiarami.
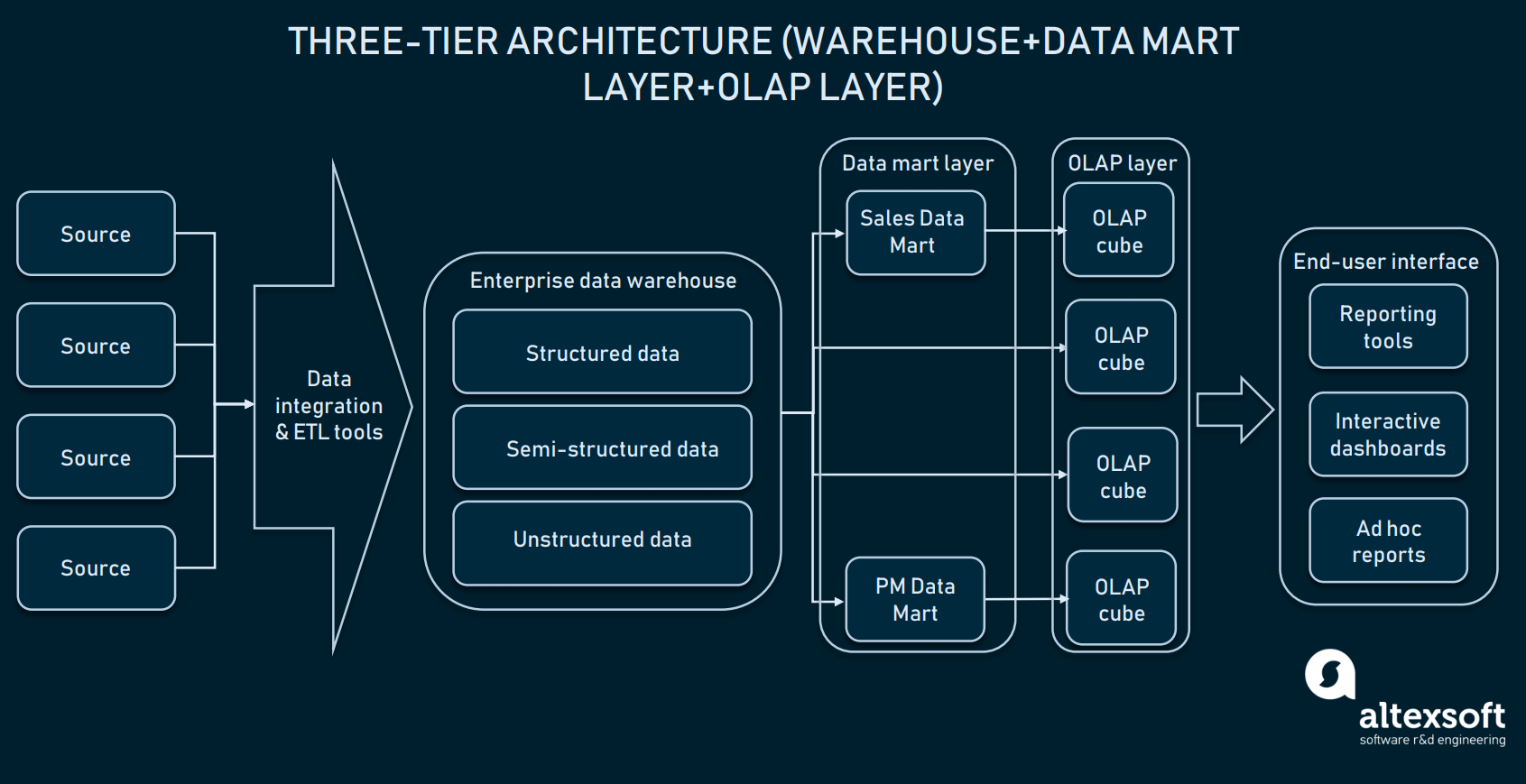
Warstwa kostek OLAP może pozyskiwać informacje z rozproszonych mart lub bezpośrednio z EDW
To dość trudne do wyjaśnienia słowami, więc spójrzmy na ten poręczny przykład tego, jak kostka może wyglądać.
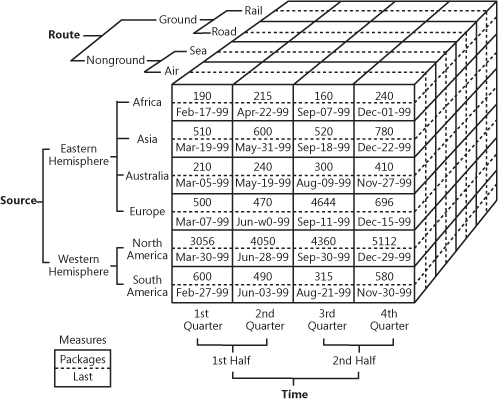
KostkaOLAP demonstrująca wielowymiarowe dane sprzedaży
Źródło: oreilly.com
Jak widać, kostka dodaje wymiary do danych. Można o niej myśleć jak o wielu tabelach Excela połączonych ze sobą. Przód kostki to zwykła dwuwymiarowa tabela, w której region (Afryka, Azja itp.) jest określony pionowo, a numery sprzedaży i daty są zapisane poziomo. Magia zaczyna się, gdy spojrzymy na górną część kostki, gdzie sprzedaż jest podzielona na trasy, a dolna określa okres czasu. To jest znane jako dane wielowymiarowe.
Wartość biznesowa OLAP polega na tym, że pozwala użytkownikom na cięcie i krojenie danych w celu sporządzania szczegółowych raportów. Tak długo, jak kostki są zoptymalizowane do pracy z hurtowniami, mogą być używane zarówno bezpośrednio z EDW, aby dać dostęp do wszystkich danych korporacyjnych lub z każdym data mart specjalnie. Jeśli chodzi o implementację, prawie wszyscy dostawcy hurtowni oferują OLAP jako usługę. Przykładem może być dokumentacja firmy Microsoft dotycząca ich oferty OLAP.
W tym miejscu omówiliśmy wysokopoziomowy projekt EDW zastosowany do potrzeb organizacji. Teraz zajmiemy się technicznymi komponentami, które hurtownia może zawierać.
Data Warehouse vs Data Lake vs Data Mart
Mówiąc o architekturze przechowywania danych, musimy wspomnieć o takich opcjach, jak użycie data mart lub data lake zamiast hurtowni. Często mylone, rozwiniemy definicje.
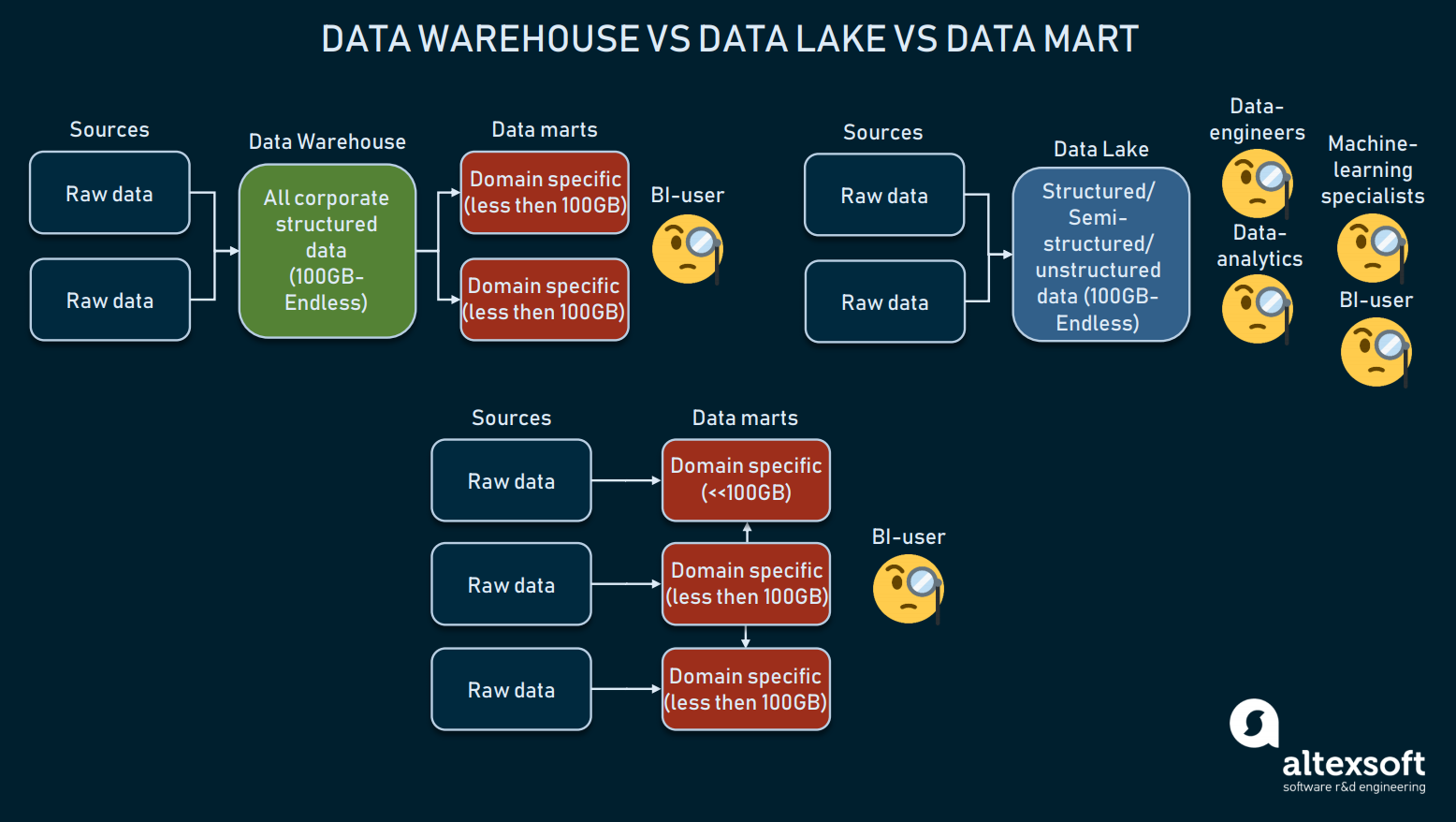
Porównanie trzech form przechowywania danych
Magazyny danych mają za zadanie przechowywać ustrukturyzowane dane, tak aby narzędzia zapytań i użytkownicy końcowi mogli uzyskać kompleksowe wyniki. Hurtownie, wykorzystywane głównie do BI, zwykle mają rozmiar od 100 GB do nieskończoności.
Ludzie danych są natomiast wykorzystywane do przechowywania głównie surowych lub mieszanych danych. Są one często wykorzystywane do celów uczenia maszynowego, big data lub eksploracji danych. Przez ostatnie kilka lat, jeziora danych były wykorzystywane do BI: surowe dane są ładowane do jeziora i przekształcane, co jest alternatywą dla procesu ETL. Chociaż to podejście ma swoje plusy i minusy, jeziora danych mogą być zbyt niechlujne, aby dotrzeć do ustrukturyzowanych danych.
Wtedy mamy data marts, które również mogą być używane jako alternatywa dla DW. Takie modele (jak model Kimballa) zakładają wykorzystanie wielu data marts do dystrybucji informacji według domen i łączenia ich ze sobą. Jednak ze względu na ich niewielki rozmiar (zwykle mniejszy niż 100GB), data marts mogą być rzadko wykorzystywane przez przedsiębiorstwa. Częściej data marts są używane do segmentacji dużych DW na bardziej operacyjne.
Komponenty korporacyjnej hurtowni danych
Istnieje wiele instrumentów używanych do tworzenia platformy hurtowni danych. O większości z nich, w tym o samej hurtowni, już wspomnieliśmy. Przyjrzyjmy się więc z lotu ptaka przeznaczeniu każdego z komponentów i ich funkcjom.
Źródła. To proste, bazy danych, w których przechowywane są surowe dane.
Warstwa ekstrakcji, transformacji, ładowania (ETL) lub Extract, Load, Transform (ELT). Są to narzędzia, które wykonują faktyczne połączenie z danymi źródłowymi, ich ekstrakcję oraz załadowanie do miejsca, w którym zostaną poddane transformacji. Transformacja ujednolica format danych. Podejścia ETL i ELT różnią się tym, że w ETL transformacja odbywa się przed EDW, w staging area. ELT jest bardziej nowoczesnym podejściem, które zajmuje się całą transformacją w hurtowni.
Staging area. W przypadku ETL, obszar inscenizacji jest miejscem, do którego dane są ładowane przed EDW. Tutaj będą one czyszczone i przekształcane do danego modelu danych. Obszar inscenizacji może również zawierać narzędzia do zarządzania jakością danych.
Baza danych EDW. Dane są ostatecznie ładowane do przestrzeni dyskowej. W ELT może to jeszcze wymagać pewnej transformacji w tym miejscu. Ale na tym etapie wszystkie ogólne zmiany zostaną zastosowane, a więc dane zostaną załadowane do swojego ostatecznego modelu (modeli). Jak już wspomnieliśmy, hurtownie danych to najczęściej relacyjne bazy danych. W skład DW będzie wchodził również system zarządzania bazą danych oraz dodatkowe miejsce do przechowywania metadanych.
Moduł metadanych. Mówiąc najprościej, metadane to dane o danych. Są to objaśnienia, które podpowiadają użytkownikom/administratorom, do jakiego tematu/domen odnosi się dana informacja. Dane te mogą być meta techniczne (np. początkowe źródło), lub meta biznesowe (np. region sprzedaży). Wszystkie meta są przechowywane w oddzielnym module EDW i są zarządzane przez menedżera metadanych.
Warstwa raportowania. Są to narzędzia, które dają użytkownikom końcowym dostęp do danych. Nazywana również interfejsem BI, warstwa ta będzie służyć jako tablica rozdzielcza do wizualizacji danych, tworzenia raportów i wyciągania oddzielnych informacji.
Pomysł końcowy
Zrozumienie łańcucha narzędzi, które przekazują dane, może pomóc Ci zorientować się, co faktycznie odpowiada wymaganiom Twojej platformy danych. Planowanie utworzenia hurtowni może zająć lata planowania i testowania, ze względu na jej skalę w najbardziej podstawowej formie.
Jako właściciel firmy możesz być zdezorientowany liczbą opcji i stosowanych technologii, dlatego ważne jest, aby skonsultować się z ekspertami w dziedzinie magazynowania, ETL i BI. Podczas gdy eksperci mogą pomóc Ci w aspekcie technicznym, aby określić cel biznesowy, porozmawiaj z tymi, którzy będą wykorzystywać dane w swojej pracy.