




Introducere în proiectarea bazelor de date
Identificarea atributelor
Elementele de date pe care doriți să le salvați pentru fiecare entitate se numesc „atribute”.
Despre produsele pe care le vindeți, doriți să știți, de exemplu, care este prețul, care este numele producătorului și care este numărul de tip. Despre clienți știți numărul lor de client, numele și adresa lor. Despre magazine, cunoașteți codul locației, numele și adresa. Despre vânzări, știți când au avut loc, în ce magazin, ce produse au fost vândute și suma totală a vânzărilor. Despre vânzător știți numărul de personal, numele și adresa acestuia. Ce anume va fi inclus nu are încă importanță; este vorba doar de ceea ce doriți să salvați.
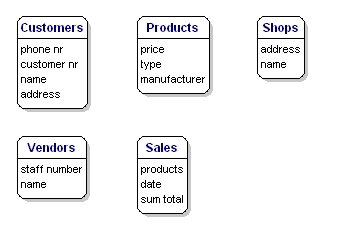
Figura 6: Entități cu atribute.
Date derivate
Datele derivate sunt date care sunt derivate din alte date pe care le-ați salvat deja. În acest caz, „suma totală” este un caz clasic de date derivate. Știți exact ce s-a vândut și cât costă fiecare produs, așa că puteți calcula oricând cât este suma totală a vânzărilor. Deci, în realitate, nu este necesar să salvați suma totală.
Atunci de ce este salvat aici? Ei bine, pentru că este vorba de o vânzare, iar prețul produsului poate varia în timp. Un produs poate avea un preț de 10 euro astăzi și de 8 euro luna viitoare, iar pentru administrarea dumneavoastră trebuie să știți cât a costat la momentul vânzării, iar cel mai simplu mod de a face acest lucru este să îl salvați aici. Există o mulțime de modalități mai elegante, dar sunt prea profunde pentru acest articol.
Prezentarea entităților și a relațiilor: Diagrama de relații între entități (ERD)
Diagrama de relații între entități (ERD) oferă o prezentare grafică a bazei de date. Există mai multe stiluri și tipuri de diagrame ER. O notație foarte utilizată este notația „picior de cioară”, în care entitățile sunt reprezentate ca dreptunghiuri, iar relațiile dintre entități sunt reprezentate ca linii între entități. Semnele de la capătul liniilor indică tipul de relație. Partea relației care este obligatorie pentru ca cealaltă să existe va fi indicată printr-o liniuță pe linie. Entitățile care nu sunt obligatorii sunt indicate printr-un cerc. „Multe” este indicată prin intermediul unui „picior de cioară”; linia de relație se împarte în trei linii.
În acest articol folosim DeZign for Databases pentru a proiecta și prezenta baza noastră de date.
O relație obligatorie 1:1 este reprezentată după cum urmează:
Figura 7: Relație obligatorie unu la unu.
O relație obligatorie 1:N:
Figura 8: Relație obligatorie de tip unu la mai mulți.
O relație M:N este:
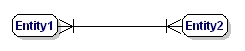
Figura 9: Relație obligatorie de tip mulți la mulți.
Modelul din exemplul nostru va arăta astfel:
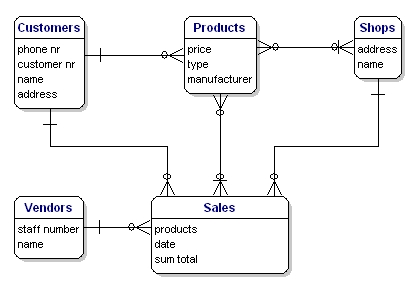
Figura 10: Model cu relații.
Asignarea cheilor
Chei primare
O cheie primară (PK) este unul sau mai multe atribute de date care identifică în mod unic o entitate. O cheie care constă din două sau mai multe atribute se numește cheie compozită. Toate atributele care fac parte dintr-o cheie primară trebuie să aibă o valoare în fiecare înregistrare (care nu poate fi lăsată goală), iar combinația valorilor din cadrul acestor atribute trebuie să fie unică în tabel.
În exemplu există câțiva candidați evidenți pentru cheia primară. Clienții au toți un număr de client, produsele au toate un număr unic de produs și vânzările au un număr de vânzări. Fiecare dintre aceste date este unică și fiecare înregistrare va conține o valoare, astfel încât aceste atribute pot fi o cheie primară. Adesea se utilizează o coloană de numere întregi pentru cheia primară, astfel încât o înregistrare să poată fi găsită cu ușurință prin numărul său.
Entitățile de legătură se referă, de obicei, la atributele cheie primare ale entităților pe care le leagă. Cheia primară a unei entități de legătură este, de obicei, o colecție a acestor atribute de referință. De exemplu, în entitatea Sales_details am putea folosi combinația de PK-uri ale entităților sales și products ca PK a Sales_details. În acest fel, impunem ca același produs (tip) să nu poată fi utilizat decât o singură dată în cadrul aceleiași vânzări. Articolele multiple ale aceluiași tip de produs într-o vânzare trebuie să fie indicate prin cantitate.
În ERD, atributele cu cheie primară sunt indicate prin textul „PK” în spatele numelui atributului. În exemplu, doar entitatea „shop” nu are un candidat evident pentru PK, așa că vom introduce un nou atribut pentru această entitate: shopnr.
Clave străine
Ceafa străină (FK) dintr-o entitate este referința la cheia primară a unei alte entități. În ERD, atributul respectiv va fi indicat cu „FK” în spatele numelui său. Cheia externă a unei entități poate fi, de asemenea, o parte a cheii primare, caz în care atributul va fi indicat cu „PF” în spatele numelui său. Acesta este, de obicei, cazul entităților de legătură, deoarece, de obicei, se leagă două instanțe doar o singură dată (în cazul unei vânzări, doar un tip de produs este vândut o singură dată).
Dacă punem toate entitățile de legătură, PK și FK în ERD, obținem modelul prezentat mai jos. Vă rugăm să rețineți că atributul „products” nu mai este necesar în „Sales”, deoarece „sold products” este acum inclus în tabelul de legături. În tabelul de legătură a fost adăugat un alt câmp, „quantity”, care indică câte produse au fost vândute. Câmpul „quantity” a fost adăugat, de asemenea, în tabelul „stock”, pentru a indica câte produse mai sunt în magazin.
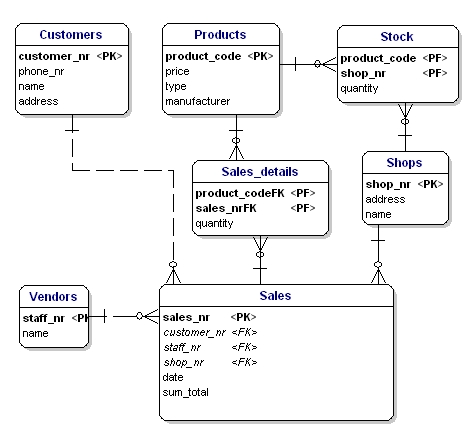
Figura 11: Chei primare și chei străine.
Definirea tipului de date al atributului
Acum este momentul să ne dăm seama ce tipuri de date trebuie să fie folosite pentru atribute. Există o mulțime de tipuri de date diferite. Câteva sunt standardizate, dar multe baze de date au propriile lor tipuri de date care au toate avantajele lor. Unele baze de date oferă posibilitatea de a defini propriile tipuri de date, în cazul în care tipurile standard nu pot face ceea ce aveți nevoie.
Tipurile de date standard pe care fiecare bază de date le cunoaște și care sunt cele mai utilizate sunt: CHAR, VARCHAR, TEXT, FLOAT, DOUBLE și INT.
Text:
- CHAR(length) – include text (caractere, numere, semne de punctuație…). CHAR are drept caracteristică faptul că salvează întotdeauna o cantitate fixă de poziții. Dacă definiți un CHAR(10), puteți salva maximum zece poziții, dar dacă utilizați doar două poziții, baza de date va salva totuși 10 poziții. Cele opt poziții rămase vor fi ocupate de spații.
- VARCHAR(length) – include text (caractere, numere, semne de punctuație…). VARCHAR este același lucru ca și CHAR, diferența este că VARCHAR ocupă doar atâta spațiu cât este necesar.
- TEXT – poate conține cantități mari de text. În funcție de tipul de bază de date, aceasta poate însuma până la gigabytes.
Numeri:
- INT – conține un număr întreg pozitiv sau negativ. O mulțime de baze de date au variații ale INT, cum ar fi TINYINT, SMALLINT, MEDIUMINT, BIGINT, INT2, INT4, INT8. Aceste variații diferă de INT doar prin dimensiunea cifrei care încape în el. Un INT obișnuit are 4 octeți (INT4) și se potrivește cu cifre de la -2147483647 la +2147483646 sau, dacă îl definiți ca UNSIGNED, de la 0 la 4294967296. INT8, sau BIGINT, poate avea o dimensiune și mai mare, de la 0 la 18446744073709551616, dar ocupă până la 8 octeți de spațiu pe disc, chiar dacă în el se află doar un număr mic.
- FLOAT, DOUBLE – Aceeași idee ca și INT, dar poate stoca și numere în virgulă mobilă. . Rețineți că acest lucru nu funcționează întotdeauna perfect. De exemplu, în MySQL, calculul cu aceste numere cu virgulă mobilă nu este perfect, (1/3)*3 va rezulta cu numere float din MySQL în 0,9999999, nu 1.
Alte tipuri:
- BLOB – pentru date binare, cum ar fi fișiere.
- INET – pentru adrese IP. De asemenea, utilizabil și pentru măști de rețea.
Pentru exemplul nostru, tipurile de date sunt următoarele:
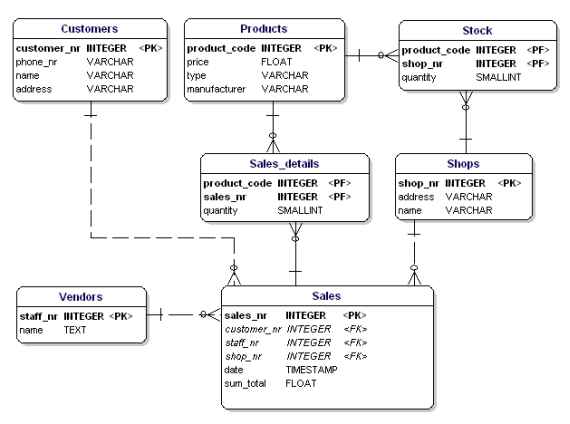
Figura 12: Model de date care afișează tipurile de date.
Normalizarea
Normalizarea face ca modelul de date să fie flexibil și fiabil. Ea generează o anumită suprasolicitare deoarece, de obicei, obțineți mai multe tabele, dar vă permite să faceți multe lucruri cu modelul dvs. de date fără a fi nevoie să îl ajustați. Puteți citi mai multe despre normalizarea bazei de date în acest articol.
Normalizarea, prima formă
Prima formă de normalizare afirmă că nu pot exista grupuri de coloane care se repetă într-o entitate. Am fi putut crea o entitate „vânzări” cu atribute pentru fiecare dintre produsele care au fost cumpărate. Aceasta ar fi arătat astfel:

Figura 13: Nu este în prima formă normală.
Ce este greșit în această situație este că acum pot fi vândute doar 3 produse. Dacă ar trebui să vindeți 4 produse, atunci ar trebui să începeți o a doua vânzare sau să vă ajustați modelul de date prin adăugarea atributelor „product4”. Ambele soluții sunt nedorite. În aceste cazuri, ar trebui să creați întotdeauna o nouă entitate pe care să o legați de cea veche printr-o relație unu-la-mulțime.
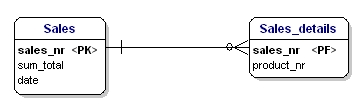
Figura 14: În conformitate cu prima formă normală.
Normalizarea, a doua formă
A doua formă de normalizare afirmă că toate atributele unei entități ar trebui să fie complet dependente de întreaga cheie primară. Aceasta înseamnă că fiecare atribut al unei entități poate fi identificat numai prin intermediul întregii chei primare. Să presupunem că am avea data în entitatea Sales_details:

Figura 15: Nu este în a doua formă normală.
Această entitate nu este conform celei de-a doua forme de normalizare, deoarece pentru a putea căuta data unei vânzări, nu trebuie să știu ce s-a vândut (productnr), singurul lucru pe care trebuie să îl știu este numărul de vânzare. Acest lucru a fost rezolvat prin împărțirea tabelelor în tabelul Sales și Sales_details:
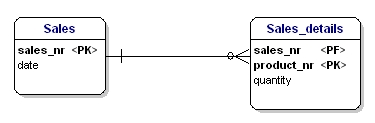
Figura 16: În conformitate cu a doua formă de normalizare.
Acum fiecare atribut al entităților este dependent de întregul PK al entității. Data este dependentă de numărul de vânzări, iar cantitatea este dependentă de numărul de vânzări și de produsul vândut.
Normalizarea, a treia formă
Cea de-a treia formă de normalizare afirmă că toate atributele trebuie să depindă direct de cheia primară, și nu de alte atribute. Acest lucru pare a fi ceea ce afirmă cea de-a doua formă de normalizare, dar în cea de-a doua formă se afirmă de fapt contrariul. În cea de-a doua formă de normalizare, atributele sunt evidențiate prin intermediul PK, în cea de-a treia formă de normalizare fiecare atribut trebuie să depindă de PK, și nimic altceva.

Figura 17: Nu în a treia formă de normalizare.
În acest caz, prețul unui produs vrac depinde de numărul de comandă, iar numărul de comandă depinde de numărul produsului și de numărul de vânzare. Acest lucru nu este în conformitate cu cea de-a treia formă de normalizare. Din nou, împărțirea tabelelor rezolvă acest lucru.
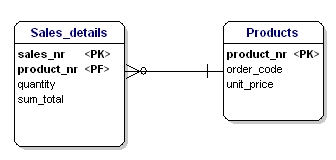
Figura 18: În conformitate cu a treia formă normală.
Normalizarea, mai multe forme
Există mai multe forme de normalizare decât cele trei forme menționate mai sus, dar acestea nu sunt de mare interes pentru utilizatorul mediu. Aceste alte forme sunt foarte specializate pentru anumite aplicații. Dacă respectați regulile de proiectare și de normalizare menționate în acest articol, veți crea un design care funcționează foarte bine pentru majoritatea aplicațiilor.
Model de date normalizat
Dacă aplicați regulile de normalizare, veți constata că „producătorul” din tabelul de produse ar trebui să fie, de asemenea, un tabel separat:
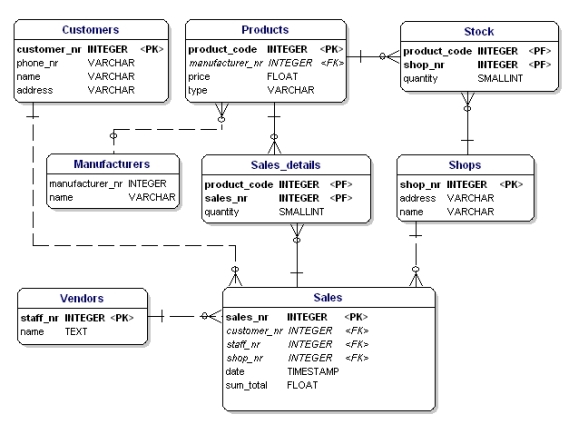
Figura 19: Model de date în conformitate cu prima, a doua și a treia formă normală.