




Enterprise Data Warehouse: Koncept, arkitektur och komponenter
Lästid: 12 minuter
Under hela dagen fattar vi många beslut som bygger på tidigare erfarenheter. Vår hjärna lagrar biljoner bitar av data om tidigare händelser och utnyttjar dessa minnen varje gång vi står inför behovet av att fatta ett beslut. Precis som människor genererar och samlar företag in massor av data om det förflutna. Och dessa uppgifter kan användas för att fatta bättre beslut.
Men medan vår hjärna tjänar till att både bearbeta och lagra behöver företag flera verktyg för att arbeta med uppgifter. Och ett av de viktigaste är ett datalager.
I den här artikeln kommer vi att diskutera vad ett datalager för företag är, dess typer och funktioner och hur det används vid databehandling. Vi kommer att definiera hur företagsdatalagren skiljer sig från de vanliga, vilka typer av datalagren som finns och hur de fungerar. Fokus ligger på att ge information om affärsvärdet av varje arkitektoniskt och konceptuellt tillvägagångssätt för att bygga ett lager.
Vad är ett företagsdatalagret?
Om du vet hur mycket terabyte är, skulle du antagligen bli imponerad av det faktum att Netflix hade cirka 44 terabyte data i sitt lager redan 2016. Enbart storleken antyder varför vi kallar det för ett lager i stället för bara en databas. Så låt oss börja med grunderna.
Ett Enterprise Data Warehouse (EDW) är en form av företagsförråd som lagrar och hanterar alla historiska affärsdata i ett företag. Informationen kommer vanligtvis från olika system som ERP, CRM, fysiska registreringar och andra platta filer. För att förbereda data för vidare analys måste de placeras i ett enda lagringsutrymme. På så sätt kan olika affärsenheter fråga efter den och analysera informationen från flera olika håll.
Med ett datalager kan ett företag hantera enorma datamängder, utan att administrera flera databaser. En sådan praxis är ett framtidssäkert sätt att lagra data för business intelligence (BI), som är en uppsättning metoder/tekniker för att omvandla rådata till användbara insikter. Med EDW som en viktig del av detta liknar systemet en mänsklig hjärna som lagrar information, men på steroider.
Enterprise data warehouse vs vanliga data warehouse: vad är skillnaden?
Varje data warehouse är en databas som alltid är ansluten till rådatakällor via dataintegreringsverktyg i ena änden och analytiska gränssnitt i den andra. Om så är fallet, varför isolerar vi företagsformen för diskussion?
Varje lager tillhandahåller lagring som har mekanismer för att omvandla data, flytta dem och presentera dem för slutanvändaren. Skillnaden mellan ett vanligt datalager och ett företagslager ligger i dess mycket större arkitektoniska mångfald och funktionalitet. På grund av den komplexa strukturen och storleken är EDW:s ofta uppdelade i mindre databaser, så att slutanvändarna är mer bekväma med att fråga i dessa mindre databaser. Med tanke på detta fokuserar vi på ett företagslager för att täcka hela spektrumet av funktionalitet.
Däremot definierar storleken på ett lager inte dess tekniska komplexitet, kraven på analys- och rapporteringsmöjligheter, antalet datamodeller och själva datan. Så för att förstå vad som gör ett lager till ett lager, låt oss dyka ner i dess kärnkoncept och funktionalitet.
Enterprise Data Warehouse concepts and functions
Med alla klockor och visselpipor, i hjärtat av varje lager ligger grundläggande koncept och funktioner. Dessa pelare definierar ett lager som ett tekniskt fenomen:
Servar som den ultimata lagringen. Ett datalager för företag är ett enhetligt förvaringsutrymme för alla företagsdata som någonsin förekommer i organisationen.
Reflekterar källdata. EDW källan till data från dess ursprungliga lagringsutrymmen som Google Analytics, CRM, IoT-enheter osv. Om data är utspridda i flera olika system är det ohanterligt. Så syftet med EDW är att tillhandahålla likheten med de ursprungliga källdata i ett enda förvaringsutrymme. Eftersom det alltid genereras nya, relevanta data både inom och utanför företaget kräver dataflödet en särskild infrastruktur för att hantera dem innan de kommer in i ett lager.
Lagrar strukturerade data. De data som lagras i ett EDW är alltid standardiserade och strukturerade. Detta gör det möjligt för slutanvändarna att fråga efter dem via BI-gränssnitt och skapa rapporter. Och det är detta som skiljer ett datalager från en datasjö. Datalager används för att lagra ostrukturerade data för analytiska ändamål. Men till skillnad från lager används datasjöar mer av dataingenjörer/forskare för att arbeta med stora uppsättningar av rådata.
Subjektorienterade data. Huvudfokus för ett lager är affärsdata som kan relatera till olika domäner. För att förstå vad data relaterar till är den alltid strukturerad kring ett specifikt ämne som kallas datamodell. Ett exempel på ett ämne kan vara ett försäljningsområde eller den totala försäljningen av en viss artikel. Dessutom läggs metadata till för att i detalj förklara var varje del av informationen kommer ifrån.
Tidsberoende. De insamlade uppgifterna är vanligtvis historiska uppgifter, eftersom de beskriver tidigare händelser. För att förstå när och hur länge en viss tendens ägde rum delas de flesta lagrade data vanligtvis in i tidsperioder.
Nonvolatil. När uppgifterna väl har placerats i ett lager raderas de aldrig därifrån. Uppgifterna kan manipuleras, ändras eller uppdateras på grund av källförändringar, men de är aldrig avsedda att raderas, åtminstone inte av slutanvändarna. När vi talar om historiska data är raderingar kontraproduktiva för analytiska ändamål. Ändå kan allmänna revideringar ske en gång på några år för att bli av med irrelevanta data.
Med tanke på grundprinciperna ska vi titta på implementeringstyperna av DWs.
Data warehouse types
Med tanke på EDW-funktioner finns det alltid utrymme för diskussion om hur det ska utformas tekniskt. När det gäller datalagring och databehandling är de specifika och distinkta för olika typer av företag. Beroende på datamängd, analytisk komplexitet, säkerhetsfrågor och budget finns det naturligtvis alltid ett alternativ för hur systemet ska utformas.
Klassiskt datalager
Enhetlig lagring som har sin egen dedikerade hårdvara och mjukvara anses vara en klassisk variant för ett EDW. Med fysisk lagring behöver du inte konfigurera verktyg för dataintegration mellan flera databaser. Istället kan EDW anslutas till datakällor via API:er för att ständigt hämta information och omvandla den i processen. Allt arbete görs alltså antingen i stagingområdet (platsen där data omvandlas innan de laddas in i DW) eller i själva lagret.
Ett klassiskt datalager anses vara superlativ till ett virtuellt (som vi diskuterar nedan), eftersom det inte finns något ytterligare abstraktionslager. Det förenklar arbetet för dataingenjörer och gör det lättare att hantera dataflödet på förbehandlingssidan samt den faktiska rapporteringen. Nackdelarna med det klassiska lagret beror på den faktiska implementeringen, men för de flesta företag är dessa:
- Dyr teknisk infrastruktur, både hårdvara och mjukvara;
- Anställa ett team av dataingenjörer och DevOps-specialister för att sätta upp och underhålla hela dataplattformen.
När du ska använda den: Lämplig för organisationer i alla storlekar som vill bearbeta sina data och använda dem. Klassiska lager gör det möjligt att förvandlas till olika arkitektoniska stilar av dataplattformen, samt att skalas upp och ner med avsikt.
Virtuellt datalager
Ett virtuellt datalager är en typ av EDW som används som ett alternativ till ett klassiskt lager. I huvudsak handlar det om flera databaser som är virtuellt anslutna, så att de kan frågas ut som ett enda system.
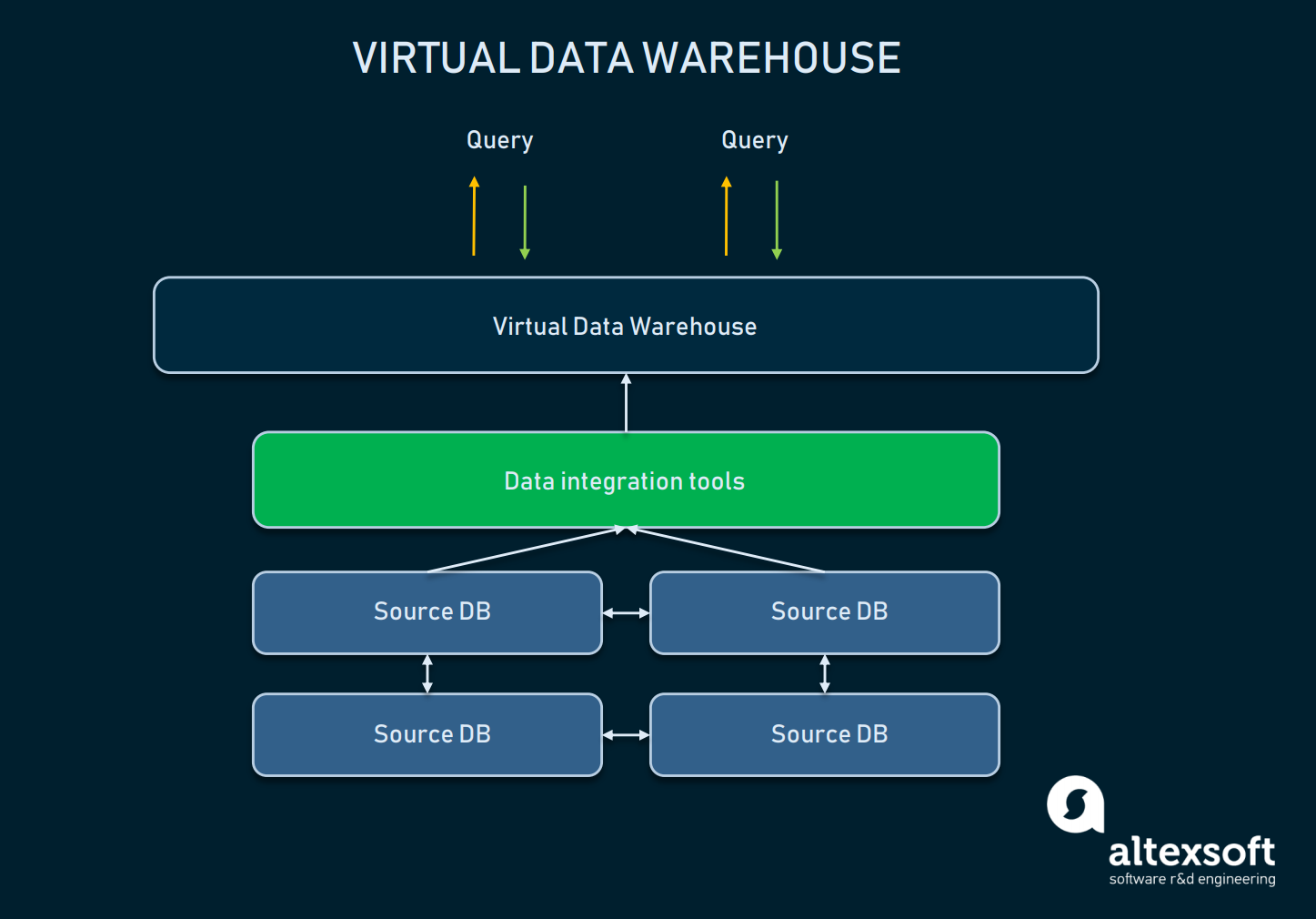
Ett schema för relationer mellan abstraktionen av virtuellt DW och källdatabaser
En sådan strategi gör det möjligt för organisationer att hålla det enkelt: Data kan stanna i källorna, men kan fortfarande dras med hjälp av analysverktyg. Virtuella lager kan användas om man inte vill krångla med all underliggande infrastruktur, eller om de data man har är lätta att hantera som de är. Ett sådant tillvägagångssätt har dock många nackdelar:
- Flera databaser kommer att kräva konstant underhåll och kostnader för mjukvara och hårdvara.
- Data som lagras i ett virtuellt DW kräver fortfarande en omvandlingsprogramvara för att göra den smältbar för slutanvändare och rapporteringsverktyg.
- Komplexa dataförfrågningar kan ta för mycket tid, eftersom de nödvändiga datastyckena kan placeras i två separata databaser.
När man ska använda: Lämplig för företag som har rådata i en standardiserad form som inte kräver komplexa analyser. Det passar också organisationer som inte använder BI systematiskt, eller som vill börja med det.
Cloud Data Warehouse
Under ett decennium har moln-/cloudless-teknik blivit mer av en standard för att sätta upp teknik på organisationsnivå. Du hittar otaliga leverantörer på marknaden som erbjuder warehousing-as-a-service. För att nämna några:
- Amazon Redshift/ Prissättningssida
- IBM Db2/ Prissättningssida
- Google BigQuery/ Prissättningssida
- Snowflake/ Prissättningssida
- Microsoft SQL Data Warehouse/ Prissättningssida
Alla de nämnda leverantörerna erbjuder fullt hanterat, skalbart lager som en del av deras BI-verktyg, eller fokuserar på EDW som en fristående tjänst, som Snowflake gör. I det här fallet har molnlagerarkitekturen samma fördelar som alla andra molntjänster. Dess infrastruktur underhålls åt dig, vilket innebär att du inte behöver sätta upp egna servrar, databaser och verktyg för att hantera den. Priset för en sådan tjänst beror på hur mycket minne som krävs och hur mycket beräkningskapacitet som krävs för sökningar.
Den enda aspekt som du kan vara orolig för när det gäller en molnlagerplattform är datasäkerheten. Dina affärsdata är en känslig sak. Så du vill kontrollera om leverantören du har valt kan lita på att den kan undvika överträdelser. Detta betyder inte nödvändigtvis att ett lager på plats är säkrare, men i det här fallet ligger säkerheten för dina data i dina händer.
När du ska använda: Molnplattformar är ett utmärkt val för organisationer av alla storlekar. Om du behöver att allt sätts upp för dig, inklusive hanterad dataintegration, DW-underhåll och BI-stöd.
Enterprise Data Warehouse Architecture
Samtidigt som det finns många arkitektoniska tillvägagångssätt som utökar lagerkapaciteten på ett eller annat sätt, kommer vi att fokusera på de mest väsentliga. Utan att dyka in i alltför många tekniska detaljer kan hela datapipeline delas in i tre lager:
- Rådatalager (datakällor)
- Lagret och dess ekosystem
- Användargränssnittet (analysverktyg)
Verktygen som rör utvinning, omvandling och inläsning av data i ett lager är en separat kategori av verktyg som kallas ETL. Under ETL-paraplyet utför även dataintegrationsverktyg manipulationer med data innan de placeras i ett lager. Dessa verktyg arbetar mellan ett rådatalager och ett lager.
När data laddas in i ett lager kan de också omvandlas. Lagret kommer alltså att kräva viss funktionalitet för rengöring/standardisering/dimensionering. Dessa och andra faktorer kommer att avgöra arkitekturens komplexitet. Vi kommer att titta på EDW-arkitekturen utifrån växande organisatoriska behov.
En-nivåarkitektur
Med tanke på att dataintegration är väl konfigurerad kan vi välja vårt datalager. I de flesta fall är ett datalager en relationsdatabas med moduler för att möjliggöra multidimensionella data, eller en som kan separera viss domänspecifik information för att underlätta åtkomsten. I sin mest primitiva form kan datalagret bara ha en arkitektur med ett lager.
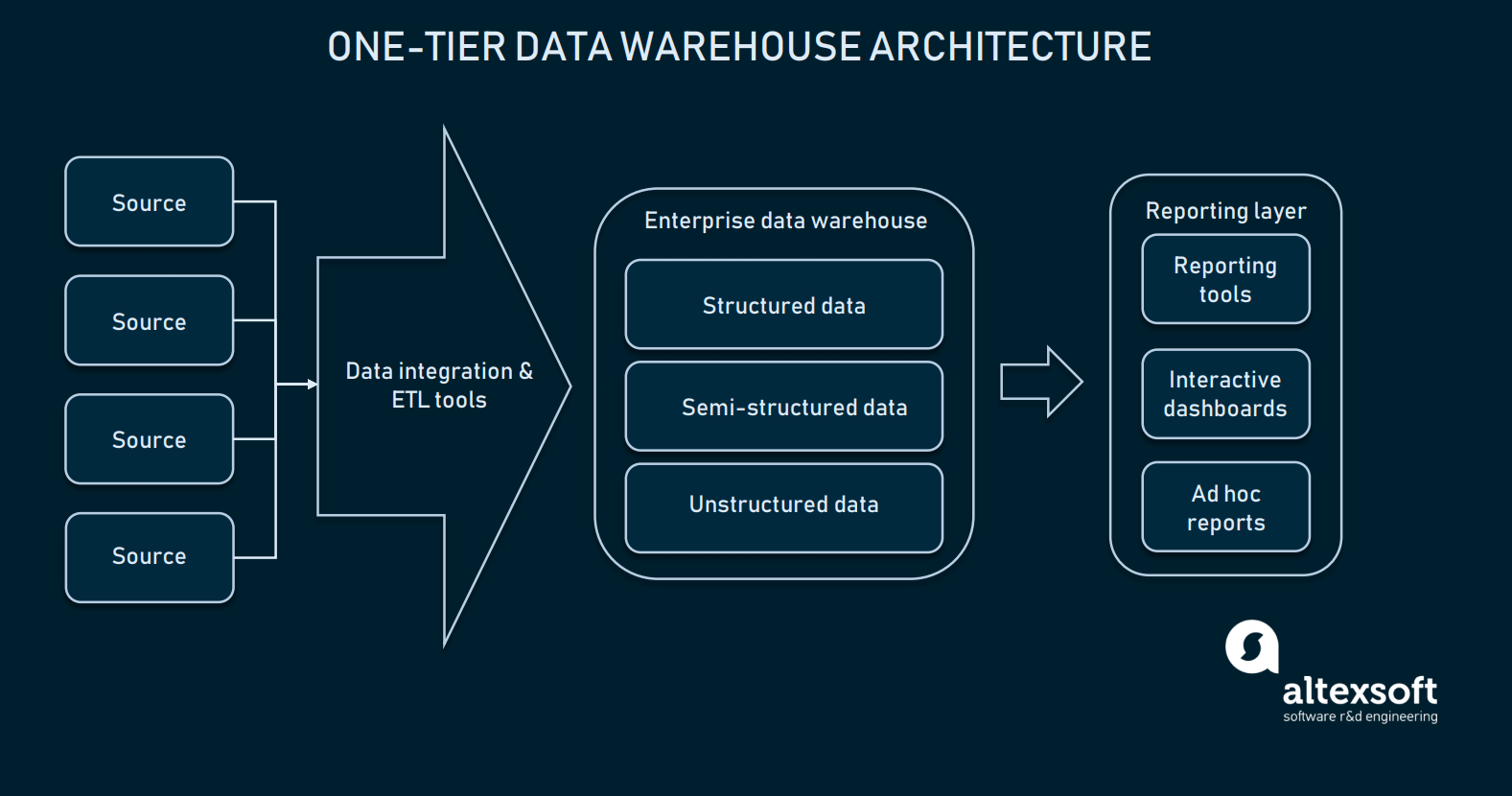
Rapporteringslagret är direkt kopplat till hela EDW-databasen
En arkitektur med ett lager för EDW innebär att du har en databas som är direkt kopplad till analysgränssnitten där slutanvändaren kan göra förfrågningar. Att ställa in den direkta anslutningen mellan en EDW och analytiska verktyg medför flera utmaningar:
- Traditionellt sett kan du betrakta din lagring som ett lager från och med 100 GB data. Att arbeta med det direkt kan resultera i röriga frågeresultat samt låg bearbetningshastighet.
- För att söka data direkt från DW kan det krävas exakt inmatning, så att systemet kan filtrera bort data som inte behövs. Vilket gör det lite svårt att hantera presentationsverktyg.
- Begränsad flexibilitet/analytiska möjligheter finns.
Den enstegsarkitekturen sätter dessutom vissa gränser för rapporteringskomplexiteten. Ett sådant tillvägagångssätt används sällan för storskaliga dataplattformar på grund av dess långsamhet och oförutsägbarhet. För att utföra avancerade dataförfrågningar kan ett lager utökas med instanser på låg nivå som underlättar åtkomsten till data.
Två-nivåarkitektur (data mart-skikt)
I två-nivåarkitektur läggs en data mart-nivå till mellan användargränssnittet och EDW. En datamart är ett arkiv på låg nivå som innehåller domänspecifik information. Enkelt uttryckt är det en annan, mindre databas som utökar EDW med dedikerad information för dina försäljnings-/driftsavdelningar, marknadsföring etc.
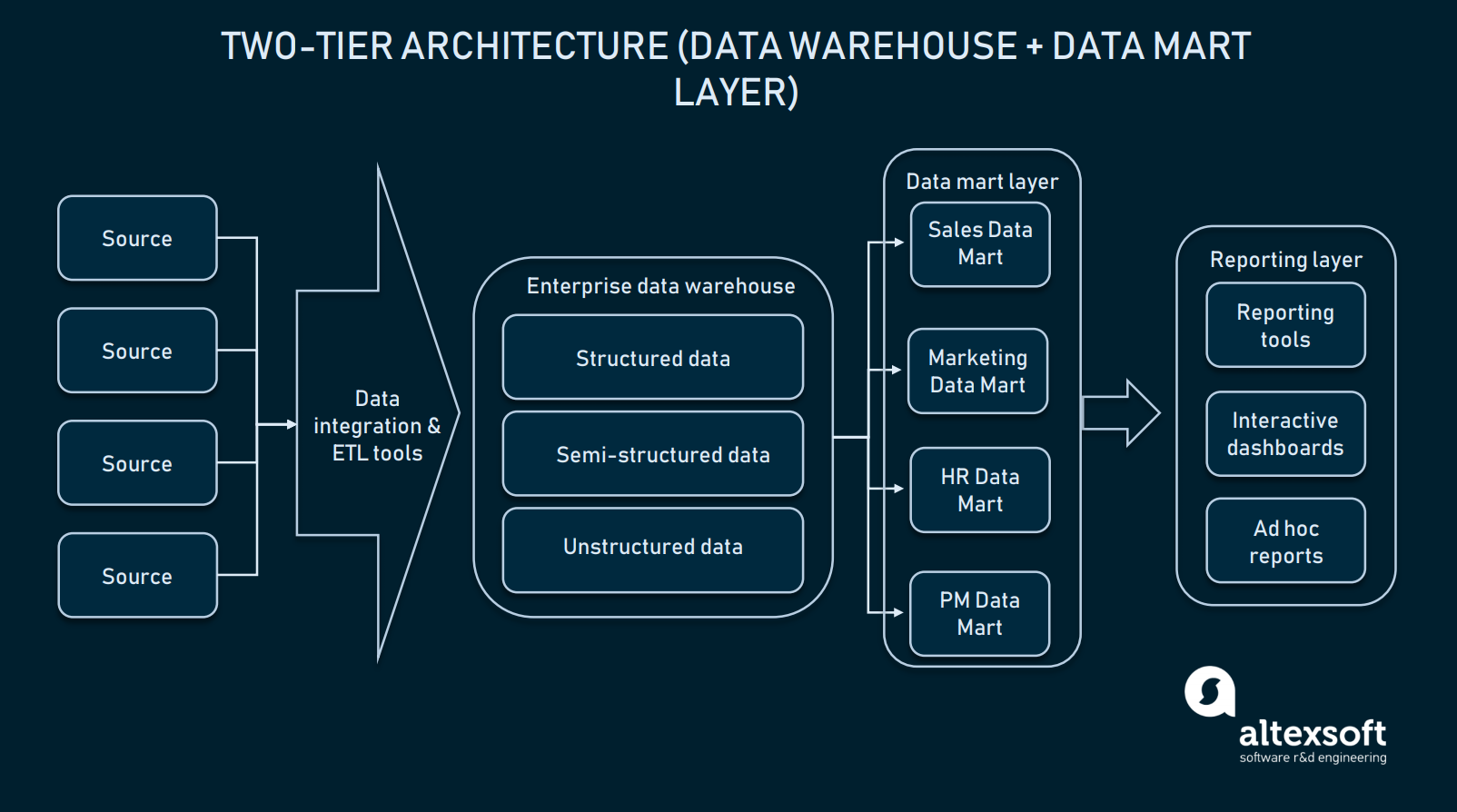
I en tvåstegsarkitektur utökas en EDW med datamarts för att tillhandahålla domänspecifika data
Skapandet av ett datamartsskikt kommer att kräva ytterligare resurser för att etablera hårdvara och integrera dessa databaser med resten av dataplattformen. Men ett sådant tillvägagångssätt löser problemet med sökning: Varje avdelning kommer att få tillgång till nödvändiga uppgifter lättare eftersom en viss mart endast innehåller domänspecifik information. Dessutom kommer datamarts att begränsa tillgången till data för slutanvändare, vilket gör EDW säkrare.
Trippelarkitektur (Online analytical processing)
Ovanpå datamartsskiktet använder företagen också kuber för online analytical processing (OLAP). En OLAP-kub är en särskild typ av databas som representerar data från flera dimensioner. Medan relationsdatabaser representerar data i endast två dimensioner (tänk Excel eller Google Sheets), gör OLAP det möjligt att sammanställa data i flera dimensioner och flytta mellan dimensioner.
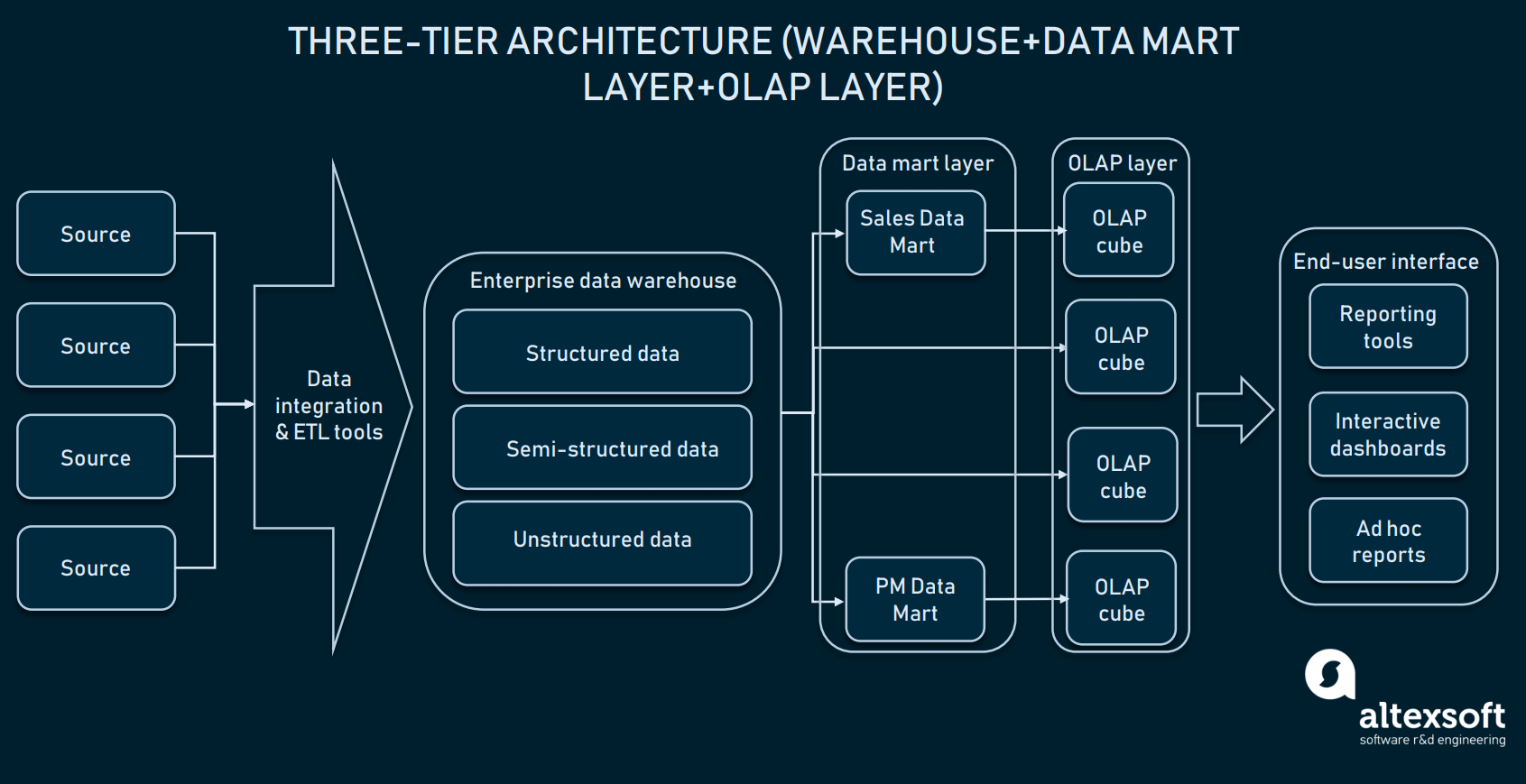
OLAP-kuber skiktet kan hämta information från distribuerade marts eller direkt från EDW
Det är ganska svårt att förklara i ord, så låt oss titta på detta praktiska exempel på hur en kub kan se ut.
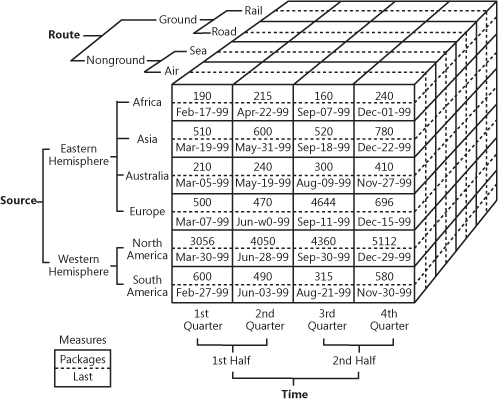
OLAP-kuber som visar multidimensionella försäljningsdata
Källa: oreilly.com
Så som du kan se lägger en kub till dimensioner till data. Du kan tänka dig det som flera Excel-tabeller som kombineras med varandra. Kubens framsida är den vanliga tvådimensionella tabellen, där region (Afrika, Asien osv.) anges vertikalt, medan försäljningssiffror och datum skrivs horisontellt. Magin börjar när vi tittar på kubens övre facett, där försäljningen segmenteras efter rutter och den nedre specificerar tidsperiod. Detta kallas multidimensionella data.
Det affärsmässiga värdet av OLAP är att användarna kan dela upp data för att sammanställa detaljerade rapporter. Så länge kuberna är optimerade för att fungera med lager kan de användas både direkt med en EDW för att ge tillgång till alla företagsdata eller med varje data mart specifikt. När det gäller genomförandet erbjuder nästan alla lagerleverantörer OLAP som en tjänst. Som exempel kan du kontrollera Microsofts dokumentation om deras OLAP-erbjudande.
På den punkten har vi diskuterat en högnivåkonstruktion av en EDW som tillämpas på organisatoriska behov. Nu ska vi borra ner till tekniska komponenter som ett lager kan innehålla.
Data Warehouse vs Data Lake vs Data Mart
På tal om datalagringsarkitektur måste vi nämna sådana alternativ som att använda en data mart eller en data lake istället för ett lager. Eftersom de ofta blandas ihop ska vi utveckla definitionerna.
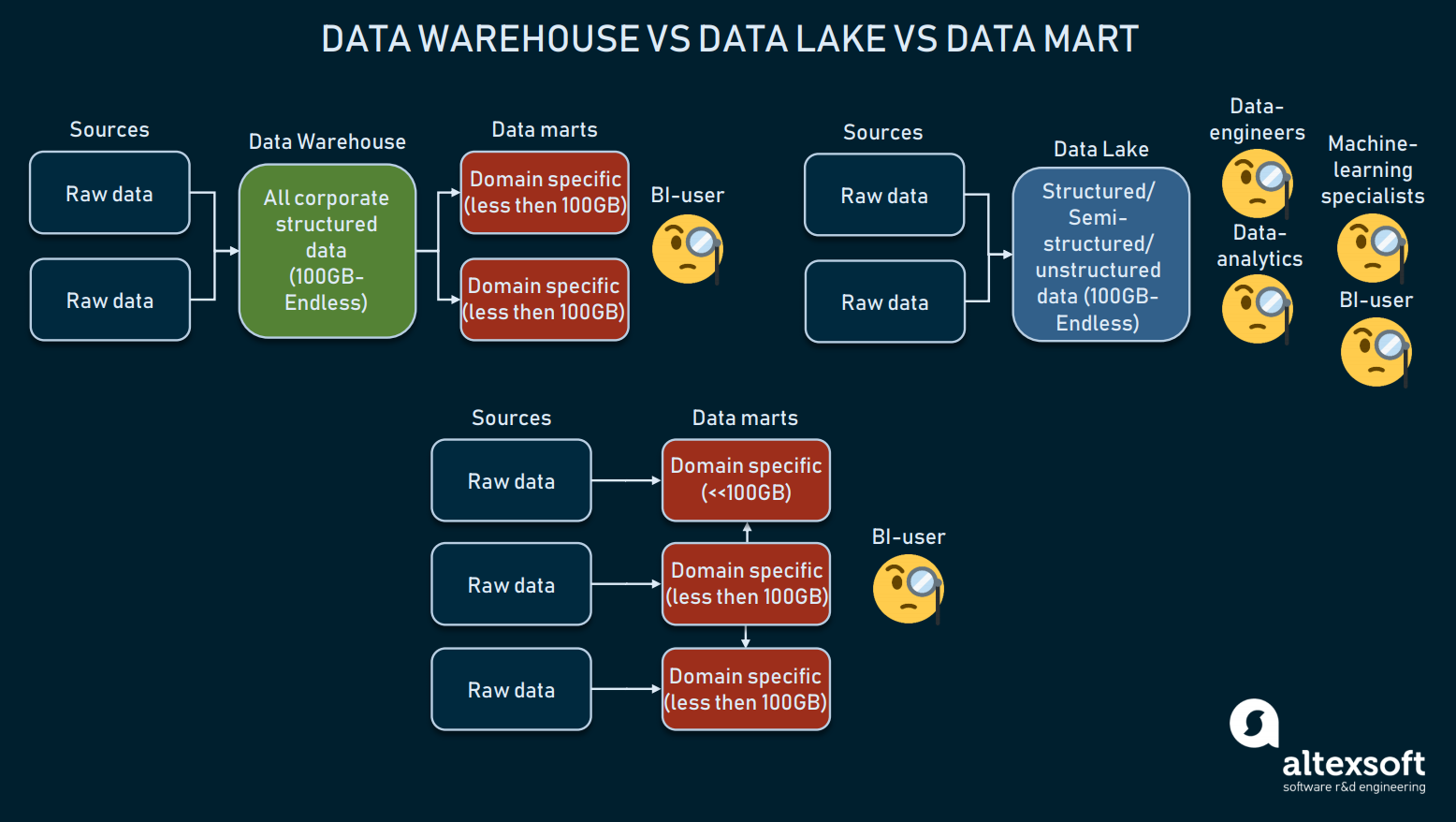
Förhållandet mellan tre former av datalagring
Data warehouses är avsedda att lagra strukturerade data, så att sökverktyg och slutanvändare kan få omfattande resultat. Lagren, som främst används för BI, varierar vanligtvis i storlek mellan 100 GB och oändligt.
Datasjöar däremot används för att lagra mestadels råa eller blandade data. Dessa används ofta för maskininlärning, stora data eller datautvinning. Under de senaste åren har datasjöar använts för BI: Rådata laddas in i en sjö och omvandlas, vilket är ett alternativ till ETL-processen. Även om detta tillvägagångssätt har sina för- och nackdelar kan datasjöar vara för röriga för att nå strukturerade data.
Därefter har vi datamarkörer, som också kan användas som ett alternativ till DW. Sådana modeller (som Kimballs modell) förutsätter att man använder flera datamarkörer för att distribuera information efter domäner och ansluta till varandra. Men på grund av deras ringa storlek (vanligtvis mindre än 100 GB) kan datamarkörer knappast användas av företag. Oftare används datamarkörer för att segmentera en stor datalagringsplattform i mer driftskompatibla sådana.
Enterprise Data Warehouse Components
Det finns en hel del instrument som används för att inrätta en lagerplattform. Vi har redan nämnt de flesta av dem, inklusive själva lagret. Så låt oss få en fågelperspektiv på syftet med varje komponent och deras funktioner.
Källor. Det är enkelt, databaserna där rådata lagras.
Extract, Transform, Load (ETL) eller Extract, Load, Transform (ELT) layer. Detta är de verktyg som utför den faktiska anslutningen till källdata, dess extraktion och laddning till den plats där den ska omvandlas. Transformationen förenhetligar dataformatet. ETL- och ELT-strategierna skiljer sig åt på så sätt att omvandlingen i ETL sker före EDW, i en staging area. ELT är ett modernare tillvägagångssätt som hanterar all omvandling i ett lager.
Staging area. Vid ETL är staging area den plats där data laddas in före EDW. Här rensas den och transformeras till en given datamodell. Stagingområdet kan också innehålla verktyg för hantering av datakvalitet.
DW-databas. Uppgifterna laddas slutligen in i lagringsutrymmet. I ELT kan det fortfarande krävas en viss omvandling här. Men i det skedet kommer alla allmänna ändringar att tillämpas, så att uppgifterna laddas in i sin(a) slutliga modell(er). Som vi nämnde är datalager oftast relationsdatabaser. DW kommer också att innehålla ett databashanteringssystem och ytterligare lagring för metadata.
Metadatamodul. Enkelt uttryckt är metadata data om data. Det är förklaringar som ger tips för användare/administratörer om vilket ämne/domän denna information avser. Dessa uppgifter kan vara tekniska metadata (t.ex. ursprunglig källa) eller affärsmetadata (t.ex. försäljningsregion). Alla metadata lagras i en separat modul i EDW och hanteras av en metadatahanterare.
Rapporteringslager. Detta är verktyg som ger slutanvändare tillgång till data. Det här lagret, som också kallas BI-gränssnitt, fungerar som en instrumentpanel för att visualisera data, skapa rapporter och hämta separat information.
Sluttanke
En förståelse för kedjan av verktyg som skickar data vidare kan hjälpa dig att ta reda på vad som faktiskt passar dina krav på dataplattformen. Att planera för att inrätta ett lager kan ta flera år av planering och testning, på grund av omfattningen av det i sin mest grundläggande form.
Som företagare kan du bli förvirrad av antalet alternativ och tekniker som används, så det är viktigt att rådgöra med experter inom området för lagring, ETL och BI. Experterna kan hjälpa dig med den tekniska aspekten, men för att definiera affärssyftet bör du tala med dem som kommer att använda de faktiska uppgifterna i sitt arbete.