




Hur bra är opinionsundersökarna? Analys av Five-Thirty-Eights dataset
Vi analyserar datasetetet för rankning av opinionsundersökare från den anrika webbplatsen för politiska förutsägelser Five-Thirty-Eight.

Detta är ett valår och opinionsundersökningarna kring valen (både presidentvalet och valet till representanthuset och senaten) är mycket intensiva. Detta kommer att bli mer och mer spännande under de kommande dagarna, med tweets, mot-tweets, slagsmål i sociala medier och oändliga punditry på tv.
Vi vet att alla opinionsundersökningar inte är av samma kvalitet. Så hur ska man göra för att förstå det hela? Hur identifierar man pålitliga opinionsundersökare med hjälp av data och analyser?

I en värld av politiska (och vissa andra frågor som sport, sociala fenomen, ekonomi etc.) prognostiska analyser är Five-Thirty-Eight ett formidabelt namn.
Sedan början av 2008 har sajten publicerat artiklar – vanligtvis genom att skapa eller analysera statistisk information – om ett stort antal olika ämnen inom aktuell politik och politiska nyheter. Webbplatsen, som drivs av rockstjärnans datavetare och statistiker Nate Silver, blev särskilt framträdande och allmänt känd kring presidentvalet 2012 när dess modell korrekt förutspådde vinnaren i alla 50 delstater och District of Columbia.
Och innan du hånar dig själv och säger ”Men hur var det med valet 2016?”, kan det vara bra att läsa den här artikeln om hur valet av Donald Trump låg inom den normala felmarginalen för statistisk modellering.
För de mer politiskt nyfikna läsarna har de en hel väska med artiklar om valet 2016 här.
Data science-utövare borde tycka om Five-Thirty-Eight eftersom de inte drar sig för att förklara sina prediktionsmodeller i mycket tekniska termer (åtminstone tillräckligt komplexa för lekmän).

Men utöver användningen av sofistikerade statistiska modelleringstekniker är Silvers team stolt över en unik metodik – pollster rating – som hjälper deras modeller att förbli mycket exakta och pålitliga.
I den här artikeln analyserar vi deras data om dessa betygsmetoder.
Five-Thirty-Eight drar sig inte för att förklara sina prediktiva modeller i termer av mycket tekniska termer (åtminstone komplexa nog för lekmän).
Pollster rating and ranking
Det finns en mängd opinionsundersökningsinstitut som är verksamma i det här landet. Att läsa och bedöma kvaliteten på dem kan vara mycket påfrestande och bråkigt. Enligt webbplatsen kan det vara farligt för hälsan att läsa opinionsundersökningar. Symtomen omfattar körsbärsplockning, överdrivet självförtroende, att falla för skräpiga siffror och att döma förhastat. Tack och lov har vi ett botemedel.” (källa)
Det finns opinionsundersökningar. Sedan finns det opinionsundersökningar av opinionsundersökningar. Sedan finns det viktade opinionsundersökningar av opinionsundersökningar. Framför allt finns det en omröstning av omröstningar med vikter som är statistiskt modellerade och dynamiskt förändrade vikter.
Låter det bekant med andra kända rankningsmetoder som du har hört talas om som datavetare? Amazons produktranking eller Netflix filmranking? Förmodligen, ja.
I huvudsak använder Five-Thirty-Eight detta betygs-/rankningssystem för att vikta opinionsundersökningsresultaten (högt rankade opinionsundersökningars resultat ges större betydelse och så och så). De följer också aktivt noggrannheten och metoderna bakom varje opinionsundersökares resultat och justerar sin rangordning under året.
Det finns opinionsundersökningar. Sedan finns det opinionsundersökningar av opinionsundersökningar. Sedan finns det viktade opinionsundersökningar av opinionsundersökningar. Framför allt finns det opinionsundersökningar av opinionsundersökningar med vikter som är statistiskt modellerade och dynamiskt förändrade vikter.
Det är intressant att notera att deras rangordningsmetodik inte nödvändigtvis värderar en opinionsundersökare med ett större urval som en bättre opinionsundersökare. Följande skärmdump från deras webbplats visar det tydligt. Även om undersökningsinstitut som Rasmussen Reports och HarrisX har större urvalsstorlekar är det i själva verket Marist College som får betyget A+ med en blygsam urvalsstorlek.
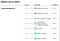
Tyvärr har de också en öppen källkod för sina rankningsdata (tillsammans med nästan alla andra dataset) här på Github. Och om du bara är intresserad av en snygg tabell så finns den här.
Naturligtvis kan du som datavetare vilja titta djupare i rådata och förstå saker som,
- hur deras numeriska rangordning korrelerar med hur noggranna opinionsundersökarna är
- om de har en partisk bias mot att välja vissa opinionsundersökare (i de flesta fall kan de kategoriseras som antingen demokratiskt eller republikanskt orienterade)
- vilka opinionsundersökare är de högst rankade? Genomför de många undersökningar eller är de selektiva?
Vi försökte analysera datasetet för att få sådana insikter. Låt oss gräva i koden och resultaten, ska vi?
Analysen
Du kan hitta Jupyter Notebook här på min Github-repo.
Källan
För att börja kan du hämta data direkt från deras Github, till ett Pandas DataFrame, enligt följande,

Det finns 23 kolumner i detta dataset. Så här ser de ut,

En del omvandling och upprensning
Vi noterar att en kolumn har lite extra utrymme. Några andra kan behöva lite extraktion och datatypkonvertering.



Efter att ha tillämpat detta utdrag, har det nya dataframmet ytterligare kolumner, vilket gör det mer lämpligt för filtrering och statistisk modellering.

Undersökning och kvantifiering av kolumnen ”538 Grade”
Kolumnen ”538 Grades” innehåller datamängdens kärna – bokstavsbetyget för opinionsundersökaren. Precis som vid ett vanligt prov är A+ bättre än A och A bättre än B+. Om vi plottar in antalet bokstavsbetyg observerar vi totalt 15 graderingar, från A+ till F.

Istället för att arbeta med så många kategoriska graderingar kan vi kanske kombinera dem till ett fåtal numeriska betyg – 4 för A+/A/A/A-, 3 för B:orna, osv.

Boxplots
Om vi går in på visuell analys kan vi börja med boxplots.
Förutsatt att vi vill kontrollera vilken omröstningsmetod som presterar bäst när det gäller prognosfel. Datasetet har en kolumn som heter ”Simple Average Error” (enkelt genomsnittligt fel), som definieras som ”Företagets genomsnittliga fel, beräknat som skillnaden mellan det avvägda resultatet och det faktiska resultatet för den marginal som skiljer de två främsta i loppet åt”.”

Då kan vi vara intresserade av att kontrollera om opinionsundersökningsinstitut med en viss partipolitisk fördomsfullhet är mer framgångsrika i att kalla valen rätt än andra.

Märker du något intressant ovan? Om du är en progressiv, liberal tänkare kan du med största sannolikhet vara partipolitiskt ansluten till det demokratiska partiet. Men i genomsnitt kallar opinionsundersökarna med republikansk inriktning valen mer korrekt och med mindre variationer. Det är bättre att se upp för dessa opinionsundersökningar!
En annan intressant kolumn i datasetet heter ”NCPP/AAPOR/Roper”. Den ”anger om undersökningsföretaget var medlem i National Council on Public Polls, undertecknade American Association for Public Opinion Researchs initiativ för öppenhet eller bidrog till Roper Center for Public Opinion Researchs dataarkiv. Ett medlemskap indikerar i praktiken att man följer en mer robust metodik för opinionsundersökningar” (källa).
Hur bedömer man giltigheten i det ovannämnda påståendet? Datasetet har en kolumn som heter ”Advanced Plus-Minus”, vilket är ”en poäng som jämför ett opinionsundersökningsbolags resultat med andra opinionsundersökningsföretag som undersöker samma lopp och som väger de senaste resultaten tyngre. Negativa poäng är gynnsamma och indikerar en kvalitet över genomsnittet” (källa).
Här finns en boxplot mellan dessa två parametrar. Det är inte bara de opinionsinstitut som är associerade med NCCP/AAPOR/Roper som uppvisar en lägre felmarginal, utan de uppvisar också en betydligt lägre variabilitet. Deras förutsägelser verkar vara stabila och robusta.

Om du är en progressiv, liberal tänkare kan du med största sannolikhet vara partisk till det demokratiska partiet. Men i genomsnitt kallar opinionsundersökarna med republikansk inriktning valen mer korrekt och med mindre variabilitet.
Spridnings- och regressionsdiagram
För att förstå korrelationen mellan parametrarna kan vi titta på spridningsdiagrammen med regressionsanpassning. Vi använder biblioteken Seaborn och Scipy Python och en anpassad funktion för att generera dessa plottar.
Till exempel kan vi relatera ”Races Called Correctly” till ”Predictive Plus-Minus”. Enligt Five-Thirty-Eight är ”Predictive Plus-Minus” ”en prognos för hur exakt opinionsundersökaren kommer att vara i framtida val”. Det beräknas genom att återföra en opinionsundersökares avancerade Plus-Minus-poäng till ett medelvärde baserat på våra proxies för metodologisk kvalitet”. (källa)

Och vi kan kontrollera hur det ”numeriska betyget” som vi definierat, korrelerar med genomsnittet för fel i opinionsundersökningar. En negativ trend visar att en högre numerisk grad är förknippad med ett lägre röstningsfel.

Vi kan också kontrollera om ”Antal opinionsundersökningar för bias-analys” hjälper till att minska den ”Partisan Bias Degree” som tilldelas varje opinionsundersökare. Vi kan observera ett nedåtgående samband, vilket tyder på att tillgången till ett stort antal opinionsundersökningar bidrar till att minska graden av partiskhet. Förhållandet ser dock mycket olinjärt ut och en logaritmisk skalning hade varit bättre för att passa in på kurvan.

Ska man lita mer på mer aktiva opinionsundersökningsinstitut? Vi ritar upp histogrammet över antalet opinionsundersökningar och ser att det följer en negativ potenslag. Vi kan filtrera bort de opinionsundersökare som har både ett mycket lågt och ett mycket högt antal opinionsundersökningar och skapa ett anpassat spridningsdiagram. Vi observerar dock en nästan obefintlig korrelation mellan antalet opinionsundersökningar och den prediktiva plus-minuspoängen. Därför leder ett stort antal opinionsundersökningar inte nödvändigtvis till hög kvalitet på opinionsundersökningar och prediktiv förmåga.