




Introduktion till databasdesign
Identifiera attribut
De dataelement som du vill spara för varje enhet kallas ”attribut”.
När det gäller de produkter som du säljer vill du till exempel veta vad priset är, vad tillverkaren heter och vad typnumret är. Om kunderna vet du deras kundnummer, deras namn och adress. Om butikerna känner du till lokalkod, namn och adress. Om försäljningen vet du när den ägde rum, i vilken butik, vilka produkter som såldes och hur stor summan av försäljningen var. Om säljaren vet du hans personalnummer, namn och adress. Vad som kommer att inkluderas exakt är inte viktigt ännu; det handlar fortfarande bara om vad du vill spara.
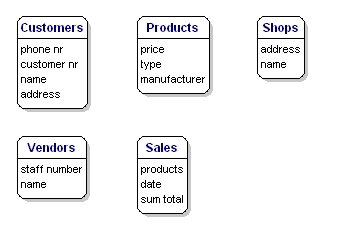
Figur 6: Enheter med attribut.
Avledda data
Avledda data är data som härrör från andra data som du redan har sparat. I det här fallet är ”totalsumman” ett klassiskt fall av härledda data. Du vet exakt vad som har sålts och vad varje produkt kostar, så du kan alltid beräkna hur mycket summan av försäljningen är. Det är alltså egentligen inte nödvändigt att spara totalsumman.
Varför sparas den då här? Jo, för att det är en försäljning och priset på produkten kan variera över tiden. En produkt kan kosta 10 euro i dag och 8 euro nästa månad, och för din administration behöver du veta vad den kostade vid tidpunkten för försäljningen, och det enklaste sättet att göra det är att spara det här. Det finns många mer eleganta sätt, men de är för djupgående för den här artikeln.
Presentera enheter och relationer: Entitetsrelationsdiagram (ERD)
Entitetsrelationsdiagrammet (ERD) ger en grafisk översikt över databasen. Det finns flera olika stilar och typer av ER-diagram. En mycket använd notation är ”crowfeet”-notationen, där enheter representeras som rektanglar och relationerna mellan enheterna representeras som linjer mellan enheterna. Tecknen i slutet av linjerna anger vilken typ av relation det rör sig om. Den sida av förhållandet som är obligatorisk för att den andra ska existera anges med ett streck på linjen. Enheter som inte är obligatoriska anges med en cirkel. ”Många” indikeras genom en ”kråkfötter”; relationslinjen delas upp i tre linjer.
I den här artikeln använder vi oss av DeZign for Databases för att utforma och presentera vår databas.
En obligatorisk 1:1-relation representeras på följande sätt:
Figur 7: Obligatorisk en till en-relation.
En obligatorisk 1:N-relation:
Figur 8: Obligatorisk en till många-relation.
En M:N-relation är:
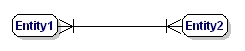
Figur 9: Obligatorisk många till många-relation.
Modellen för vårt exempel kommer att se ut så här:
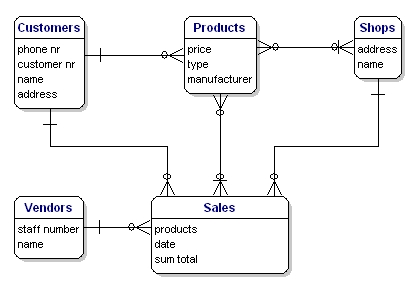
Figur 10: Modell med relationer.
Ansättning av nycklar
Primärnycklar
En primärnyckel (PK) är ett eller flera dataattribut som unikt identifierar en enhet. En nyckel som består av två eller flera attribut kallas en sammansatt nyckel. Alla attribut som ingår i en primärnyckel måste ha ett värde i varje post (som inte kan lämnas tomt) och kombinationen av värdena inom dessa attribut måste vara unik i tabellen.
I exemplet finns det några uppenbara kandidater för primärnyckeln. Alla kunder har ett kundnummer, alla produkter har ett unikt produktnummer och försäljningen har ett försäljningsnummer. Var och en av dessa uppgifter är unik och varje post kommer att innehålla ett värde, så dessa attribut kan vara en primärnyckel. Ofta används en heltalskolumn för primärnyckeln så att en post lätt kan hittas genom sitt nummer.
Länk-enheter hänvisar vanligtvis till primärnyckelattributen för de enheter som de länkar. Den primära nyckeln för en länk-enhet är vanligtvis en samling av dessa referensattribut. I entiteten Sales_details kan vi till exempel använda kombinationen av PK:erna för entiteterna sales och products som PK för Sales_details. På detta sätt kan vi se till att samma produkt (typ) endast kan användas en gång i samma försäljning. Flera artiklar av samma produkttyp i en försäljning måste anges genom kvantiteten.
I ERD anges primärnyckelattributen med texten ”PK” bakom attributets namn. I exemplet är det bara enheten ”shop” som inte har någon uppenbar kandidat för PK, så vi kommer att införa ett nytt attribut för den enheten: shopnr.
Förändringsnycklar
Förändringsnyckeln (Foreign Key, FK) i en enhet är referensen till primärnyckeln i en annan enhet. I ERD anges attributet med ”FK” bakom namnet. Den främmande nyckeln i en enhet kan också vara en del av den primära nyckeln, i så fall anges attributet med ”PF” bakom namnet. Detta är vanligtvis fallet med länk-entiteter, eftersom man vanligtvis länkar två instanser endast en gång tillsammans (med 1 försäljning säljs endast 1 produkttyp 1 gång).
Om vi lägger in alla länk-entiteter, PK:s och FK:s i ERD:n får vi modellen som visas nedan. Observera att attributet ”products” inte längre behövs i ”Sales”, eftersom ”sold products” nu ingår i länktabellen. I länktabellen har ytterligare ett fält lagts till, ”quantity”, som anger hur många produkter som sålts. Fältet kvantitet har också lagts till i lagertabellen för att ange hur många produkter som fortfarande finns i lager.
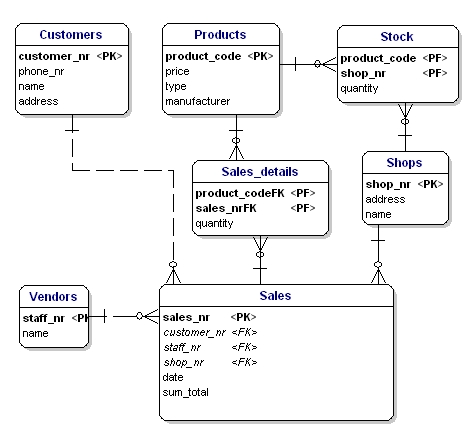
Figur 11: Primärnycklar och främmande nycklar.
Definiera attributens datatyp
Nu är det dags att ta reda på vilka datatyper som behöver användas för attributen. Det finns många olika datatyper. Några är standardiserade, men många databaser har egna datatyper som alla har sina egna fördelar. Vissa databaser erbjuder möjligheten att definiera egna datatyper, om standardtyperna inte kan göra det du behöver.
De standarddatatyper som alla databaser känner till och som används mest är: CHAR, VARCHAR, TEXT, FLOAT, DOUBLE och INT.
Text:
- CHAR(length) – innehåller text (tecken, siffror, interpunktioner…). CHAR har som egenskap att den alltid sparar ett fast antal positioner. Om du definierar CHAR(10) kan du spara högst tio positioner, men om du bara använder två positioner kommer databasen ändå att spara 10 positioner. De återstående åtta positionerna kommer att fyllas av mellanslag.
- VARCHAR(length) – innehåller text (tecken, siffror, interpunktion…). VARCHAR är samma sak som CHAR, skillnaden är att VARCHAR bara tar så mycket utrymme som behövs.
- TEXT – kan innehålla stora mängder text. Beroende på typ av databas kan detta uppgå till gigabyte.
Nummer:
- INT – innehåller ett positivt eller negativt heltal. Många databaser har varianter av INT, till exempel TINYINT, SMALLINT, MEDIUMINT, BIGINT, INT2, INT4, INT8. Dessa varianter skiljer sig från INT endast genom storleken på det tal som ryms i den. Ett vanligt INT är 4 bytes (INT4) och passar siffror från -2147483647 till +2147483646, eller om du definierar det som UNSIGNED från 0 till 4294967296. INT8, eller BIGINT, kan bli ännu större i storlek, från 0 till 18446744073709551616, men tar upp till 8 byte diskutrymme, även om det bara finns ett litet tal i det.
- FLOAT, DOUBLE – Samma idé som INT, men kan också lagra flyttalstal. . Observera att detta inte alltid fungerar perfekt. Till exempel i MySQL är det inte perfekt att beräkna med dessa flyttal, (1/3)*3 kommer med MySQL:s flyttal att resultera i 0,999999999, inte 1.
Andra typer:
- BLOB – för binära data, t.ex. filer.
- INET – för IP-adresser. Kan även användas för nätmasker.
För vårt exempel är datatyperna följande:
Figur 12: Datamodell som visar datatyper.
Normalisering
Normalisering gör din datamodell flexibel och tillförlitlig. Det genererar en del overhead eftersom du vanligtvis får fler tabeller, men det gör att du kan göra många saker med din datamodell utan att behöva justera den. Du kan läsa mer om databasnormalisering i den här artikeln.
Normalisering, den första formen
Den första formen av normalisering anger att det inte får finnas några upprepande grupper av kolumner i en enhet. Vi kunde ha skapat en entitet ”försäljning” med attribut för varje produkt som köptes. Detta skulle se ut så här:

Figur 13: Inte i första normalformen.
Det som är fel med detta är att nu kan endast tre produkter säljas. Om du skulle behöva sälja 4 produkter måste du starta en andra försäljning eller justera din datamodell genom att lägga till attribut ”product4”. Båda lösningarna är oönskade. I dessa fall bör du alltid skapa en ny enhet som du kopplar till den gamla enheten via en one-to-many-relation.
Figur 14: I enlighet med första normalformen.
Normalisering, den andra formen
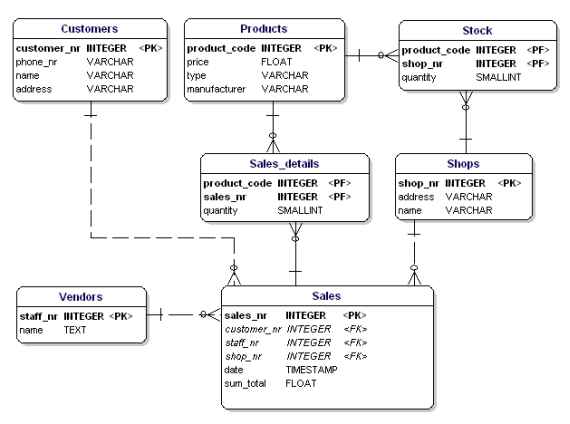
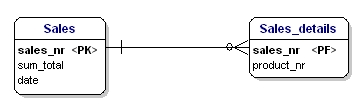
Den andra formen av normalisering anger att alla attribut för en entitet ska vara helt beroende av hela primärnyckeln. Detta innebär att varje attribut för en enhet endast kan identifieras genom hela primärnyckeln. Anta att vi hade datumet i entiteten Sales_details:

Figur 15: Inte i 2:a normalformen.
Denna entitet är inte enligt den andra normaliseringsformen, för för att kunna slå upp datumet för en försäljning behöver jag inte veta vad som sålts (productnr), det enda jag behöver veta är försäljningsnumret. Detta löstes genom att dela upp tabellerna i tabellerna Sales och Sales_details:
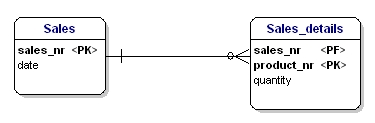
Figur 16: I enlighet med den andra normalformen.
Nu är varje attribut i enheterna beroende av hela PK för enheten. Datumet är beroende av försäljningsnumret, och kvantiteten är beroende av försäljningsnumret och den sålda produkten.
Normalisering, den tredje formen
Den tredje formen av normalisering anger att alla attribut måste vara direkt beroende av primärnyckeln och inte av andra attribut. Detta verkar vara vad den andra formen av normalisering anger, men i den andra formen anges faktiskt motsatsen. I den andra normaliseringsformen pekar man ut attribut genom PK, i den tredje normaliseringsformen måste alla attribut vara beroende av PK, och inget annat.

Figur 17: Inte i tredje normalformen.
I detta fall är priset på en lös produkt beroende av beställningsnumret, och beställningsnumret är beroende av produktnumret och försäljningsnumret. Detta är inte enligt den tredje normaliseringsformen. Återigen löser en uppdelning av tabellerna detta.
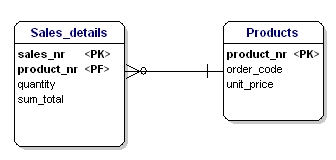
Figur 18: I enlighet med den tredje normalformen.
Normalisering, fler former
Det finns fler normaliseringsformer än de tre formerna som nämnts ovan, men dessa är inte av stort intresse för den genomsnittlige användaren. Dessa andra former är mycket specialiserade för vissa tillämpningar. Om du håller dig till designreglerna och den normalisering som nämns i den här artikeln kommer du att skapa en design som fungerar utmärkt för de flesta tillämpningar.
Normaliserad datamodell
Om du tillämpar normaliseringsreglerna kommer du att upptäcka att ”tillverkaren” i produkttabellen också bör vara en separat tabell:
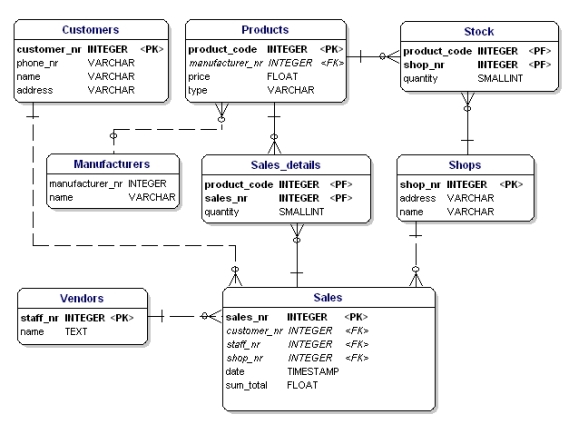
Figur 19: Datamodell enligt första, andra och tredje normalformen.