




Lär dig Regex: En nybörjarguide'
I den här guiden lär du dig regex, syntaxen för reguljära uttryck. I slutet kommer du att kunna tillämpa regex-lösningar i de flesta scenarier som kräver det i ditt arbete med webbutveckling.
Reguljära uttryck har många användningsområden, bland annat:
- validering av formulärinmatning
- webbskrapning
- sökning och ersättning
- filtrering av information i massiva textfiler, t.ex. loggfiler
Reguljära uttryck, eller regex som de vanligen kallas, ser komplicerade och skrämmande ut för nya användare. Ta en titt på det här exemplet:
/^+@+(?:\.+)*$/Det ser bara ut som förvrängd text. Men misströsta inte, det finns en metod bakom detta vansinne.

Credit: xkcd
Jag ska visa dig hur du behärskar reguljära uttryck på nolltid. Låt oss först klargöra den terminologi som används i den här guiden:
- mönster: mönster för reguljära uttryck
- sträng: teststräng som används för att matcha mönstret
- siffra: 0-9
- bokstav: a-z, A-Z
- symbol: !$%^&*()_+|~-=`{}:”;'<>?,./
- mellanslag: enkelt vitrymd, tabb
- tecken: hänvisar till en bokstav, siffra eller symbol
Basics
Om du vill lära dig regex snabbt med den här guiden kan du besöka Regex101, där du kan bygga regexmönster och testa dem mot strängar (text) som du anger.
När du öppnar webbplatsen måste du välja JavaScript-smaken, eftersom det är den vi kommer att använda i den här guiden. (Regex-syntaxen är i stort sett densamma för alla språk, men det finns några mindre skillnader.)
Nästan måste du inaktivera flaggorna global och multi line i Regex101. Vi kommer att behandla dem i nästa avsnitt. För tillfället tittar vi på den enklaste formen av reguljära uttryck som vi kan bygga. Ange följande:
- regex inmatningsfält: cat
- teststräng: rat bat cat sat fat cats eat tat cat mat CAT
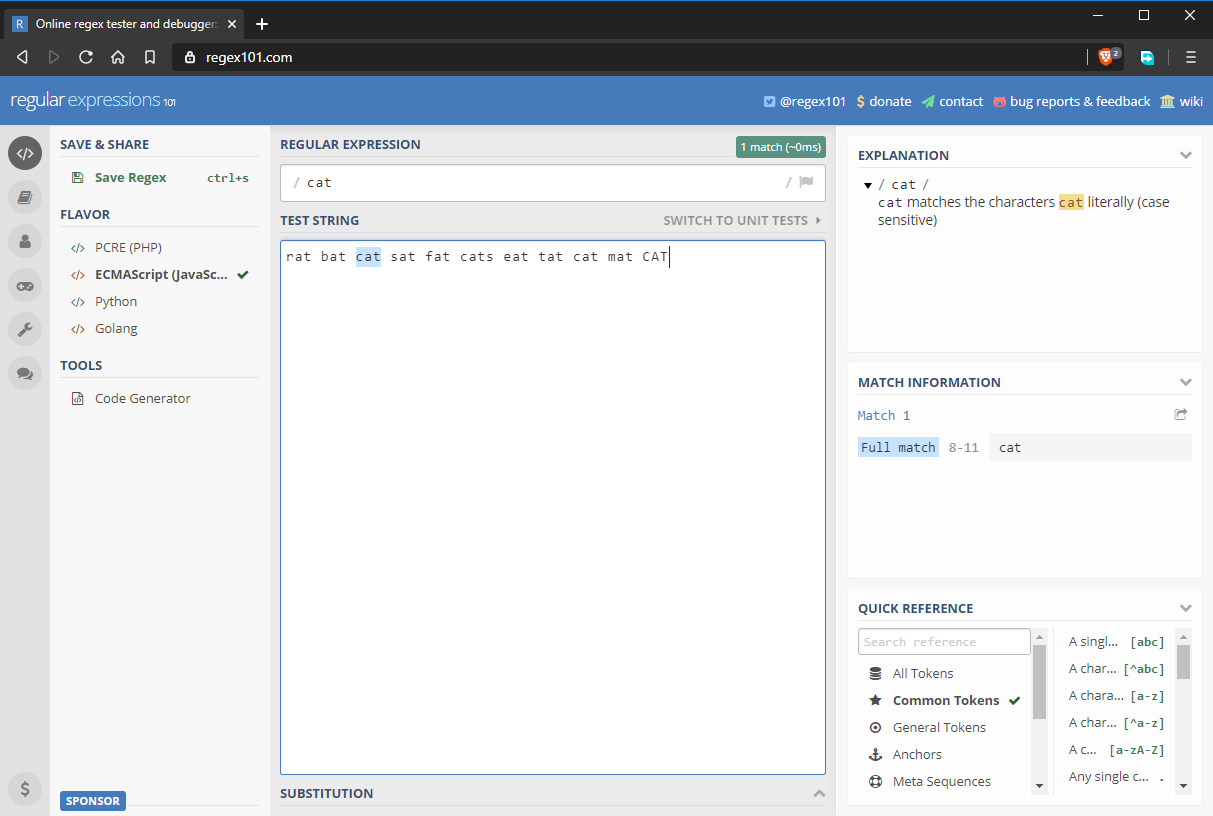
Tänk på att reguljära uttryck i JavaScript börjar och slutar med /. Om du skulle skriva ett reguljärt uttryck i JavaScript-kod skulle det se ut så här: /cat/ utan citationstecken. I tillståndet ovan matchar det reguljära uttrycket strängen ”cat”. Som du kan se i bilden ovan finns det dock flera ”cat”-strängar som inte matchas. I nästa avsnitt tittar vi på varför.
Globala och Case Insensitive Regex Flags
Som standard returnerar ett regexmönster endast den första matchningen det hittar. Om du vill returnera ytterligare träffar måste du aktivera den globala flaggan, som betecknas g. Regex-mönster är också skiftlägeskänsliga som standard. Du kan åsidosätta detta beteende genom att aktivera flaggan okänslig, betecknad med i. Det uppdaterade regexmönstret är nu fullständigt uttryckt som /cat/gi. Som du kan se nedan har alla ”cat”-strängar matchats, inklusive den som har ett annat kasus.
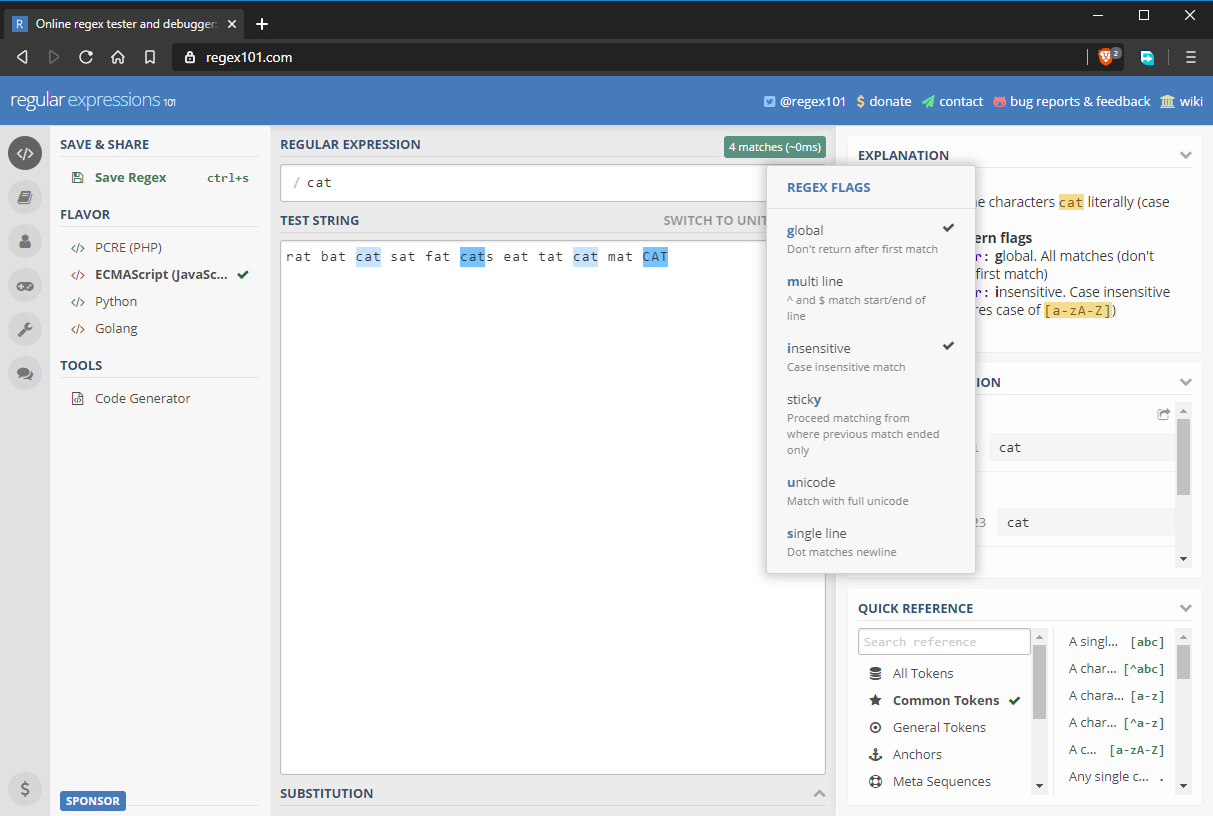
Teckensatser
I det föregående exemplet lärde vi oss att utföra exakta matchningar som är känsliga för stora och små bokstäver. Tänk om vi vill matcha ”bat”, ”cat” och ”fat”. Vi kan göra detta genom att använda teckenuppsättningar, som betecknas med . I princip anger du flera tecken som du vill att de ska matchas. Till exempel kommer at att matcha flera strängar enligt följande:
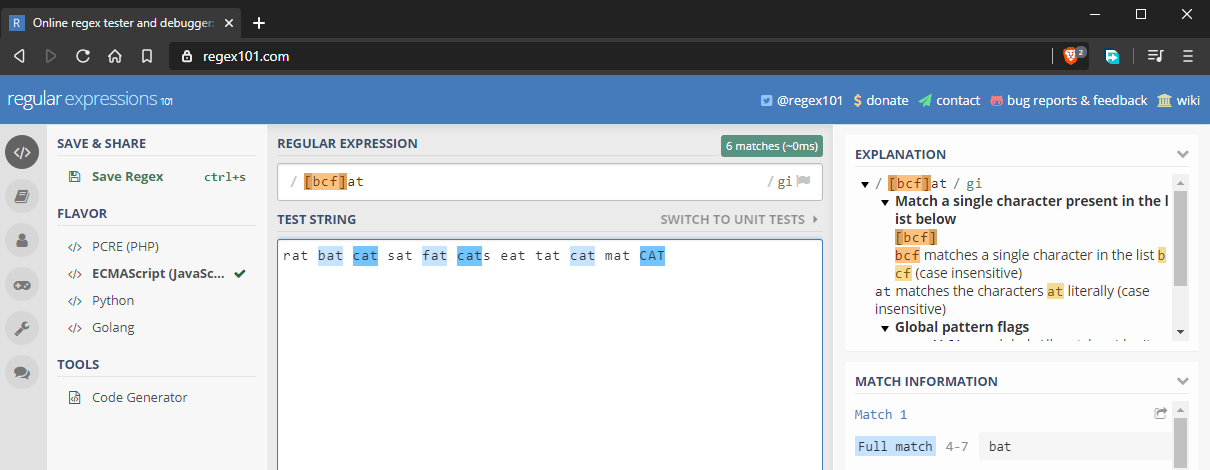
Teckensatser fungerar även med siffror.
Ranges
Vi antar att vi vill matcha alla ord som slutar på at. Vi skulle kunna ange hela alfabetet i teckenuppsättningen, men det skulle vara tråkigt. Lösningen är att använda intervall som detta at:
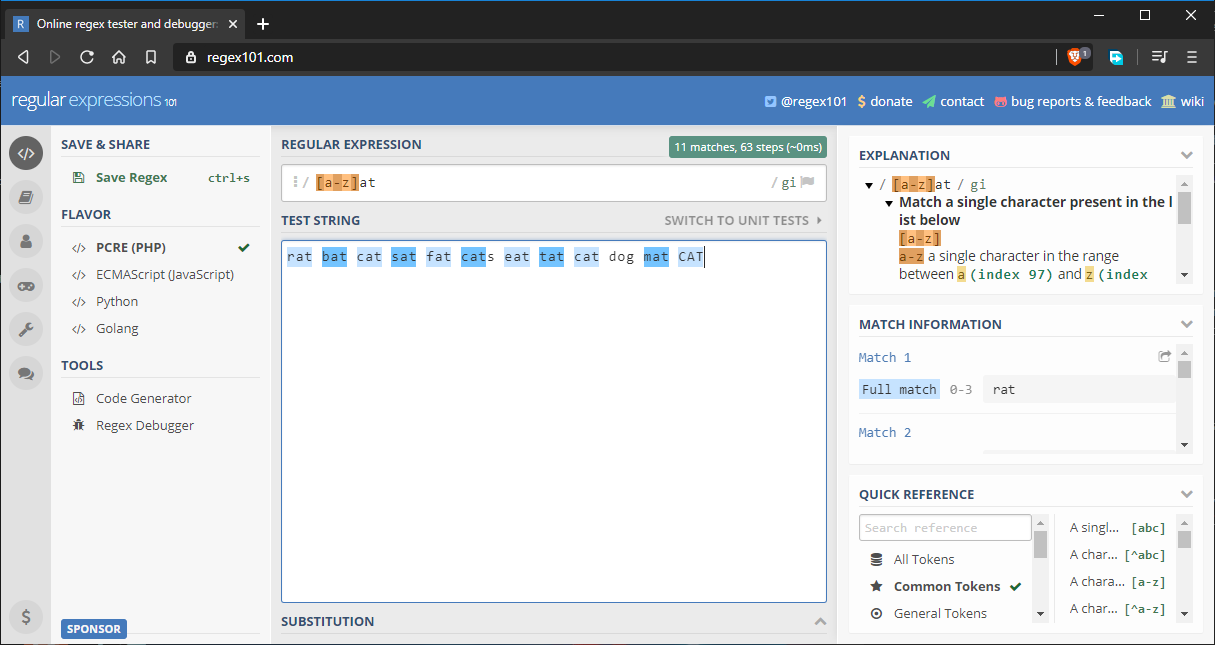
Här är hela strängen som testas: rat bat cat sat fat cats eat tat cat dog mat CAT.
Som du kan se matchar alla ord som förväntat. Jag har lagt till ordet dog bara för att slänga in en ogiltig matchning. Här är andra sätt du kan använda intervall:
-
Partiellt intervall: val som
eller. -
Kapitaliserat intervall:
. -
Siffrigt intervall:
. -
Symbolområde: t.ex.
. -
Mixat område: t.ex.
omfattar alla siffror, små och stora bokstäver. Observera att ett intervall endast anger flera alternativ för ett enskilt tecken i ett mönster.För att ytterligare förstå hur man definierar ett intervall är det bäst att titta på hela ASCII-tabellen för att se hur tecknen är ordnade.

Rekommenderande tecken
Säg att du vill matcha alla ord med tre bokstäver. Du skulle förmodligen göra så här:
Detta skulle matcha alla ord med tre bokstäver. Men vad händer om du vill matcha ett ord med fem eller åtta tecken? Ovanstående metod är tråkig. Det finns ett bättre sätt att uttrycka ett sådant mönster med hjälp av notationen {}parenteser. Allt du behöver göra är att ange antalet repeterande tecken. Här är exempel:
-
a{5}matchar ”aaaaa”. -
n{3}matchar ”nnn”. -
{4}matchar ett ord med fyra bokstäver, till exempel ”dörr”, ”rum” eller ”bok”. -
{6,}matchar alla ord med sex eller fler bokstäver. -
{8,11}matchar alla ord med mellan åtta och elva bokstäver. Grundläggande validering av lösenord kan göras på detta sätt. -
{11}matchar ett 11-siffrigt nummer. Grundläggande validering av internationella telefoner kan göras på detta sätt.
Metatakoder
Med hjälp av metakoder kan du skriva reguljära uttrycksmönster som är ännu mer kompakta. Låt oss gå igenom dem en efter en:
-
\dmatchar alla siffror som är samma som -
\wmatchar alla bokstäver, siffror och understrykningstecken -
\smatchar ett vitrymdstecken – dvs, ett mellanslag eller en tabb -
\tmatchar endast ett tabbtecken
Med utgångspunkt från vad vi har lärt oss hittills kan vi skriva reguljära uttryck så här:
-
\w{5}matchar ett ord med fem bokstäver eller ett femsiffrigt nummer -
\d{11}matchar ett elvasiffrigt nummer, t.ex. ett telefonnummer
Specialtecken
Specialtecken tar oss ett steg längre i skrivandet av mer avancerade mönsteruttryck:
-
+: Ett eller flera kvantifierare (föregående tecken måste finnas och kan eventuellt dupliceras). Exempelvis kommer uttrycketc+atatt matcha ”cat”, ”ccat” och ”ccccccccccat”. Du kan upprepa det föregående tecknet hur många gånger som helst och du får ändå en träff. -
?: Nul eller en kvantifierare (det föregående tecknet är valfritt). Till exempel kommer uttrycketc?atendast att matcha ”cat” eller ”at”. -
*: Nio eller fler kvantifierare (det föregående tecknet är valfritt och kan eventuellt dupliceras). Exempelvis kommer uttrycketc*atatt matcha ”at”, ”cat” och ”ccccccat”. Det är som kombinationen av+och?. -
\: Detta ”escape-tecken” används när vi vill använda ett specialtecken bokstavligen. Till exempel kommerc\*att exakt matcha ”c*” och inte ”ccccccc”. -
: Denna ”negation” används för att ange ett tecken som inte ska matchas inom ett område. Till exempel kommer uttrycketbldinte att matcha ”bald” eller ”bbld” eftersom de andra bokstäverna a till c är negativa. Mönstret kommer dock att matcha ”beld”, ”bild”, ”bold” och så vidare. -
.: Denna ”do”-notering matchar alla siffror, bokstäver eller symboler utom newline. Till exempel:.{8}matchar ett lösenord med åtta tecken bestående av bokstäver, siffror och symboler. till exempel: ”password” och ”P@ssw0rd” matchar båda.
Från det vi lärt oss hittills kan vi skapa en intressant mängd kompakta men kraftfulla reguljära uttryck. Till exempel:
-
.+matchar ett eller ett obegränsat antal tecken. Till exempel: ”c” , ”cc” och ”bcd#.670” matchar alla. -
+matchar alla ord med små bokstäver oavsett längd, så länge de innehåller minst en bokstav. Till exempel kommer både ”book” och ”boardroom” att matcha.
Groups
Alla specialtecken som vi nyss nämnde påverkar endast ett enskilt tecken eller en intervalluppsättning. Vad händer om vi vill att effekten ska gälla en del av uttrycket? Det kan vi göra genom att skapa grupper med hjälp av runda parenteser – (). Exempelvis kommer mönstret book(.com)? att matcha både ”book” och ”book.com”, eftersom vi har gjort ”.com”-delen valfri.
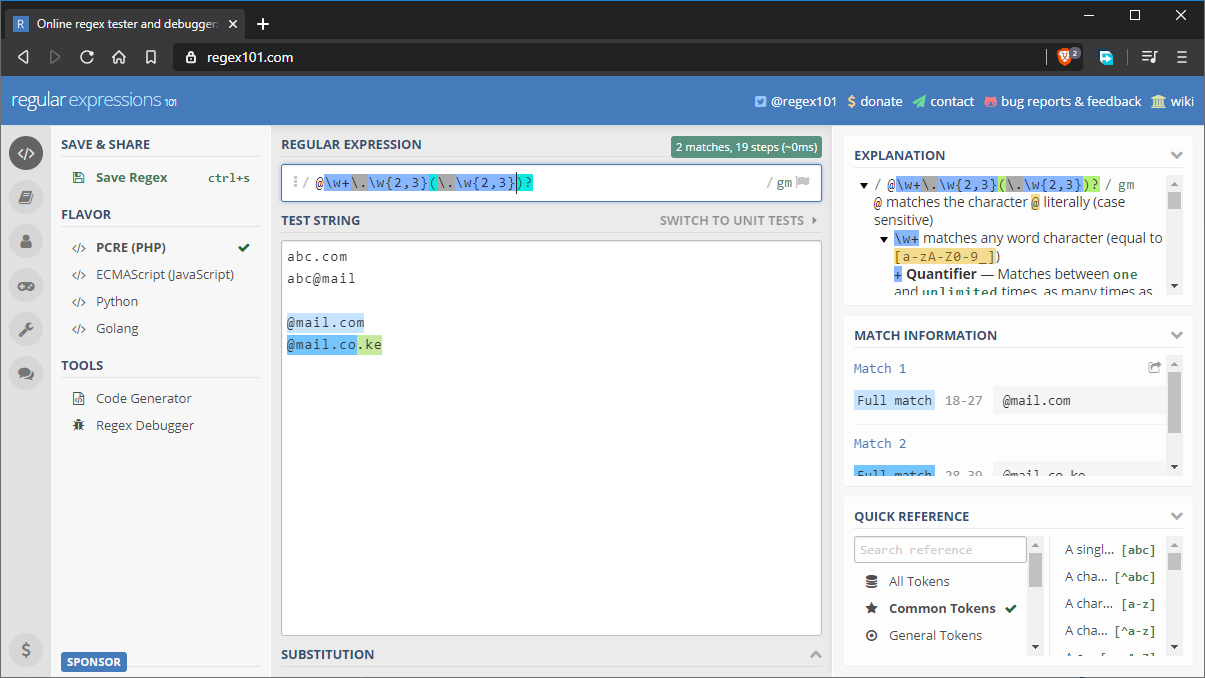
Här är ett mer komplext exempel som skulle användas i ett realistiskt scenario, t.ex. validering av e-post:
- mönster:
@\w+\.\w{2,3}(\.\w{2,3})? - teststräng:
abc.com abc@mail @mail.com @mail.co.ke
Alternativa tecken
I regex kan vi ange alternativa tecken med hjälp av ”pipesymbolen” – |. Detta skiljer sig från de specialtecken som vi visade tidigare eftersom det påverkar alla tecken på vardera sidan av pipesymbolen. Exempelvis kommer mönstret sat|sit att matcha både ”sat” och ”sit” strängar. Vi kan skriva om mönstret till s(a|i)t för att matcha samma strängar.
Mönstret ovan kan uttryckas som s(a|i)t genom att använda () parenteser.
Start- och slutmönster
Du kanske har lagt märke till att vissa positiva matchningar är ett resultat av partiell matchning. Om jag till exempel skrev ett mönster för att matcha strängen ”boo” kommer strängen ”book” också att få en positiv matchning, trots att den inte är en exakt matchning. För att åtgärda detta använder vi följande notationer:
-
^: placerad i början, det här tecknet matchar ett mönster i början av strängen. -
$: placerad i slutet, det här tecknet matchar ett mönster i slutet av strängen.
För att åtgärda ovanstående situation kan vi skriva vårt mönster som boo$. Detta säkerställer att de tre sista tecknen matchar mönstret. Det finns dock ett problem som vi ännu inte har tagit hänsyn till, vilket följande bild visar:
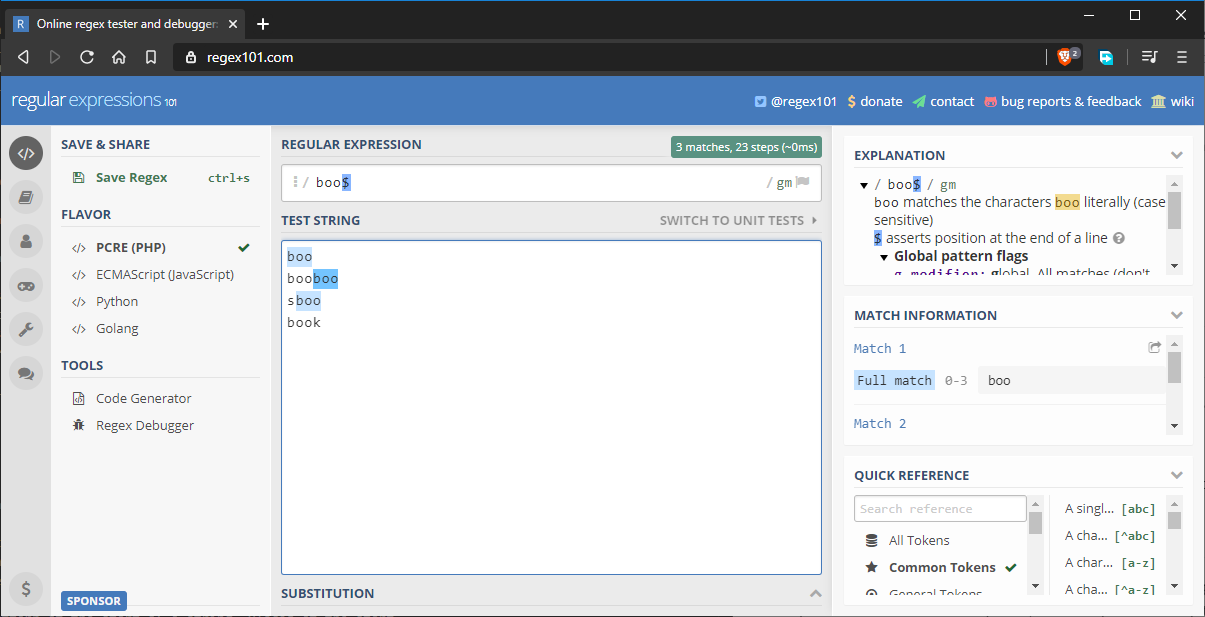
Strängen ”sboo” får en matchning eftersom den fortfarande uppfyller de aktuella kraven för mönstermatchning. För att åtgärda detta kan vi uppdatera mönstret på följande sätt: ^boo$. Detta kommer att strikt matcha ordet ”boo”. Om du använder båda dessa mönster tillämpas båda reglerna. Exempelvis ^{5}$ matchar strikt ett ord med fem bokstäver. Om strängen har fler än fem bokstäver matchar inte mönstret.
Regex i JavaScript
// Example 1const regex1=/a-z/ig//Example 2const regex2= new RegExp(//, 'ig')Oppna en terminal och utför kommandot node för att starta skaltolken i Node.js om Node.js är installerad på din maskin. Kör sedan följande:
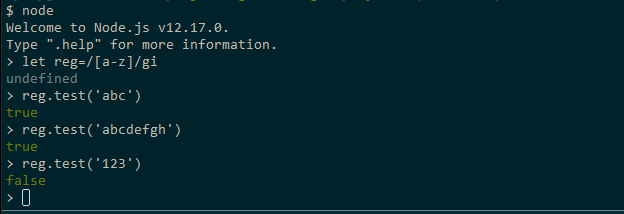
Känn dig fri att leka med fler regexmönster. När du är klar använder du kommandot .exit för att avsluta skalet.
Real World Example: E-postvalidering
När vi avslutar den här guiden ska vi titta på en populär användning av regex, nämligen e-postvalidering. (Vi kan till exempel vilja kontrollera att en e-postadress som en användare har skrivit in i ett formulär är en giltig e-postadress.)
Det här ämnet är mer komplicerat än du kanske tror. Syntaxen för e-postadresser är ganska enkel: {name}@{domain}. I teorin kan en e-postadress innehålla ett begränsat antal symboler som #-@&%. osv. Placeringen av dessa symboler har dock betydelse. E-postservrar har också olika regler för användningen av symboler. Vissa servrar behandlar till exempel symbolen + som ogiltig. På andra e-postservrar används symbolen för underadressering av e-post.
Som en utmaning för att testa dina kunskaper kan du försöka bygga upp ett reguljärt uttrycksmönster som endast matchar de giltiga e-postadresser som är markerade nedan:
# invalid emailabcabc.com# valid email [email protected]@[email protected]@[email protected]# invalid email [email protected]@[email protected]#[email protected]# valid email [email protected]@[email protected][email protected]# invalid domain [email protected]@mail#[email protected]@mail..com# valid domain [email protected]@[email protected]@[email protected]Observera att vissa e-postadresser som är markerade som giltiga kan vara ogiltiga för vissa organisationer, medan vissa som är markerade som ogiltiga faktiskt kan vara tillåtna i andra organisationer. Hur som helst är det av största vikt att lära sig att bygga anpassade reguljära uttryck för de organisationer du arbetar för för att kunna tillgodose deras behov. Om du fastnar kan du titta på följande möjliga lösningar. Observera att ingen av dem kommer att ge dig en 100-procentig matchning på ovanstående giltiga e-postteststrängar.
- Möjlig lösning 1:
^\w*(\-\w)?(\.\w*)?@\w*(-\w*)?\.\w{2,3}(\.\w{2,3})?$- Möjlig lösning 2:
^((\.,;:\s@"]+(\.\.,;:\s@"]+)*)|(".+"))@((\{1,3}\.{1,3}\.{1,3}\.{1,3}])|((+\.)+{2,}))$Sammanfattning
Jag hoppas att du nu har lärt dig grunderna i reguljära uttryck. Vi har inte täckt alla regex-funktioner i den här snabba nybörjarguiden, men du bör ha tillräckligt med information för att ta itu med de flesta problem som kräver en regex-lösning. Om du vill veta mer kan du läsa vår guide om bästa praxis för praktisk tillämpning av regex i verkliga scenarier.