




Vilken liga är bäst?
Detta arbete är skrivet tillsammans med Madeline Gall.
Men medan scouting för vissa sporter är okomplicerat (collegefotboll → NFL), kan scouting för NHL vara en mer mödosam process. Med spelare från över 45+ internationella ishockeyligor, var och en med sina egna regler och svårigheter, hur kan man på ett adekvat sätt bedöma kvaliteten på en spelares prestation? Det är inte lätt att göra jämförelser mellan olika ligor. 18 poäng för en artonåring som spelar mot andra artonåringar i en mindre liga bör inte tillskrivas samma värde som 18 poäng för en artonåring som spelar mot veteraner i NHL.
Det har funnits andra försök att ta hänsyn till detta, inklusive variabler för spelaröversättning, som Rob Vollmans hockeyöversättningsfaktorer och Gabriel Desjardins NHL Equivalency Ratings (NHLe). Desjardins NHLe tog tidigare itu med frågan om att jämföra och förutsäga spelarprestanda vid övergångar från liga till NHL (övergång från en annan liga till NHL). Det var bra för en snabb, allmän jämförelse och har förvisso sina fördelar (enkelt och snabbt att beräkna), men det finns vissa nackdelar med dess metod. Till att börja med kontrollerade den inte nödvändigtvis lagkvalitet, position och ålder. Översättningsfaktorer beräknas med hjälp av statistik från spelare som spelat minst 20 matcher i den aktuella ligan innan de spelat minst 20 matcher i NHL. Det innebär att det finns en hel del värdefull data om dessa mellanliggande övergångar som inte används.
I det här projektet introducerar vi en ny metod för att jämföra och projicera spelares prestationer mellan olika ligor med hjälp av ett justerat z-score-metriskt mått som skulle ta hänsyn till dessa nackdelar. Detta mått kontrollerar faktorer som ålder, liga, säsong och position som påverkar en spelares P/PG-mått och skulle kunna tillämpas på alla ligor av intresse. Detta nya mått är nödvändigt eftersom det finns många egenskaper som varierar från liga till liga. På grund av de olika spelstilarna och motståndarnas svårighetsgrad finns det inte ett enhetligt mått för att göra jämförbara utvärderingar av spelarnas prestationer för hockeyligor runt om i världen. Andra faktorer som målvaktsstärka, utvisningsfrekvens och rinkdimensioner är också inkonsekventa i olika internationella ligor. Scenarier kan uppstå där spelare med liknande styrka kan tyckas ha till synes olika prestationer.
Ett sådant exempel på detta är Thomas Harley och Ville Heinola från den senaste draften 2019. Båda är spelare från olika ligor som spelar mot olika motståndare och sätter upp vitt skilda siffror, men värderades ändå som ungefär lika starka. Harley, en amerikanskfödd back som spelar i den kanadensiska juniorishockeyligan, spelar för närvarande med Mississauga Steelheads i Ontario Hockey League. Han draftades som 18:e spelare totalt av Dallas Stars i den första rundan av NHL Entry Draft 2019. Heinola å andra sidan är en finsk professionell ishockeyförsvarare som för närvarande spelar för Lukko i Liiga och är utlånad som prospect till Winnipeg Jets i National Hockey League. Han rankades som en av de bästa internationella skridskoåkarna som är kvalificerade för NHL Entry Draft 2019. Heinola draftades som 20:e spelare totalt av Jets. Hur slutade det med att dessa två spelare utvärderades av sina respektive lag? Förmodligen med något som liknar vår metrik utöver scoutinginformation.
För vårt mått inspirerades vi inte bara av tidigare metoder som NHLe, utan även av den senaste tidens uppsving för Elo. Elo är en metod för att beräkna den relativa skicklighetsnivån hos spelare i nollsummespel. Elo skapades ursprungligen för att mäta schackspelares betyg, men kan också användas i flera andra scenarier, t.ex. inom professionell idrott. Om du vill läsa mer och se exempel på Elo inom idrotten kan du hitta en handledning från 538 här. Elo är helt enkelt en särskild modell för en modell för parvisa jämförelser. Vi kommer att gå igenom processen där vi skapade vår modell för parade jämförelser/Elo.
För att börja använde vi ett dataset som innehöll cirka 300 000 observationer från spelarinformation (namn, position, liga, födelsedag osv.) och spelarstatistik (spelade matcher, mål, assist osv.) som fanns tillgängliga, skrapade från eliteprospects.com. En av de första frågorna vi stötte på var vilken typ av responsvariabel vi kunde skapa för att jämföra spelarstatistik, med kontroll för ålder, ligastyrka, position osv. Spelarprestationer har beräknats i stor utsträckning inom NHL; det finns olika mått som WAR, GAR, Corsi osv. Datainsamlingen är dock inte lika i alla ligor. Vissa ligor var inte lika proaktiva när det gäller att spåra statistik som träffar och blockeringar som andra, vilket innebar att vi bara kunde använda variabler som var allestädes närvarande i alla ligor som faktorer i vår regression.
När vi skapade den nya responsvariabeln ville vi omvandla poäng per match på ett sätt som tog hänsyn till ålder, säsong, position och liga. Det första steget var att ta loggen av poäng per match plus ett. Denna omvandling hade en mer normal fördelning medan råpoäng per match var mycket högerskevad. Även om logtransformationen bidrog till att uppgifterna verkade mer normalfördelade, tog logpoäng per match fortfarande inte hänsyn till de variabler som anges ovan. Vi beslutade att för att ta hänsyn till sådana variabler skulle vi skapa ett z-värde för varje spelares logpoäng per match. Det första steget var att beräkna medelvärde och standardavvikelse för varje grupp av position, säsong, liga och ålder. Därefter beräknades en z-score för varje spelarobservation med hjälp av det medelvärde och den standardavvikelse som gällde för de variabler som vi kontrollerade för. Z-score för logaritmen av poäng per match plus ett var således vår slutliga svarsvariabel. Z-poängen verkade vara ännu mer normalfördelade än logpoängen per match, och z-poängen för grupper som försvarare och forwards var också normalfördelade.
Skapande av den parade jämförelsemodellen, som är mycket lik en Elo-modell. Till att börja med bygger vi ett jämförelsedataframe. Vi skapar par av spelare-ligasäsonger för varje spelare, så att det finns ett litet dataframe med alla parvisa jämförelser för de ligor som de har spelat i. Detta innebär att om en spelare har spelat i K ligor kommer den spelaren att ha K-choose-2 par av spelare-ligasäsonger. Därefter eliminerar vi alla par som har samma liga, liksom par som ligger längre än en säsong ifrån varandra, och beräknar en utfallsvariabel. Denna variabel kan antingen vara kontinuerlig eller binär, beroende på vilken regression som används. Det är viktigt att förstå att den ”svårare” ligan att spela i faktiskt skulle ha en lägre resultatvariabel. Detta bygger på antagandet att svårare ligor har bättre backar och målvakter, vilket gör det svårare att göra mål.
| Spelarnamn | Liga | Säsong | Z- Poäng |
|---|---|---|---|
| Kris Letang | QMJHL | 2006-07 | 1.829 |
| Kris Letang | NHL | 2006-07 | 1.158 |
| Kris Letang | AHL | 2007-08 | 1.557 |
| Liga 1 | Säsong 1 | Z-poäng 1 | Liga 2 | Säsong 2 | Z-poäng 2 | Z-.Poäng 2 | Z-poäng Skillnad |
|---|---|---|---|---|---|---|---|
| QMJHL | 2006-07 | 1.829 | NHL | 2006-07 | 1.158 | 0.671 | |
| NHL | 2006-07 | 1.158 | AHL | 2007-08 | 1.557 | -0.399 | |
| QMJHL | 2006-07 | 1.829 | AHL | 2007-08 | 1.557 | 0.272 |
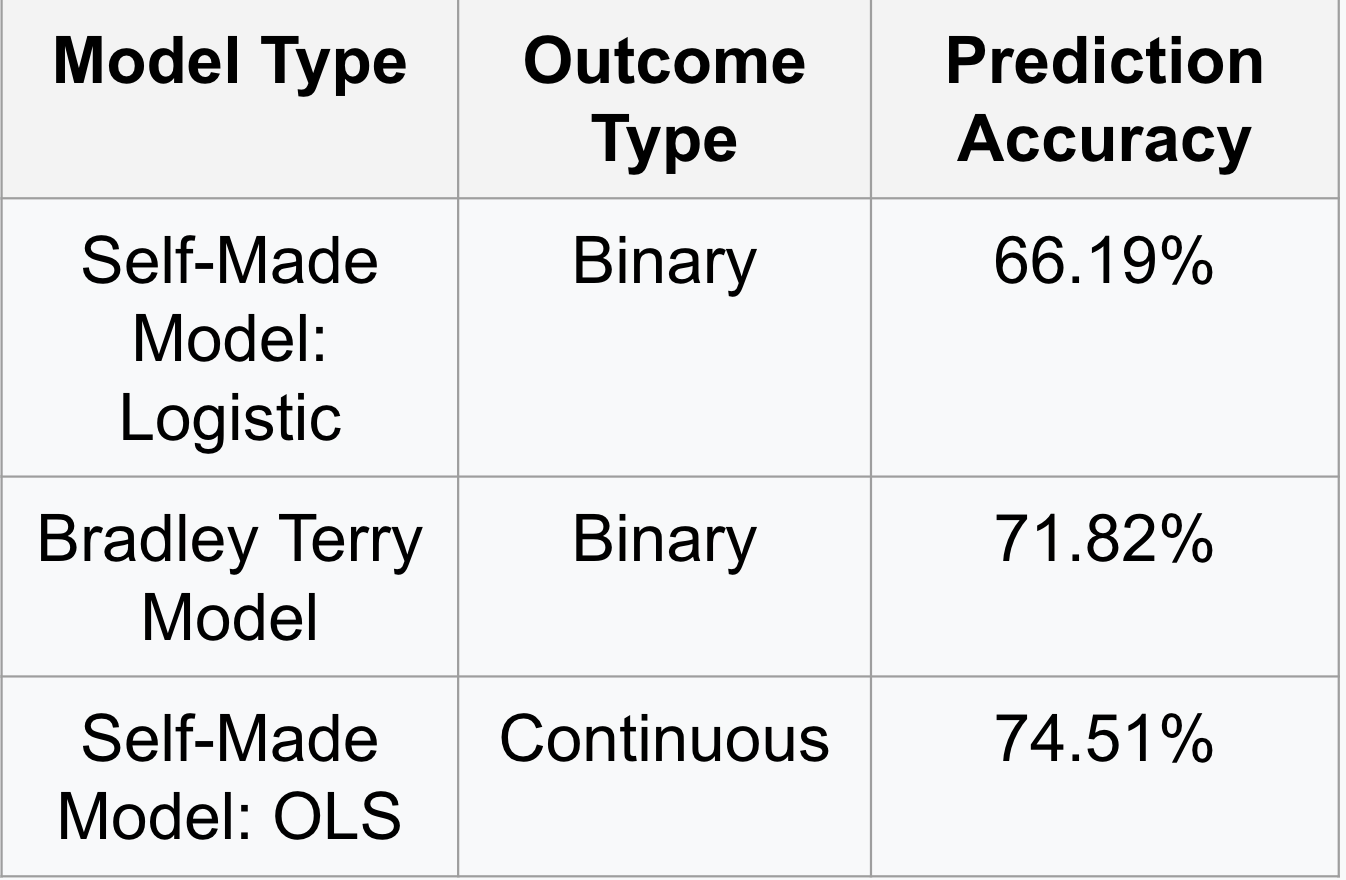
Efter att ha byggt upp modellen för parade jämförelser användes olika typer av regressioner för att beräkna koefficienterna. Vi fokuserade på att använda en egenutvecklad logistisk modell, Bradley Terry-modellen (med hjälp av BTm-paketet i R), som båda skapade binära utfall, samt en Ordinary Least Squares-regression, som skapade ett kontinuerligt utfall. För att utvärdera vilken regression som fungerade för att skapa de mest exakta resultaten delade vi först upp de parade uppgifterna 70/30 för tränings- och testprover. Därefter förutspådde vi sannolikheten för en vinst för alla ligor, baserat på den justerade poäng per match Z-score. Ett tröskelvärde för ”vinna” fastställdes; om sannolikheten var större än tröskelvärdet var det förutspådda resultatet = 1. I annat fall var det = 0. Därefter jämfördes de förutspådda resultaten med de faktiska resultaten för att beräkna prediktionsnoggrannheten för varje modell. Resultaten visas i följande tabell nedan.
När våra olika modelleringsmetoder hade skapats kunde vi använda styrkekoefficienterna från modellerna för att skapa en rangordning av ligor bestämda efter deras styrka. Det var ingen överraskning att för varje år från 2008 till 2018 och för de totala styrkekoefficienterna att National Hockey League anses vara den starkaste ligan. Den andra ligan som genomgående ansågs vara den näst bästa var världsmästerskapen, vilket är logiskt eftersom det är de bästa spelarna från olika länder som tävlar, och denna turnering består av många spelare som spelar i NHL. Om man bara tittar på ligorna var AHL, KHL, SHL och DEL genomgående några av de starkaste ligorna med över 45 lag. Den slutliga rankningen av de tio bästa ligorna var NHL, världsmästerskapen, juniorvärldsmästerskapen, KHL, SHL, AHL, USDP, juniorvärldsmästerskapen U18, DEL och NLA. Några av de ligor som kanske var en överraskning var juniorhockeyligorna eller USDP. Dessa ligor syntes högre på vår ranking eftersom vi tog hänsyn till ålder i vår modell. Detta gjorde att styrkan kunde baseras på spelarnas kvalitet snarare än på spelarnas ålder. Var och en av de tre modellerna vi skapade hade liknande rankningar med endast små avvikelser.
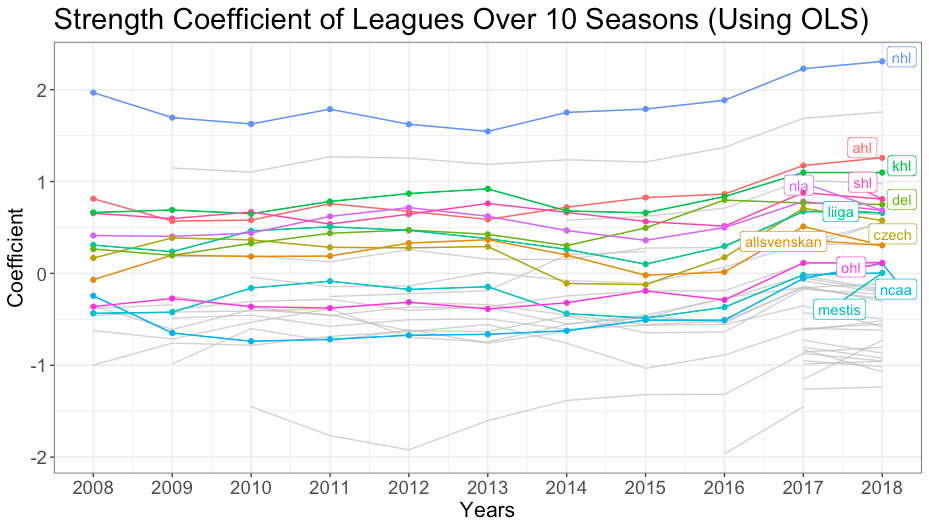
Styrkekoefficienter över tid: Grafen ovan visar styrkekoefficienterna för varje liga för varje år från 2008 – 2018. De mer kända ligorna och de genomgående starka ligorna är markerade ovan.
Efter att ha genererat en ranking av ligor baserat på våra justerade poäng per match var nästa steg att se hur dessa rankningar jämfördes med att använda enbart poäng per match. När vi använde bara poäng per match märkte vi att tre saker hände med ligornas styrkekoefficienter. De ligor som hade en högre styrkekoefficient tenderade att fortfarande vara de starkare ligorna för justerade poäng per match. För de ligor som låg i mitten av alla ligor var deras styrkekoefficienter för råpoäng per match mycket lika deras styrkekoefficienter för justerade poäng per match. Slutligen hade de ligor som hade de lägsta styrkekoefficienterna för råpoäng per match sämre styrkekoefficienter för justerade poäng per match. De enda ligor som hade lägre styrkekoefficienter som hade styrkekoefficienter som förbättrades av justerade poäng per match var ligor som hade unga spelare. Den här trenden gäller för juniorvärldsmästerskapen för både U20 och U18 och för United States High School, Minnesota-ligan. För Minnesota high school-ligan ansågs den vara den överlägset sämsta ligan när man använde råpoäng per match som svarsvariabel, men genom att använda justerade poäng per match presterar denna liga bättre än tio andra ligor, varav många är professionella ligor. Detta gjorde det möjligt för oss att ytterligare se bristerna med poäng per match som en prediktor för ligastyrka, och belyste också hur viktigt det är att ta hänsyn till ålder när man fastställer ligastyrka.
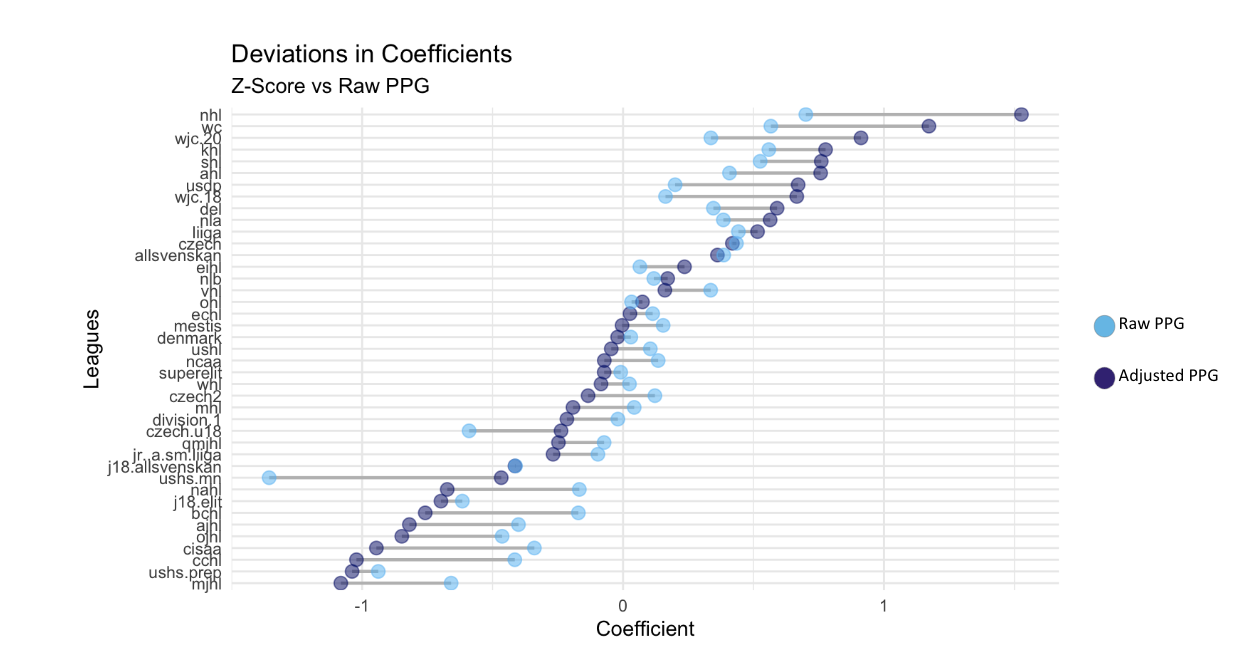
Styrkekoefficienter för varje liga för Raw P/GP vs Adjusted P/GP: Detta diagram visar styrkekoefficienterna för varje liga för de två olika svarsvariablerna. Styrkekoefficienterna beräknades med hjälp av samma modelleringsmetod.
Som nämnts ovan behövde en ny uppskattning av spelarnas prestationer skapas eftersom befintliga prediktorer, t.ex. poäng per match, är snedvridna på grund av ålder, ligastyrka, lagstyrka och år. Att skapa percentiler för spelartyper gör det möjligt att jämföra ett prospekt med andra spelare liknande vilket möjliggör en mer exakt förutsägelse. Percentilen för log P/GP och vår valda metod är mycket användbar eftersom den gör det möjligt att förutsäga en viss spelares prestationer i någon av de över 45 ligorna. Med så många ligor är det inte garanterat att en spelare skulle ha blivit uttagen från den ligan till NHL, men utan modellmetoden behövs inte detta för att göra en korrekt förutsägelse.
Till exempel var Jake Geuntzels justerade poäng per match under säsongen 2017-2018 för Pittsburgh Penguins 0,94. Med hjälp av denna justerade poäng per match kan vi förutsäga hans justerade poäng per match i vilken annan liga som helst. Nedan har vi några av de vanligaste ligorna som visas och Jake Guentzels förutspådda justerade poäng per match i var och en av dessa ligor. Som jämförelse hade Jake Guentzel 2016-2017 en justerad poäng per match på 2,30 i AHL. Våra förutspådda justerade poäng per match på 2 ligger ganska nära.
Vår metod för att förutsäga en spelares justerade poäng per match för att avgöra hur en spelare kan prestera i en viss liga är en enkel beräkning från våra styrkekoefficienter i från den modelleringsprocess som beskrivs tidigare. För att jämföra två ligor subtraherar du deras styrkekoefficienter från varandra. Lägg sedan till detta värde till de justerade poängen per match eller z-poängen för den liga där spelaren har registrerat uppgifter. Summan av z-poängen och skillnaden mellan styrkekoefficienterna ger de justerade poängen per match för någon annan given liga.
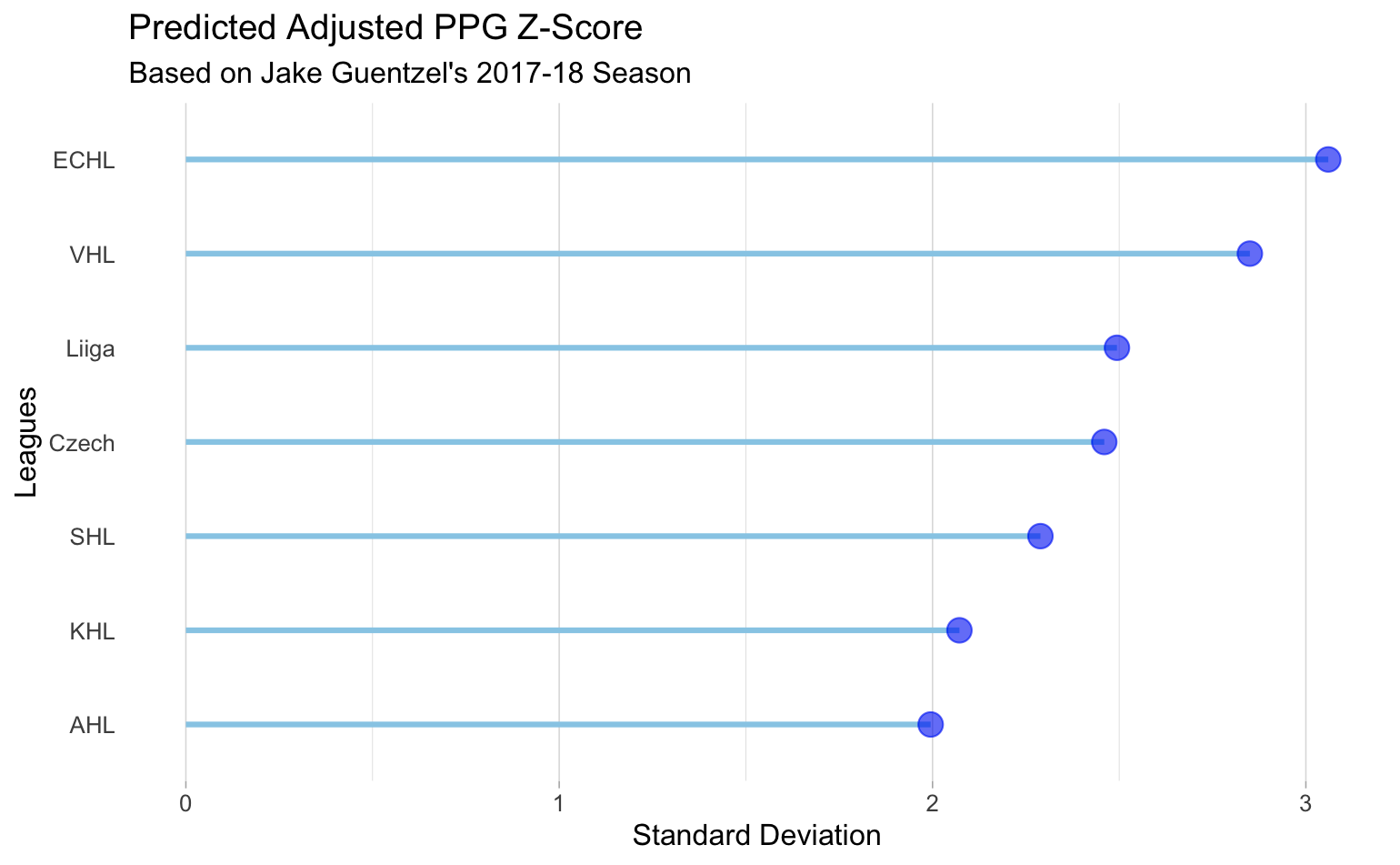
När man förutspår en enskild spelares prestationer är det inte bara användbart för scouting, utan styrkekoefficienterna ger också information om ligans styrka. Koefficienterna tar hänsyn till ålder, säsong, position och liga. Detta skulle kunna göra det möjligt för en scout att investera mer resurser i en ungdomsliga som kanske står i skuggan. Detta beror på att ålder är en viktig faktor för poäng per match, men när man tar hänsyn till alla andra störande variabler fanns det några ungdomsligor som totalt sett hade en mycket bättre ligastyrka än vissa professionella ligor.
Dessa begrepp har också tillämpningar i det verkliga livet. Under månaderna före 2016 års draft har det diskuterats vem Columbus Blue Jackets skulle välja som tredje spelare. De flesta scouter hade värderat Jesse Puljujarvi, en finsk forward, som konsensusval, men fansen blev chockade när de hörde att CBJ istället valde Pierre-Luc Dubois, en kanadensisk centermålvakt. En snabb titt på siffrorna avslöjar dock att detta beslut inte borde komma som en överraskning. När Puljujarvi spelade i den professionella hockeyligan Liiga gjorde han imponerande 28 poäng på 50 ordinarie säsongsmatcher, och rankades som femte bäst bland Liigaspelare under 20 år. Dubois å andra sidan spelade i en mindre hockeyliga, men slutade ändå på tredje plats i QMJHL med 99 poäng på 62 matcher. Med hjälp av koefficienterna kan vi beräkna deras justerade P/GP i NHL för jämförelse, och vi finner att Dubois leder Puljujarvi ur statistisk synvinkel. Självklart skulle detta inte vara det enda som scouter skulle ta hänsyn till när de draftade, Dubois formidabla storlek och fysik spelade definitivt också en roll i deras beslut, men man kan anta att Blue Jackets hade en bättre bild av hur varje spelare stod sig mot varandra när de valde Dubois framför Puljujarvi.
En annan tillämpning förutom jämförelser från spelare till spelare skulle vara jämförelser från liga till liga. Om vi återgår till exemplet Harley vs Heinola kan vi utvärdera deras respektive ligor med andra ligor med liknande status. I stället för att jämföra NHL med OHL, där kontrasten är uppenbar, kan mer nyanserade bedömningar göras genom att jämföra OHL med andra nordamerikanska mindre ligor. Av graferna nedan kan vi se att OHL faktiskt är den starkaste ligan i NA:s mindre ligor, medan Liiga är en medelmåttigt rankad liga jämfört med andra professionella ligor.
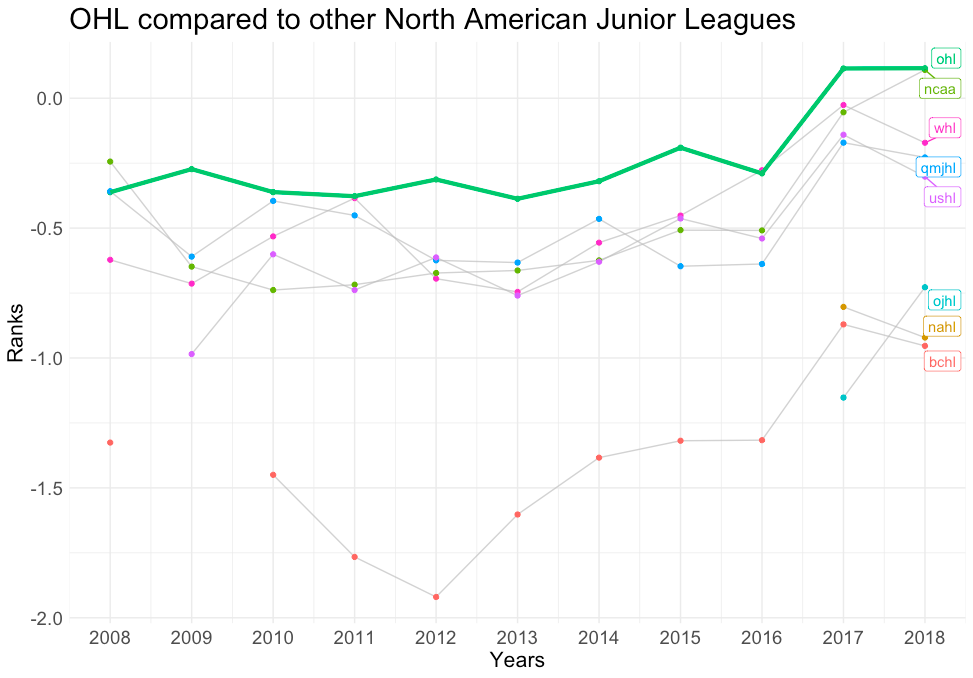
OHL jämfört med andra NA juniorligor: Den här grafen visar styrkekoefficienterna för alla nordamerikanska juniorligor, med OHL markerad i grönt.
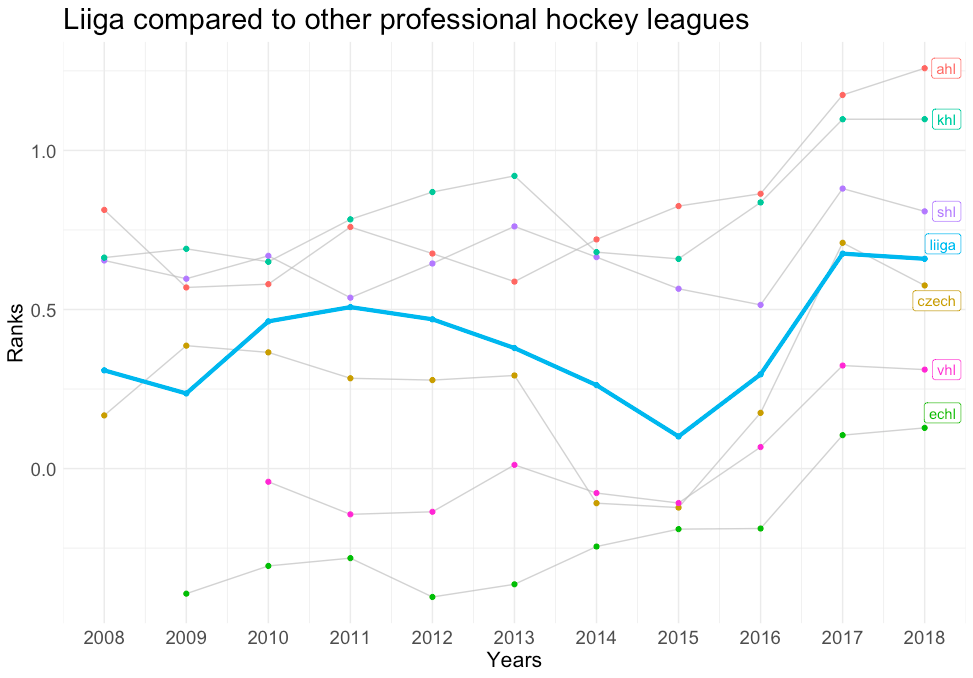
Liiga jämfört med andra professionella hockeyligor: Den här grafen visar styrkekoefficienterna för alla professionella hockeyligor i världen, med Liiga markerad i ljusblått.
Med den justerade spelarmätningen för poäng per match kontrolleras inte bara förvirrande variabler som spelarens ålder, position, liga och säsong, vilket kan förändra utsikterna för en viss spelares värde. De modelleringstekniker som används gör det möjligt att göra spelarjämförelser av hockeyligor över hela världen, inte bara av de framstående stora ligorna. Detta ger lagen möjlighet att förutsäga hur en viss spelare kan prestera i deras liga i förhållande till liknande spelare, vilket tidigare gjordes genom att använda en snedvriden estimator. Det justerade måttet för poäng per match möjliggör ett mer holistiskt tillvägagångssätt för att utvärdera spelare och ger en väg för spelare som tidigare kanske har förbisetts eller legat i marginalen. Det finns många tillämpningar redan nu bara genom att använda justerade poäng per match, men andra typer av data kan också användas, som scoutrankingar eller förväntade mål osv. Med mer detaljerad data i framtiden i alla ligor kan denna metod också förbättras ytterligare.
Forskningen i denna artikel presenterades också vid CBJHAC20 av Katerina Wu. Du kan hitta bildspelet här.
Följ oss på Twitter @kattaqueue och @madelinejgall!