




Enterprise Data Warehouse: Concepts, Architecture, and Components
Leestijd: 12 minuten
Door de dag heen nemen we veel beslissingen op basis van eerdere ervaringen. Onze hersenen slaan triljoenen stukjes gegevens op over gebeurtenissen in het verleden en gebruiken die herinneringen telkens wanneer we een beslissing moeten nemen. Net als mensen genereren en verzamelen bedrijven tonnen gegevens over het verleden. En deze gegevens kunnen worden gebruikt om betere beslissingen te nemen.
Terwijl onze hersenen dienen om zowel te verwerken als op te slaan, hebben bedrijven meerdere hulpmiddelen nodig om met gegevens te werken. En een van de belangrijkste is een datawarehouse.
In dit artikel zullen we bespreken wat een enterprise datawarehouse is, de soorten en functies ervan, en hoe het wordt gebruikt bij gegevensverwerking. We zullen definiëren hoe enterprise warehouses verschillen van de gebruikelijke, welke soorten data warehouses er bestaan, en hoe ze werken. De focus ligt op het verstrekken van informatie over de zakelijke waarde van elke architecturale en conceptuele benadering voor het bouwen van een magazijn.
Wat is een Enterprise Data Warehouse?
Als u weet hoeveel terabyte is, zou u waarschijnlijk onder de indruk zijn van het feit dat Netflix in 2016 ongeveer 44 terabytes aan gegevens in zijn magazijn had. De grootte alleen al geeft aan waarom we het een magazijn noemen, in plaats van gewoon een database. Dus laten we beginnen met de basis.
Een Enterprise Data Warehouse (EDW) is een vorm van bedrijfsopslagplaats die alle historische bedrijfsgegevens van een onderneming opslaat en beheert. De informatie is meestal afkomstig uit verschillende systemen, zoals ERP’s, CRM’s, fysieke registraties en andere platte bestanden. Om gegevens klaar te maken voor verdere analyse, moeten ze in één opslagplaats worden ondergebracht. Op die manier kunnen verschillende bedrijfseenheden de informatie opvragen en analyseren vanuit verschillende invalshoeken.
Met een data warehouse kan een onderneming enorme gegevensverzamelingen beheren, zonder meerdere databases te beheren. Dit is een toekomstbestendige manier om gegevens op te slaan voor business intelligence (BI), een geheel van methoden/technologieën om ruwe gegevens om te zetten in bruikbare inzichten. Met het EDW als belangrijk onderdeel, is het systeem vergelijkbaar met een menselijk brein dat informatie opslaat, maar dan op steroïden.
Enterprise data warehouse vs usual data warehouse: wat is het verschil?
Elk data warehouse is een database die altijd verbonden is met ruwe-data bronnen via data integratie tools aan de ene kant en analytische interfaces aan de andere kant. Als dat zo is, waarom isoleren we dan de ondernemingsvorm voor discussie?
Elk pakhuis biedt opslag die mechanismen heeft om gegevens te transformeren, te verplaatsen, en aan de eindgebruiker te presenteren. Het verschil tussen een gewoon data warehouse en een enterprise warehouse zit hem in de veel grotere architectonische diversiteit en functionaliteit. Vanwege de complexe structuur en omvang worden EDW’s vaak opgedeeld in kleinere databases, zodat eindgebruikers zich meer op hun gemak voelen bij het bevragen van deze kleinere databases. Dit in overweging nemend, richten we ons op een enterprise warehouse om het hele spectrum van functionaliteit te bestrijken.
De grootte van een warehouse bepaalt echter niet de technische complexiteit, de eisen voor analytische en rapportage mogelijkheden, het aantal datamodellen, en de data zelf. Dus, om te begrijpen wat een magazijn tot een magazijn maakt, duiken we in de kernconcepten en -functionaliteit.
Interprise Data Warehouse concepten en functies
Met alle toeters en bellen, in het hart van elk magazijn liggen basisconcepten en -functies. Deze pijlers definiëren een warehouse als een technologisch fenomeen:
Dient als de ultieme opslagplaats. Een enterprise data warehouse is een uniforme opslagplaats voor alle bedrijfsgegevens die ooit in de organisatie zijn voorgekomen.
Verspiegelt de brongegevens. Het EDW haalt gegevens uit de oorspronkelijke opslagruimten, zoals Google Analytics, CRM’s, IoT-apparaten, enz. Als de data verspreid is over meerdere systemen, is het onbeheersbaar. Dus, het doel van EDW is om de gelijkenis van de originele brongegevens in een enkele opslagplaats te bieden. Aangezien er altijd nieuwe, relevante gegevens worden gegenereerd, zowel binnen als buiten het bedrijf, vereist de stroom van gegevens een speciale infrastructuur om deze te beheren voordat ze een magazijn binnenkomen.
Opslaan van gestructureerde gegevens. De gegevens die in een EDW worden opgeslagen, zijn altijd gestandaardiseerd en gestructureerd. Dit maakt het mogelijk voor de eindgebruikers om ze te bevragen via BI-interfaces en formulieren. En dit is wat een data warehouse anders maakt dan een data lake. Data lakes worden gebruikt om ongestructureerde gegevens op te slaan voor analytische doeleinden. Maar in tegenstelling tot pakhuizen worden data lakes meer gebruikt door data engineers/wetenschappers om te werken met grote reeksen ruwe gegevens.
Subjectgeoriënteerde gegevens. Het belangrijkste aandachtspunt van een magazijn zijn bedrijfsgegevens die betrekking kunnen hebben op verschillende domeinen. Om te begrijpen waar de gegevens betrekking op hebben, zijn ze altijd gestructureerd rond een specifiek onderwerp dat een gegevensmodel wordt genoemd. Een voorbeeld van een onderwerp kan een verkoopregio zijn of de totale verkoop van een bepaald artikel. Daarnaast worden metadata toegevoegd om in detail uit te leggen waar elk stukje informatie vandaan komt.
Tijdsafhankelijk. De verzamelde gegevens zijn meestal historische gegevens, omdat zij gebeurtenissen uit het verleden beschrijven. Om te begrijpen wanneer en hoe lang een bepaalde tendens heeft plaatsgevonden, worden de meeste opgeslagen gegevens meestal onderverdeeld in tijdsperioden.
Nonvolatiel. Eenmaal in een magazijn geplaatst, worden de gegevens er nooit meer uit gewist. De gegevens kunnen worden gemanipuleerd, gewijzigd of bijgewerkt als gevolg van bronwijzigingen, maar het is nooit de bedoeling dat ze worden gewist, althans niet door de eindgebruikers. Als we het hebben over historische gegevens, zijn verwijderingen contraproductief voor analytische doeleinden. Toch kunnen algemene herzieningen eens in de paar jaar voorkomen om zich te ontdoen van irrelevante gegevens.
Gezien de basisprincipes, zullen we kijken naar de implementatietypes van DW’s.
Data warehouse types
Gezien de EDW-functies, is er altijd ruimte voor discussie over hoe het technisch ontworpen moet worden. In het geval van data opslag en verwerking, zijn ze specifiek en verschillend voor verschillende soorten bedrijven. Afhankelijk van de hoeveelheid data, analytische complexiteit, veiligheidskwesties, en budget, is er natuurlijk altijd een optie over hoe het systeem in te richten.
Klassiek datawarehouse
Gezamenlijke opslag met zijn eigen hardware en software wordt beschouwd als een klassieke variant voor een EDW. Met fysieke opslag hoeft u geen data-integratietools tussen meerdere databases op te zetten. In plaats daarvan kan het EDW via API’s met databronnen worden verbonden om voortdurend informatie te verkrijgen en in het proces te transformeren. Al het werk wordt dus gedaan in de staging area (de plaats waar de gegevens worden getransformeerd voordat ze in het DW worden geladen), of in het magazijn zelf.
Een klassiek datawarehouse wordt beschouwd als superieur aan een virtueel datawarehouse (dat we hieronder bespreken), omdat er geen extra abstractielaag is. Het vereenvoudigt het werk voor data-engineers en maakt het gemakkelijker om de gegevensstroom aan de voorbewerkingskant te beheren, evenals de feitelijke rapportage. De nadelen van het klassieke magazijn zijn afhankelijk van de daadwerkelijke implementatie, maar voor de meeste bedrijven zijn dit:
- Dure technologische infrastructuur, zowel hardware als software;
- Het inhuren van een team van data-engineers en DevOps-specialisten om het hele dataplatform op te zetten en te onderhouden.
Wanneer te gebruiken: geschikt voor organisaties van elke omvang die hun gegevens willen verwerken en er gebruik van willen maken. Klassieke magazijnen maken het mogelijk om te morphen in verschillende architecturale stijlen van het gegevensplatform, en ook om doelbewust op en neer te schalen.
Virtueel datawarehouse
Een virtueel datawarehouse is een type EDW dat wordt gebruikt als alternatief voor een klassiek magazijn. In wezen gaat het om meerdere databases die virtueel met elkaar zijn verbonden, zodat ze als één systeem kunnen worden bevraagd.
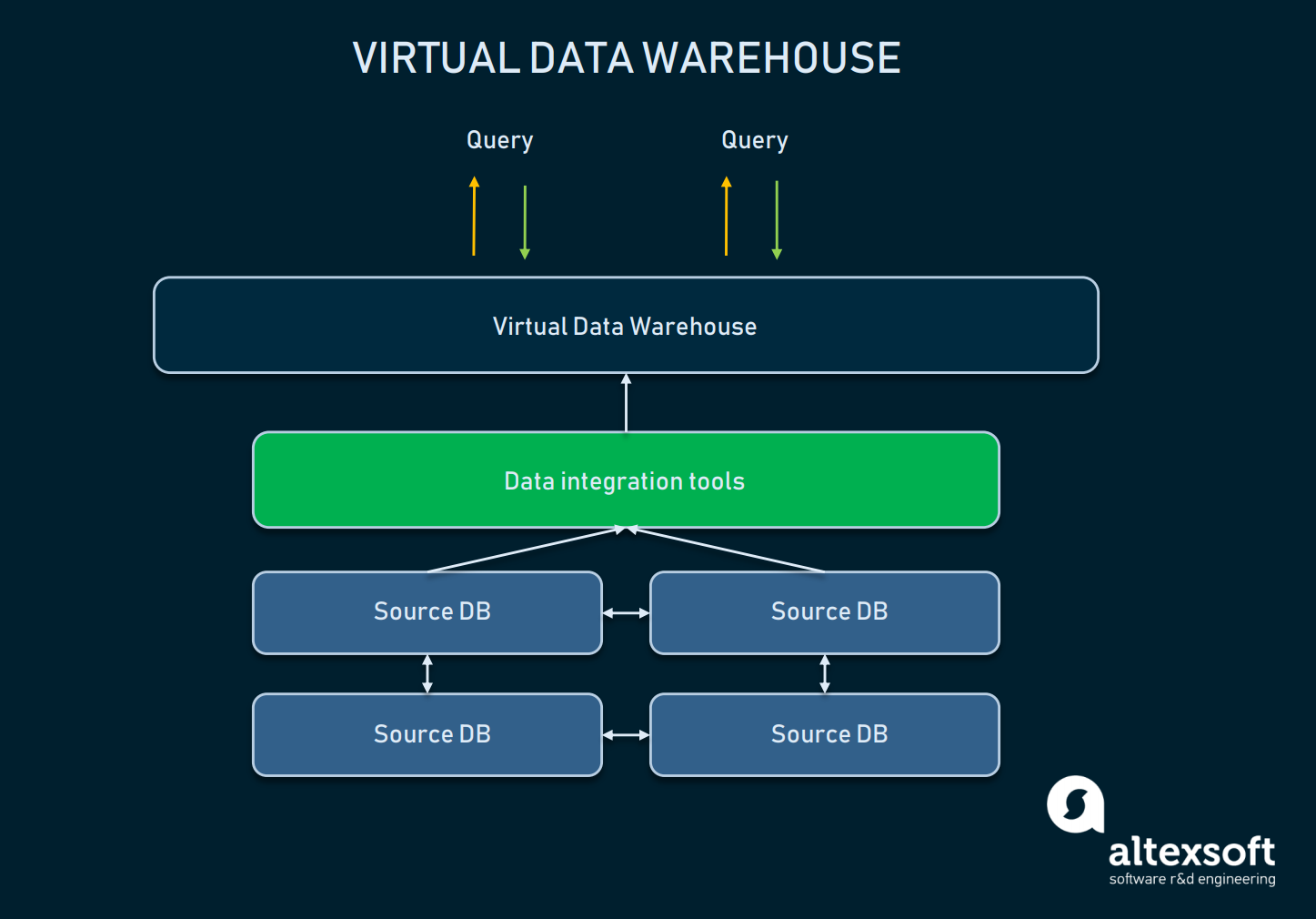
Een relatieschema tussen de abstractie van het virtuele DW en de brondatabases
Een dergelijke aanpak stelt organisaties in staat het eenvoudig te houden: De gegevens kunnen in de bronnen blijven, maar kunnen toch met behulp van analytische hulpmiddelen worden opgehaald. Virtuele magazijnen kunnen worden gebruikt als men niet wil knoeien met de onderliggende infrastructuur, of als de gegevens waarover men beschikt gemakkelijk kunnen worden beheerd zoals ze nu zijn. Een dergelijke aanpak heeft echter veel nadelen:
- Meerdere databases vergen voortdurend software- en hardware-onderhoud en kosten.
- De in een virtueel DW opgeslagen gegevens vereisen nog steeds een transformatie-software om ze verteerbaar te maken voor de eindgebruikers en rapportage-tools.
- Complexe data queries kunnen te veel tijd in beslag nemen, omdat de benodigde stukken data in twee afzonderlijke databases kunnen worden geplaatst.
Wanneer te gebruiken: geschikt voor bedrijven die ruwe data in een gestandaardiseerde vorm hebben die geen complexe analyses vereisen. Het past ook bij organisaties die BI niet systematisch gebruiken, of ermee willen beginnen.
Cloud Data Warehouse
Sinds een decennium zijn cloud/cloudless technologieën meer een standaard geworden voor het opzetten van technologieën op organisatieniveau. Er zijn talloze aanbieders op de markt die warehousing-as-a-service aanbieden. Om er een paar te noemen:
- Amazon Redshift/ Pricing page
- IBM Db2/ Pricing page
- Google BigQuery/ Pricing page
- Snowflake/ Pricing page
- Microsoft SQL Data Warehouse/ Pricing page
Al deze genoemde aanbieders bieden volledig beheerde, schaalbare warehousing aan als onderdeel van hun BI-tooling, of richten zich op EDW als een standalone service, zoals Snowflake doet. In dit geval heeft de cloud warehouse-architectuur dezelfde voordelen als elke andere cloud-dienst. De infrastructuur wordt voor u onderhouden, wat betekent dat u geen eigen servers, databases en tooling hoeft op te zetten om het te beheren. De prijs voor een dergelijke dienst zal afhangen van de hoeveelheid geheugen die nodig is, en de hoeveelheid rekencapaciteiten voor query’s.
Het enige aspect waar u zich zorgen over zou kunnen maken als het gaat om een cloud warehouse-platform is gegevensbeveiliging. Uw bedrijfsgegevens zijn een gevoelig iets. Dus, u wilt controleren of de leverancier die u hebt gekozen kan worden vertrouwd om inbreuken te voorkomen. Dit betekent niet noodzakelijkerwijs dat een on-premise magazijn veiliger is, maar in dit geval ligt de veiligheid van uw gegevens in uw handen.
Wanneer te gebruiken: Cloudplatforms zijn een geweldige keuze voor organisaties van elke omvang. Als u alles voor u wilt laten opzetten, inclusief beheerde gegevensintegratie, DW-onderhoud en BI-ondersteuning.
Enterprise Data Warehouse-architectuur
Hoewel er vele architecturale benaderingen zijn die de magazijnmogelijkheden op de een of andere manier uitbreiden, zullen we ons richten op de meest essentiële. Zonder in al te veel technische details te duiken, kan de hele gegevenspijplijn in drie lagen worden verdeeld:
- Ruwe gegevenslaag (gegevensbronnen)
- Warenhuis en zijn ecosysteem
- Gebruikersinterface (analytische tools)
De tooling die zich bezighoudt met gegevensextractie, -transformatie en -lading in een warenhuis is een aparte categorie tools die bekend staat als ETL. Onder de ETL-paraplu voeren data-integratietools manipulaties uit met gegevens voordat ze in een magazijn worden geplaatst. Deze tools opereren tussen een ruwe data laag en een warehouse.
Wanneer de gegevens in een warehouse zijn geladen, kunnen ze ook worden getransformeerd. Het pakhuis zal dus bepaalde functionaliteit nodig hebben voor het opschonen/standaardiseren/dimensionaliseren. Deze en andere factoren zullen de complexiteit van de architectuur bepalen. We zullen de EDW architectuur bekijken vanuit het oogpunt van groeiende organisatorische behoeften.
One-tier architectuur
Als de data integratie goed is geconfigureerd, kunnen we ons data warehouse kiezen. In de meeste gevallen is een data warehouse een relationele database met modules om multidimensionale gegevens mogelijk te maken, of een die bepaalde domeinspecifieke informatie kan scheiden om de toegang te vergemakkelijken. In zijn meest primitieve vorm kan warehousing slechts een one-tier architectuur hebben.
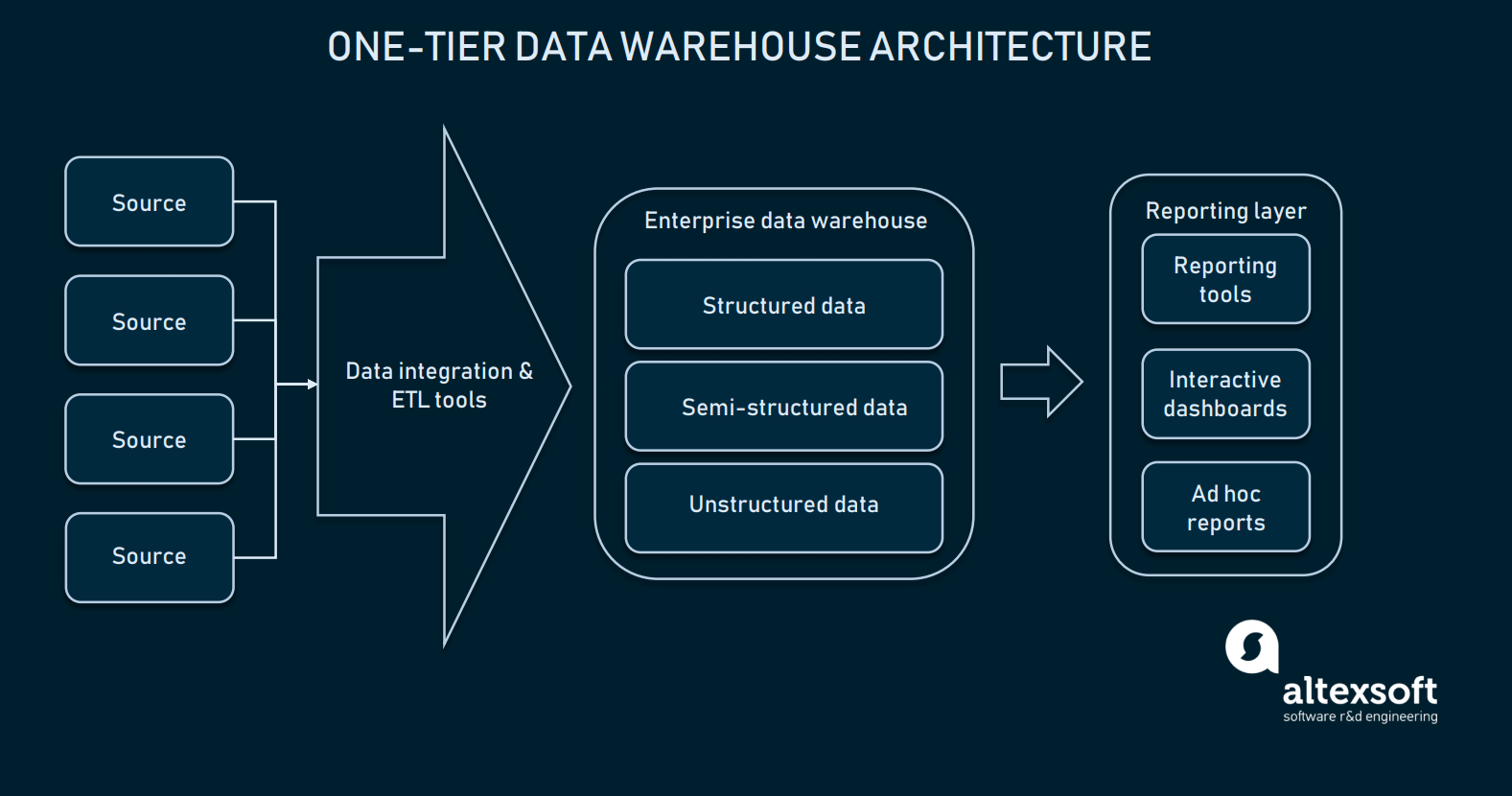
De rapportagelaag is direct verbonden met de gehele database van EDW
One-tier architectuur voor EDW betekent dat u een database heeft die direct verbonden is met de analytische interfaces waar de eindgebruiker queries kan maken. De directe verbinding tussen een EDW en analytische tools brengt verschillende uitdagingen met zich mee:
- Traditioneel kunt u uw opslag beschouwen als een magazijn vanaf 100GB aan data. Rechtstreeks ermee werken kan leiden tot rommelige query-resultaten, evenals een lage verwerkingssnelheid.
- Vragen naar gegevens rechtstreeks uit het DW kan nauwkeurige invoer vereisen, zodat het systeem in staat zal zijn om niet-vereiste gegevens uit te filteren. Dat maakt het omgaan met presentatiehulpmiddelen wat moeilijk.
- Er zijn beperkte flexibiliteit/analytische mogelijkheden.
Daarnaast stelt de one-tier architectuur enige grenzen aan de complexiteit van de rapportage. Een dergelijke aanpak wordt zelden gebruikt voor grootschalige gegevensplatforms, vanwege de traagheid en onvoorspelbaarheid ervan. Om geavanceerde data queries uit te voeren, kan een warehouse worden uitgebreid met low-level instances die de toegang tot data vergemakkelijken.
Two-tier architectuur (data mart laag)
In een two-tier architectuur wordt een data mart niveau toegevoegd tussen de gebruikersinterface en het EDW. Een data mart is een opslagplaats op laag niveau die domeinspecifieke informatie bevat. Simpel gezegd is het een andere, kleinere database die het EDW uitbreidt met specifieke informatie voor uw verkoop-/operationele afdelingen, marketing, enz.
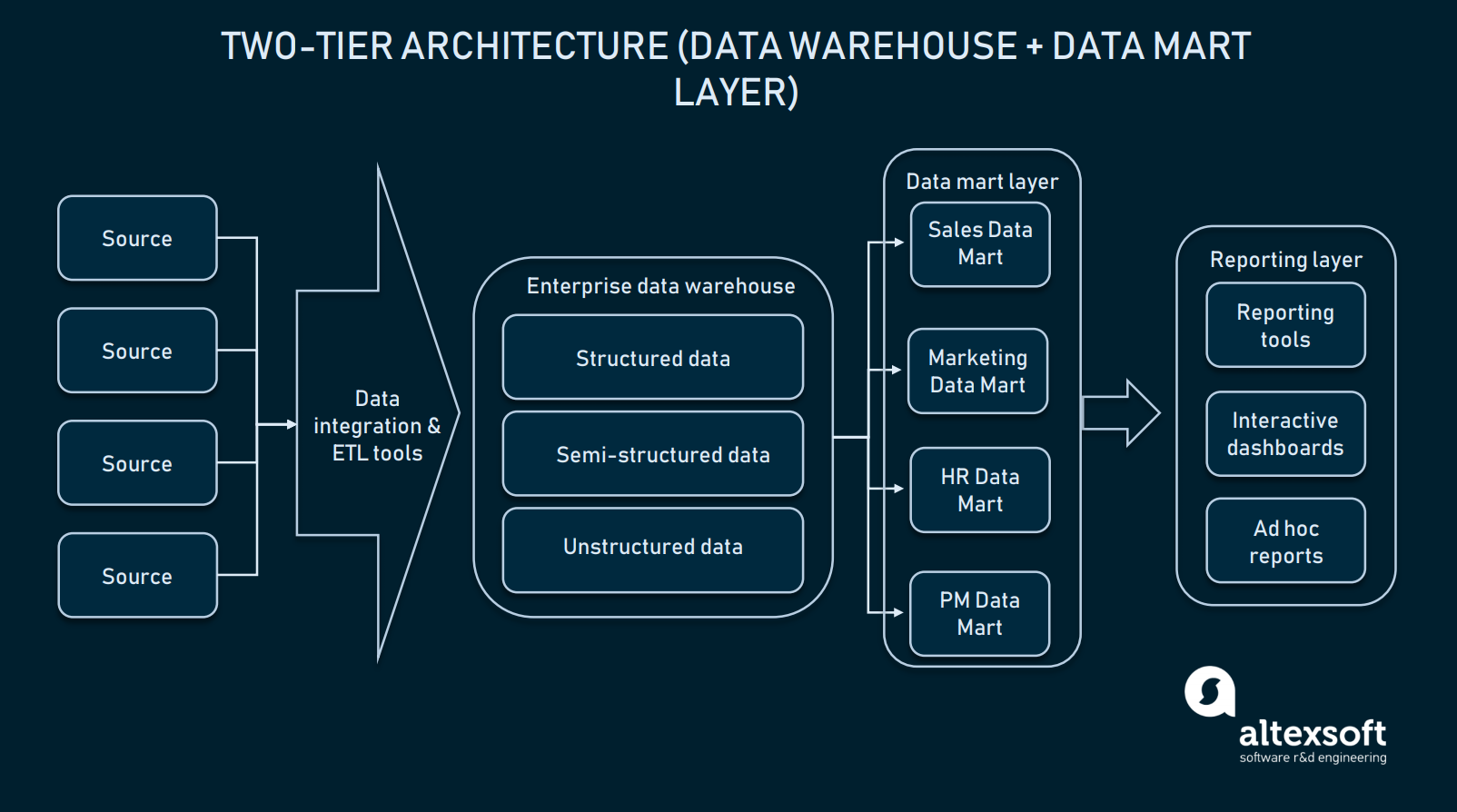
In een two-tier architectuur wordt een EDW uitgebreid met data marts om domeinspecifieke gegevens te verstrekken
Het creëren van een data mart laag zal extra middelen vereisen om hardware op te zetten en deze databases te integreren met de rest van het dataplatform. Maar een dergelijke aanpak lost het probleem met query’s op: Elke afdeling zal gemakkelijker toegang krijgen tot de vereiste gegevens omdat een bepaalde mart alleen domeinspecifieke informatie zal bevatten. Bovendien beperken data marts de toegang tot gegevens voor eindgebruikers, waardoor EDW veiliger wordt.
Three-tier architecture (Online analytical processing)
Naast de data mart-laag gebruiken ondernemingen ook online analytical processing (OLAP) cubes. Een OLAP-kubus is een specifiek type database dat gegevens in meerdere dimensies weergeeft. Terwijl relationele databases gegevens in slechts twee dimensies weergeven (denk aan Excel of Google Sheets), kunt u met OLAP gegevens in meerdere dimensies samenstellen en tussen dimensies verplaatsen.
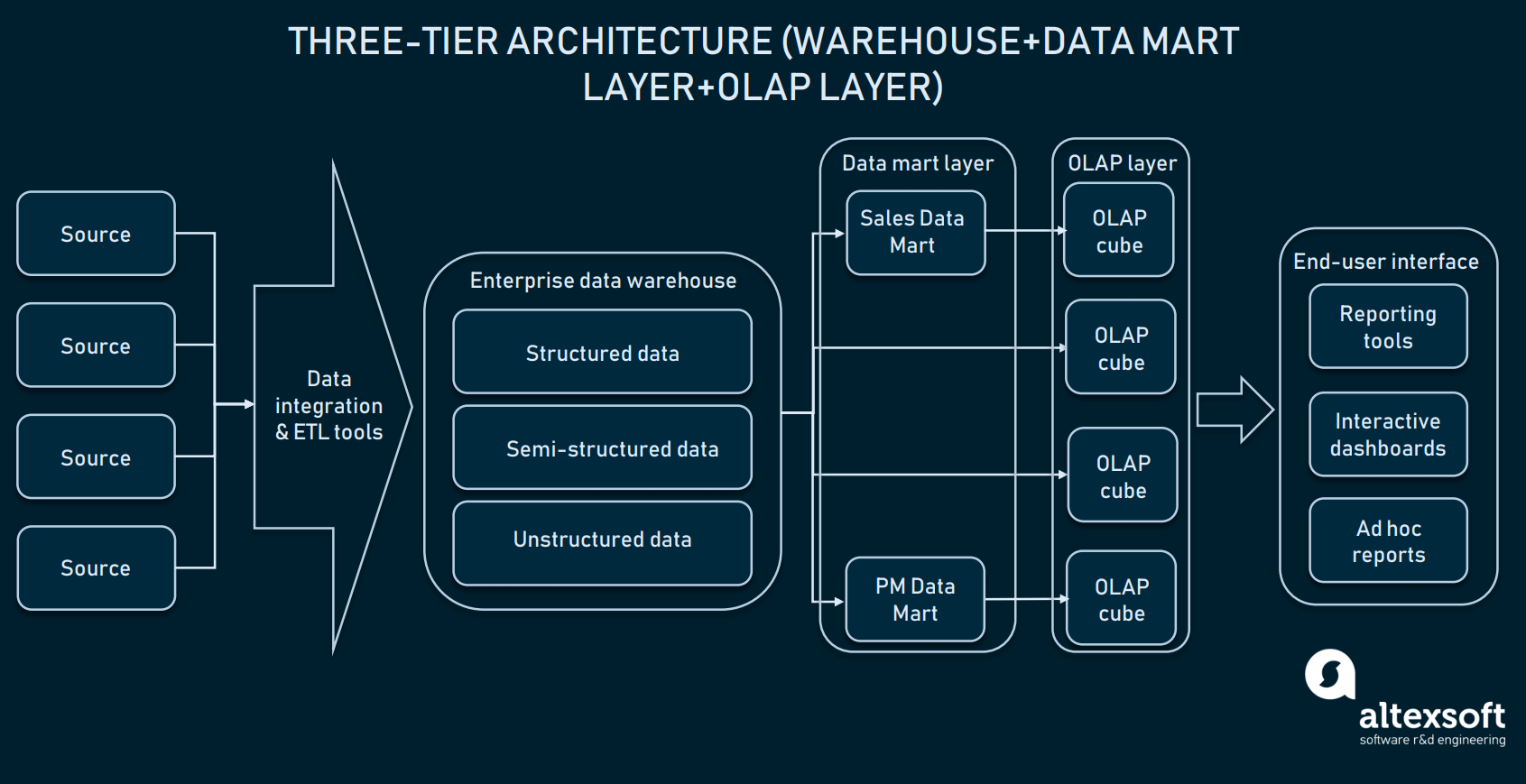
OLAP kubes laag kan informatie uit gedistribueerde marts of rechtstreeks uit EDW halen
Het is vrij moeilijk uit te leggen in woorden, dus laten we eens kijken naar dit handige voorbeeld van hoe een kubus eruit kan zien.
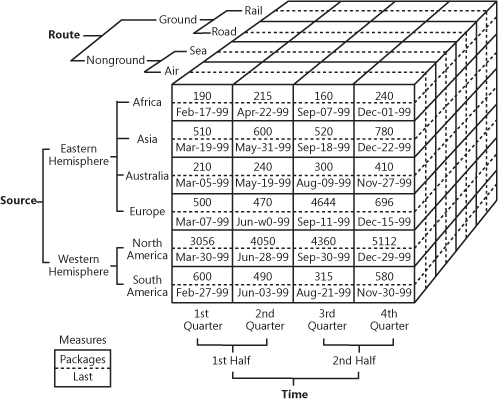
OLAP-kubus die multidimensionale verkoopgegevens laat zien
Bron: oreilly.com
Zoals u ziet, voegt een kubus dimensies toe aan de gegevens. U kunt het zien als meerdere Excel-tabellen die met elkaar zijn gecombineerd. De voorkant van de kubus is de gebruikelijke tweedimensionale tabel, waarin regio (Afrika, Azië, enz.) verticaal wordt gespecificeerd, terwijl verkoopaantallen en datums horizontaal worden geschreven. De magie begint wanneer we naar het bovenste facet van de kubus kijken, waar de verkoop wordt gesegmenteerd per route en de onderkant de tijdsperiode specificeert. Dat staat bekend als multidimensionale data.
De zakelijke waarde van OLAP is dat het gebruikers in staat stelt de gegevens te slicen en dice-en om gedetailleerde rapporten samen te stellen. Zolang de kubussen zijn geoptimaliseerd om met magazijnen te werken, kunnen ze zowel direct met een EDW worden gebruikt om toegang te geven tot alle bedrijfsgegevens, als specifiek met elke datamart. Wat de implementatie betreft, bieden bijna alle leveranciers van magazijnen OLAP als een service aan. Kijk bijvoorbeeld eens naar de documentatie van Microsoft over hun OLAP-aanbod.
Op dat punt hebben we een high-level ontwerp van een EDW besproken, toegepast op organisatorische behoeften. Nu gaan we dieper in op de technische componenten die een magazijn kan omvatten.
Data Warehouse vs Data Lake vs Data Mart
Sprekend over de architectuur van gegevensopslag, moeten we opties noemen als het gebruik van een data mart of een data lake in plaats van een magazijn. Deze worden vaak door elkaar gehaald en we zullen de definities nader toelichten.
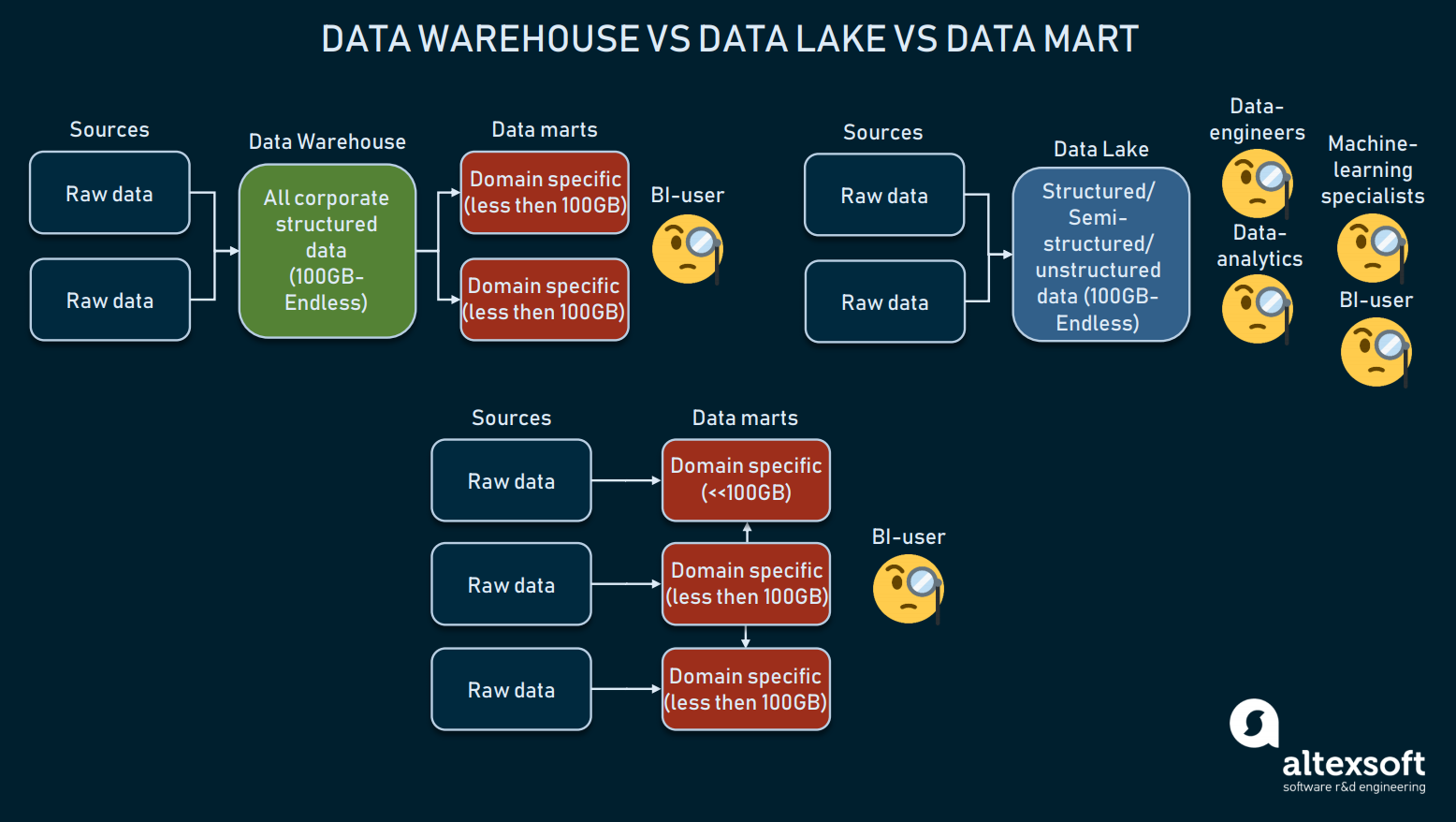
De vergelijking van drie vormen van gegevensopslag
Data warehouses zijn bedoeld om gestructureerde gegevens op te slaan, zodat querytools en eindgebruikers uitgebreide resultaten kunnen krijgen. Warehouses, meestal gebruikt voor BI, variëren meestal in grootte tussen 100GB en oneindig.
Data lakes, daarentegen, worden gebruikt om voornamelijk ruwe of gemengde gegevens op te slaan. Deze worden vaak gebruikt voor machine learning, big data of datamining. De laatste jaren werden data lakes gebruikt voor BI: ruwe gegevens worden in een lake geladen en getransformeerd, wat een alternatief is voor het ETL-proces. Hoewel deze aanpak zijn voor- en nadelen heeft, kunnen data lakes te rommelig zijn om gestructureerde gegevens te bereiken.
Dan hebben we data marts, die ook kunnen worden gebruikt als alternatief voor DW. Dergelijke modellen (zoals het model van Kimball) gaan uit van het gebruik van meerdere data marts om informatie naar domeinen te verdelen en met elkaar te verbinden. Maar vanwege hun kleine omvang (meestal minder dan 100 GB) kunnen data marts nauwelijks door ondernemingen worden gebruikt. Vaker worden data marts gebruikt om een groot DW op te splitsen in meer bruikbare DW’s.
Enterprise Data Warehouse Components
Er zijn een heleboel instrumenten die gebruikt worden om een warehousing platform op te zetten. De meeste hebben we al genoemd, inclusief een magazijn zelf. Laten we dus in vogelvlucht het doel van elke component en hun functies bekijken.
Bronnen. Dat is eenvoudig, de databases waar de ruwe gegevens zijn opgeslagen.
Extract, Transform, Load (ETL) of Extract, Load, Transform (ELT) laag. Dit zijn de gereedschappen die de feitelijke verbinding met de brongegevens tot stand brengen, deze extraheren en laden naar de plaats waar zij zullen worden getransformeerd. Transformatie verenigt het gegevensformaat. ETL en ELT verschillen in die zin dat bij ETL de transformatie vóór het EDW wordt uitgevoerd, in een staging area. ELT is een modernere aanpak die alle transformatie in een magazijn afhandelt.
Staging area. In het geval van ETL, is het staging gebied de plaats waar data wordt geladen voordat het EDW. Hier worden ze opgeschoond en getransformeerd naar een bepaald datamodel. Het staging-gebied kan ook tooling voor datakwaliteitsbeheer omvatten.
DW-database. De gegevens worden uiteindelijk in de opslagruimte geladen. In ELT kan hier nog enige transformatie nodig zijn. Maar in dat stadium worden alle algemene wijzigingen toegepast, zodat de gegevens in hun definitieve model(len) worden geladen. Zoals gezegd, zijn data warehouses meestal relationele databases. Een DW omvat ook een databasebeheersysteem en extra opslagruimte voor metadata.
Meta-gegevensmodule. Eenvoudig gezegd, metadata zijn gegevens over gegevens. Het zijn de toelichtingen die voor gebruikers/beheerders hints geven op welk onderwerp/domein deze informatie betrekking heeft. Deze gegevens kunnen technische meta zijn (b.v. oorspronkelijke bron), of zakelijke meta (b.v. regio van verkoop). Alle meta wordt opgeslagen in een aparte module van EDW en wordt beheerd door een metadatamanager.
Rapportagelaag. Dit zijn tools die eindgebruikers toegang geven tot gegevens. Ook wel BI-interface genoemd, zal deze laag dienen als een dashboard om gegevens te visualiseren, rapporten te vormen, en afzonderlijke stukken informatie op te halen.
Eindgedachte
Inzicht in de keten van tooling die gegevens doorgeeft, kan u helpen erachter te komen wat eigenlijk past bij uw eisen aan het gegevensplatform. Het opzetten van een magazijn kan jaren van planning en testen vergen, vanwege de omvang ervan in de meest elementaire vorm.
Als bedrijfseigenaar kunt u in de war raken door het aantal opties en gebruikte technologieën, dus het is van vitaal belang om te overleggen met experts op het gebied van warehousing, ETL, en BI. Terwijl deskundigen u kunnen helpen met het technische aspect, moet u voor het definiëren van het zakelijke doel spreken met degenen die de werkelijke gegevens in hun werk zullen gebruiken.